hbase读写性能测试调优_初稿
Hbase读写性能测试调优
| 日期 |
版本 |
修订 |
审批 |
修订说明 |
| 2016.9.23 |
1.0 |
章鑫 |
|
初始版本 |
|
|
|
|
|
|
1 前言
本篇文章主要讲的是hbase读写性能调优过程中遇到的一些技巧和配置项的修改,对于hbase本身的原理和框架不会做太多的介绍。该文档中涉及到ycsb配置和使用方面的内容需要结合ycsb工具使用文档阅读理解。
2 配置
2.1 集群配置
[root@node1 ~]#uname -a
| Linux node1.dcom 3.10.0-327.el7.x86_64 #1 SMP Thu Nov 19 22:10:57 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
|
[root@node1 ~]# top
| top - 10:02:40 up 51 days, 12:39, 11 users, load average: 1.42, 1.23, 1.04 Tasks: 414 total, 1 running, 413 sleeping, 0 stopped, 0 zombie %Cpu(s): 1.6 us, 0.4 sy, 0.0 ni, 97.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65772144 total, 23124796 free, 8079632 used, 34567716 buff/cache KiB Swap: 0 total, 0 free, 0 used. 56828368 avail Mem
|
[root@node1 ~]# free -m #64G内存
| total used free shared buff/cache available Mem: 64230 7899 23391 475 32939 55486 Swap: 0 0 0 |
[root@node1 ~]# df -Th
| Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/centos-root xfs 231G 11G 221G 5% / devtmpfs devtmpfs 32G 0 32G 0% /dev tmpfs tmpfs 32G 24K 32G 1% /dev/shm tmpfs tmpfs 32G 588M 31G 2% /run tmpfs tmpfs 32G 0 32G 0% /sys/fs/cgroup /dev/sda1 xfs 494M 130M 364M 27% /boot /dev/mapper/centos-var xfs 100G 6.7G 94G 7% /var /dev/mapper/centos-opt xfs 600G 733M 599G 1% /opt tmpfs tmpfs 6.3G 0 6.3G 0% /run/user/0 /dev/sdc xfs 932G 66G 866G 8% /opt/hdata /dev/sdb1 xfs 932G 63G 869G 7% /opt/hdata2 /dev/sdd1 xfs 932G 65G 867G 7% /opt/hdata3 /dev/sde1 xfs 932G 67G 866G 8% /opt/hdata4
#Hdfs的datanode目录磁盘是sdb、sdc、sdd和sde,也就是说hbase存储在这四块磁盘上。总的大小大概是4T不到一点,4台设备的集群总大小大约在14.5T左右。 |
[root@node1~]# cat /proc/cpuinfo #24核
| …………………… processor : 23 vendor_id : GenuineIntel cpu family : 6 model : 62 model name : Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz stepping : 4 microcode : 0x428 cpu MHz : 1211.109 cache size : 15360 KB physical id : 1 siblings : 12 core id : 5 cpu cores : 6 apicid : 43 initial apicid : 43 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm arat epb pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms xsaveopt bogomips : 4204.89 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management:
|
[root@node1 ~]# ethtool bond0 #网卡信息
| Settings for bond0: Supported ports: [ ] Supported link modes: Not reported Supported pause frame use: No Supports auto-negotiation: No Advertised link modes: Not reported Advertised pause frame use: No Advertised auto-negotiation: No Speed: 2000Mb/s Duplex: Full Port: Other PHYAD: 0 Transceiver: internal Auto-negotiation: off Link detected: yes |
[root@node1 ~]# hadoop version #hadoop版本
| Hadoop 2.7.1.2.4.2.0-258 Subversion [email protected]:hortonworks/hadoop.git -r 13debf893a605e8a88df18a7d8d214f571e05289 Compiled by jenkins on 2016-04-25T05:46Z Compiled with protoc 2.5.0 From source with checksum 2a2d95f05ec6c3ac547ed58cab713ac This command was run using /usr/hdp/2.4.2.0-258/hadoop/hadoop-common-2.7.1.2.4.2.0-258.jar |
[root@node1 ~]# hbase version #hbase版本
| 2016-09-06 14:52:19,070 INFO [main] util.VersionInfo: HBase 1.1.2.2.4.2.0-258 2016-09-06 14:52:19,071 INFO [main] util.VersionInfo: Source code repository file:///grid/0/jenkins/workspace/HDP-build-centos6/bigtop/build/hbase/rpm/BUILD/hbase-1.1.2.2.4.2.0 revision=Unknown 2016-09-06 14:52:19,071 INFO [main] util.VersionInfo: Compiled by jenkins on Mon Apr 25 06:36:21 UTC 2016 2016-09-06 14:52:19,071 INFO [main] util.VersionInfo: From source with checksum 4f661ee4f9f148ce7bfcad5b0d667c27 |
[root@node1 ~]# hdfs version #hdfs版本
| Hadoop 2.7.1.2.4.2.0-258 Subversion [email protected]:hortonworks/hadoop.git -r 13debf893a605e8a88df18a7d8d214f571e05289 Compiled by jenkins on 2016-04-25T05:46Z Compiled with protoc 2.5.0 From source with checksum 2a2d95f05ec6c3ac547ed58cab713ac This command was run using /usr/hdp/2.4.2.0-258/hadoop/hadoop-common-2.7.1.2.4.2.0-258.jar |
Hadoop集群共有相同配置的4个node节点,在其他相同配置的集群以外的node节点上运行ycsb测试进程,hadoop集群是通过ambari软件运行维护的,对应的很多配置都是在ambari的web界面上去完成的。
2.2 hadoop配置
这里的hadoop配置主要包括了hbase和hdfs两类配置,读写在具体配置时会有稍许不同,这个在具体的地方会具体指明。
在后面第4、5章中介绍读写配置时没有单独指出介绍的配置项一般在两种情况下都较为适用,而且几乎都已经调到了最大值,在这里会统一介绍。
2.2.1 hbase配置
[root@node1 test]# cat /usr/hdp/current/hbase-client/conf/hbase-site.xml
|
#Todo
#Todo
#每条记录的最大大小为1MB
#hbase client操作失败重新请求数为35
#当一次scan操作不在本地内存时,需要从disk中获取时,缓存的条数,这里设置为100000条,该值不能大于下文中hbase.client.scanner.timeout.period配置项的值
下图中的第一个配置项hbase.client.scanner.timeout.period对应的是上文中的Number of Fetched Rows when Scanning from Disk,它的值必须小于下图中的第一个配置项才行。 第二个配置项的话默认是true的,无需额外配置,之前在解决一个相关问题时,将它置为了false。
#hbase是否配置为分布式
#Todo
#Todo
#设置为ture,忽略对默认hbase版本的检查(设置为false的话在maven工程的编译过程中可能会遇到版本相关的问题)
#设置系统进行1次majorcompaction的启动周期,如果设置为0,则系统不会主动出发MC过程,默认为7天
#用来作为计算MC时间周期,与hbase.hregion.majorcompaction相结合,计算出一个浮动的MC时间。默认是0.50,简单来说如果当前store中hfile的最早更新时间早于某个MCTime,就会触发major compaction,hbase通过这种机制定期删除过期数据。MCTime是一个浮动值,浮动区间为[ hbase.hregion.majorcompaction - hbase.hregion.majorcompaction * hbase.hregion.majorcompaction.jitter , hbase.hregion.majorcompaction + hbase.hregion.majorcompaction * hbase.hregion.majorcompaction.jitter ]
#单个region的大小为10G,当region大于这个值的时候,一个region就会split为两个,适当的增加这个值的大小可以在写操作时减少split操作的发生,从而减少系统性能消耗而增加写操作的性能,默认是10G,官方建议10G~30G
#当一个region的memstore总量达到hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size (默认2*128M)时,会阻塞这个region的写操作,并强制刷写到HFile,触发这个刷新操作只会在Memstore即将写满hbase.hregion.memstore.flush.size时put了一个巨大的记录的情况,这时候会阻塞写操作,强制刷新成功才能继续写入
#每个单独的memstore的大小(默认128M),这里调成了256M,每个列族columnfamily在每个region中都分配有它单独的memstore,当memstore超过该值时,就会发生flush操作,将memstore中的内容刷成一个hfile,每一次memstore的flush操作,都会为每一次columnfamily创建一个新的hfile;调高该值可以减少flush的操作次数,减少每一个region中的hfile的个数,这样就会减少minor compaction的次数和split的次数,从而降低了系统性能损耗,提升了写性能,也提升了读性能(因为读操作的时候,首先要去memstore中查数据,查找不到的话再去hfile,hflie存储在hdfs中,这就涉及到了对性能要求较高的io操作了)。当然这个值变大了之后,每次flush操作带来的性能消耗也就更大。
#mslab特性是在分析了HBase产生内存碎片后的根因后给出了解决方案,这个方案虽然不能够完全解决Full GC带来的问题,但在一定程度上延缓了Full GC的产生间隔,总之减少了内存碎片导致的full gc,提高整体性能。
#当任意一个store中有超过hbase.hstore.blockingStoreFiles个数的storefiles时,这个store所在region的update操作将会被阻塞,除非这个region的compaction操作完成或者hbase.hstore.blockingWaitTime超时。 Block操作会严重影响当前regionserver的响应时间,但过多的storefiles会影响读性能,站在实际使用的角度,为了获取较为平滑的响应时间,可以将该值设得很大,甚至无限大。默认值为7,这里暂时调大到100。
#一次minor compaction的最大file数
#一次minor compaction的最小file数
#本地文件目录用来作为hbase在本地的存储
#todo #与前文配置项图中第二红线标注的配置项重复
#hbase master web界面绑定的IP地址(任何网卡的ip都可以访问)
#hbase master web界面绑定端口
#todo
#分配1%的regionserver的内存给写操作当作缓存,这个参数和下面的hfile.block.cache.size(读缓存)息息相关,二者之和不能超过总内存的80%,读操作时,该值最好为0,但是这里有个bug,取不到0,所以取值1%即0.01,系统尽可能的把内存给读操作用作缓存
#regionserver处理IO请求的线程数,默认是30这里调高到240
#regionserver 信息 web界面接口
#regionserver服务端口
#todo
#hbase所有表的文件存放在hdfs中的路径,用户可以在hdfs的web页面和后台命令行中查看,若要彻底删除表,现在hbase中删除,然后在hdfs中删除源文件即可,drop命令运行过后hdfs上内容没有删除情况下。
#todo
#hbase rpc操作超时时间
#todo
#todo
#todo
#本地文件系统上的临时目录,最好不要使用/tmp下的目录,以免重启后丢失文件
#zookeeper配置文件zoo.cfg中定义的内容,zookeeper 客户端通过该port连接上zookeeper服务
#zookeeper服务的节点数目和各节点名称
#zookeeper支持多重update
#将regionserver的内存的79%分配作为读缓存,默认是40%,这里因为是单独的读操作性能调优所以调到了79%,上文中提到了一个bug,不能调为最高的80%。该配置项与上文中的hbase.regionserver.global.memstore.size关系密切,二者的总和不能大于regionserver内存的80%,读操作为主时就将该值调高,写操作为主时就将hbase.regionserver.global.memstore.size调高
#todo
#zookeeper session会话超时时间
#znode 存放root region的地址 #todo
# RegionServers maximum value for –Xmn 新生代jvm内存大小,默认是1024,这里调到了4096,这个参数影响到regionserver 的jvm的CMS GC,64G内存的话建议1~3G,最大为4G,regionserver –Xmn in –Xmx ratio配置项也密切相关,该比例设置的太大或者太小都不好,这方面涉及到的内容太多,后续再详细介绍。 # Number of Fetched Rows when Scanning from Disk这个就是上文中提到的hbase.client.scanner.caching # Maximum Store Files before Minor Compaction 在执行Minor Compaction合并操作前Store Files的最大数目,默认是3,这里调到了4 # The maximum amount of heap to use, in MB. Default is 1000. #export HBASE_HEAPSIZE=3000 分配给hbase服务的内存,默认是1000,由于hbase较耗内存,所以提高到了3000 这个地方有疑问:这里配置这么小的内存到底是给谁用的?
|



2.2.2 hdfs配置
相关配置介绍:
(1) NameNode directories
这里配置了4个namenode目录,分别挂载在不同的硬盘上。Namenode的目录,只在namenode节点上有内容,datanode节点上该目录为空,且namenode节点上该目录的内容都是一样的(其他的作为备份)。
(2) DataNode directories
这里配置了4个datanode目录,分别挂载在不同的硬盘上。Datanode目录在每个datanode节点上都有实际的内容,存储着真正的hdfs数据和备份。
(3) Namenode_heapsize
Namenode节点的java运行内存,默认1G,这里调高到了3G。
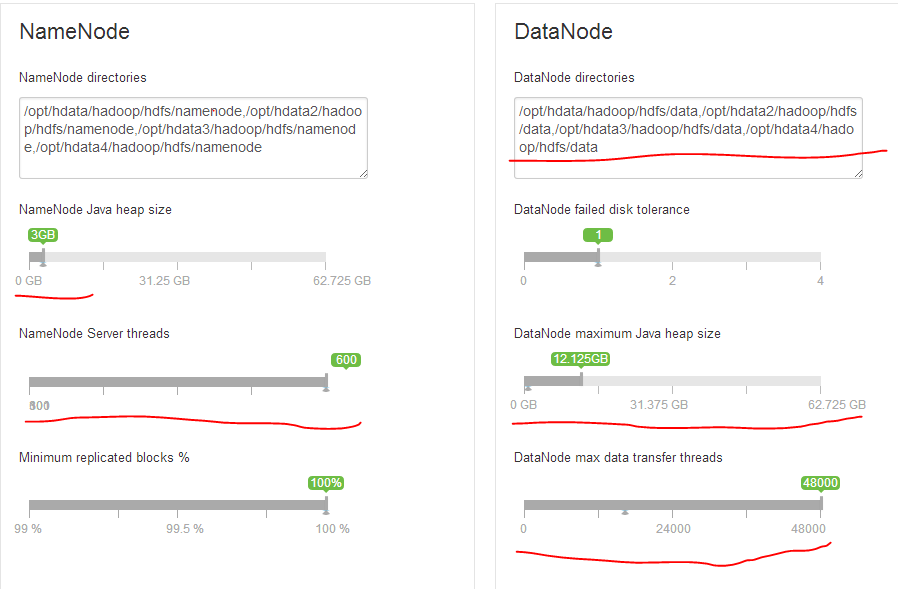
(4) dtnode_heapsize
默认为1G,这里调大到了12G,也不能太大,否则datanode启动时会因为无法分配足够内存而报错。
(5) Dfs.datanode.max.transfer.threads
Datanode传输数据线程数,默认16384调大到了48000。
2.2.3 其他配置
(1)另外还有几个重要的配置参数介绍一下(这里其实是我遇到个一个疑问)
Hbase.regionserver.global.memstore.uppperLimit默认0.4
Hbase.regionserver.global.memstore.lowerLimit默认0.35
一个regionserver会有多个region,多个memstore,所以可能单个region并没有超过阈值,但是整个regionserver的内存占用已经非常多了,上面这两个参数也会去控制和影响内存的刷写,当regionserver上全部的memstore占用超过heap(heap的值在hbase-env.sh中设置,HBASE_HEAPSIZE默认为1000,我们这里设置为3000)的40%时,强制阻塞所有的写操作,将所有的memstore刷写到HFile;当所有的memstore占用超过heap的35%时,会选择一些占用内存比较大的memstore阻塞写操作并进行flush。
注意:
这两个配置项,在当前的环境中并未找到!怀疑是直接当作默认值,用户可以自行添加修改?
3 测试步骤
这里简单介绍下具体测试时的大体步骤,关于ycsb工具使用的细节需要结合ycsb使用文档阅读理解。
3.1.1 预分区和建表
Hbase shell 操作:
hbase(main):033:0>n_splits=200
=> 200 #200个region分区
hbase(main):032:0> create
'a',{NAME=>'cf'},{SPLITS=>(1...n_splits).map{|i|"user#{1000000+i*(9999999-1000000)/n_splits}"}}
0 row(s) in28.4070 seconds
=>Hbase::Table – a #建立名为a,列族1个名为cf,分区region200个,并通过一定的算法使得rowkey的分布呈一定的规律
采用预分区和rowkey均匀分布的方式建立表格能够很大程度上提高hbase的读写性能。
3.1.2 装载初始化数据库
插入数据 ycsb的load阶段(测试写入性能)。
[root@node5test]# sh ycsb_load.sh load
******Loadingtest begin******
******Loadingtest end******
Load文件即为执行load阶段时ycsb的配置文件
3.1.3 对数据库进行操作
ycsb的run阶段(配置参数例如read、scan操作可测试读取性能)。
[root@node5test]# sh ycsb_run.sh run
******runningtest begin******
******runningtest end******
run文件即为执行run阶段时ycsb的配置文件
4 读性能测试与调优
4.1 Scan操作
Hbase集群四台节点的top、iostat和带宽记录值以及ycsb配置文件见本文档附带的文件目录。
YCSB scan操作扫描hbase数据库,测试结果:
| 操作 |
分区数 |
value长度 |
速度 条/秒 |
集群节点数 |
ycsb client节点数 |
带宽 |
操作数 |
瓶颈 |
| 扫描scan |
200 regions |
9216bytes |
85000~90000左右 |
4 |
4 |
1500~1600Mb/s |
200000 |
带宽、ycsb clinet 内存 |
| 扫描scan |
200 regions |
9216bytes |
20000左右 |
4 |
1 |
1850Mb/s |
200000 |
带宽 |
Scan操作选取了两个结果,第一个运行了4个ycsb client,第二个只有1个ycsb client第二个的瓶颈明显是带宽。
由于ycsb 和hbase 的scan操作特点所以这里具体的操作速度都是通过带宽估算出来的。
4.1.1 配置调优重点
Hbase的scan操作是一种批量读取的操作,scan与read不同,scan一次性请求大量数据,默认的话是读取全表,这就需要在客户端的本地占用很大的内存来缓存一次批量拉取的数据,下面介绍一下几个关系密切的配置项。
读取hbase数据的顺序是:
先去memstore中查找,找不到再去blockcahe中,如果没有就去hdfs中查找,找到之后读取的同时保存一份到blockcahe中便于下次查找。
memstore和blockcahe都是在内存中查找速度很快,延时很低,性能很好,而在hdfs中查找和读取就涉及到磁盘的读取操作,磁盘IO消耗性能较大。
(1)hadoop配置
#当一次scan操作不在本地内存时,需要从disk中获取时,缓存的条数,这里设置为100000条,该值不能大于下文中hbase.client.scanner.timeout.period配置项的值。该数值也并不是越高越好,太高的话scan超时时间就会很长,影响性能,一次性获取条数固然多,但由于带宽和其他的限制并不能很好的消化掉,太低当然也不行,配置时需要根据具体情况具体设置。
一条数据长度为9k的话,一次缓存100000条就需要900MB,所以对ycsb client端有较高的内存要求。
#Scanner超时时间,必须大于hbase.client.scanner.caching的数值。这个参数是在配置hbase.client.scanner.caching后hadoop报错之后我自己加的。
(2)ycsb配置
这里有必要解释一下ycsb在scan时的原理:
Ycsb利用自己的hash算法生成一个rowkey,然后每次在1~ maxscanlength里选取一个值作为本次要扫描的条数。
ycsb配置文件关键项:
##节选 ycsb配置文件
maxscanlength=20000 #每次最多能扫描的条数
#scanlengthdistribution=zipfian #获取scanlength的概率分布,默认是uniform等概率随机分布
requestdistribution=latest #读取最近更新过的数据,存在热点数据,但根据LRU blockcache原理这种选择性能更好
##节选 ycsb配置文件
4.1.2 Ycsb client状态
一共有4个ycsb client节点,四个系统状态基本一致,可能在某些参数上有少许差别,ycsbclient上没有对磁盘进行操作,所以没有记录iostat命令。
(1)Top命令:
[root@node7 test]# top
| top - 02:44:17 up 49 days, 16:20, 8 users, load average: 2.28, 1.51, 1.24 Tasks: 372 total, 1 running, 371 sleeping, 0 stopped, 0 zombie %Cpu(s): 4.6 us, 0.1 sy, 0.0 ni, 95.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65772144 total, 7317380 free, 54500600 used, 3954164 buff/cache KiB Swap: 0 total, 0 free, 0 used. 10777744 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 20073 root 20 0 64.803g 0.049t 14944 S 62.5 80.4 483:46.18 java 11669 root 20 0 148356 2152 1384 R 6.2 0.0 0:00.01 top 17433 root 20 0 978192 35864 5000 S 6.2 0.1 21:02.36 python 1 root 20 0 49520 11668 2064 S 0.0 0.0 9:13.75 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.34 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:02.20 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:01.77 migration/0 |
可知,scan读状态下主要消耗的是系统的内存,达到了80%以上将近52G,但cpu占用很低。
(2)带宽
| [Tue Sep 13 02:44:08 CST 2016] IN: 1389094904Bps(1324Mbps) OUT: 7091152Bps(6Mbps) [Tue Sep 13 02:44:09 CST 2016] IN: 1404023672Bps(1338Mbps) OUT: 7577184Bps(7Mbps) [Tue Sep 13 02:44:10 CST 2016] IN: 1508430248Bps(1438Mbps) OUT: 7674216Bps(7Mbps) [Tue Sep 13 02:44:11 CST 2016] IN: 1437603968Bps(1371Mbps) OUT: 7205992Bps(6Mbps) [Tue Sep 13 02:44:12 CST 2016] IN: 720413848Bps(687Mbps) OUT: 3720896Bps(3Mbps) [Tue Sep 13 02:44:13 CST 2016] IN: 1259848896Bps(1201Mbps) OUT: 6752184Bps(6Mbps) [Tue Sep 13 02:44:14 CST 2016] IN: 1291553552Bps(1231Mbps) OUT: 7213832Bps(6Mbps) [Tue Sep 13 02:44:15 CST 2016] IN: 1250500584Bps(1192Mbps) OUT: 6809800Bps(6Mbps) [Tue Sep 13 02:44:16 CST 2016] IN: 1245858144Bps(1188Mbps) OUT: 6811296Bps(6Mbps) [Tue Sep 13 02:44:17 CST 2016] IN: 1290120160Bps(1230Mbps) OUT: 6957832Bps(6Mbps) [Tue Sep 13 02:44:18 CST 2016] IN: 1309091656Bps(1248Mbps) OUT: 6893712Bps(6Mbps) [Tue Sep 13 02:44:19 CST 2016] IN: 1231891208Bps(1174Mbps) OUT: 6519600Bps(6Mbps) [Tue Sep 13 02:44:20 CST 2016] IN: 1200068072Bps(1144Mbps) OUT: 6494376Bps(6Mbps) [Tue Sep 13 02:44:21 CST 2016] IN: 1232850840Bps(1175Mbps) OUT: 6436968Bps(6Mbps) [Tue Sep 13 02:44:22 CST 2016] IN: 1248240840Bps(1190Mbps) OUT: 6216216Bps(5Mbps) [Tue Sep 13 02:44:23 CST 2016] IN: 1071171808Bps(1021Mbps) OUT: 5650304Bps(5Mbps) [Tue Sep 13 02:44:24 CST 2016] IN: 1268564440Bps(1209Mbps) OUT: 6902568Bps(6Mbps) [Tue Sep 13 02:44:25 CST 2016] IN: 1264221552Bps(1205Mbps) OUT: 6871656Bps(6Mbps) [Tue Sep 13 02:44:26 CST 2016] IN: 1256361264Bps(1198Mbps) OUT: 6637352Bps(6Mbps) |
此刻这台设备的IN带宽大概在1200~1300Mbps左右。
(3)ycsb配置
| # The thread count threadcount=300 #300个线程
# The number of fields in a record fieldcount=1
# The size of each field (in bytes) fieldlength=9216 #一条记录长度为9KB
# Number of Records will be loaded recordcount=20000000
# Number of Operations will be handle in run parsh operationcount=2000000 #scan操作2百万次 readallfields=true insertorder=hashed #insertstart=0 #insertcount=500000000
# Control Porption of hbase operation type readproportion=0 updateproportion=0 scanproportion=1 #完全scan操作 insertproportion=0
# The following param always be fixed # The table name table=usertable
# The colume family columnfamily=cf
# The workload class workload=com.yahoo.ycsb.workloads.CoreWorkload
# The measurement type measurementtype=raw
clientbuffering=true
writebuffersize=12582912
#requestdistribution=zipfian
maxscanlength=20000
#hbase.usepagefilter=false
#scanlengthdistribution=zipfian
requestdistribution=latest #请求最近读取过的数据,与LRU读缓存结合较好
|
4.1.3 Hbase节点状态
4台设备组成的hbase集群,这里选取其中1台的系统状态,其余3台的状态基本与选取的状态一致。
(1)Iostat
| 09/13/2016 02:44:54 AM avg-cpu: %user %nice %system %iowait %steal %idle 7.81 0.00 0.66 0.85 0.00 90.69
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdd 0.06 0.00 25.52 0.01 3.17 0.00 254.14 0.13 5.23 5.23 8.33 2.58 6.58 sda 0.00 0.29 0.02 2.25 0.00 0.02 16.64 0.01 3.13 11.54 3.05 1.85 0.42 sdc 0.11 0.00 29.00 0.00 3.76 0.00 265.38 0.19 6.69 6.69 0.00 2.97 8.61 sdb 0.12 0.00 30.55 0.11 4.14 0.00 276.66 0.21 6.80 6.80 7.08 2.91 8.92 sde 0.08 0.00 24.61 0.00 2.97 0.00 247.51 0.13 5.14 5.14 0.00 2.66 6.55 dm-0 0.00 0.00 0.02 1.26 0.00 0.01 12.47 0.00 2.81 11.54 2.66 1.24 0.16 dm-1 0.00 0.00 0.00 0.11 0.00 0.00 10.46 0.00 3.89 0.00 3.89 3.14 0.03 dm-2 0.00 0.00 0.00 1.06 0.00 0.01 19.57 0.00 3.40 0.00 3.40 2.20 0.23 |
可知,在读状态下,由于设置了较大的读缓存blockcache和scan本身的特性,所以对磁盘的io操作并不多。
(2)Top
[root@node1 ~]# top
| top - 02:42:14 up 6 days, 11:15, 5 users, load average: 1.35, 1.66, 1.81 Tasks: 401 total, 1 running, 394 sleeping, 6 stopped, 0 zombie %Cpu(s): 2.9 us, 0.4 sy, 0.0 ni, 96.3 id, 0.4 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65773904 total, 358628 free, 54028200 used, 11387076 buff/cache KiB Swap: 0 total, 0 free, 0 used. 11329324 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28879 hbase 20 0 52.267g 0.046t 29116 S 143.8 74.9 1346:45 java 18644 root 20 0 146272 2164 1352 R 6.2 0.0 0:00.01 top 1 root 20 0 45288 7428 1988 S 0.0 0.0 2:15.42 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.18 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.95 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:02.31 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh |
主要是内存的消耗,cpu占用不多,内存大小由用户维护的hbase-site.xml中的hbase_regionserver_heapsize决定,这里已接近用掉了50G的内存,很大一部分用作了读缓存。
(3)带宽
| [Tue Sep 13 02:44:11 CST 2016] IN: 22436840Bps(21Mbps) OUT: 1471864896Bps(1403Mbps) [Tue Sep 13 02:44:12 CST 2016] IN: 13982576Bps(13Mbps) OUT: 1353348496Bps(1290Mbps) [Tue Sep 13 02:44:13 CST 2016] IN: 41001296Bps(39Mbps) OUT: 1415041312Bps(1349Mbps) [Tue Sep 13 02:44:14 CST 2016] IN: 24540680Bps(23Mbps) OUT: 1251462792Bps(1193Mbps) [Tue Sep 13 02:44:15 CST 2016] IN: 23827832Bps(22Mbps) OUT: 1320654496Bps(1259Mbps) [Tue Sep 13 02:44:16 CST 2016] IN: 19069888Bps(18Mbps) OUT: 1281471968Bps(1222Mbps) [Tue Sep 13 02:44:17 CST 2016] IN: 40502944Bps(38Mbps) OUT: 1290429472Bps(1230Mbps) [Tue Sep 13 02:44:18 CST 2016] IN: 15378312Bps(14Mbps) OUT: 1298991384Bps(1238Mbps) [Tue Sep 13 02:44:19 CST 2016] IN: 23261504Bps(22Mbps) OUT: 1231679168Bps(1174Mbps) [Tue Sep 13 02:44:20 CST 2016] IN: 20102808Bps(19Mbps) OUT: 1205856648Bps(1149Mbps) [Tue Sep 13 02:44:21 CST 2016] IN: 27994376Bps(26Mbps) OUT: 1162188960Bps(1108Mbps) [Tue Sep 13 02:44:22 CST 2016] IN: 20662608Bps(19Mbps) OUT: 995859928Bps(949Mbps) [Tue Sep 13 02:44:23 CST 2016] IN: 31011776Bps(29Mbps) OUT: 1285450232Bps(1225Mbps) [Tue Sep 13 02:44:24 CST 2016] IN: 14276128Bps(13Mbps) OUT: 1127933176Bps(1075Mbps) [Tue Sep 13 02:44:25 CST 2016] IN: 50224704Bps(47Mbps) OUT: 1179008864Bps(1124Mbps) [Tue Sep 13 02:44:26 CST 2016] IN: 26989040Bps(25Mbps) OUT: 1386031752Bps(1321Mbps) [Tue Sep 13 02:44:27 CST 2016] IN: 26029776Bps(24Mbps) OUT: 1383180992Bps(1319Mbps) [Tue Sep 13 02:44:28 CST 2016] IN: 73159800Bps(69Mbps) OUT: 1392148184Bps(1327Mbps) [Tue Sep 13 02:44:29 CST 2016] IN: 27760800Bps(26Mbps) OUT: 1339476496Bps(1277Mbps) [Tue Sep 13 02:44:30 CST 2016] IN: 19761192Bps(18Mbps) OUT: 1207076944Bps(1151Mbps) [Tue Sep 13 02:44:31 CST 2016] IN: 19563336Bps(18Mbps) OUT: 1242348416Bps(1184Mbps) |
与ycsb client节点类似,此刻的OUT带宽在1200~1300Mbps左右。
4.2 Read操作
Read操作和scan操作有一些类似,都是客户端向hbase server端请求数据,不同的是read一次只请求一条,而scan一次可以请求多条即批量读取,因此scan操作对hbase client的内存有较高的要求。
在当前设备环境中,单台服务器上Ycsb client执行读read操作时,最多大约可以开启30000个threads。采用越多的ycsb threads的话,在真正对数据进行操作前的准备时间也就越长,会影响最终获得的每秒操作数。30000的threads大概read 20000t/s,带宽已达到极限1850Mb/s,测试结果如下:
|
|
分区数 |
value长度 |
速度 条/秒 |
集群节点数 |
ycsb client节点数 |
带宽 |
操作数 |
瓶颈 |
| 读取read |
200 regions |
9216bytes |
45000~50000左右 |
4 |
4 |
1100~1200Mb/s |
20000000 |
hbase clinet 内存 |
| 读取read |
200 regions |
9216bytes |
20000左右 |
4 |
1 |
1850Mb/s |
20000000 |
带宽 |
这里也选取了两个结果,第一个运行了4个ycsb client,第二个运行1个ycsb client很明显单个ycsb client进行read读取操作时的瓶颈在于带宽。
4.2.1 配置调优要点
Hbase本身提供了读缓存,具体可以查看上面hbase-site.xml文件解析,本集群环境中每个regionserver可提供最多40G左右的读缓存。
简单介绍下Hbase读操作read的原理,首先去memstore中查找,查不到就在读缓存blockcache中查找,再查不到就去hdfs也就是硬盘中查,并且将查到的结果放置在读缓存blockcache中以便下次查找。Blockcache是一个LRU,当blockcache达到上限(heapsize*hfile.block.cache.size*0.85)时,会启动淘汰机制,淘汰掉最老的一批数据。
Scan操作可以设置每次scan取到的条数,一次读的越大每条数据消耗的RPC也就越少,性能也就相应会提高,但是设置的越大对内存的要求也就越高,应根据实际设备性能调整大小。
(1)hadoop配置
这里介绍几个关键配置:
#分配1%的regionserver的内存给写操作当作缓存,这个参数和下面的hfile.block.cache.size(读缓存)息息相关,二者之和不能超过总内存的80%,读操作时,该值最好为0,但是这里有个bug,取不到0,所以取值1%即0.01,系统尽可能的把内存给读操作用作缓存。
#将regionserver的内存的79%分配作为读缓存,默认是40%,这里因为是单独的读操作性能调优所以调到了79%,上文中提到了一个bug,不能调为最高的80%。该配置项与上文中的hbase.regionserver.global.memstore.size关系密切,二者的总和不能大于regionserver内存的80%,读操作为主时就将该值调高,写操作为主时就将hbase.regionserver.global.memstore.size调高。
(2)ycsb配置
Ycsb 配置文件关键项:
##ycsb 配置文件节选
requestdistribution=latest #数据请求模式,最近访问的数据,非等概率与LRU缓存结合较好
##ycsb 配置文件节选
4.2.2 ycsb client状态
一共有4个ycsb client节点,四个系统状态基本一致,可能在某些参数上有少许差别,ycsbclient上没有对磁盘进行操作,所以没有记录iostat命令
这里的话ycsb client的thread数几乎已经到了极限(20000、30000)。下面分析的是跑了4个ycsb client的情况,单独1个ycsb client暂不分析。
(1)top
| top - 16:28:13 up 71 days, 7:20, 6 users, load average: 3.52, 3.50, 3.17 Tasks: 395 total, 1 running, 394 sleeping, 0 stopped, 0 zombie %Cpu(s): 2.0 us, 0.4 sy, 0.0 ni, 97.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65772144 total, 28988184 free, 30913756 used, 5870204 buff/cache KiB Swap: 33030140 total, 32722816 free, 307324 used. 34177996 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4721 root 20 0 82.531g 0.021t 14956 S 288.9 33.8 95:40.78 java 1985 root 20 0 148356 2148 1384 R 11.1 0.0 0:00.03 top 8520 hbase 20 0 505952 8864 2624 S 5.6 0.0 707:06.23 python2.7 24980 yarn 20 0 2069392 337560 24480 S 5.6 0.5 20:29.57 java 1 root 20 0 203556 18160 2144 S 0.0 0.0 17:05.19 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:01.37 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:07.33 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H |
由上可知,read操作对于cpu和内存的压力都不是很大。
(2)带宽
| [Tue Sep 13 16:28:04 CST 2016] IN: 1090692056Bps(1040Mbps) OUT: 28791808Bps(27Mbps) [Tue Sep 13 16:28:05 CST 2016] IN: 1050596840Bps(1001Mbps) OUT: 27955120Bps(26Mbps) [Tue Sep 13 16:28:06 CST 2016] IN: 1455753528Bps(1388Mbps) OUT: 37571904Bps(35Mbps) [Tue Sep 13 16:28:07 CST 2016] IN: 1431038136Bps(1364Mbps) OUT: 36814408Bps(35Mbps) [Tue Sep 13 16:28:08 CST 2016] IN: 87732120Bps(83Mbps) OUT: 52472Bps(0Mbps) [Tue Sep 13 16:28:09 CST 2016] IN: 58797728Bps(56Mbps) OUT: 1438416Bps(1Mbps) [Tue Sep 13 16:28:10 CST 2016] IN: 1630987592Bps(1555Mbps) OUT: 42776208Bps(40Mbps) [Tue Sep 13 16:28:11 CST 2016] IN: 771773360Bps(736Mbps) OUT: 19205928Bps(18Mbps) [Tue Sep 13 16:28:12 CST 2016] IN: 1240965184Bps(1183Mbps) OUT: 32610560Bps(31Mbps) [Tue Sep 13 16:28:13 CST 2016] IN: 1310319648Bps(1249Mbps) OUT: 33690016Bps(32Mbps) [Tue Sep 13 16:28:14 CST 2016] IN: 1481654992Bps(1413Mbps) OUT: 38381168Bps(36Mbps) [Tue Sep 13 16:28:15 CST 2016] IN: 1342465440Bps(1280Mbps) OUT: 35507448Bps(33Mbps) [Tue Sep 13 16:28:16 CST 2016] IN: 991861888Bps(945Mbps) OUT: 25188448Bps(24Mbps) [Tue Sep 13 16:28:17 CST 2016] IN: 1455500744Bps(1388Mbps) OUT: 38124632Bps(36Mbps) [Tue Sep 13 16:28:18 CST 2016] IN: 1562847648Bps(1490Mbps) OUT: 40131136Bps(38Mbps) [Tue Sep 13 16:28:19 CST 2016] IN: 1353514144Bps(1290Mbps) OUT: 34863296Bps(33Mbps) [Tue Sep 13 16:28:20 CST 2016] IN: 990938744Bps(945Mbps) OUT: 25207296Bps(24Mbps) [Tue Sep 13 16:28:21 CST 2016] IN: 1352270600Bps(1289Mbps) OUT: 36755976Bps(35Mbps) [Tue Sep 13 16:28:22 CST 2016] IN: 1342217736Bps(1280Mbps) OUT: 35219184Bps(33Mbps) |
总体带宽平均在1100Mbps左右。
(3)ycsb 配置
| # The thread count threadcount=20000 #起2万个线程,当前环境最多起30000个左右
# The number of fields in a record fieldcount=1
# The size of each field (in bytes) fieldlength=9216 #一条数据长度为9KB
# Number of Records will be loaded recordcount=20000000
# Number of Operations will be handle in run parsh operationcount=20000000 #读取2千万条数据 readallfields=true insertorder=hashed #insertstart=0 #insertcount=500000000
# Control Porption of hbase operation type readproportion=1 updateproportion=0 scanproportion=0 insertproportion=0
# The following param always be fixed # The table name table=usertable
# The colume family columnfamily=cf
# The workload class workload=com.yahoo.ycsb.workloads.CoreWorkload
# The measurement type measurementtype=raw
clientbuffering=true
writebuffersize=12582912
#requestdistribution=zipfian
maxscanlength=20000
#hbase.usepagefilter=false
#scanlengthdistribution=zipfian
requestdistribution=latest #数据请求模式,最近访问的数据,非等概率与LRU缓存结合较好 |
4.2.3 hbase节点状态
4台设备组成的hbase集群,这里选取其中1台的系统状态,其余3台的状态基本与选取的状态一致。
(1) iostat
| 09/13/2016 04:28:36 PM avg-cpu: %user %nice %system %iowait %steal %idle 13.57 0.00 1.45 21.11 0.00 63.86
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdd 0.12 0.00 70.17 0.05 10.23 0.00 298.41 4.99 71.00 71.04 23.33 9.24 64.90 sda 0.00 0.20 0.05 1.98 0.00 0.02 16.52 0.01 2.49 0.33 2.55 1.82 0.37 sdc 0.05 0.00 75.37 0.05 11.14 0.00 302.59 6.68 88.59 88.54 164.33 9.15 69.03 sdb 0.05 0.00 67.18 0.05 9.83 0.00 299.35 4.13 61.34 61.36 30.00 8.91 59.90 sde 0.02 0.00 62.60 0.13 9.19 0.00 300.02 2.51 40.07 40.11 21.25 7.88 49.42 dm-0 0.00 0.00 0.05 1.10 0.00 0.01 12.06 0.00 1.30 0.33 1.35 0.99 0.11 dm-1 0.00 0.00 0.00 0.05 0.00 0.00 8.00 0.00 6.00 0.00 6.00 6.00 0.03 dm-2 0.00 0.00 0.00 0.93 0.00 0.01 20.71 0.00 3.59 0.00 3.59 2.43 0.23 |
可知,4块hdfs磁盘的读压力不是很大,这是因为设置了较大的LRU缓存。
(2)top
| top - 16:28:44 up 7 days, 1:02, 5 users, load average: 26.92, 70.49, 67.85 Tasks: 419 total, 2 running, 411 sleeping, 6 stopped, 0 zombie %Cpu(s): 3.5 us, 0.4 sy, 0.0 ni, 95.4 id, 0.7 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65773904 total, 432196 free, 53853744 used, 11487964 buff/cache KiB Swap: 0 total, 0 free, 0 used. 11494572 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28879 hbase 20 0 52.273g 0.046t 6756 S 1819 74.9 3266:44 java 28970 ambari-+ 20 0 4843484 20372 8148 S 75.0 0.0 0:00.13 java 1184 root 20 0 4372 584 488 S 12.5 0.0 117:57.11 rngd 2941 root 20 0 2273740 43784 2972 S 6.2 0.1 341:08.54 python 29452 root 20 0 146408 2188 1352 R 6.2 0.0 0:00.02 top 1 root 20 0 45700 7776 1964 S 0.0 0.0 2:24.08 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.20 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:01.14 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:02.69 migration/0 |
可知,hbase server节点的内存占用较高,这是因为我们手动配置了较多的内存,cpu的话占用并不多。
(3)带宽
| [Tue Sep 13 16:28:35 CST 2016] IN: 22483256Bps(21Mbps) OUT: 661447256Bps(630Mbps) [Tue Sep 13 16:28:36 CST 2016] IN: 23613704Bps(22Mbps) OUT: 656564224Bps(626Mbps) [Tue Sep 13 16:28:37 CST 2016] IN: 22772616Bps(21Mbps) OUT: 647350776Bps(617Mbps) [Tue Sep 13 16:28:38 CST 2016] IN: 18973704Bps(18Mbps) OUT: 605782640Bps(577Mbps) [Tue Sep 13 16:28:39 CST 2016] IN: 20327680Bps(19Mbps) OUT: 632839840Bps(603Mbps) [Tue Sep 13 16:28:40 CST 2016] IN: 25086640Bps(23Mbps) OUT: 883033808Bps(842Mbps) [Tue Sep 13 16:28:41 CST 2016] IN: 22399624Bps(21Mbps) OUT: 670929048Bps(639Mbps) [Tue Sep 13 16:28:42 CST 2016] IN: 20382304Bps(19Mbps) OUT: 656173848Bps(625Mbps) [Tue Sep 13 16:28:43 CST 2016] IN: 22866432Bps(21Mbps) OUT: 612133800Bps(583Mbps) [Tue Sep 13 16:28:44 CST 2016] IN: 8875152Bps(8Mbps) OUT: 55318144Bps(52Mbps) [Tue Sep 13 16:28:45 CST 2016] IN: 22386368Bps(21Mbps) OUT: 476991368Bps(454Mbps) [Tue Sep 13 16:28:46 CST 2016] IN: 24189632Bps(23Mbps) OUT: 872880840Bps(832Mbps) [Tue Sep 13 16:28:47 CST 2016] IN: 6160408Bps(5Mbps) OUT: 208640776Bps(198Mbps) [Tue Sep 13 16:28:48 CST 2016] IN: 12127112Bps(11Mbps) OUT: 598652792Bps(570Mbps) [Tue Sep 13 16:28:49 CST 2016] IN: 21815088Bps(20Mbps) OUT: 813550904Bps(775Mbps) [Tue Sep 13 16:28:50 CST 2016] IN: 15003336Bps(14Mbps) OUT: 705601072Bps(672Mbps) [Tue Sep 13 16:28:51 CST 2016] IN: 20196840Bps(19Mbps) OUT: 693023464Bps(660Mbps) [Tue Sep 13 16:28:52 CST 2016] IN: 12980888Bps(12Mbps) OUT: 459208480Bps(437Mbps) [Tue Sep 13 16:28:53 CST 2016] IN: 14621152Bps(13Mbps) OUT: 433819432Bps(413Mbps) [Tue Sep 13 16:28:54 CST 2016] IN: 9265656Bps(8Mbps) OUT: 14933976Bps(14Mbps) |
此刻的带宽基本在700Mbps左右。
5 写性能测试与调优
利用ycsb工具进行写性能测试的话,其实就是先建立空表然后执行ycsb 的load阶段即可,具体方案的话分为单个节点写入和多个节点写入。
5.1 单节点写入
只执行一个yscb client进行写入操作。测试的结果如下:
| 分区数 |
value长度 |
速度 条/秒 |
集群节点数 |
ycsb client节点数 |
带宽 |
操作数 |
瓶颈 |
|
| 插入insert |
200 regions |
9216bytes |
11000左右 |
4 |
1 |
1200Mb/s 不稳定 |
5000000 |
ycsb client cpu、磁盘IO |
| 插入insert |
200 regions |
9216bytes |
9000左右 |
4 |
1 |
1000Mb/s 不稳定 |
40000000 |
ycsb client cpu、磁盘IO |
这里保存了2次单点插入的结果,第一次这里只作为结果对比,第一次与第二次的配置除了写入条数有较大差异之外,其他几乎相同,我分析的原因是写入时间越久,rpc消耗越多,磁盘flush延时越久,hbase本身的compaction和spilts操作以及jvm GC操作也就越多这些操作是很消耗系统性能的。因此写入时间越长,性能相应的也会下降一些,所以第二次插入40000000条结果只有9000sec/opc。
5.1.1 配置调优要点
本次测试一条数据长度为9KB,共写入40000000条,大概有1TB左右,集群总共是200个region,每个region大小为默认的10G,集群总大小为2TB。集群总量足够,rowkey分布均匀的话不会发生集群的splits操作。
(1)这里简单介绍下hbase 写流程和原理:
客户端流程解析:
a) 用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过 AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用groupcommit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
b) 在提交之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照 HRegionLocation分组,每个分组可以对应一次RPC请求。
c) HBase会为每个HRegionLocation构造一个远程RPC请求 MultiServerCallable
服务器端流程解析
a) 服务器端RegionServer接收到客户端的写入请求后,首先会反序列化为Put对象,然后执行各种检查操作,比如检查region是否是只读、memstore大小是否超过blockingMemstoreSize等。检查完成之后,就会执行如下核心操作:

b) 获取行锁、Region更新共享锁:HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。
c) 开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。
d) 写缓存memstore:HBase中每列都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
e) Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升。
f) 释放行锁以及共享锁
g) Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
h) 结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。
i) flush memstore:当写缓存满256M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构可参考相关资料,这里不细说。
(2)hadoop配置
#当一个region的memstore总量达到hbase.hregion.memstore.block.multiplier* hbase.hregion.memstore.flush.size (默认2*128M)时,会阻塞这个region的写操作,并强制刷写到HFile,触发这个刷新操作只会在Memstore即将写满hbase.hregion.memstore.flush.size时put了一个巨大的记录的情况,这时候会阻塞写操作,强制刷新成功才能继续写入。
该配置项默认为2,调大至8,降低block发生的概率。
#每个单独的memstore的大小(默认128M),这里调成了256M,每个列族columnfamily在每个region中都分配有它单独的memstore,当memstore超过该值时,就会发生flush操作,将memstore中的内容刷成一个hfile,每一次memstore的flush操作,都会为每一次columnfamily创建一个新的hfile;调高该值可以减少flush的操作次数,减少每一个region中的hfile的个数,这样就会减少minor compaction的次数和split的次数,从而降低了系统性能损耗,提升了写性能,也提升了读性能(因为读操作的时候,首先要去memstore中查数据,查找不到的话再去hfile,hflie存储在hdfs中,这就涉及到了对性能要求较高的io操作了)。当然这个值变大了之后,每次flush操作带来的性能消耗也就更大。
#分配75%的regionserver的内存给写操作当作缓存,这个参数和下面的hfile.block.cache.size(读缓存)息息相关,二者之和不能超过总内存的80%,追求写入性能时,该值尽量设置的大一些;追求读操作性能时,该值尽量取得小一些,但这里有个bug,该值取不到0,现将该值设置为0.75。
#与上面相呼应,将regionserver的内存的5%分配作为读缓存,默认是40%,上文中提到了一个bug,不能调为最高的80%。该配置项与上文中的hbase.regionserver.global.memstore.size关系密切,二者的总和不能大于regionserver内存的80%,读操作为主时就将该值调高,写操作为主时就将hbase.regionserver.global.memstore.size调高。
其他的配置的话基本上都已调到了最大值,上文中hadoop配置都有介绍,不了解的话可以翻看前文内容。
(3)ycsb配置
#ycsb配置文件节选
insertorder=hashed #前面提到过,建表的时候采用的是预分区和rowkey均匀分布,所以这里插入的顺序需要配置成较为随机的hashed模式而非默认的order模式
clientbuffering=true #没有关闭auto flush,而是打开了ycsb端的缓存,效果和原理是一样的
writebuffersize=12582912 #默认就是12MB,试过了多个数据大小,12MB性能最好
#ycsb配置文件节选
(4)其他配置说明
这里没有关闭wal机制(其实是指wal中的写hlog)以获得更好的性能,一是因为暂时没在hbase-site.xml中找到相应配置项(可通过代码中调用wal的相关api来实现);二是因为在实际使用中必须要用到wal以保证hbase的可靠性。
另外建表时采用的预分区和rowkey随机分布模式对写入性能也很关键。
5.1.2 Ycsb client状态
由于ycsb client上只进行了对hbase集群的插入操作,它本身不涉及到硬盘相关的操作,所以未记录iostat的数据。
(1) Top
| top - 20:00:21 up 63 days, 9:36, 8 users, load average: 58.52, 57.87, 54.67 Tasks: 389 total, 2 running, 387 sleeping, 0 stopped, 0 zombie %Cpu(s): 4.0 us, 0.2 sy, 0.0 ni, 95.8 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65772144 total, 28196656 free, 18563928 used, 19011560 buff/cache KiB Swap: 0 total, 0 free, 0 used. 46689236 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 575 root 20 0 29.235g 0.016t 15004 S 2229 25.7 853:18.36 java 33 root 20 0 0 0 0 S 5.9 0.0 44:18.02 rcu_sched 30866 root 20 0 148356 2208 1384 R 5.9 0.0 0:00.02 top 1 root 20 0 50712 12892 2064 S 0.0 0.0 12:22.47 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.41 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:03.16 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:01.97 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh |
可见ycsb client设备上cpu几乎已经用完,而内存占用不高,瓶颈之一便是ycsb客户端的cpu。
(2) Ycsb 配置
| # The thread count threadcount=60 #写入时线程数不能设置太多,否则cpu长期占用太高
# The number of fields in a record fieldcount=1
# The size of each field (in bytes) fieldlength=9216
# Number of Records will be loaded recordcount=40000000
# Number of Operations will be handle in run parsh operationcount=40000000 readallfields=true insertorder=hashed #insertstart=0 #insertcount=500000000
# Control Porption of hbase operation type readproportion=1 updateproportion=0 scanproportion=0 insertproportion=0
# The following param always be fixed # The table name table=a
# The colume family columnfamily=cf
# The workload class workload=com.yahoo.ycsb.workloads.CoreWorkload
# The measurement type measurementtype=raw
clientbuffering=true #开启ycsb client缓存
writebuffersize=12582912 #缓存大小为12MB,即写满12MB之后才提交一次put
requestdistribution=latest
maxscanlength=30000
#hbase.usepagefilter=false
#scanlengthdistribution=zipfian
#requestdistribution=zipfian |
(3) 带宽
| [Mon Sep 26 20:00:11 CST 2016] IN: 4988752Bps(4Mbps) OUT: 839334032Bps(800Mbps) [Mon Sep 26 20:00:12 CST 2016] IN: 6514928Bps(6Mbps) OUT: 1088183680Bps(1037Mbps) [Mon Sep 26 20:00:14 CST 2016] IN: 8717768Bps(8Mbps) OUT: 1410373848Bps(1345Mbps) [Mon Sep 26 20:00:15 CST 2016] IN: 929808Bps(0Mbps) OUT: 101317320Bps(96Mbps) [Mon Sep 26 20:00:16 CST 2016] IN: 3039288Bps(2Mbps) OUT: 505524416Bps(482Mbps) [Mon Sep 26 20:00:17 CST 2016] IN: 4603112Bps(4Mbps) OUT: 709229680Bps(676Mbps) [Mon Sep 26 20:00:18 CST 2016] IN: 5055904Bps(4Mbps) OUT: 836841368Bps(798Mbps) [Mon Sep 26 20:00:19 CST 2016] IN: 4320296Bps(4Mbps) OUT: 600734144Bps(572Mbps) [Mon Sep 26 20:00:20 CST 2016] IN: 5017200Bps(4Mbps) OUT: 690111416Bps(658Mbps) [Mon Sep 26 20:00:22 CST 2016] IN: 1684920Bps(1Mbps) OUT: 186839352Bps(178Mbps) [Mon Sep 26 20:00:23 CST 2016] IN: 4994136Bps(4Mbps) OUT: 724239776Bps(690Mbps) [Mon Sep 26 20:00:24 CST 2016] IN: 1762232Bps(1Mbps) OUT: 202245440Bps(192Mbps) [Mon Sep 26 20:00:25 CST 2016] IN: 5015744Bps(4Mbps) OUT: 809145376Bps(771Mbps) [Mon Sep 26 20:00:26 CST 2016] IN: 10445648Bps(9Mbps) OUT: 1724724832Bps(1644Mbps) [Mon Sep 26 20:00:27 CST 2016] IN: 5497880Bps(5Mbps) OUT: 891578624Bps(850Mbps) [Mon Sep 26 20:00:28 CST 2016] IN: 5338080Bps(5Mbps) OUT: 900875672Bps(859Mbps) [Mon Sep 26 20:00:29 CST 2016] IN: 6025912Bps(5Mbps) OUT: 939329000Bps(895Mbps) [Mon Sep 26 20:00:31 CST 2016] IN: 4176824Bps(3Mbps) OUT: 599762176Bps(571Mbps) |
可见,ycsb client 的out带宽最高能达到1644Mbps的极限值,最低也有96Mbps,写入时由于写入机制的原因,所以带宽起伏比较大,在某些时候,带宽也可能成为瓶颈。
5.1.3 Hbase 节点状态
在本集群中Hbase client 一共有4个,由于负载均衡的原因,4台设备的情况差不多,所以这里只取其中一台来做简单分析。
(1) Top
| top - 20:00:45 up 24 days, 3:37, 8 users, load average: 3.41, 3.91, 3.45 Tasks: 400 total, 1 running, 399 sleeping, 0 stopped, 0 zombie %Cpu(s): 2.7 us, 0.3 sy, 0.0 ni, 96.6 id, 0.5 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65773904 total, 399556 free, 49904428 used, 15469920 buff/cache KiB Swap: 0 total, 0 free, 0 used. 15470316 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 16637 hdfs 20 0 13.277g 467696 5788 S 150.0 0.7 164:58.31 java 17860 ams 20 0 13.394g 798188 5852 S 50.0 1.2 458:36.00 java 24800 hbase 20 0 52.121g 0.041t 5728 S 43.8 66.9 119:11.18 java 1158 root 20 0 4372 472 376 S 18.8 0.0 264:00.04 rngd 17799 ams 20 0 2585248 1.690g 5856 S 12.5 2.7 1458:47 java 51 root 20 0 0 0 0 S 6.2 0.0 1:49.17 rcuos/17 188 root 20 0 0 0 0 S 6.2 0.0 31:05.79 kswapd0 26517 root 20 0 0 0 0 D 6.2 0.0 0:11.29 kworker/u48:4 1 root 20 0 43420 5072 1528 S 0.0 0.0 3:51.31 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.63 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:03.68 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:03.74 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh |
可见hbase client上hdfs和hbase的cpu和内存都处于正常范围内(与我们配置的值一致)。
(2) Iostat
| 09/26/2016 08:00:36 PM avg-cpu: %user %nice %system %iowait %steal %idle 5.26 0.00 4.01 5.79 0.00 84.94
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdb 1.10 0.67 37.12 79.18 2.05 38.42 712.62 57.97 508.18 11.39 741.05 4.20 48.90 sda 0.12 0.47 5.85 4.22 0.22 0.11 67.93 0.08 7.75 8.30 6.99 2.02 2.04 sdc 1.00 0.58 70.77 79.35 5.43 38.67 601.68 60.85 405.38 4.69 762.73 3.42 51.30 sdd 1.92 0.53 26.80 73.68 3.59 35.83 803.44 54.24 539.81 6.80 733.67 4.60 46.24 sde 1.58 1.02 30.90 76.40 4.07 37.06 784.91 44.08 410.85 5.58 574.76 3.70 39.66 dm-0 0.00 0.00 4.70 3.48 0.15 0.10 62.45 0.05 6.58 6.65 6.48 1.78 1.46 dm-1 0.00 0.00 0.00 0.12 0.00 0.00 10.29 0.00 21.71 0.00 21.71 8.29 0.10 dm-2 0.00 0.00 1.27 0.90 0.07 0.01 79.20 0.03 11.90 15.18 7.28 4.68 1.01 |
Hdfs的datanode目录磁盘是sdb、sdc、sdd和sde,可见在这一时刻磁盘的写性能还没有完全达到瓶颈(这里是一分钟统计一次,在实际写入的过程中磁盘其实性能很多时刻已经接近瓶颈了)。
(3) 带宽
| [Mon Sep 26 20:00:31 CST 2016] IN: 1210087048Bps(1154Mbps) OUT: 1245843600Bps(1188Mbps) [Mon Sep 26 20:00:32 CST 2016] IN: 1122776616Bps(1070Mbps) OUT: 1108381680Bps(1057Mbps) [Mon Sep 26 20:00:33 CST 2016] IN: 971949568Bps(926Mbps) OUT: 843617520Bps(804Mbps) [Mon Sep 26 20:00:34 CST 2016] IN: 927039152Bps(884Mbps) OUT: 849902544Bps(810Mbps) [Mon Sep 26 20:00:35 CST 2016] IN: 366340304Bps(349Mbps) OUT: 381034384Bps(363Mbps) [Mon Sep 26 20:00:36 CST 2016] IN: 399862576Bps(381Mbps) OUT: 471332992Bps(449Mbps) [Mon Sep 26 20:00:37 CST 2016] IN: 413687768Bps(394Mbps) OUT: 391028384Bps(372Mbps) [Mon Sep 26 20:00:38 CST 2016] IN: 680225704Bps(648Mbps) OUT: 431916984Bps(411Mbps) [Mon Sep 26 20:00:39 CST 2016] IN: 780438024Bps(744Mbps) OUT: 438607464Bps(418Mbps) [Mon Sep 26 20:00:40 CST 2016] IN: 958073136Bps(913Mbps) OUT: 308162872Bps(293Mbps) [Mon Sep 26 20:00:41 CST 2016] IN: 615614080Bps(587Mbps) OUT: 163420880Bps(155Mbps) [Mon Sep 26 20:00:42 CST 2016] IN: 838286960Bps(799Mbps) OUT: 407006984Bps(388Mbps) [Mon Sep 26 20:00:43 CST 2016] IN: 1202815176Bps(1147Mbps) OUT: 869450448Bps(829Mbps) [Mon Sep 26 20:00:44 CST 2016] IN: 1496259744Bps(1426Mbps) OUT: 1058140352Bps(1009Mbps) [Mon Sep 26 20:00:45 CST 2016] IN: 1737074056Bps(1656Mbps) OUT: 1441636832Bps(1374Mbps) [Mon Sep 26 20:00:46 CST 2016] IN: 1560269944Bps(1487Mbps) OUT: 1162835360Bps(1108Mbps) [Mon Sep 26 20:00:47 CST 2016] IN: 1112355128Bps(1060Mbps) OUT: 1107538248Bps(1056Mbps) [Mon Sep 26 20:00:48 CST 2016] IN: 956544592Bps(912Mbps) OUT: 757010040Bps(721Mbps) [Mon Sep 26 20:00:49 CST 2016] IN: 937077248Bps(893Mbps) OUT: 413743160Bps(394Mbps) [Mon Sep 26 20:00:50 CST 2016] IN: 602041384Bps(574Mbps) OUT: 66556848Bps(63Mbps) [Mon Sep 26 20:00:51 CST 2016] IN: 753859744Bps(718Mbps) OUT: 454967144Bps(433Mbps) |
这一时刻Hbase client的in带宽平均在900~1000Mbps左右,out带宽在500Mbs左右,由于写入机制的原因,所以带宽表现很不稳定,所以在某些时刻,带宽也可能成为瓶颈。
5.2 多节点写入
集群一共有四个节点,ycsb client多节点写入时,这里也配置了4个节点写入,测试的结果表名,4个ycsb client的各项性能数据是几乎是一样的(具体性能数据可以查看附录中给出的测试过程记录文件)。
测试结果:
| 分区数 |
value长度 |
速度 条/秒 |
集群节点数 |
ycsb client节点数 |
带宽 |
操作数 |
瓶颈 |
|
| 插入insert |
200 regions |
9216bytes |
9100左右 |
4 |
4 |
1000Mb/s 不稳定 |
40000000 |
ycsb client cpu、磁盘IO |
5.2.1 配置调优要点
多节点写入和单节点写入配置要点除了ycsb配置文件有不同外其他均相同,这里只介绍ycsb配置文件中需要注意的点。
4个ycsb client写入,每个节点写入10000000条。
##ycsb配置文件
# Number of Records will be loaded
recordcount=40000000 #总共写入40000000条
# Number of Operations will be handle in run parsh
operationcount=40000000
readallfields=true
insertorder=hashed
insertstart=0 #第一个写入的节点从第0条开始写
insertcount=10000000 #每个ycsb client只写入10000000条
##ycsb配置文件
5.2.2 Ycsb client状态
由于ycsb client上只进行了对hbase集群的插入操作,它本身不涉及到硬盘相关的操作,所以未记录iostat的数据。
上文说过,4个ycsb client性能数据都是一致的,所以这里只选择其中一台分析。
(1) top
| top - 12:00:57 up 64 days, 1:37, 8 users, load average: 28.11, 28.21, 28.40 Tasks: 386 total, 2 running, 384 sleeping, 0 stopped, 0 zombie %Cpu(s): 4.0 us, 0.2 sy, 0.0 ni, 95.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65772144 total, 33683104 free, 13066860 used, 19022180 buff/cache KiB Swap: 0 total, 0 free, 0 used. 52188600 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 31443 root 20 0 29.227g 0.011t 15016 S 2276 17.4 1251:05 java 17433 root 20 0 1051924 36208 5000 S 17.6 0.1 439:39.24 python 39 root 20 0 0 0 0 S 5.9 0.0 6:21.77 rcuos/5 32074 root 20 0 113252 1572 1264 S 5.9 0.0 0:04.43 sh 1 root 20 0 50812 12980 2064 S 0.0 0.0 12:31.21 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.41 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:03.17 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:02.00 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh |
Cpu占用几乎已达到了极限,内存占用很少,瓶颈是ycsb client上的cpu。
(2) 带宽
| [Tue Sep 27 12:00:48 CST 2016] IN: 45232Bps(0Mbps) OUT: 5504Bps(0Mbps) [Tue Sep 27 12:00:49 CST 2016] IN: 42608Bps(0Mbps) OUT: 0Bps(0Mbps) [Tue Sep 27 12:00:50 CST 2016] IN: 19712Bps(0Mbps) OUT: 2656Bps(0Mbps) [Tue Sep 27 12:00:51 CST 2016] IN: 752960Bps(0Mbps) OUT: 101177576Bps(96Mbps) [Tue Sep 27 12:00:52 CST 2016] IN: 871192Bps(0Mbps) OUT: 100964520Bps(96Mbps) [Tue Sep 27 12:00:54 CST 2016] IN: 749272Bps(0Mbps) OUT: 101177000Bps(96Mbps) [Tue Sep 27 12:00:55 CST 2016] IN: 2500864Bps(2Mbps) OUT: 404391184Bps(385Mbps) [Tue Sep 27 12:00:56 CST 2016] IN: 755264Bps(0Mbps) OUT: 100997440Bps(96Mbps) [Tue Sep 27 12:00:57 CST 2016] IN: 1980824Bps(1Mbps) OUT: 303891608Bps(289Mbps) [Tue Sep 27 12:00:58 CST 2016] IN: 1267472Bps(1Mbps) OUT: 215759664Bps(205Mbps) [Tue Sep 27 12:00:59 CST 2016] IN: 2814136Bps(2Mbps) OUT: 492450312Bps(469Mbps) [Tue Sep 27 12:01:00 CST 2016] IN: 3533136Bps(3Mbps) OUT: 506166008Bps(482Mbps) [Tue Sep 27 12:01:01 CST 2016] IN: 2232616Bps(2Mbps) OUT: 303978808Bps(289Mbps) [Tue Sep 27 12:01:02 CST 2016] IN: 64312Bps(0Mbps) OUT: 528Bps(0Mbps) [Tue Sep 27 12:01:04 CST 2016] IN: 736720Bps(0Mbps) OUT: 183792Bps(0Mbps) [Tue Sep 27 12:01:05 CST 2016] IN: 103144Bps(0Mbps) OUT: 3504Bps(0Mbps) [Tue Sep 27 12:01:06 CST 2016] IN: 1304368Bps(1Mbps) OUT: 190653920Bps(181Mbps) |
可见out的带宽占用很少,很多时候带宽为0,由于写hbase机制的原因导致写入的时候性能不够稳定,且在总的每秒能够写入的条数既定的情况下,平均分给每个ycsb client的数目就比较少了。
(3) ycsb配置
| # The thread count threadcount=30 #写入不能设的太大,否则容易出现写错误,导致写入数据不完整影响后续的run操作
# The number of fields in a record fieldcount=1
# The size of each field (in bytes) fieldlength=9216
# Number of Records will be loaded recordcount=40000000
# Number of Operations will be handle in run parsh operationcount=40000000 readallfields=true insertorder=hashed insertstart=0 insertcount=10000000 #每个ycsb client只写入10000000条
# Control Porption of hbase operation type readproportion=1 updateproportion=0 scanproportion=0 insertproportion=0
# The following param always be fixed # The table name table=a
# The colume family columnfamily=cf
# The workload class workload=com.yahoo.ycsb.workloads.CoreWorkload
# The measurement type measurementtype=raw
clientbuffering=true
writebuffersize=12582912
requestdistribution=latest
maxscanlength=30000
#hbase.usepagefilter=false
#scanlengthdistribution=zipfian
#requestdistribution=zipfian |
5.2.3 Hbase 节点状态
Hbase 集群中的4个节点由于负载均衡的缘故,每个节点性能数据也不会有太大差别,这里也只选取其中一个分析。
(1) Iostat
| 09/27/2016 12:00:38 PM avg-cpu: %user %nice %system %iowait %steal %idle 7.43 0.00 4.34 6.83 0.00 81.40
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdb 1.18 0.75 50.62 86.05 6.29 41.78 720.25 96.77 687.11 15.31 1082.27 5.21 71.25 sda 0.10 1.20 14.17 7.03 0.71 0.12 79.83 0.21 10.05 4.99 20.23 1.49 3.16 sdc 0.72 0.85 20.57 92.98 2.66 45.39 866.68 68.79 616.00 7.34 750.63 5.23 59.40 sdd 1.37 0.80 74.12 93.70 4.48 45.63 611.55 73.64 438.84 11.48 776.88 3.50 58.80 sde 0.60 0.68 24.55 81.77 3.14 39.91 829.34 45.93 424.30 4.17 550.44 3.85 40.95 dm-0 0.00 0.00 11.60 7.03 0.59 0.11 77.04 0.21 11.32 3.43 24.34 1.19 2.22 dm-1 0.00 0.00 0.00 0.12 0.00 0.00 10.29 0.00 2.14 0.00 2.14 1.57 0.02 dm-2 0.00 0.00 2.67 0.90 0.12 0.01 71.66 0.04 10.36 12.23 4.80 3.10 1.11 |
Hdfs的datanode目录磁盘是sdb、sdc、sdd和sde,可见在这一时刻磁盘的写性能还没有完全达到瓶颈(这里是一分钟统计一次,实际上在很多时刻性能已经接近瓶颈了)。
(2) top
| top - 12:00:51 up 24 days, 19:37, 8 users, load average: 4.09, 4.26, 3.97 Tasks: 401 total, 1 running, 400 sleeping, 0 stopped, 0 zombie %Cpu(s): 2.7 us, 0.3 sy, 0.0 ni, 96.6 id, 0.5 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 65773904 total, 392076 free, 49955132 used, 15426696 buff/cache KiB Swap: 0 total, 0 free, 0 used. 15422596 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 16637 hdfs 20 0 13.277g 512876 5632 S 100.0 0.8 269:32.82 java 24800 hbase 20 0 52.121g 0.041t 5512 S 50.0 66.9 190:32.63 java 21660 root 20 0 1450572 493904 5592 S 25.0 0.8 323:19.53 splunkd 188 root 20 0 0 0 0 S 12.5 0.0 34:16.28 kswapd0 17799 ams 20 0 2585248 1.720g 5668 S 12.5 2.7 1767:16 java 9648 root 20 0 0 0 0 S 6.2 0.0 0:37.22 kworker/2:2 23753 root 20 0 146272 2132 1352 R 6.2 0.0 0:00.02 top 1 root 20 0 43540 5120 1528 S 0.0 0.0 3:57.51 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.65 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:03.98 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:05.65 migration/0 |
可见,在hbase client上内存和cpu都未达到瓶颈(hbase内存与预先配置的值一致)。
(3) 带宽
| [Tue Sep 27 12:00:42 CST 2016] IN: 1373615064Bps(1309Mbps) OUT: 1445021992Bps(1378Mbps) [Tue Sep 27 12:00:43 CST 2016] IN: 1336094184Bps(1274Mbps) OUT: 1695614248Bps(1617Mbps) [Tue Sep 27 12:00:44 CST 2016] IN: 1061823192Bps(1012Mbps) OUT: 1509200960Bps(1439Mbps) [Tue Sep 27 12:00:45 CST 2016] IN: 1199476784Bps(1143Mbps) OUT: 1262087768Bps(1203Mbps) [Tue Sep 27 12:00:46 CST 2016] IN: 1238180664Bps(1180Mbps) OUT: 1070946320Bps(1021Mbps) [Tue Sep 27 12:00:47 CST 2016] IN: 1114114816Bps(1062Mbps) OUT: 1082001232Bps(1031Mbps) [Tue Sep 27 12:00:48 CST 2016] IN: 925406000Bps(882Mbps) OUT: 922874832Bps(880Mbps) [Tue Sep 27 12:00:49 CST 2016] IN: 303008648Bps(288Mbps) OUT: 309360352Bps(295Mbps) [Tue Sep 27 12:00:50 CST 2016] IN: 115133960Bps(109Mbps) OUT: 27696024Bps(26Mbps) [Tue Sep 27 12:00:51 CST 2016] IN: 1138637952Bps(1085Mbps) OUT: 729543344Bps(695Mbps) [Tue Sep 27 12:00:52 CST 2016] IN: 1191545232Bps(1136Mbps) OUT: 794576104Bps(757Mbps) [Tue Sep 27 12:00:53 CST 2016] IN: 1299891096Bps(1239Mbps) OUT: 805488592Bps(768Mbps) [Tue Sep 27 12:00:54 CST 2016] IN: 1327530600Bps(1266Mbps) OUT: 850532632Bps(811Mbps) [Tue Sep 27 12:00:55 CST 2016] IN: 1373236368Bps(1309Mbps) OUT: 258604392Bps(246Mbps) [Tue Sep 27 12:00:56 CST 2016] IN: 494876368Bps(471Mbps) OUT: 135714176Bps(129Mbps) [Tue Sep 27 12:00:57 CST 2016] IN: 812250304Bps(774Mbps) OUT: 275401936Bps(262Mbps) [Tue Sep 27 12:00:58 CST 2016] IN: 1162702224Bps(1108Mbps) OUT: 1108739560Bps(1057Mbps) [Tue Sep 27 12:00:59 CST 2016] IN: 1000194016Bps(953Mbps) OUT: 1340316848Bps(1278Mbps) [Tue Sep 27 12:01:00 CST 2016] IN: 1276394448Bps(1217Mbps) OUT: 1627286296Bps(1551Mbps) |
进出IN和OUT带宽都在1000Mbps左右,未达到瓶颈。
6 测试调优总结
本文的题目是测试与调优,其实主要是测试的结果和分析,由于本人一开始对hbase的框架原理等知识的理解和研究不够,所以调优的过程持续了太长时间,而且调优过程中的很多细节也没有记录的必要。
本文中的大部分配置其实是调优之后得到的结果。Hbase的读写本身就是一个动态的均衡的追求综合性能的过程,所以很多时候需要根据具体的使用场景来设置对应的参数,所以测试调优的目的在于理解和掌握hbase相关知识和配置并在实际使用中得到较好的性能。
本文得到的结果是在调优之后取得的尽可能的最大值,由于当前水平有限,应该在性能上还有一些提升的空间,但综合来看,目前的性能数据也算是较为客观的反映了我们当前使用的hadoop集群中hbase的性能了。
| 分区数 |
value长度 |
速度 条/秒 |
集群节点数 |
ycsb client节点数 |
带宽 |
操作数 |
瓶颈 |
|
| 插入insert |
200 regions |
9216bytes |
11000左右 |
4 |
1 |
1200Mb/s 不稳定 |
5000000 |
ycsb client cpu、磁盘IO |
| 插入insert |
200 regions |
9216bytes |
9000左右 |
4 |
1 |
1000Mb/s 不稳定 |
40000000 |
ycsb client cpu、磁盘IO |
| 插入insert |
200 regions |
9216bytes |
9100左右 |
4 |
4 |
1000Mb/s 不稳定 |
40000000 |
磁盘IO、ycsb client cpu |
| 扫描scan |
200 regions |
9216bytes |
85000~90000左右 |
4 |
4 |
1500~1600Mb/s |
200000 |
带宽、ycsb clinet 内存 |
| 扫描scan |
200 regions |
9216bytes |
20000左右 |
4 |
1 |
1850Mb/s |
200000 |
带宽 |
| 读取read |
200 regions |
9216bytes |
45000~50000左右 |
4 |
4 |
1100~1200Mb/s |
20000000 |
ycsb clinet 内存 |
| 读取read |
200 regions |
9216bytes |
20000左右 |
4 |
1 |
1850Mb/s |
20000000 |
带宽 |
到目前为止,调优的重点集中在ycsb工具的研究与使用和hbase、hdfs大部分配置项的设置。因为某些原因还有一些内容没有去做太大的调整和研究,例如jvm GC调优和wal机制的研究,由于自己暂时水平还没达到,所以一些很深入很细致的内容还处于研究之中,这篇文章也只是初稿,接下来会深入研究代码并结合实际环境和网络资料来提升自身对hbase的理解和研究水平,回过头来再继续更新这篇文档。
7 附录
具体的测试记录数据分别保存在本文档相同的svn目录下:
分别为单点-insert、多点-insert、scan和read
本文档需要结合ycsb介绍文档《YCSB--HBase性能测试工具的安装和使用》阅读理解。