Zeppelin 搭建遇到的若干坑
最近搭建zeppelin,单独起了一台spark-thriftserver,进行hive库的查询。遇到了N多坑,这边记录一下几个主要的地方。
当然,有zeppelin相关的疑问也欢迎在文末评论!
1、无法启动
![]()
有好多种可能,详细可以查看/logs中得日志。
可能是没有创建Log/Pid目录。
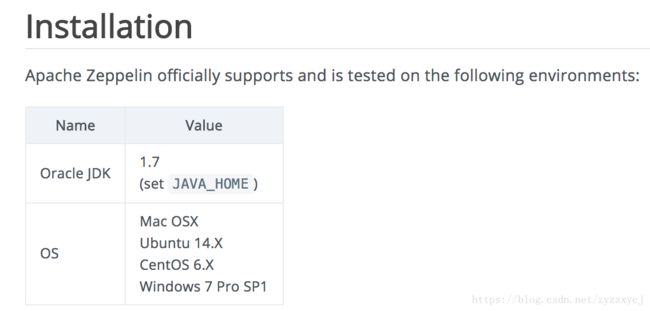
可能是没有正确安装JDK,或者版本不对。
确认JDK和系统版本:(我用的zeppelin版本为当前最新:0.7.3)
2、zeppelin ip+端口可以访问,绑定域名无法访问
我用的是8089端口,直接ip+端口,一切正常。
如果把域名映射成ip+端口,则无法访问。
正常情况:

不正常情况为红色的点,websocket disconnected
仔细研究了一下,域名映射的时候:
NGINX 通过在客户端和后端服务器之间建立起一条隧道来支持WebSocket。为了使NGINX可以将来自客户端的Upgrade请求发送给
后端服务器,Upgrade和Connection的头信息必须被显式的设置。
location /ws {
proxy_pass http://zepplin;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
3、Zeppelin用户登录认证
Zeppelin采用的是shiro认证,去/conf/shiro.ini 中配置,里面的roles为用户组,users为用户。
一个用户组可以包含多个用户,一个用户也可以属于多个用户组。
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
[users]
# List of users with their password allowed to access Zeppelin.
# To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuration-INISections
admin = 密码, 用户组1, 用户组2
# Sample LDAP configuration, for user Authentication, currently tested for single Realm
[main]
### A sample for configuring Active Directory Realm
#activeDirectoryRealm = org.apache.zeppelin.realm.ActiveDirectoryGroupRealm
#activeDirectoryRealm.systemUsername = userNameA
#use either systemPassword or hadoopSecurityCredentialPath, more details in http://zeppelin.apache.org/docs/latest/security/shiroauthentication.html
#activeDirectoryRealm.systemPassword = passwordA
#activeDirectoryRealm.hadoopSecurityCredentialPath = jceks://file/user/zeppelin/zeppelin.jceks
#activeDirectoryRealm.searchBase = CN=Users,DC=SOME_GROUP,DC=COMPANY,DC=COM
#activeDirectoryRealm.url = ldap://ldap.test.com:389
#activeDirectoryRealm.groupRolesMap = "CN=admin,OU=groups,DC=SOME_GROUP,DC=COMPANY,DC=COM":"admin","CN=finance,OU=groups,DC=SOME_GROUP,DC=COMPANY,DC=COM":"finance","CN=hr,OU=groups,DC=SOME_GROUP,DC=COMPANY,DC=COM":"hr"
#activeDirectoryRealm.authorizationCachingEnabled = false
### A sample for configuring LDAP Directory Realm
#ldapRealm = org.apache.zeppelin.realm.LdapGroupRealm
## search base for ldap groups (only relevant for LdapGroupRealm):
#ldapRealm.contextFactory.environment[ldap.searchBase] = dc=COMPANY,dc=COM
#ldapRealm.contextFactory.url = ldap://ldap.test.com:389
#ldapRealm.userDnTemplate = uid={0},ou=Users,dc=COMPANY,dc=COM
#ldapRealm.contextFactory.authenticationMechanism = simple
### A sample PAM configuration
#pamRealm=org.apache.zeppelin.realm.PamRealm
#pamRealm.service=sshd
### A sample for configuring ZeppelinHub Realm
#zeppelinHubRealm = org.apache.zeppelin.realm.ZeppelinHubRealm
## Url of ZeppelinHub
#zeppelinHubRealm.zeppelinhubUrl = https://www.zeppelinhub.com
#securityManager.realms = $zeppelinHubRealm
sessionManager = org.apache.shiro.web.session.mgt.DefaultWebSessionManager
### If caching of user is required then uncomment below lines
cacheManager = org.apache.shiro.cache.MemoryConstrainedCacheManager
securityManager.cacheManager = $cacheManager
securityManager.sessionManager = $sessionManager
# 86,400,000 milliseconds = 24 hour
securityManager.sessionManager.globalSessionTimeout = 86400000
shiro.loginUrl = /api/login
[roles]
admin = admin
develop = develop
[urls]
# This section is used for url-based security.
# You can secure interpreter, configuration and credential information by urls. Comment or uncomment the below urls that you want to hide.
# anon means the access is anonymous.
# authc means Form based Auth Security
# To enfore security, comment the line below and uncomment the next one
/api/version = anon
/api/interpreter/** = authc, roles[admin]
/api/configurations/** = authc, roles[admin]
/api/credential/** = authc, roles[admin]
#/** = anon
/** = authc
在最底下可以配置用户对解释器interpreter,configurations,credential等权限控制:
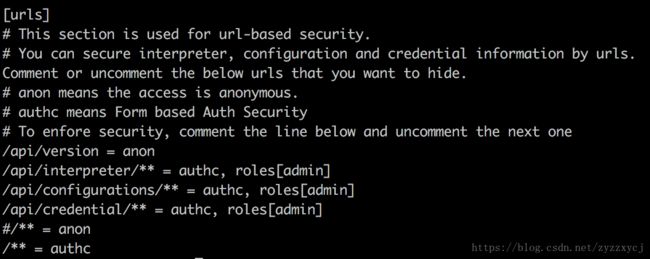
这边只有admin用户组才能访问这些配置。
4、spark-thriftserver jdbc连接的权限控制
这边目前只实现了,能用于连接的用户密码的权限控制,具体登录后,暂时无法控制create、drop等权限。
具体实现是通过实现了IteblogPasswdAuthenticationProvider 来进行身份验证的。
将这个类打成jar包,上传到spark-thriftserver,放在jars里面,然后beeline 去连接jdbc:hive2://0.0.0.0:10000 就可以验证了。
在spark日志中,也都会打出该身份验证记录。
代码如下:
import com.google.common.base.Charsets;
import com.google.common.collect.Maps;
import com.google.common.io.Files;
import com.google.common.io.LineProcessor;
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hive.service.auth.PasswdAuthenticationProvider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.security.sasl.AuthenticationException;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class IteblogPasswdAuthenticationProvider implements PasswdAuthenticationProvider {
private static Logger logger = LoggerFactory.getLogger("IteblogPasswdAuthenticationProvider");
private static Map lines = null;
// static {
// HiveConf hiveConf = new HiveConf();
//// String filePath = hiveConf.get("hive.server2.custom.authentication.passwd.filepath");
// String filePath = "/opt/app/spark-2.2.1-bin-hadoop2.6/conf/hive-thrift-passwd";
// logger.warn("Start init configuration file: {}.", filePath);
// try {
// File file = new File(filePath);
// lines = Files.readLines(file, Charsets.UTF_8, new LineProcessor>() {
// Map map = Maps.newHashMap();
//
// public boolean processLine(String line) {
// String arr[] = line.split(",");
// if (arr.length != 2) {
// logger.error("Configuration error: {}", line);
// return false;
// }
// map.put(arr[0], arr[1]);
// return true;
// }
//
// public Map getResult() {
// return map;
// }
// });
//
// } catch (IOException e) {
// logger.error("Read configuration file error: {}", e.getMessage());
// System.exit(127);
// }
//
// userInfo.put("heguozi","123456");
// }
public void Authenticate(String username, String password) throws AuthenticationException {
// if (lines == null) {
// throw new AuthenticationException("Configuration file parser error!");
// }
// String pwd = lines.get(username);
Map userInfo = new HashMap();
userInfo.put("账号1", "密码1");
userInfo.put("账号2", "密码2");
String pwd = userInfo.get(username);
if (pwd == null) {
throw new AuthenticationException("Unauthorized user: " + username + ", please contact 和果子 to add an account.");
} else if (!pwd.equals(password)) {
throw new AuthenticationException("Incorrect password for " + username + ", please contact 和果子 to change the password.");
}
logger.warn("User[{}] authorized success.", username);
}
}
5、控制hdfs权限
使用hadoop fs -chmod 755 test.db来实现除了创建者以外,无法新增、修改、删除该库及里面的表。
如果hive中drop了,会提示没有权限。
beeline连接spark,删除hive的表,只会删除hive层面上的结构(drop不会有报错),而hdfs中表仍旧存在。

6、输出文件大小限制
报错:
Output exceeds 102400. Truncated.
参考官方文档 https://zeppelin.apache.org/docs/0.7.2/install/configuration.html#ssl-configuration
在zeppelin-site.xml中,按需要增加参数:

在zeppelin interpreter的设置中修改参数:

7、hdfs interpreter
为了能像hue那样操作hdfs,使用file interpreter 自行创建了一个hdfs interpreter:
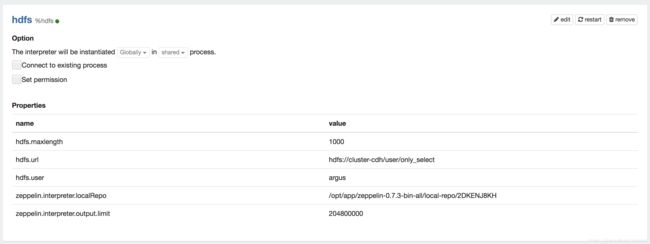
但是一直报错:
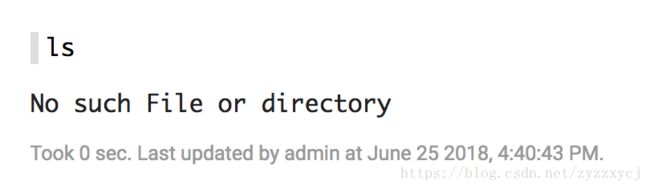
查看日志:
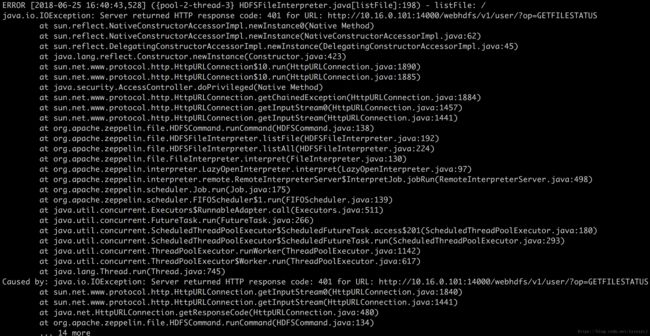
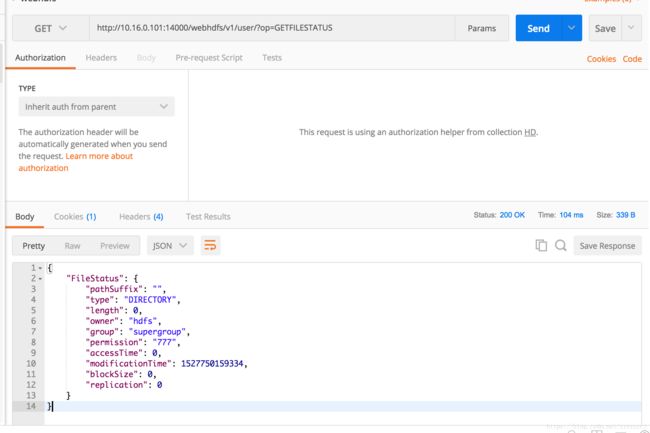
http 401 权限认证问题,直接访问和postman调用都是可以的:
查看hdfsinterpreter的源码,发现这边需要在http请求中加上user.name:
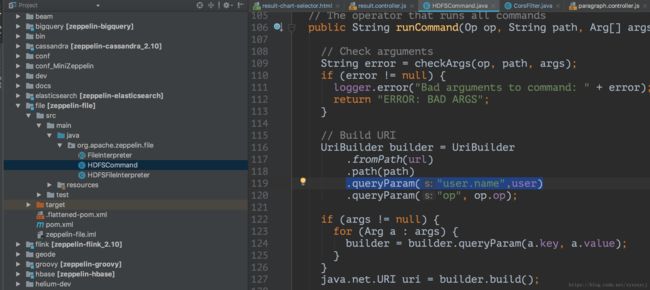
之后用mvn打个包即可解决该问题。
mvn clean package -Pbuild-distr -Dcheckstyle.skip=true -Drat.skip=true -DskipTests