MySQL之体系结构和存储引擎
体系结构和存储引擎
- 1. 定义数据库和实例
- 2. MySQL 体系结构
- 3. MySQL 存储引擎
- 3.1 InnoDB
- 3.2 MyISAM
- 3.3 NDB
- 3.4 Memory
- 3.5 Archive
- 3.6 Federated
- 3.7 Maria
- 3.8 BlackHole
- 3.9 CSV
- 4. MyISAM VS InnoDB
- 5. 连接 MySQL
- 5.1 TCP/IP
- 5.2 管道
- 5.3 共享内存
- 5.4 UNIX 域套接字
1. 定义数据库和实例
- 数据库:物理操作系统文件或其他形式文件类型的集合。
- 实例:
MySQL 数据库由后台线程以及一个共享内存区组成。数据库实例才是真正用于操作数据库文件的。
MySQL 数据库实例在系统上的表现就是一个进程。
数据库是文件的集合,是依照某种数据模型组织起来并存放于二级存储器中的数据集合;数据库实例是程序,是位于用户于操作系统之间的一层数据管理软件,用户对数据库数据的任何操作,包括数据库定义、数据查询、数据维护、数据库运行控制等都是在数据库实例下进行的,应用程序只有通过数据库实例才能和数据库打交道。
2. MySQL 体系结构
MySQL 数据库的体系如下所示:
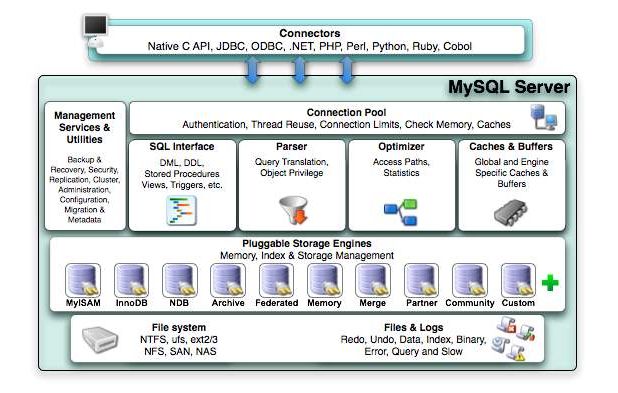
MySQL由以下几部分组成:
- 连接池组件
- 管理服务和工具组件
SQL接口组件- 查询分析器组件
- 优化器组件
- 缓冲(
Cache)组件 - 插件式存储引擎
- 物理文件
MySQL数据库区别于其他数据库的最重要的一个特点就是其插件式的存储引擎。存储引擎式基于表的,而不是数据库。
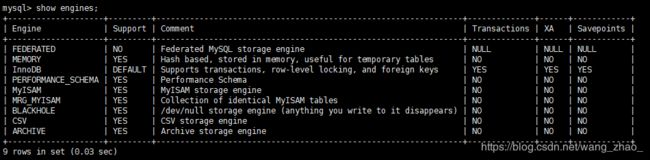
3. MySQL 存储引擎
存储引擎的好处是,每个存储引擎都有各自的特点,能够根据具体的应用建立不同存储引擎表。
查询MySQL支持的数据库有哪些?
3.1 InnoDB
InnoDB 是默认的事务性引擎,被用来设计处理大量的短期事务。其特点是支持行锁、外键、非锁定读,即默认读取操作不会产生锁。
InnoDB 通过使用多版本控制(MVCC)来获得高并发性,并且实现了SQL标准的四种隔离级别,默认是REPEATABLE级别。同时使用next-key避免欢度(phantom)现象的产生。
InnoDB 还提供了插入缓冲、二次写、自适应哈希索引、预读等高性能、高可用的功能。
InnoDB 采用聚集的方式存储表中的数据,因此每张表的存储都是按主键的顺序进行存放。
3.2 MyISAM
MyISAM不支持事务、行锁、外键等,支持表锁、全文索引等。
MyISAM另一个特点是其缓冲池只缓存(cache)文件,而不缓存数据文件。

MyISAM表由MYD和MyI组成,MYD用来存放数据文件,MYI用来存放索引文件。
3.3 NDB
NDB是一个集群存储引擎。
NDB的特点是数据全部存放在内存中(5.1 版本,可以将非索引数据放在磁盘上),因此主键查询的速度极快,通过添加NDB数据存储引擎节点(Data Node)可以线性地提高数据库性能,是高可用、高性能地集群系统。
3.4 Memory
Memory将表中的数据存放在内存中,,如果数据库重启或宕机,表中的数据将消失,适合用于存储临时数据的临时表。
Memory默认使用哈希索引。
3.5 Archive
Archive只支持INSERT和SELECT操作,其设计的主要目标是提供高速的插入和压缩功能。
Archive非常适合存储归档数据,如日志信息。
3.6 Federated
Federated并不存放数据,用来访问其他MySQL数据库服务器的代理。
3.7 Maria
Maria设计目的是用来取代MyISAM。
Maria特点是:支持缓存数据和索引文件,应用了行锁设计,提供了MVCC功能,支持事务和非事务安全的选项,以及更好的BLOB字符类型的处理性能。
3.8 BlackHole
BlackHole只记录日志信息,其没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存。但服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者简单的日志记录。
3.9 CSV
CSV可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。
CSV存储的数据直接可以在操作系统里,用文本编辑器或Excel读取。
4. MyISAM VS InnoDB
InnoDB和MyISAM是最常用的存储引擎,两者的对比如下:

5. 连接 MySQL
连接MySQL指一个连接进程和MySQL数据库实例进行通信。本质上是进程之间如何进行通信,常用的方式有匿名管道、命名管道、命名字、TCP/IP套接字、UNIX域套接字。
5.1 TCP/IP
TCP/IP方式是MySQL数据库在任何平台下都提供的连接方式,这种方式在TCP/IP连接上建立一个基于网络的连接请求,一般情况下客户端(client)在一台服务器,而MySQL实例(server)在另一台服务器上,这两台机器通过一个TCP/IP网络连接。
5.2 管道
管道的本质便是文件,进程间通过对文件内容的读写实现通信。
匿名管道用于有亲缘关系的进程通信。
命名管道用于无亲缘关系的进程通信。
5.3 共享内存
本质同管道,进程间通过对内存区域中的数据读写完成通信。
5.4 UNIX 域套接字
在Linux和Unix环境下,还可以使用UNIX域套接字,只能在MySQL客户端和数据库实例都在一台服务器上的情况下使用。