被豆瓣反爬虫制裁实记录——温柔小薛的第一个小爬虫
写在前面
最近的课设是用python写一个简单爬虫,然而不让用使用起来便捷的第三方模块和爬虫框架,要求基于socket来写,死磕了好几天,结果还只能爬一丢丢啦,最后才查资料找到了问题所在,其实是遇到了简单的蜜罐,听了好久蜜罐,还真让我遇上一次,不用第三方真的绕不过去啊,还好老师没太难为人,不过自己也是挺生气哦,留个坑吧,以后抽时间再写一个功能强的说啥也得绕过了!
不多说了,报告整上,做这个爬虫需要一些web端知识哦,整体思路就是模拟浏览器发送request,接受返回的数据,再进行储存,之后解析抽离出自己需要的数据,注释都写得很清楚了,只不过有些乱,没写的我会截图说明,注释的print都是我bebug用的
爬取目标是 https://movie.douban.com/top250?start=0&filter= 以及后面的页面
一、需求分析
网络爬虫是从 web 中发现 ,下载以及存储内容,是搜索引擎的核心部分。传统爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL ,在抓取网页的过程中,不断从当前页面上抽取新的 URL 放入队列,直到满足系统的一定停止条件。
选择自己熟悉的开发环境和编程语言,实现网络爬虫抓取页面、从而形成结构化数据的基本功能,界面适当美化。
二、系统设计
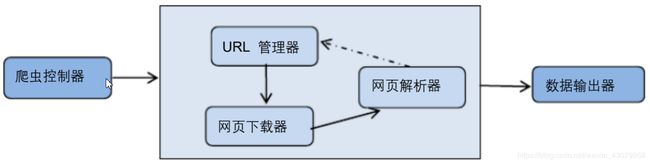
在本爬虫程序中共有三个模块:
1、爬虫调度端:启动爬虫,停止爬虫,监视爬虫的运行情况。
2、爬虫模块:包含三个小模块,URL 管理器、网页下载器、网页解析器。
(1)URL 管理器:对需要爬取的 URL 和已经爬取过的 URL 进行管理,可以从 URL管理器中取出一个待爬取的 URL,传递给网页下载器。
(2)网页下载器:网页下载器将 URL 指定的网页下载下来,存储成一个字符串,传递给网页解析器。
(3)网页解析器:网页解析器解析传递的字符串,解析器不仅可以解析出需要爬取的数据,而且还可以解析出每一个网页指向其他网页的 URL,这些 URL 被解析出来会补充进 URL 管理器
3、数据输出模块:存储爬取的数据。
三、系统实现
文件1 爬虫主体
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XUE
# 目标是 https://movie.douban.com/top250?start=25&filter=
import socket
import ssl
import random
from tkinter import *
#网站的四个组成部分
#协议 主机 端口 路径
#函数一 模仿浏览器访问功能 构建发送GET请求 接收返回数据
def get (url):
# 目标是 https://movie.douban.com/top250?start=25&filter=
print('url是',url)
u = url.split('://')[1] #切片获取 协议 域名 路径
protocol = url.split('://')[0]
i = u.find('/')
host = u[:i]
path = u[i:]
if protocol == 'https': #根据是http还是https 进行传输方式判断
s = ssl.wrap_socket(socket.socket())#创建实例 也可以说是建立连接
port = 443 #默认端口
else:
s = socket.socket()#创建实例
port = 80
# print(protocol)
s.connect((host,port))
request = 'GET {} HTTP/1.1\r\nhost:{}\r\n\r\n'.format(path,host)
# Cookie = {'bid=wPX71ZOfcqg': 'douban-fav-remind=1'}
# print('request是',request)
encoding = 'utf-8'
s.send(request.encode(encoding))
response = b''
buffer_size = 1024
while True :
# print('response是',response)
r = s.recv(buffer_size)
response += r
if len(r) < buffer_size:
break
response = response.decode(encoding)
return response
#函数二 这里有十个页面 十个URL 写一个函数来遍历十个页面 得到十个页面源代码
def htmls_from_douban():
html = []#创建空列表
url = """https://movie.douban.com/top250?start={}&filter="""
for index in range (0,250,25):#依次是 0 25 50 ...
u = url.format(index) #把index传入url 得到一个完整的url 就是u
# print('url 是',u) #方便检测
r = get (u) #调用第一个函数 得到 字符串
# print(' r是',r)
html.append(r) #把字符串添加到列表
return html #得到一个列表 有十个元素 每个元素都是get函数得到的字符串
print('htmls 是',list(html))
# print('htmls',htmls_from_douban())
#函数三 处理得到的页面源代码 这里思路是例如想爬取这些电影的名字 我就去搜寻前后的关键字
#可以理解为一个复杂的字符串操作
#假如调用这个函数的话,先找到一个标题,进入while循环
#把标题放入列表,再继续查,查到再放入列表,最后跳出
def findall_in_html(html,startpart,endpart):#前后的字符串关键字
all_strings = []#定义空列表
#find函数是字符串自带的函数
#find()方法检测字符串中是否包含子字符串str ,如果指定beg(开始)和 end(结束)范围,
#则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
start = html.find(startpart) + len(startpart) #得到起始下标 也就是>的位置
end = html.find(endpart,start)#结尾下标 也就是从start开始找 也就是后半部分<的位置
string = html[start:end] #通过下标取到字符串 这里采用切片
# print('string是',string)
#通过while循环 来满足25个操作 (一页25个标题)
# print('进去了吗',html.find ('