基于候选区域的目标检测器总结(RCNN,FastRCNN,FasterRCNN)
这段时间了解了一下深度学习中的目标检测常用的模型,为以后学习打一打基础,其中基于候选区域的目标检测经典模型必属RCNN,FastRCNN,FasterRCNN,网上有很多大牛的博客讲的都很详细,大家可以去查找,我就从者三个模型的训练和测试过程方面简单的总结一下。小白一枚,不足之处多多指正
RCNN
RCNN是一个多阶段训练模型,包括生成候选区域,CNN微调,SVM训练和边界框回归等多个步骤。
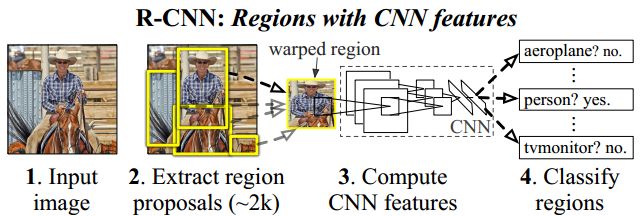
训练过程
1. 使用ILSCRC2012训练集对CNN Alexnet模型进行预训练
2. 在验证集上使用SelectResearch对每张图片上生成2000个左右的候选的区域(IoU>0.5的标记正样本,IoU<0.5的标记负样本),将候选框大小调整为224*224大小
3. 将生成的候选区域送入预训练完成的Alexnet网络中进行微调,微调时使用SGD,并将学习率设置为预训练时的1/10(每一个batch中有大约128个候选框,其中正样本32个,负样本96个)
4. 微调完成后,在进行SVM之前需要重新定义正负样本,其中IoU<0.3的为背景负样本,正样本用GT box来表示
5. 将重新定义的候选框从Alexnet中得到4096维度的特征向量,进行SVM训练,为每一个类别训练一个二分类器(目标,背景)
6. 进行边界框回归,在选择线性回归器的样本时使用Hard negative mining method,就是选择假样本中代表性比较高的样本,即选择IoU>0.6的候选框进行回归训练。
具体做法:假如下图中的蓝色box用P来表示,P=(Px,Py,Pw,Ph),这四个值分别表示这个box的中心点横坐标,中心点纵坐标,box宽度以及box高度.红色框为目标的真实box,设为G,G=(Gx,Gy,Gw,Gh),每个元素的含义和P中相同,现在的目的就是想学习到一种变换,这个变换可以将P映射到G.

如何对这个变换进行建模? 作者给出了一种变换关系如下图所示:

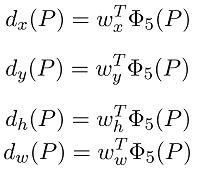
其中,Φ5(P)是CNN网络中Pool5计算出的特征,,w_{x,y,h,w}为待学习的回归器参数。
测试过程
- 测试集上的图片使用SelectResearch生成2000个大小的候选区域,并调整到224*224大小
- 使用CNN计算每个特征图的特征向量
- 使用多个SVM二分类器进行预测每个类的概率
- 对每一类别执行NMS(非极大值抑制),保留该类别概率值较大的候选框
- 对保留的候选框进行边界框回归
缺点不足
- 训练时多任务管道(CNN微调,SVM分类器,边界框回归等)
- 训练过程在时间和空间上时非常耗时和昂贵的
- 在测试时,物体检测速度比较慢
参考文献
RCNN详细解释
RCNN原论文地址
FastRCNN
针对RCNN训练速度比较慢和多任务模型的问题,FastRCNN提出使用多任务损失的单阶段训练,使用了ROI池化层,实际上是空间金字塔池化层的一个特例,只有一个金字塔层。
FastRCNN原论文中指出,RCNN慢的主要原因是每个图片的每个候选框都要经历前向传播运算,没有使用共享的特征图。

而SPPnet也存在显著的缺点,首先就是多阶段训练(CNN微调,训练SVM等等),还有就是在CNN微调阶段不能有效的更新spatial pyramid pooling(金字塔池化层)之前的卷积层,只能更新后面的全连接层。这点我也很疑惑,原文是这样解释的:


原因是训练样本来自不同的图片,需要同时计算和存储这些图像的Feature Map,过程变得expensive,因为每一个ROI可能有非常大的感受野,很有可能是整张图片,所以训练输入非常大。
传送门:为什么SPP-Net无法fine-tune卷积层
训练过程
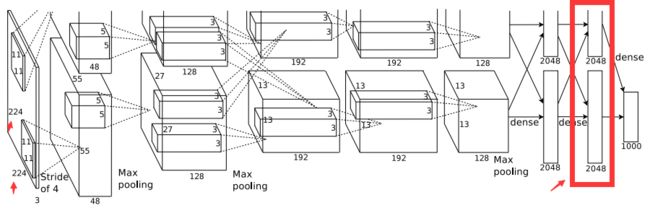
- 使用Alexnet(或者VGG_CNN_M_1024、或者VGG-16)模型对ImageeNet进行有监督的预训练
对预训练模型进行三个转变:
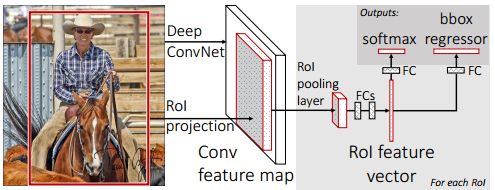
将最后一个池化层变成ROI层;
最后一个全连接层和SoftMax变成两个并行层;一个并行层是新的全连接层和候选框回归,另一个并行层是新的全连接层和SoftMax
最后,网络的输入改为图片和候选框双输入格式在验证集上使用SelectSearch对每张图片上生成2000个左右的候选的区域(IoU>0.5的标记正样本,IoU<0.5的标记负样本),此时不用像RCNN一样把图片更改为固定大小
- 输入图片和对应的候选框,得到图片的特征图
- 使用ROI池化层对每一个候选框从特征图中提取固定长度的特征向量
提取方法:
假设候选框在特征图中对应的特征框大小为w*h,将其划分为(w/W*h/H)个子窗口,对每一个子窗口max-pool池化,得到一个W*H固定大小的特征向量 - 将特征向量送入全连接层并产生两个输出,分别是类别概率和类别边界框位置。对于全连接层,使用SVD分解进行加速。
损失函数:
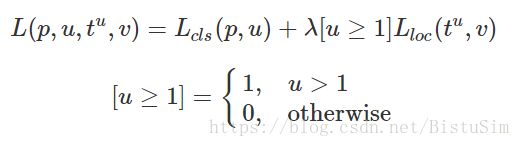
约定u=0为背景分类,那么[u≥1] 函数表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作; λ 控制分类损失和回归损失的平衡,文中所有实验λ=1;
分类log损失:
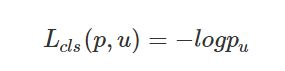
回归损失:
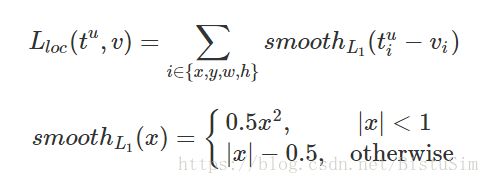
预测的坐标参数:
![]()
真实的坐标参数:
![]()
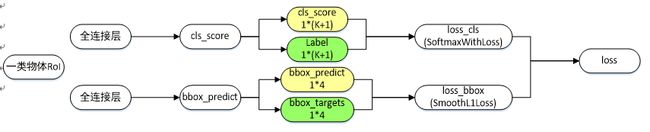
盗用大神的一个损失过程图解:
测试过程
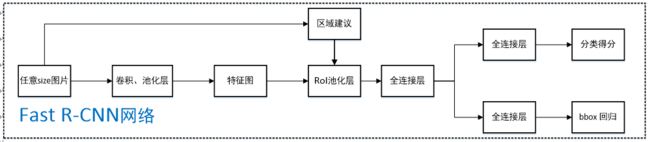
- 将任意大小的图片送入CNN 网络,得到图片的特征图
- 使用SelectResearch得到2000个左右的候选框,根据原图像到特征图的映射关系,得到候选框在特征图上的位置
- 将提取的特征框送入ROI层得到固定大小的特征向量
- 将特征向量分别送入两个全连接层(使用SVD分解),得到回归框的位置和类别的概率
- 根据得到的概率和位置进行非极大值抑制,得到概率较高的窗口
参考:
Fast R-CNN论文详解
fast-rcnn论文翻译
FasterRCNN
RCNN的不足主要是多任务、空间消耗比较大;FastRCNN实现了对多任务阶段的改进,将SVM和边界框回归统一到一个训练过程中,但是在获取候选框时还是使用了SelectSearch方法,仍有局限。所以,FasterRCNN就是使用RPN生成候选区域。
FasterRCNN由两个模型组成,第一个就是RPN(深层全卷积网络)生成候选区域,第二个就是使用FastRCNN对候选区域进行检测。

Anchors
Anchors是RPN网络中比较的重要的一部分。在RPN网络中,用一个3*3的卷积核在最后一个卷积层产生的特征图上进行滑动操作,将卷积核的中心位置映射回输入图像,生成三种尺度{128*128,256*256,512*512}和三种长宽比{1:1,1:2,2:1}共九种Anchors。所以对于M*N大小的特征图会在原图像中生成M*N*9个Anchors,可以在原图像上得到多尺度的候选框。之所以采用滑动窗口的方式,因为可以保证关联上特征图上所有的像素点。
这里使用3*3的卷积核目的是进一步集中特征的信息,使得每个特征点可以关联局部邻域的空间信息。
RPN网络结构
RPN(Region Proposal Network)是一个深度全卷积网络,其作用就是代替选择性搜索SelectSearch,输入一张图片,输出是一个包含softmax二分类和bbox的多任务模型(包括是否包含目标的概率,以及每个区域的中心位置坐标和长宽)。
RPN结构如图(Alextnet):
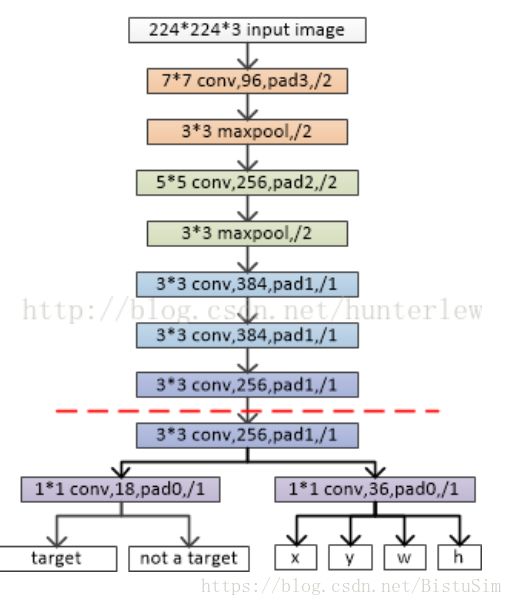
虚线以下是RPN特有的结构,首先使用3*3大小的卷积核进行卷积,然后在用1*1的卷积核输出分成两路,一个是输出包含目标的概率,另一个就是区域的位置信息。
RPN网络的训练损失函数:
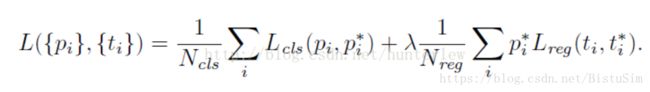
可以看到损失函数为多任务模型,前部分表示区域中是否含有目标的分类损失,后部分表示边界框的回归损失。其中,回归损失采用fastRCNN中的SmoothL1损失函数,Leg与Pi相乘表示仅计算候选区域为正样本的回归误差,在计算时,不是比较四个点的位置坐标,而是tx,ty,tw,th。
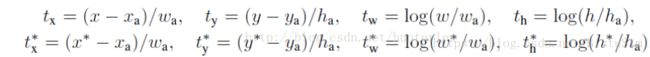
如何判断候选区域中是否包含目标:首先该anchor与目标区域的IOU最大,则该anchor为正样本;若anchor与目标区域的IOU>0.7也为正样本;若anchor与目标区域的IOU<0.3则为负样本。
训练过程
- 使用预训练模型初始化RPN,并进行微调
- 使用RPN的Proposal和预训练模型初始化FastRCNN,并进行微调,此时并没有共享参数,只是分开进行训练
- 再次训练RPN,固定RPN与FastRCNN共有的参数,仅更新RPN独有的参数
- 使用RPN新生成的区域再次训练FastRCNN,固定共有的参数,只更新独有的参数
SelectResearch
通过简单的区域划分法,将图片划为多个小区域,通过相似度和区域大小不断聚合相邻比较小的区域,相似度的计算从颜色、纹理等方面计算;
算法过程:

参考:Selective Search for Object Recognition
感受野
在视觉的深度学习中经常可以听到感受野这个概念,感受野就是卷积神经网络某层特征图上的某个像素点在原始图像上映射区域的大小
感受野大小的计算:
- 计算感受野大小时忽略padding的影响
- 第一层卷积网络输出的特征图上的像素点的感受野等于卷积核的大小
- 深层卷积网络的像素点的大小和该层的stride、卷积核大小有关
//某卷积层像素点的感受野
RF = 1
for layer in (从当前层到第一层):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize参考:物体检测之感受野大小计算
NMS
非极大值抑制;顾名思义就是在某个邻域内寻找最大值,抑制非极大值;原理:假设BBox集合为B,对应的置信度为S,选择具有最大score的检测框M,将其从B中移除M,并加入最终结果D中,并计算B中剩余的检测框与M的IoU,并将大于一定阈值的检测框剔除,重复此过程,直到B为空。

参考
非极大抑制