对抗样本(论文解读一): DPATCH: An Adversarial Patch Attack on Object Detectors
准备写一个论文学习专栏,先以对抗样本相关为主,后期可能会涉及到目标检测相关领域。
内容不是纯翻译,包括自己的一些注解和总结,论文的结构、组织及相关描述,以及一些英语句子和相关工作的摘抄(可以用于相关领域论文的写作及扩展)。
平时只是阅读论文,有很多知识意识不到,当你真正去着手写的时候,发现写完之后可能只有自己明白做了个啥。包括从组织、结构、描述上等等很多方面都具有很多问题。另一个是对于专业术语、修饰、语言等相关的使用,也有很多需要注意和借鉴的地方。
本专栏希望在学习总结论文核心方法、思想的同时,期望也可以学习和掌握到更多论文本身上的内容,不论是为自己还有大家,尽可能提供更多可以学习的东西。
当然,对于只是关心论文核心思想、方法的,可以只关注摘要、方法及加粗部分内容,或者留言共同学习。
**
DPATCH:An Adversarial Patch Attack on Object Detectors
**
XinLiu1,HuanruiYang1,ZiweiLiu2,LinghaoSong1,HaiLi1,YiranChen1
1Duke University, 2The Chinese University of Hong Kong
1{xin.liu4, huanrui.yang, linghao.song, hai.li, yiran.chen}@duke.edu, [email protected]
发表:AAAI 2019
针对目标检测的对抗块攻击
1 摘要:
提出了一个针对主流目标检测器(Faster R-CNN和YOLO)的基于对抗块的黑盒攻击-----DPATCH.
Compared to prior works, DPATCH has several appealing properties:
(1)可以实现无目标及有目标的攻击,分别将原始Faster R-CNN和YOLO的mAP由75.10%和65.7%降到1%以下;
(2)块的尺寸非常小且攻击效果与安放位置无关;
(3)对于不同的检测器和训练数据集具有强转移性(DPATCH demonstrates great transferability among different detectors as well as training datasets).如基于Faster R-CNN训练的生成的对抗块对于YOLO也具有有效的攻击,反之亦然(and vice versa).
2 介绍:
As deep learning systems achieve excellent performance in many cognitive applications, their security and robustness issues are also raised as important concerns recently. 背景–应用
像素级全局扰动的优-缺点
引入对抗块,Recently, adversarial patch (Brown et al. 2017) is introduced as an practical approach of real-world attacks.
原有对抗块无法攻击识别器, as shown in Fig.1. The reason resides at the detector architectures: Modern object detectors first locate the objects with different sizes at different locations on the image and then perform classification. Hence, the number of targets that need to be attacked in this case is much larger than that in apure classification application (Avishek and Parham 2018).For example,Faster R-CNN generates approximately 20k regions for classification, which is far beyond an original adversarial patch can effectively attack.
引入本论文,Our key insight is that both bounding box regression and object classification need to be simultaneously attacked. Based on this observation, we propose DPATCH – an iteratively trained adversarial patch that …
3 相关工作
Attacking Deep Learning Systems. ( pixel-wise additive noise (Goodfellow et al. 2014))
Adversarial Patch. To achieve a universal attack on realworld vision system, Google (Brown et al. 2017)
4 提出的方法
Revisit Modern Detectors
Faster R-CNN.two-stage detector
•Region Proposal Network This Region Proposal Network takes as input an n × n spatial window (3 × 3 window as default) to slide over the last shared convolutional layer. These proposed regions generated by RPN will be mapped to the previous feature map for object classification later on.
•Anchors Generation and Region of Interest It generates 9 anchor boxes at each sliding position associated with 3 scales and 3 aspect ratios. These anchor boxes are considered as the potential proposal. When evaluating, Faster R-CNN uses a cls layer, which outputs 2k scores to estimate probability of object or not for each potential proposal.
通过分析网络特性,引出我们的攻击思想。Our purpose is to make the region where the DPATCH exists as the only valid RoI, while other potential proposal should be considered not to own an object and thus, ignored. 从第一个阶段的region入手,使其网络提取评估ROI时只对对抗块感兴趣,而忽略其他全部区域。
YOLO. It reframes object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities. one-stage
•Unified Detection it divides the input image into multiple grids, predicts bounding boxes and confidence scores for each grid. These confident scores reflect the confidence of the box containing an object,as well as the accuracy of the model predicting that box.
•Bounding Boxes Prediction and Confidence Scores Each grid in the image predicts B bounding boxes and confidence scores for those boxes.
从包含对抗块的grid的bboxes入手,使其置信度远高于其他任何grid。the grids where the DPATCH exists should be considered to have an object when attacking YOLO, while other grids should be ignored. That is, the grid containing a DPATCH has higher confidence score than others with normal objects.
DPATCH Formulation
基于谷歌生成对抗块的如下方法,类比学习引出我们的针对目标检测器的攻击方法:

分为如下两种情况:
1)无目标攻击:将网络输出的真实标签y^和真实bboxes B^作为loss值进行回传;(这一块的最大损失回传,需要再看一下代码,是否跟愚弄摄像头那个一样,只是找到概率最大的那个值进行回传,估计一样)

2)有目标攻击:最小化与目标类别yt和目标bboxes Bt的损失。
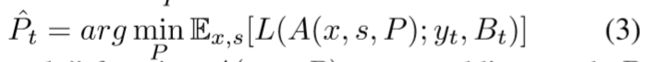
损失函数L,块应用函数A,图像x,图像变换s,块P。
Object Detector Attacking System
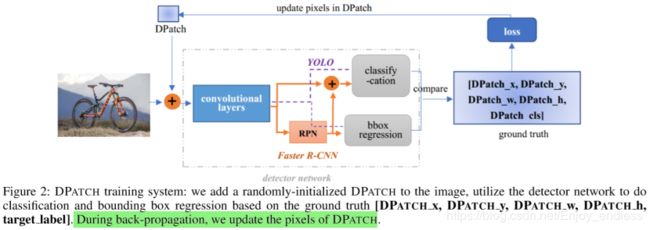
其整体的攻击流程如上,相关攻击方法都是类似的,比较简单:首先在原始图像上随机初始化一个图像块,然后送入检测网络获得检测结果并根据给定的loss函数进行回传更新,在更新的时候只是更新图像块内的像素,最后通过loss回传不断迭代网络更新对抗块实现攻击效果。
最后其生成的两个对抗块效果如下:

DPATCH Design. 默认大小40*40
**•Randomly-located DPATCH:**每次迭代训练时,随机更改块的位置
**•DPATCH of Different Targeted Classes:**randomly select four classes, bike, boat, cow ,tv
**•DPATCH with Different Sizes:**20-by-20,40-by-40 and 80-by-80
Transferability of DPATCH
YOLO训练生成的对抗块攻击Faster R-CNN,反之亦然;
COCO上训练生成的对抗块攻击VOC训练的检测器。
**
5 实验
**
使用了三个预训练检测器:YOLO、基于VGG16和ResNet101的Faster R-CNN
使用不同检测网络在voc的20个类别上的攻击效果:
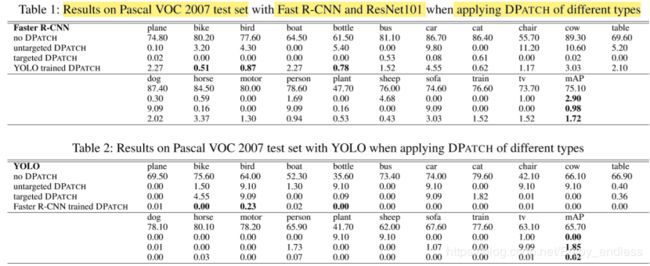
可以看到取得的攻击效果确实非常好,但是也有一个需要注意的地方就是:
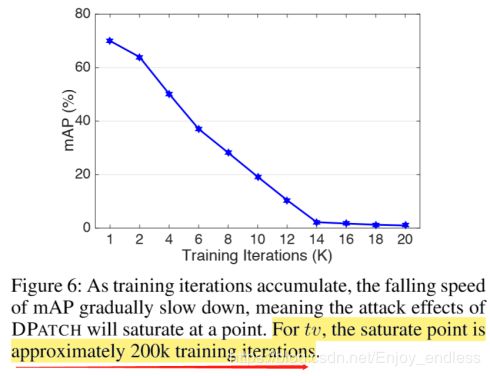
其迭代次数非常巨大,达到了200K!!
在迭代训练过程当中,他们发现在迭代100k时为class损失降低到0;
而迭代200k时box的loss依然较高!!
下面这是他添加的对抗块,对于不同网络一个ROI的影响结果的可视化,证明他的块对于网络预测ROI起到了攻击的效果。


这篇论文总体思想其实是比较简单的,但是在该方向也是有一个比较大的创新的,通过引入对于ROI的攻击思想。虽然训练过程耗费比较大,但是对于相关领域的研究还是有一个比较大的启发的。
Github上有一份源码,还没具体实践分析,期望与大家一起分享讨论:
https://github.com/veralauee/DPatch