词汇处理——词义辨析消歧(一)
经典方法
详细介绍解决NLP词义辨析消歧的经典方法
研究现状
参考链接:
Train-O - Mictic:无需人工培训数据即可在多种语言中进行大规模监督的词义消歧
Word Sense Disambiguation
对NLP词义辨析消歧的综述介绍
词义消岐(WSD)是NLP的一个难点,由于在某些情况下语境复杂,会给模型的训练带来困难。
WSD的任务包括将上下文中的词与最合适的词条在预定义的词义清单中相关联。
通常,解决WSD的方法有两种:监督的(使用有意义注释的训练数据)和基于知识的(使用词汇资源的属性)。
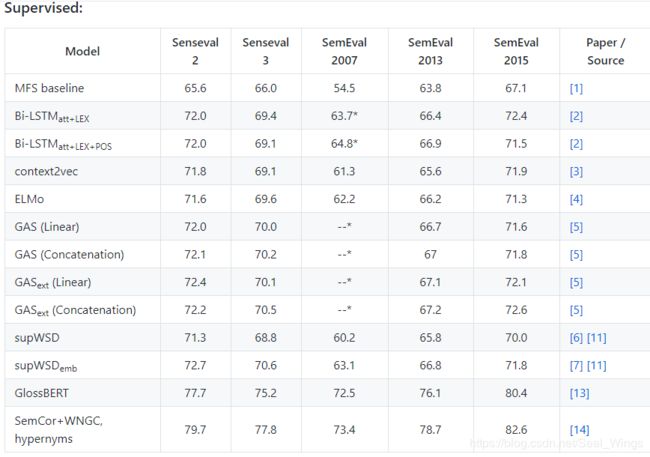
监督的方法:
在这种情况下,最广泛使用的语料库是SemCor,从352个文档中手动标注了226,036个意义注释。
在评估表中所有的受监督系统都在SemCor语料上进行训练,一些受监督的方法,特别是神经体系结构,通常使用SemEval 2007数据集作为开发集(在表中将它们标记为*)。最常见的基准是最常见的含义(the Most Frequent Sense,MFS)启发式,它为每一个目标单词在训练数据中选择出最常见的含义。
基于知识的方法:
基于知识的系统通常使用WordNet或者BabelNet作为语义网络。底层意义清单(即WordNet 3.0)给出的第一个意义被包括在内作为基准。
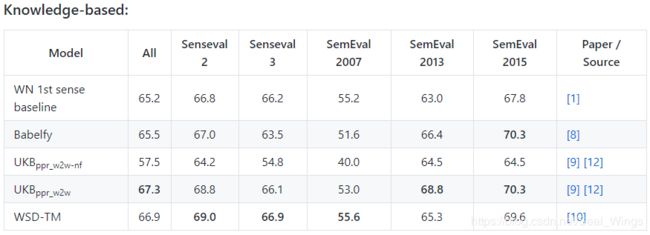
上述表中列出的评价指标主要是F1值。

它们所对应的文献分别是:

下面依次介绍各篇文献:
(1)2017年的论文《Word Sense Disambiguation: A Unified Evaluation Framework and Empirical Comparison(词义消歧:统一的评估框架和实证比较)》
在缺乏对自动系统的评估框架的背景下,作者开发出一个统一的评估框架,以公平的方式分析各种词义消歧系统的性能。 结果表明,监督系统明显优于基于知识的模型。 在受监督的系统中,经过常规局部特征训练的线性分类器仍然被证明是很难击败的。尽管如此,利用未标记语料库上的神经网络的最新方法仍取得了可喜的结果,在大多数测试集中都超过了这一硬性基准。
(2)2017年的论文《Neural Sequence Learning Models for Word Sense Disambiguation(用于词义消歧的神经序列学习模型)》
即使受监督的系统往往表现出最佳的准确性,但他们往往会败给更灵活的基于知识的解决方案,因为这些基于知识的解决方案不需要词汇专家针对每个消歧目标词进行训练。
为了缩小这一差距,论文作者采用了不同的视角,并依靠序列学习来框架化消歧问题:作者提出并深入研究了一系列直接针对该任务的端到端神经体系结构,从双向长短期记忆到编码器-解码器模型。对标准基准测试和多种语言的广泛评估表明,序列学习可以实现更通用的全单词模型,以达到最先进的结果,甚至可以与设计特征的专家抗衡。
(3)2016年的论文《context2vec: Learning Generic Context Embedding with Bidirectional LSTM(语境化词向量表示:基于双向lstm的通用上下文嵌入学习)》
作者提出了一种神经模型,其主要目标是为目标词周围的长度可变的句子上下文学习通用的与任务无关的嵌入函数。该模型可以使用双向LSTM从大型语料库中有效学习通用的上下文嵌入功能。通过非常简单地应用上下文表示,作者在词义消歧等任务上都达到或超过了最新的结果,同时大大胜过了平均单词嵌入的流行上下文表示。
(4)2018年的论文《Deep contextualized word representations(深度上下文化的单词表示)》
作者介绍了一种新型的深层上下文化词表示形式,该模型可以针对以下两种情况进行建模:首先是单词使用的复杂特征(例如语法和语义),其次是这些用法如何在语言上下文中变化(即建模多义性)。作者使用的词向量是深度双向语言模型(biLM)内部状态中学习过的函数功能,该模型在大型文本语料库上进行了预训练。
(5)2018年的论文《Incorporating Glosses into Neural Word Sense Disambiguation(将Gloss纳入神经词义消歧)》
词义歧义消除(WSD)旨在识别特定上下文中多义词的正确含义。事实证明,诸如WordNet之类的词汇资源对于WSD的基于知识的方法大有帮助。但是,以前的WSD神经网络始终依靠大量的标记数据(上下文),而忽略了如修饰词(语义定义)的词汇资源。在本文中,我们将目标词的上下文和修饰语整合到一个统一的框架中,以充分利用标记的数据和词汇知识。因此,我们提出GAS:一种修饰语增强的WSD神经网络,该网络联合编码目标单词的上下文和修饰语。 GAS在改进的记忆网络框架中对上下文和修饰语之间的语义关系进行建模,从而打破了之前受监督的方法和基于知识的方法的障碍。作者通过词语在WordNet中的语义关系来扩展词义的原始修饰词,以丰富修饰词信息。实验结果表明,作者的模型在几个英语全单词WSD数据集上的性能优于最新系统。
(6)2010年的论文《It makes sense: A wide-coverage word sense disambiguation system for free text(这是说得通的:适用于自由文本的广泛词义消除歧义系统)》
基于监督学习的单词歧义消除(WSD)系统在SensEval和SemEval研讨会上取得了最佳表现。 但是,很少有公开可用的开源WSD系统。 这限制了WSD在其他应用程序中的使用,特别是对于那些研究兴趣不在WSD中的研究人员。 在本文中,作者介绍了IMS,一种受监督的英语全语言WSD系统。 IMS的灵活框架允许用户集成不同的预处理工具、其他的功能和不同的分类器。 默认情况下,IMS使用具有多个基于知识的特征的线性支持向量机作为分类器。 在作者的实验中,IMS在多个SensEval和SemEval任务上得到了最优的结果。
(7)2016年的论文《Embeddings for Word Sense Disambiguation: An Evaluation Study(词义消歧中的词嵌入:一项评估研究)》
近年来,由于词嵌入能够从大量文本内容中捕获语义信息,词嵌入的流行程度有了显着增长。因此,自然语言处理中的许多任务都试图利用这个分布模型的潜力。在这项工作中,作者研究了如何在自然语言处理和人工智能领域最古老的任务之一“词义消歧”中使用词嵌入。作者提出了可以在最新的监督WSD系统体系结构中使用不同方法加入词嵌入,并对不同的参数如何影响性能进行了深入的分析。 作者展示了在设计得当的情况下,仅使用单词嵌入的WSD系统,如何能够比结合了几个标准WSD功能的最新WSD系统显著提高性能。
(8)2014年的论文《Entity Linking meets Word Sense Disambiguation: a Unified Approach(实体连接遇到词义歧义:一个统一方法)》
实体链接(EL)和词义歧义消除(WSD)都解决了语言的词汇歧义。 但是,尽管这两个任务非常相似,但是它们在基本方面有所不同:在EL中,文本提及的内容可以链接到可能包含或不包含确切提及的命名实体,而在WSD中,单词形式(确切的说是它的引理)和合适的词义之间是完全匹配的 。 在本文中,作者介绍Babelfy,一种基于图的EL和WSD统一方法,其基于候选含义的松散识别、选择了高一致性语义解释的最密集的子图启发式算法。 作者的实验显示了两项任务在6种不同数据集(包括多语言设置)上均表现出最佳性能。
同时可以在线上http://babelfy.org获取Babelfy。
(9)2014年的论文《Random Walks for Knowledge-Based Word Sense Disambiguation(随机游走的词义消歧算法)》
词义消歧(WSD)系统会自动根据上下文选择词的预期含义。 在本文中,作者提出了一种基于大型词法知识库(LKB)上的随机游走的WSD算法。 作者证明,在基于WordNet和扩展WordNet构建的图形上运行时,作者的算法比其他基于图形的方法性能更好。 作者的算法和LKB的组合与文献中使用相似知识结合其他各种英语数据集和西班牙语数据集的其他基于知识的方法相比具有优势。 同时,作者对影响算法的因素进行了详细分析。
(10)2018年的论文《Knowledge-based Word Sense Disambiguation using Topic Models(使用主题模型的基于知识的词义消歧)》
词义消除歧义是自然语言处理中的一个开放性问题,在无监督的环境中特别具有挑战性且有用,在这种情况下,任何给定文本中的所有词都需要消除歧义而不使用任何标记的数据。通常,WSD系统使用目标单词周围的句子或单词的小窗口作为消除歧义的上下文,因为它们的计算复杂度随上下文的大小呈指数级增长。在本文中,作者利用主题模型的形式主义设计了一种WSD系统,该系统随上下文中的单词数量线性扩展。结果,作者的系统能够将整个文档用作要消除歧义的单词的上下文。作者所提出的方法是潜在Dirichlet分配的一种变体,其中文档的主题比例被替换为同义词集比例。作者通过在单词上的同义词集分布之前分配均匀一致的优先级,并在文档上通过同义词集分配逻辑正则优先级来进一步利用WordNet中的信息。我们在Senseval-2,Senseval-3,SemEval-2007, SemEval2013和SemEval-2015英语全单词WSD数据集显示,它的性能明显优于最新的无监督知识型WSD系统。
(11)2017年的论文《SUPWSD:A Flexible Toolkit for Supervised Word Sense Disambiguation(SUPWSD:监督式词义消歧方法的灵活工具包)》
在此演示中,作者介绍了SUPWSD,这是一种用于监督式词义消除歧义的Java API。 该工具包包括实施最新的监督WSD系统以及用于预处理和特征提取的自然语言处理管道。作者的目标是为研究社区提供一种易于使用的工具,该工具的设计特点为模块化、快速且可扩展的,可用于对大型数据集进行训练和测试。
SUPWSD的源代码可在http://github.com/SI3P/SupWSD获得。
(12)2018年的论文《The risk of sub-optimal use of Open Source NLP Software: UKB is inadvertently state-of-the-art in knowledge-based WSD(开源NLP软件使用不佳的风险:UKB在基于知识的WSD中无意中处于最新状态)》
UKB是一个开源程序集合,用于执行基于知识的词义消除歧义(WSD)等任务,自2009年发布以来,它经常在次优设置中开箱即用。 作者证明,九年后,这是基于知识的WSD的最新技术。 这种情况说明了在没有最佳默认设置和精确的可重复性说明的情况下发布开源NLP软件的陷阱。
(13)2019年的论文《GlossBERT: BERT for Word Sense Disambiguation with Gloss Knowledge(GlossBERT:BERT通过Gloss知识消除词义歧义)》
词义消歧(WSD)的目的是在特定上下文中找到歧义词的确切含义。 传统的监督方法很少考虑诸如WordNet之类的词法资源,后者在基于知识的方法中得到了广泛的利用。 最近的研究表明,将修饰词(感官定义)纳入WSD神经网络的有效性。但是,与传统的词专家监督方法相比,它们并没有取得太大的进步。 在本文中,作者专注于如何在监督的神经WSD系统中更好地利用修饰词知识。 作者构造了上下文修饰词对,并为WSD提出了三个基于BERT的模型。 作者对预训练的BERT模型进行微调,并在WSD任务1上获得了最新的最新结果。
(14)2019年的论文《Sense Vocabulary Compression through the Semantic Knowledge of WordNet for Neural Word Sense Disambiguation
(通过WordNet语义知识进行感知词汇压缩,以消除神经词义歧义)》
在本文中,作者通过利用同义词,上位词和下位词等语义之间的语义关系,来压缩普林斯顿WordNet的有义词汇,从而解决了用于词义消除歧义的人工意义注释语料库数量有限的问题。因此,减少了必须消除词汇数据库中所有单词的歧义来消除所有意义标签的词的数量。
作者提出了两种不同的方法,它们可以极大地减小神经网络WSD模型的大小,并且可以在不增加额外训练数据且不影响其准确性的情况下提高其覆盖范围。
除了作者的方法外,作者还提供了一种WSD系统,该系统依赖于预训练的BERT字向量,以实现在所有WSD评估任务上均明显优于最新技术的结果。
除了上述在英语领域内的有关词义消歧的文献综述介绍之外,特别介绍一下这篇2017年九月发表的论文:
《Train-O-Matic Large-Scale Supervised Word Sense Disambiguation in Multiple Languages without Manual Training Data(Train-O-Matic:无需人工培训数据即可在多种语言中进行大规模监督的词义消歧)》
用感官注释大量句子是当前词义消歧的最重要要求。 作者介绍了Train-O-Matic,这是一种独立于语言的方法,可为语言词汇中几乎所有单词的含义生成数百万个带有感官注释的训练实例。这种方法是完全自动的:不需要人工干预,并且唯一使用的人类知识类型是类似于WordNet的资源。
Train-O-Matic在金标准数据集和各种语言上始终保持最先进的性能,同时消除了手动注释的负担。
所有训练数据都可以在http://trainomatic.org上获得以用于研究目的。