B+树
B+树中,所有记录节点都按照键值的大小顺序放在同一层叶子节点,各个叶子节点指针进行连接。
图中指针是单向的,但是书上的图是双向的,而且旋转应该也是双向才能完成)
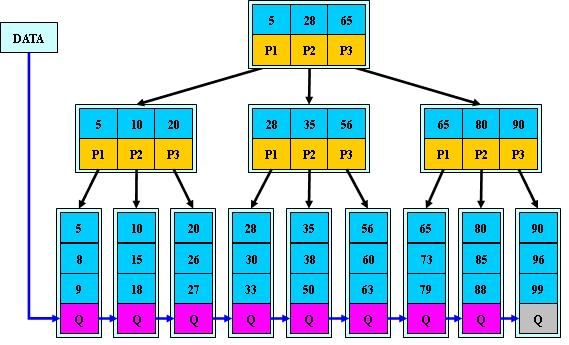
B+树插入处理
| Leaf Page满 | Index Page 满 | 操作 |
|---|---|---|
| No | No | 直接插入到叶子节点 |
| Yes | No | 1. 拆分Leaf Page 2.将中间的节点值加入到Index Page中 3. 中间节点左边的记录放拆分后的左页 4. 其余(包括中间节点)放右页 |
| Yes | Yes | 1. 拆分Leaf Page,步骤与上条一致(当作IndexPage还未满) 2. 拆分Index Page,将其与普通Leaf Page看待 |
页拆分意味着层次增加,因此B+树也会进行旋转。当Leaf Page满了的时候,会去查看其左右兄弟页是否已满,若未满则会移动记录到兄弟页上,通常顺序是先左后右。
B+树删除操作
删除合并叶子的标准是填充因子(fill factor),50%是可以设置的最小值。
| Leaf Page小于填充因子 | Index Page 小于填充因子 | 操作 |
|---|---|---|
| No | No | 直接在叶子节点中删除该记录,若该记录是Index Page中的值则将该记录的右边记录代替 |
| Yes | No | 合并叶子节点和它的兄弟节点,更新Index Page |
| Yes | Yes | 1. 合并叶子节点和其兄弟节点 2. 更新Index Page 3. 合并Index Page和其兄弟节点 |
B+树索引
聚集索引
- Innodb中每张表都会有一个聚集索引,其行记录存在该索引的叶子节点上。
- 叶子节点通过双向链表链接,按照主键的顺序排序
- 页中的记录也是双向链表进行维护,物理上可以不按照顺序存储。
- 所有索引只能定位到页,不能通过索引定位到具体的行,到页后通过Page Directory确定行。
辅助索引
叶子节点不包含行记录,只有创建索引定义的值和一个指针(叫书签)指向其对应的聚集索引叶节点。
B+树索引分裂
因为索引的顺序很多情况下是递增的,如果此时还从中间分裂的话会导致很大的浪费,因此对其进行部分改进。
- 如果插入是随机的,取页的中间记录作为分裂点记录。
- 若同一方向进行插入的记录数为5,且如果插入新记录的位置后,如果还有3条记录则分裂点在其后第3条记录,如果没有3条那么分裂点就是新插入的这条记录(新记录分到新页)
B+树索引管理
1. 索引管理
show index from tablename可查看索引信息,其中Cardinality表示索引中唯一值的估计值(最好能接近1,如果非常小则可以考虑删除该索引),优化器根据该值判断是否选择使用该索引。- cardinality值是通过简单抽样统计出来的,默认随机取8个叶子节点数据统计其平均值(不足8页则全取)。
- cardinality更新策略:表中1/16的数据已经发生变化或
stat_modified_counter>2000000000(每个表维护一个stat_modified_counter,每次DML更新1行就加1,直到满足阈值则自动收集统计信息,并把此值清0;)
2. Fast Index Creation
Mysql5.5之前添加或删除索引的操作过程:
1. 创建新临时表,再通过Alter table定义新结构
2. 将原表数据导入临时表
3. 删除原表,将临时表重命名进行操作时不可访问。
- Fast Index Creation(FIC)会对创建索引的表加S锁,不需要建新表。删除索引则只更新数据库内部视图删除对该索引的定义即可。
- FIC可以使修改索引时提供查询操作,然而事物操作还是不能提供。
3. Online Schema Change
在线架构改变(OSC),在修改索引是可以同时进行事物处理。步骤如下:
1.检查必要条件,如表是否有主键等。
2.创建与原始表相同表,并修改其索引或列。
3.创建deltas表,对原表创建insert、update和delete触发器,将产生的记录写入deltas表
4.开始OSC操作事物
5.将原表数据写入新表
6.将deltas表记录事物回放
7.交换表名,需要锁两张表。书上的步骤写的有点不懂,为什么导数据前要先删除新表索引?所以只简略写下大致步骤
4. Online DDL
Mysql5.6开始支持,允许辅助索引创建与删除、改变自增长值、添加删除外键约束和列重命名时进行DML操作。
alter table table_name
| add {index|key} [index_name]
[index_type] (index_col_name,...) [index_option]..
algorithm [=] {default|inplace|copy}
lock [=] {default|none|shared|exclusive}- algorithm指定修改索引的算法,copy表示创建临时表方法,inplace表示不需要临时表,default则根据配置文件选。
- lock为修改索引时对表加锁情况,none不加任何锁,share加S锁,exclusive加X锁,default则按照前面的顺序判断是否可用。
- 原理是在执行过程中将DML操作日志写入缓存中,等索引创建后再重新应用到表上。
B+树索引的使用
- 联合索引,索引的有序性可用于排序,减少内存排序。
- 覆盖索引,当要查询的值都在一个二级索引时,此时不需要去聚集索引查询记录值可直接返回结果。
- from table_name force index(filed_name) where ...,可强制使用索引。
- using index 是告诉优化器可以选择该索引
Multi-Range Read 优化
减少随机IO,将随机IO转化为顺序IO。主要有利于范围查询
工作方式:
1. 将查询的辅助索引值放入缓存
2. 对缓存中键值RowId进行排序
3. 根据RowId顺序load 页
还可以将某些范围查询拆分为键值对,以此批量查询数据。Index Condition Pushdown优化
ICP在使用索引时会对where条件进行过滤(以前是不过滤直接查出所有记录再筛选)再去获取记录,前提是条件字段必须能在该索引覆盖范围内。
全文索引
Innodb1.2开始支持全文索引,原理还是倒排索引。
倒排索引
- 倒排索引在辅助表(auxiliary table)中存储词与文档的映射关系(主键是词)。
- inverted file index,{词,docIdList}
- full inverted index,{词,(docId:position)...},innodb使用此形式。
Innodb全文检索
- 将(docId,position)看作一个ilist,其全文检索表中有两列,word和ilist,word列建有索引。
- 其共有6张辅助表,每张表根据word的Latin编码进行分区。
- 辅助表是持久表,存放在磁盘。
- FTS Index Cache(全文检索索引缓存)是一个红黑树,根据(word,ilist)排序。
- 插入数据分词后,数据不直接写入辅助表,而是写入FTS Index Cache,其查询将会把Cache与辅助表合并。
- 事物提交时写入FTS Index Cache,然后再通过批量更新写入磁盘。
- 当宕机使FTS Index Cache数据丢失,则下次当使用全文检索时Innodb将自动读取未完成的文档,然后进行分此操作,再将分词结果写入FTS Index Cache。
- 使用全文索引的表必须有一个字段与word进行映射,命名为FTS_DOC_ID类型必须为BIGINT UNSIGNED NOT NULL,若没有则将自动创建并加上unique index。
- 删除记录时不删除辅助表的记录,只删除FTS Index Cache中记录,并将docId保存在DELETE辅助表
- 全文检索限制:每张表只能用一个全文检索索引、多列组合的必须使用相同字符集与排序规则、不支持中文。。。