Python合并两Excel表格并写入新表格,数据加工统计 ,Python查询目录下所有重复文件并输出路径和名字
(1)查找硬盘中的所有重复文件,并列出每组重复文件中每个文件的文件名、文件大小、位置和创建日期【不是重名文件!!用md5值判断是否是相同文件】
import hashlib
import os
from collections import Counter
import time
import datetime
def get_md5_01(file_path):
md5 = None
if os.path.isfile(file_path): #防止报错,存在该文件时才读取
f = open(file_path, 'rb')#二进制模式读取文件
md5_obj = hashlib.md5() #创建hash对象,md5:(message-Digest Algorithm 5)消息摘要算法,得出一个128位的密文
md5_obj.update(f.read())#更新哈希对象,以字符串为参数 ,此处为读入的文件内容
hash_code = md5_obj.hexdigest()#返回摘要,作为十六进制数据字符串值 23eeeb4347bdd26bfc6b7ee9a3b755dd
f.close()
md5 = str(hash_code).lower()#计算的md5值变为小写
return md5
#
# def get_md5_02(file_path):
# f = open(file_path, 'rb')
# md5_obj = hashlib.md5()
# while True:
# d = f.read(8096)
# if not d:
# break
# md5_obj.update(d)
# hash_code = md5_obj.hexdigest()
# f.close()
# md5 = str(hash_code).lower()
# return md5
def TimeStampToTime(timestamp):
timeStruct = time.localtime(timestamp)
return time.strftime('%Y-%m-%d %H:%M:%S',timeStruct)
def get_FileSize(filePath):
fsize = os.path.getsize(filePath)#文件大小,字节为单位,转换成兆
fsize = fsize/float(1024*1024)
return round(fsize,2)
def get_FileCreateTime(filePath):
t = os.path.getctime(filePath)
return TimeStampToTime(t)
if __name__ == "__main__":
output_list = []
output_path = os.getcwd()#返回当前工作目录
print(output_path)
g = os.walk(output_path)#返回当前目录的路径,文件夹名(目录列表),文件列表
for path, dir_list, file_list in g:#遍历顺序以目录树的形式,不断递归到更深层的文件夹内
print(dir_list,'----->')
print(file_list)
for file_name in file_list:
output_list.append(os.path.join(path, file_name))#输出文件路径和文件名,并将主目录路径和文件列表组合成完整路径,将每个文件组装好的路径放入output列表中
md5_list = [get_md5_01(i) for i in output_list]#对所有文件求md5值,并存在列表中
Counter_list = Counter(md5_list)#该函数直接对求得的所有md5值计数,并用字典标记每个md5值的出现次数
print(Counter_list)
for i in Counter_list.items():
# print(type(i),i)#items()返回一个元组,表示dict的 键-值,[0]为键,[1]为值
if i[1] > 1:#一个计数大于1的md5值说明重复出现
duplicate_list = [a for a in range(len(md5_list)) if md5_list[a] == i[0]]#遍历所有md5值,符合条件的文件下标存下
print(i[0])#中奖的md5值
for j in duplicate_list:#将符合条件的文件信息输出
# with open('duplicate.log', mode='a+') as f:
# f.write(i[0] +'\t' + output_list[j] + '\n')
print('文件路径',output_list[j])
print('文件大小',get_FileSize(output_list[j]), 'M')
print('文件创建时间',get_FileCreateTime(output_list[j]))
print('文件绝对路径',os.path.abspath(output_list[j]))
(2)合并两个Excel文件中的数据,并将合并后的数据写入一个新的Excel文件。然后将五星~一星评价数转化为百分数的形式(只保留整数,不写百分号);统计8分以上和9分以上的书籍数目,以及两个分组(8分 分组和9分 分组)中5星和4星评价的平均值
操作用到的两个表格名为:doubanbook-1.xlsx、doubanbook-2.xlsx
生成的合并新表格为result_excel.xlsx
调用xlrd和xlsxwriter包实现,需要使用pip下载包
运行结果:
#将多个Excel文件合并成一个
import xlrd
import xlsxwriter
#打开一个excel文件
def open_xls(file):
fh=xlrd.open_workbook(file)
return fh
#获取excel中所有的sheet表
def getsheet(fh):
return fh.sheets()
#获取sheet表的行数
# def getnrows(fh,sheet):
# table=fh.sheets()[sheet]
# return table.nrows
def changestart(x,y):
return int(x/y*100)
#读取文件内容并返回行内容
def getFilect(file,shnum):
fh=open_xls(file)#第fl个文档 的第shnum个表
table=fh.sheets()[shnum]#第shnum个表
num=table.nrows#得到行数
for row in range(num):#遍历这个表的所有行
tot=0
rdata=table.row_values(row)#整行信息
# print(rdata)
if type(rdata[8])==float:
if rdata[2]>=8:
global s84
s84+=rdata[5]
global s85
s85+=rdata[4]
if rdata[2]>=9:
global s94
s94+=rdata[5]
global s95
s95+=rdata[4]
for star in range(4,9):
tot+=rdata[star]
for i in range(4,9):
rdata[i]=changestart(rdata[i], tot)
datavalue.append(rdata)
return datavalue#包含了该表中所有行信息
#获取sheet表的个数
def getshnum(fh):
x=0
sh=getsheet(fh)#所有表
for sheet in sh:
x+=1
return x
if __name__=='__main__':
#定义要合并的excel文件列表
allxls=['D:\KuroNeko\Desktop\程序语言\python\doubanbook-1.xlsx','D:\KuroNeko\Desktop\程序语言\python\doubanbook-2.xlsx']
#存储所有读取的结果
datavalue=[]
global f8, f9, s84, s85, s94, s95
f8=f9=s84=s85=s94=s95=0
for fl in allxls:
fh=open_xls(fl)#读入文档
x=getshnum(fh)#统计表个数
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue=getFilect(fl,shnum)#读入表内容
#定义最终合并后生成的新文件
endfile='D:\KuroNeko\Desktop\程序语言\python\\result_excel.xlsx'
wb1=xlsxwriter.Workbook(endfile)# 建立合并结果文件
#创建一个sheet工作对象
ws=wb1.add_worksheet()#建表
for a in range(len(rvalue)): #遍历读入完所有文档所有表的列表,其中a为很多行,b为每行的内容
for b in range(len(rvalue[a])):
c=rvalue[a][b]
if(b==2 and type(c)!=str):
if c>=8:f8+=1
if c>=9:f9+=1
ws.write(a,b,c)#表的a行b列写入内容c
wb1.close()
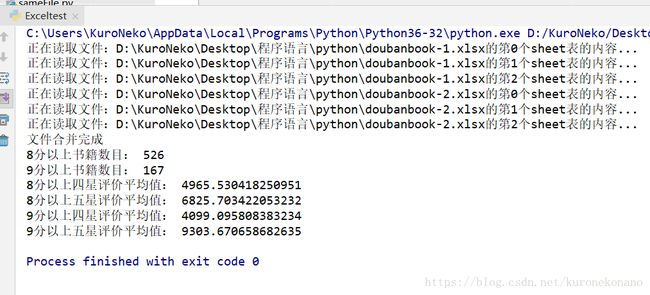
print("文件合并完成")
print('8分以上书籍数目:',f8)
print('9分以上书籍数目:',f9)
print('8分以上四星评价平均值:',s84/f8)
print('8分以上五星评价平均值:',s85/f8)
print('9分以上四星评价平均值:',s94/f9)
print('9分以上五星评价平均值:',s95/f9)