Scikit-learn:模型评估Model evaluation
http://blog.csdn.net/pipisorry/article/details/52250760
模型评估Model evaluation: quantifying the quality of predictions
3 different approaches to evaluate the quality of predictions of a model:
- Estimator score method: Estimators have a score method providing a default evaluation criterion for the problem they are designed to solve. This is not discussed on this page, but in each estimator’s documentation.
- Scoring parameter: Model-evaluation tools using cross-validation (such as cross_validation.cross_val_scoreand grid_search.GridSearchCV) rely on an internal scoring strategy. This is discussed in the section The scoring parameter: defining model evaluation rules.
- Metric functions: The metrics module implements functions assessing prediction error for specific purposes. These metrics are detailed in sections on Classification metrics, Multilabel ranking metrics, Regression metrics and Clustering metrics.
Finally, Dummy estimators are useful to get a baseline value of those metrics for random predictions.
For “pairwise” metrics, between samples and not estimators or predictions, see the Pairwise metrics, Affinities and Kernels section.
sklearn一般评估方法
The scoring parameter: defining model evaluation rules
| Scoring | Function | Comment |
|---|---|---|
| Classification | ||
| ‘accuracy’ | metrics.accuracy_score |
|
| ‘average_precision’ | metrics.average_precision_score |
|
| ‘f1’ | metrics.f1_score |
for binary targets |
| ‘f1_micro’ | metrics.f1_score |
micro-averaged |
| ‘f1_macro’ | metrics.f1_score |
macro-averaged |
| ‘f1_weighted’ | metrics.f1_score |
weighted average |
| ‘f1_samples’ | metrics.f1_score |
by multilabel sample |
| ‘neg_log_loss’ | metrics.log_loss |
requires predict_proba support |
| ‘precision’ etc. | metrics.precision_score |
suffixes apply as with ‘f1’ |
| ‘recall’ etc. | metrics.recall_score |
suffixes apply as with ‘f1’ |
| ‘roc_auc’ | metrics.roc_auc_score |
|
| Clustering | ||
| ‘adjusted_rand_score’ | metrics.adjusted_rand_score |
|
| Regression | ||
| ‘neg_mean_absolute_error’ | metrics.mean_absolute_error |
|
| ‘neg_mean_squared_error’ | metrics.mean_squared_error |
|
| ‘neg_median_absolute_error’ | metrics.median_absolute_error |
|
| ‘r2’ | metrics.r2_score |
使用如cross_val_score(clf, X, y, scoring='neg_log_loss')
Note:计算auc值的时候需要注意的一点是,sklearn.metric.roc_auc_score(y_actual, y_pred)才是计算ROC AUC的,而sklearn.metrics.auc(x,y)是计算折线与x轴之间的面积,x是折线上点的横坐标,y是折线上点的纵坐标。而且需要注意的是,y_actual必须是二类的,不能是连续数值(如果是,那么就需要自己利用sklearn.metrics.auc写一个计算面积的函数了)。
[Common cases: predefined values¶]
自定义scoring函数
>>> import numpy as np >>> def my_custom_loss_func(ground_truth, predictions): ... diff = np.abs(ground_truth - predictions).max() ... return np.log(1 + diff) ... >>> # loss_func will negate the return value of my_custom_loss_func, >>> # which will be np.log(2), 0.693, given the values for ground_truth >>> # and predictions defined below. >>> loss = make_scorer(my_custom_loss_func, greater_is_better=False) >>> score = make_scorer(my_custom_loss_func, greater_is_better=True) >>> ground_truth = [[1, 1]] >>> predictions = [0, 1] >>> from sklearn.dummy import DummyClassifier >>> clf = DummyClassifier(strategy='most_frequent', random_state=0) >>> clf = clf.fit(ground_truth, predictions) >>> loss(clf,ground_truth, predictions) -0.69... >>> score(clf,ground_truth, predictions) 0.69...交叉验证自定义scoring函数
def rocAucScorer(*args): ''' 自定义ROC-AUC评价指标rocAucScorer(clf, x_test, y_true) :param y_true: y_test真值 :param x_test: x测试集 ''' from sklearn import metrics # y值比对函数 fun = lambda yt, ys: metrics.roc_auc_score([1.0 if _ > 0.0 else 0.0 for _ in yt], np.select([ys < 0.0, ys > 1.0, True], [0.0, 1.0, ys])) return metrics.make_scorer(fun, greater_is_better=True)(*args)[Defining your scoring strategy from metric functions ¶]
或者You can generate even more flexible model scorers by constructing your ownscoring object from scratch, without using the make_scorer factory.For a callable to be a scorer, it needs to meet the protocol specified bythe following two rules:
- It can be called with parameters
(estimator, X, y), whereestimatoris the model that should be evaluated,Xis validation data, andyisthe ground truth target forX(in the supervised case) orNone(in theunsupervised case). - It returns a floating point number that quantifies the
estimatorprediction quality onX, with reference toy.Again, by convention higher numbers are better, so if your scorerreturns loss, that value should be negated.
def rocAucScorer(clf, x_test, y_true): ''' 自定义ROC-AUC评价指标 :param y_true: y_test真值 :param x_test: x测试集 ''' from sklearn import metrics ys = clf.predict(x_test) score = metrics.roc_auc_score([1.0 if _ > 0.0 else 0.0 for _ in y_true], np.select([ys < 0.0, ys > 1.0, True], [0.0, 1.0, ys])) return score
[Implementing your own scoring object¶]
皮皮blog
分类模型评估
分类模型评估方法
Some of these are restricted to the binary classification case:
matthews_corrcoef(y_true, y_pred[, ...]) |
Compute the Matthews correlation coefficient (MCC) for binary classes |
precision_recall_curve(y_true, probas_pred) |
Compute precision-recall pairs for different probability thresholds |
roc_curve(y_true, y_score[, pos_label, ...]) |
Compute Receiver operating characteristic (ROC) |
Others also work in the multiclass case:
cohen_kappa_score(y1, y2[, labels, weights]) |
Cohen’s kappa: a statistic that measures inter-annotator agreement. |
confusion_matrix(y_true, y_pred[, labels, ...]) |
Compute confusion matrix to evaluate the accuracy of a classification |
hinge_loss(y_true, pred_decision[, labels, ...]) |
Average hinge loss (non-regularized) |
Some also work in the multilabel case:
accuracy_score(y_true, y_pred[, normalize, ...]) |
Accuracy classification score. |
classification_report(y_true, y_pred[, ...]) |
Build a text report showing the main classification metrics |
f1_score(y_true, y_pred[, labels, ...]) |
Compute the F1 score, also known as balanced F-score or F-measure |
fbeta_score(y_true, y_pred, beta[, labels, ...]) |
Compute the F-beta score |
hamming_loss(y_true, y_pred[, labels, ...]) |
Compute the average Hamming loss. |
jaccard_similarity_score(y_true, y_pred[, ...]) |
Jaccard similarity coefficient score |
log_loss(y_true, y_pred[, eps, normalize, ...]) |
Log loss, aka logistic loss or cross-entropy loss. |
precision_recall_fscore_support(y_true, y_pred) |
Compute precision, recall, F-measure and support for each class |
precision_score(y_true, y_pred[, labels, ...]) |
Compute the precision |
recall_score(y_true, y_pred[, labels, ...]) |
Compute the recall |
zero_one_loss(y_true, y_pred[, normalize, ...]) |
Zero-one classification loss. |
And some work with binary and multilabel (but not multiclass) problems:
average_precision_score(y_true, y_score[, ...]) |
Compute average precision (AP) from prediction scores |
roc_auc_score(y_true, y_score[, average, ...]) |
Compute Area Under the Curve (AUC) from prediction scores |
分类准确率(Classification accuracy)
# calculate accuracy
from sklearn import metrics
print metrics.accuracy_score(y_test, y_pred_class)
0.692708333333
分类准确率分数
是指所有分类正确的百分比。
空准确率(null accuracy)
是指当模型总是预测比例较高的类别,那么其正确的比例是多少。
# examine the class distribution of the testing set (using a Pandas Series method)
y_test.value_counts()
# calculate the percentage of ones
y_test.mean()
# calculate the percentage of zeros
1 - y_test.mean()
# calculate null accuracy(for binary classification problems coded as 0/1)
max(y_test.mean(), 1-y_test.mean())
我们看到空准确率是68%,而分类准确率是69%,这说明该分类准确率并不是很好的模型度量方法,分类准确率的一个缺点是其不能表现任何有关测试数据的潜在分布。
# calculate null accuracy (for multi-class classification problems)
y_test.value_counts().head(1) / len(y_test)
比较真实和预测的类别响应值:
# print the first 25 true and predicted responses
print "True:", y_test.values[0:25]
print "Pred:", y_pred_class[0:25]
从上面真实值和预测值的比较中可以看出,当正确的类别是0时,预测的类别基本都是0;当正确的类别是1时,预测的类别大都不是1。换句话说,该训练的模型大都在比例较高的那项类别的预测中预测正确,而在另外一中类别的预测中预测失败,而我们没法从分类准确率这项指标中发现这个问题。
分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型。接下来介绍的混淆矩阵可以识别这个问题。
基于混淆矩阵的评估度量
混淆矩阵
混淆矩阵赋予一个分类器性能表现更全面的认识,同时它通过计算各种分类度量,指导你进行模型选择。
# IMPORTANT: first argument is true values, second argument is predicted values
print metrics.confusion_matrix(y_test, y_pred_class)
[[118 12]
[ 47 15]]
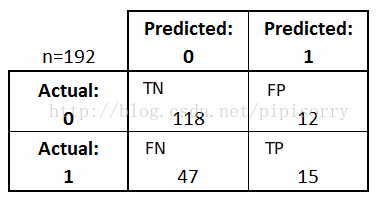
- 真阳性(True Positive,TP):指被分类器正确分类的正例数据
- 真阴性(True Negative,TN):指被分类器正确分类的负例数据
- 假阳性(False Positive,FP):被错误地标记为正例数据的负例数据
- 假阴性(False Negative,FN):被错误地标记为负例数据的正例数据
准确率、识别率(Classification Accuracy):分类器正确分类的比例
print (TP+TN) / float(TP+TN+FN+FP)
print metrics.accuracy_score(y_test, y_pred_class)
错误率、误分类率(Classification Error):分类器误分类的比例
print (FP+FN) / float(TP+TN+FN+FP)
print 1-metrics.accuracy_score(y_test, y_pred_class)
考虑类不平衡问题,其中感兴趣的主类是稀少的。即数据集的分布反映负类显著地占多数,而正类占少数。故面对这种问题,需要其他的度量,评估分类器正确地识别正例数据的情况和正确地识别负例数据的情况。
召回率(Recall),也称为真正例识别率、灵敏性(Sensitivity)、查全率:正确识别的正例数据在实际正例数据中的百分比
print TP / float(TP+FN)
print metrics.recall_score(y_test, y_pred_class)
特效性(Specificity),也称为真负例率:正确识别的负例数据在实际负例数据中的百分比
print TN / float(TN+FP)
假阳率(False Positive Rate):实际值是负例数据,预测错误的百分比
print FP / float(TN+FP)
specificity = TN / float(TN+FP)
print 1 - specificity
精度(Precision):看做精确性的度量,即标记为正类的数据实际为正例的百分比
print TP / float(TP+FP)
precision = metrics.precision_score(y_test, y_pred_class)
print precision
F度量(又称为F1分数或F分数),是使用精度和召回率的方法组合到一个度量上
F度量是精度和召回率的调和均值,它赋予精度和召回率相等的权重。
Fβ度量是精度和召回率的加权度量,它赋予召回率权重是赋予精度的β倍。
print (2*precision*recall) / (precision+recall)
print metrics.f1_score(y_test, y_pred_class)
sklearn评估报告
from sklearn import metrics
# summarize the fit of the model
print(metrics.classification_report(expected, predicted)) precision recall f1-score support
0 0.96 0.77 0.86 4950
1 0.18 0.62 0.28 392
avg / total 0.90 0.76 0.81 5342
Note: 如0.18就是正例1对应的precision。
Precision-Recall曲线
sklearn.metrics.precision_recall_curve(y_true, probas_pred, pos_label=None, sample_weight=None)
参数
y_true : array, shape = [n_samples]
True targets of binary classification in range {-1, 1} or {0, 1}. 也就是二分类的binary。
probas_pred : array, shape = [n_samples]
Estimated probabilities or decision function. 必须是连续的continuous.
def plotPR(yt, ys, title=None): ''' 绘制precision-recall曲线 :param yt: y真值 :param ys: y预测值, recall, ''' import seaborn from sklearn import metrics from matplotlib import pyplot as plt precision, recall, thresholds = metrics.precision_recall_curve(yt, ys) plt.plot(precision, recall, 'darkorange', lw=1, label='x=precision') plt.plot(recall, precision, 'blue', lw=1, label='x=recall') plt.legend(loc='best') plt.plot([0, 1], [0, 1], color='navy', linestyle='--') plt.title('Precision-Recall curve for %s' % title) plt.ylabel('Recall') plt.xlabel('Precision') plt.show() plt.savefig(os.path.join(CWD, 'middlewares/pr-' + title + '.png'))[ sklearn.metrics.precision_recall_curve]
ROC曲线和AUC
[机器学习模型的评价指标和方法 :ROC曲线和AUC]
sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
参数
y_true : array, shape = [n_samples]
True targets of binary classification in range {-1, 1} or {0, 1}. 也就是二分类的binary。
y_score : array, shape = [n_samples]
Target scores, can either be probability estimates of the positiveclass, confidence values, or non-thresholded measure of decisions(as returned by “decision_function” on some classifiers).应该也必须是连续的continuous.
绘制实现
def plotRUC(yt, ys, title=None): ''' 绘制ROC-AUC曲线 :param yt: y真值 :param ys: y预测值 ''' from sklearn import metrics from matplotlib import pyplot as plt f_pos, t_pos, thresh = metrics.roc_curve(yt, ys) auc_area = metrics.auc(f_pos, t_pos) print('auc_area: {}'.format(auc_area)) plt.plot(f_pos, t_pos, 'darkorange', lw=2, label='AUC = %.2f' % auc_area) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], color='navy', linestyle='--') plt.title('ROC-AUC curve for %s' % title) plt.ylabel('True Pos Rate') plt.xlabel('False Pos Rate') plt.show() plt.savefig(os.path.join(CWD, 'middlewares/roc-' + title + '.png'))[
roc_curve(y_true, y_score[, pos_label, ...])]
[roc_auc_score(y_true, y_score[, average, ...])]
使用什么度量取决于具体的业务要求
- 垃圾邮件过滤器:优先优化精度或者特效性,因为该应用对假阳性(非垃圾邮件被放进垃圾邮件箱)的要求高于对假阴性(垃圾邮件被放进正常的收件箱)的要求
- 欺诈交易检测器:优先优化灵敏度,因为该应用对假阴性(欺诈行为未被检测)的要求高于假阳性(正常交易被认为是欺诈)的要求
皮皮blog
from: http://blog.csdn.net/pipisorry/article/details/52250760
ref: [机器学习模型的评价指标和方法 ]
[scikit-learn User Guide]
[Model selection and evaluation]
[3.3. Model evaluation: quantifying the quality of predictions]*
[3.5. Validation curves: plotting scores to evaluate models]*