hadoop组件---数据仓库(四)---hive常用命令
安装好hive的环境之后 我们可以尝试一些常用的命令,常用命令也可以作为平时工作中的速查手册。
进入hive控制台
首先需要知道hive的启动目录在哪,可以使用命令
whereis hive
启动hive shell在hive安装bin目录下使用命令
hive shell
注:如果hive环境已经加入环境变量,那么whereis时会显示/usr/bin/hive,这种情况下在任意目录运行hive shell。
如下图:
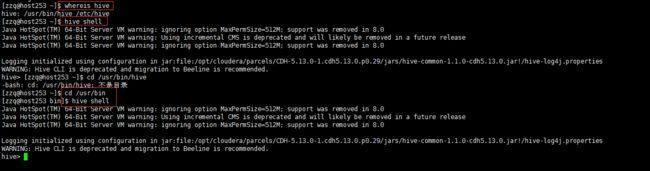
运行过程如下:
[zzq@host253 ~]$ whereis hive
hive: /usr/bin/hive /etc/hive
[zzq@host253 ~]$ hive shell
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hive-common-1.1.0-cdh5.13.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> [zzq@host253 ~] cd/usr/bin/hive−bash:cd:/usr/bin/hive:不是目录[zzq@host253 ] c d / u s r / b i n / h i v e − b a s h : c d : / u s r / b i n / h i v e : 不 是 目 录 [ z z q @ h o s t 253 ] cd /usr/bin
[zzq@host253 bin]$ hive shell
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hive-common-1.1.0-cdh5.13.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive>
新建表和导入数据
创建数据
cd /home/zzq
vim table_hive.txt
单击键盘i插入内容如下(注意间隔使用Tab键):
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
单击键盘Esc,输入:wq回车保存退出。
如下图:
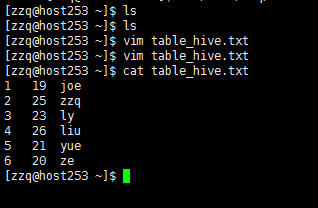
创建新表
使用命令hive shell进入hive控制台如下使用命令创建新表:
CREATE TABLE t_hive (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';如下图:

[zzq@host253 ~]$ hive shell
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hive-common-1.1.0-cdh5.13.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> CREATE TABLE t_hive (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
OK
Time taken: 3.839 seconds
hive>
说明:
数据类型需要与我们文本中的数据对应,以及确定好分隔符,如果是制表符作分隔,我们这里使用’\t’作为分隔,使用空格则使用’\s’。
导入数据table_hive.txt到表t_hive
hive支持很多数据来源,包括HDFS中的和HBase中的,详见后面的数据导入小节,我们这里先熟悉从本地路径导入的命令如下:
LOAD DATA LOCAL INPATH '/home/zzq/table_hive.txt' OVERWRITE INTO TABLE t_hive ;
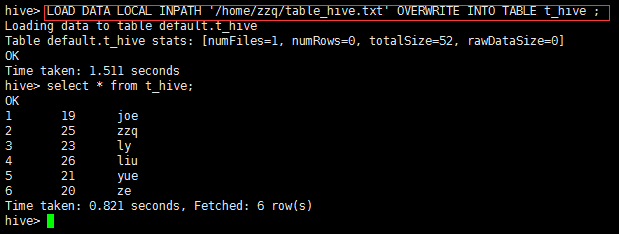
hive> LOAD DATA LOCAL INPATH '/home/zzq/table_hive.txt' OVERWRITE INTO TABLE t_hive ;
Loading data to table default.t_hive
Table default.t_hive stats: [numFiles=1, numRows=0, totalSize=52, rawDataSize=0]
OK
Time taken: 1.511 seconds
hive> select * from t_hive;
OK
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
Time taken: 0.821 seconds, Fetched: 6 row(s)
可能遇到的情况–导入数据为NULL
有时候导入数据时发现导入的数据为NULL,如图:
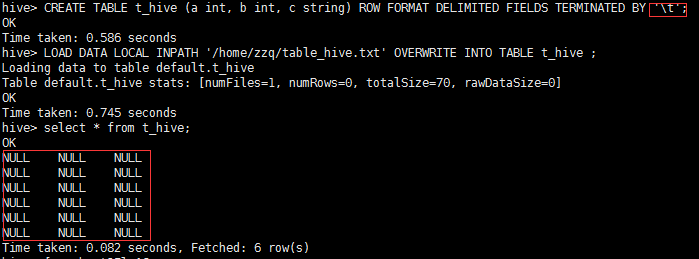
hive> CREATE TABLE t_hive (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.586 seconds
hive> LOAD DATA LOCAL INPATH '/home/zzq/table_hive.txt' OVERWRITE INTO TABLE t_hive ;
Loading data to table default.t_hive
Table default.t_hive stats: [numFiles=1, numRows=0, totalSize=70, rawDataSize=0]
OK
Time taken: 0.745 seconds
hive> select * from t_hive;
OK
NULL NULL NULL
NULL NULL NULL
NULL NULL NULL
NULL NULL NULL
NULL NULL NULL
NULL NULL NULL
Time taken: 0.082 seconds, Fetched: 6 row(s)
原因是 分隔符不对应导致的。
尤其是空格和制表符以及多个空格这种情况需要尤其注意。
解决方式,修正原数据的分隔符情况或者 修改创建语句的分隔符与之对应即可。
查看表和数据
查看表
show tables;
结果如下:
hive> show tables;
OK
t_hive
Time taken: 0.434 seconds, Fetched: 1 row(s)
正则匹配表名
show tables 'hive';
结果如下:
hive> show tables 'hive';
OK
t_hive
Time taken: 0.019 seconds, Fetched: 1 row(s)
查看表数据
select * from t_hive;
结果如下:
hive> select * from t_hive;
OK
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
Time taken: 0.146 seconds, Fetched: 6 row(s)
查看表结构
desc t_hive;
结果如下:
hive> desc t_hive;
OK
a int
b int
c string
Time taken: 0.072 seconds, Fetched: 3 row(s)
修改表
增加一个字段
ALTER TABLE t_hive ADD COLUMNS (address String);
desc t_hive;
结果如下:
hive> ALTER TABLE t_hive ADD COLUMNS (address String);
OK
Time taken: 0.669 seconds
hive> desc t_hive;
OK
a int
b int
c string
address string
Time taken: 0.07 seconds, Fetched: 4 row(s)
hive>
重命名表
ALTER TABLE t_hive RENAME TO t_hadoop;
show tables;
结果如下:
hive> ALTER TABLE t_hive RENAME TO t_hadoop;
OK
Time taken: 0.42 seconds
hive> show tables;
OK
t_hadoop
Time taken: 0.017 seconds, Fetched: 1 row(s)
hive>
删除表
DROP TABLE t_hadoop;
show tables;
结果如下:
hive> DROP TABLE t_hadoop;
OK
Time taken: 1.057 seconds
hive> show tables;
OK
Time taken: 0.019 seconds, Fetched: 0 row(s)
数据导入
首先需要准备数据文件和创建表结构。
创建数据
cd /home/zzq
vim table_hive.txt
单击键盘i插入内容如下(注意间隔使用Tab键):
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
单击键盘Esc,输入:wq回车保存退出。
创建新表
使用命令hive shell进入hive控制台如下使用命令创建新表:
hive shell
CREATE TABLE t_hive (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
从操作系统的本地文件系统加载数据LOCAL
使用命令
LOAD DATA LOCAL INPATH '/home/zzq/table_hive.txt' OVERWRITE INTO TABLE t_hive ;
结果如下:
hive> LOAD DATA LOCAL INPATH '/home/zzq/table_hive.txt' OVERWRITE INTO TABLE t_hive ;
Loading data to table default.t_hive
Table default.t_hive stats: [numFiles=1, numRows=0, totalSize=52, rawDataSize=0]
OK
Time taken: 1.511 seconds
hive> select * from t_hive;
OK
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
Time taken: 0.821 seconds, Fetched: 6 row(s)
从HDFS加载数据
从本地操作系统的文件导入hive时,hive默认会把文件给复制到HDFS文件系统中。有些版本的hive会在控制台输出复制文件在HDFS文件系统中的路径,有些版本的不会,这个时候我们首先需要找到复制文件在HDFS文件系统中的路径。
使用命令
hadoop fs -ls -R / |grep "table_hive.txt"
结果输出如下:
[zzq@host253 ~]$ hadoop fs -ls -R / |grep "table_hive.txt"
-rwxrwxrwt 3 zzq hive 52 2018-01-10 15:01 /user/hive/warehouse/t_hadoop/table_hive.txt
知道路径之后我们就可以对HDFS系统中的文件进行加载了。我们先新建一个新表t_hive2如下:
CREATE TABLE t_hive2 (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
使用HDFS加载命令如下:
LOAD DATA INPATH '/user/hive/warehouse/t_hadoop/table_hive.txt' OVERWRITE INTO TABLE t_hive2 ;
结果如下:
[zzq@host253 ~]$ hive shell
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hive-common-1.1.0-cdh5.13.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> CREATE TABLE t_hive2 (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
OK
Time taken: 3.755 seconds
hive> LOAD DATA INPATH ‘/user/hive/warehouse/t_hadoop/table_hive.txt’ OVERWRITE INTO TABLE t_hive2 ;
Loading data to table default.t_hive2
Table default.t_hive2 stats: [numFiles=1, numRows=0, totalSize=52, rawDataSize=0]
OK
Time taken: 1.158 seconds
hive> select * from t_hive2;
OK
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
Time taken: 0.968 seconds, Fetched: 6 row(s)
从其他表导入
使用命令
CREATE TABLE t_hive3 (a int, b int, c string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
INSERT OVERWRITE TABLE t_hive3 SELECT * FROM t_hive2;
输出结果如下:
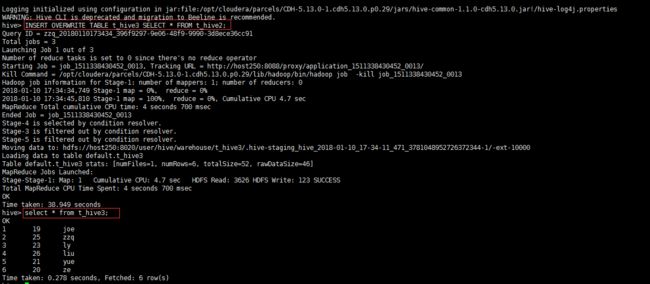
[zzq@host253 ~]$ hive shell
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hive-common-1.1.0-cdh5.13.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> INSERT OVERWRITE TABLE t_hive3 SELECT * FROM t_hive2;
Query ID = zzq_20180110173434_396f9297-9e06-48f9-9990-3d8ece36cc91
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1511338430452_0013, Tracking URL = http://host250:8088/proxy/application_1511338430452_0013/
Kill Command = /opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/bin/hadoop job -kill job_1511338430452_0013
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-01-10 17:34:34,749 Stage-1 map = 0%, reduce = 0%
2018-01-10 17:34:45,810 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.7 sec
MapReduce Total cumulative CPU time: 4 seconds 700 msec
Ended Job = job_1511338430452_0013
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://host250:8020/user/hive/warehouse/t_hive3/.hive-staging_hive_2018-01-10_17-34-11_471_3781048952726372344-1/-ext-10000
Loading data to table default.t_hive3
Table default.t_hive3 stats: [numFiles=1, numRows=6, totalSize=52, rawDataSize=46]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 4.7 sec HDFS Read: 3626 HDFS Write: 123 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 700 msec
OK
Time taken: 38.949 seconds
hive> select * from t_hive3;
OK
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
Time taken: 0.278 seconds, Fetched: 6 row(s)
可能遇到的问题Permission denied
报错情况如下:
Job Submission failed with exception 'org.apache.hadoop.security.AccessControlException(Permission denied: user=zzq, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
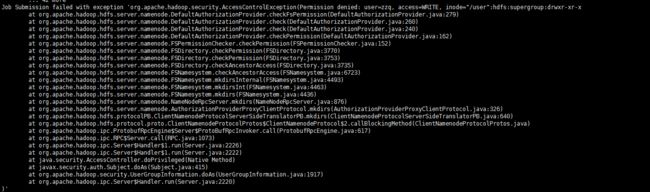
原因
执行某些hive命令时需要访问hdfs的/user目录。
在当前的用户zzq或者root用户下,没有对/user这个文件夹的权限。
查看发现/user是属于用户hdfs的。
[zzq@host253 ~]$ hadoop fs -ls /
Found 3 items
drwxr-xr-x - hbase hbase 0 2018-01-02 14:56 /hbase
drwxrwxrwt - hdfs supergroup 0 2017-11-21 19:37 /tmp
drwxr-xr-x - hdfs supergroup 0 2017-11-29 18:40 /user
解决方案,切换到hdfs用户然后修改/user目录的权限。
如果是root用户,使用命令
su hdfs
hdfs dfs -chmod -R 777 /user
如果是普通用户,则需要sudo权限,使用命令
sudo su hdfs
hdfs dfs -chmod -R 777 /user
如图

创建表同时从其他表导入数据
我们之前导入数据都需要先新建表格再导入,还有一种方式可以快速复制表的结构进行导入。使用命令:
CREATE TABLE t_hive4 AS SELECT * FROM t_hive3;
输出结果如下:
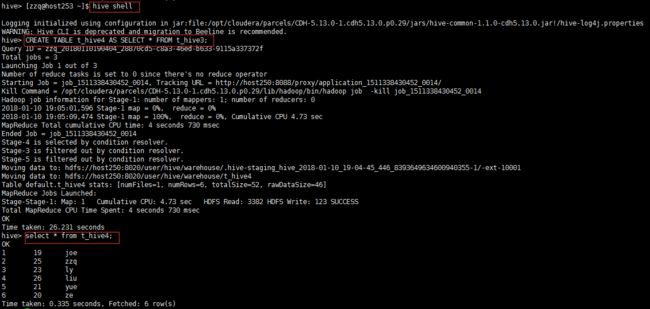
hive> [zzq@host253 ~]$ hive shell
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hive-common-1.1.0-cdh5.13.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> CREATE TABLE t_hive4 AS SELECT * FROM t_hive3;
Query ID = zzq_20180110190404_28870cd5-c8a3-46ed-b633-9115a337372f
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1511338430452_0014, Tracking URL = http://host250:8088/proxy/application_1511338430452_0014/
Kill Command = /opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/bin/hadoop job -kill job_1511338430452_0014
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-01-10 19:05:01,596 Stage-1 map = 0%, reduce = 0%
2018-01-10 19:05:09,474 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.73 sec
MapReduce Total cumulative CPU time: 4 seconds 730 msec
Ended Job = job_1511338430452_0014
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://host250:8020/user/hive/warehouse/.hive-staging_hive_2018-01-10_19-04-45_446_8393649634600940355-1/-ext-10001
Moving data to: hdfs://host250:8020/user/hive/warehouse/t_hive4
Table default.t_hive4 stats: [numFiles=1, numRows=6, totalSize=52, rawDataSize=46]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 4.73 sec HDFS Read: 3382 HDFS Write: 123 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 730 msec
OK
Time taken: 26.231 seconds
hive> select * from t_hive4;
OK
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
Time taken: 0.335 seconds, Fetched: 6 row(s)
仅复制表结构不导数据
使用命令
CREATE TABLE t_hive5 LIKE t_hive4;
从MySQL数据库导入数据
可以考虑使用Sqoop或者kettle等工具进行抽取。
数据导出
在进行导出时我们首先需要了解hive的数据存放方式,hive对数据的存放其实就是以文件的形式存放的,所以导出数据也就对数据目录进行导出备份等操作。
使用命令查看表格的数据目录:
hadoop fs -ls /user/hive/warehouse/
结果如下:
[zzq@host253 ~]$ hadoop fs -ls /user/hive/warehouse/
Found 6 items
drwxrwxrwt - zzq hive 0 2018-01-10 16:39 /user/hive/warehouse/t_hive2
drwxrwxrwt - zzq hive 0 2018-01-10 17:34 /user/hive/warehouse/t_hive3
drwxrwxrwt - zzq hive 0 2018-01-10 19:05 /user/hive/warehouse/t_hive4
[zzq@host253 ~]$ hadoop fs -ls /user/hive/warehouse/t_hive2
Found 1 items
-rwxrwxrwt 3 zzq hive 52 2018-01-10 15:01 /user/hive/warehouse/t_hive2/table_hive.txt
从HDFS复制到HDFS其他位置
比如我们把表格t_hive2复制到hdfs的根目录下
注意需要hdfs的用户权限
使用命令
sudo su hdfs
hadoop fs -cp /user/hive/warehouse/t_hive2 /
查看复制是否成功使用命令
hadoop fs -ls /t_hive2
结果如下:

[zzq@host253 ~]$ sudo su hdfs
[sudo] password for zzq:
[hdfs@host253 zzq]$ hadoop fs -cp /user/hive/warehouse/t_hive2 /
[hdfs@host253 zzq]$ hadoop fs -ls /t_hive2
Found 1 items
-rw-r--r-- 3 hdfs supergroup 52 2018-01-10 19:22 /t_hive2/table_hive.txt
[hdfs@host253 zzq]$
通过Hive导出到本地文件系统
使用命令
INSERT OVERWRITE LOCAL DIRECTORY '/home/zzq/hive' SELECT * FROM t_hive2;
结果如下:
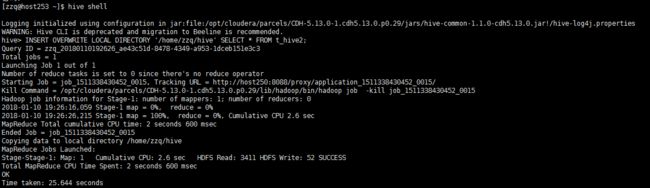
使用!可以在hive shell中查看本地操作系统目录文件,使用命令如下
! ls /home/zzq/hive;
! cat /home/zzq/hive/000000_0;
结果如下:
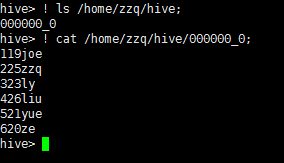
hive> ! ls /home/zzq/hive;
000000_0
hive> ! cat /home/zzq/hive/000000_0;
119joe
225zzq
323ly
426liu
521yue
620ze
Hive查询HiveQL
普通查询:列别名,嵌套子查询
查询出年龄大于20的两条记录
使用命令
FROM (
SELECT b,c as c2 FROM t_hive2
) t
SELECT t.b, t.c2
WHERE b>20
LIMIT 2;
结果如下:
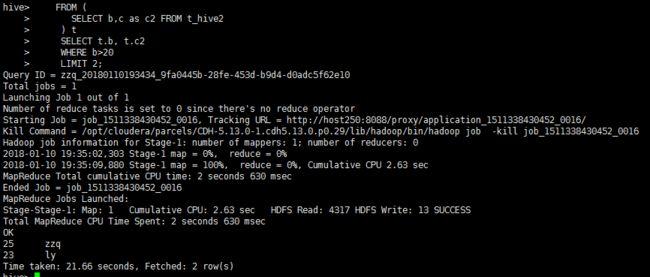
连接查询JOIN
对t_hive2和t_hive3进行连接,id相等时进行关联。筛选条件为年龄大于20岁。
使用命令
SELECT t2.a,t2.b,t3.a,t3.b
FROM t_hive2 t2 JOIN t_hive3 t3 on t2.a=t3.a
WHERE t2.b>20;
结果如下:
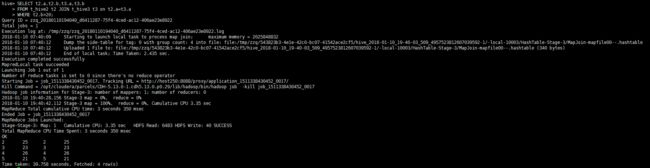
聚合查询1:count, avg
查询数据条数以及平均年龄
使用命令
SELECT count(*), avg(b) FROM t_hive2;
结果如下:
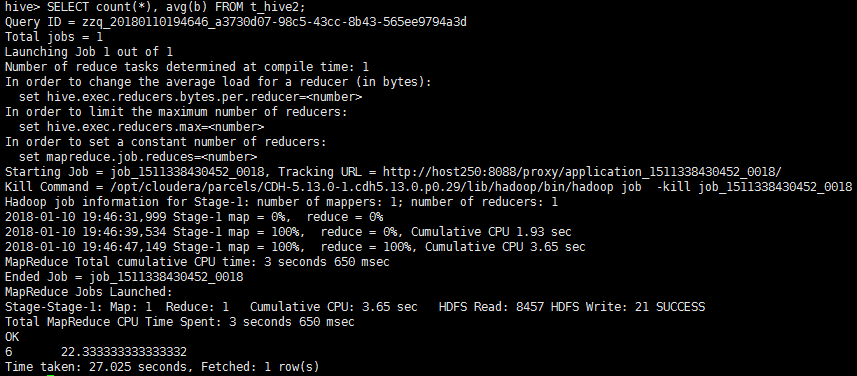
聚合查询2:count, distinct
年龄去重后的种类数量
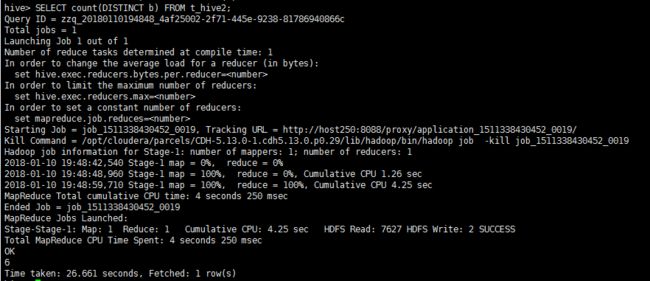
SELECT count(DISTINCT b) FROM t_hive2;
结果如下:
聚合查询3:GROUP BY, HAVING
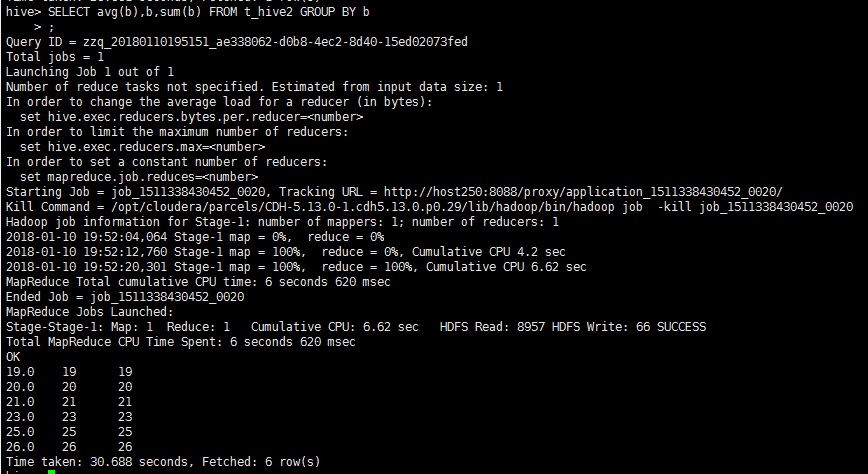
根据年龄进行分组后求每组的平均年龄和年龄总和
SELECT avg(b),b,sum(b) FROM t_hive2 GROUP BY b;
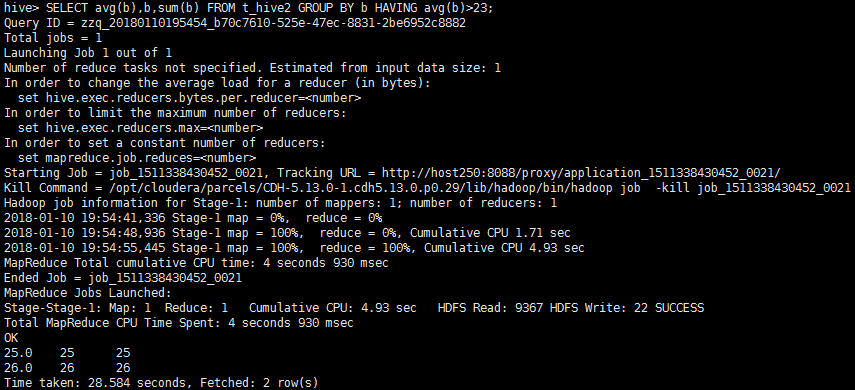
根据年龄进行分组后求每组的平均年龄和年龄总和,筛选条件每组的平均年龄大于23
SELECT avg(b),b,sum(b) FROM t_hive2 GROUP BY b HAVING avg(b)>23;
Hive视图
创建视图
Hive 0.6版本及以上支持视图(View,详见Hive的RELEASE_NOTES.txt),Hive View具有以下特点:
1)View是逻辑视图,暂不支持物化视图(后续将在1.0.3版本以后支持);
2)View是只读的,不支持LOAD/INSERT/ALTER。需要改变View定义,可以是用Alter View;
3)View内可能包含ORDER BY/LIMIT语句,假如一个针对View的查询也包含这些语句, 则View中的语句优先级高;
4)支持迭代View。
本质上来说View只是为了使用上的方便,从执行效率上来说没有区别,甚至可能因为要多一次对MetaStore元数据的操作效率略有下降(这里只是一种理论上的推测,实际可能看不出太大区别)。
为什么需要使用视图
进行数据仓库分析时,使用hive作为cube的输入,但是有些情况下,hive中的表定义和数据并不能满足分析的需求,例如有些列的值需要进行处理,有些列的类型不满足需求,甚至有时候在创建hive表时为了图方便,hive中的所有列都被定义成了string,因此很多情况下在使用Kylin之前需要对hive上的数据格式进行适当的修剪,但是使用alter table的方式修改hive原始的schema信息未免会对其它依赖hive的组件有所影响(例如可能导致数据导入失败),于是不得不另辟蹊径,而此时使用hive的视图就是一个非常好的方案。
使用命令
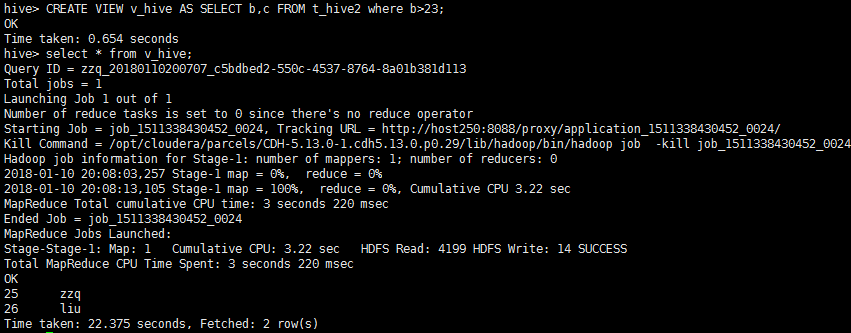
CREATE VIEW v_hive AS SELECT b,c FROM t_hive2 where b>23;
select * from v_hive;
结果如下:
删除视图
如果视图已经存在,那么再新建时会报错,所以有时候需要删除视图。
使用命令
DROP VIEW IF EXISTS v_hive;
结果如下:

分区表
分区表是数据库的基本概念,但很多时候数据量不大,我们完全用不到分区表。Hive是一种OLAP数据仓库,涉及的数据量是非常大的,所以分区表在这个场景就显得非常重要。
准备数据
使用命令
cd /home/zzq
vim table_class1.txt
单击键盘i插入内容如下(注意间隔使用Tab键):
1 19 joe
2 25 zzq
3 23 ly
4 26 liu
5 21 yue
6 20 ze
单击键盘Esc,输入:wq回车保存退出。
cd /home/zzq
vim table_class2.txt
单击键盘i插入内容如下(注意间隔使用Tab键):
1 20 jie
2 26 zzy
3 27 liuxin
4 22 wang
5 23 kk
6 22 qq
单击键盘Esc,输入:wq回车保存退出。
创建分区数据表
hive shell;
CREATE TABLE t_student (id int, age int, name string) PARTITIONED BY (class INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
可以看到与普通数据表的创建区别就是多了分区的依据PARTITIONED BY (class INT)。我们这里按照班级来分区,一般股票数据可以按天等来分区。
如图:

导入数据
LOAD DATA LOCAL INPATH '/home/zzq/table_class1.txt' OVERWRITE INTO TABLE t_student PARTITION (class=1);
LOAD DATA LOCAL INPATH '/home/zzq/table_class2.txt' OVERWRITE INTO TABLE t_student PARTITION (class=2);

查看分区表
SHOW PARTITIONS t_student;

查询数据
select * from t_student where id=1;
select * from t_student where id=1 and class=1;

Hive交互式模式
quit,exit: 退出交互式shell
reset: 重置配置为默认值
set : 修改特定变量的值(如果变量名拼写错误,不会报错)
set : 输出用户覆盖的hive配置变量
set -v : 输出所有Hadoop和Hive的配置变量
add FILE[S] *, add JAR[S] *, add ARCHIVE[S] * : 添加 一个或多个 file, jar, archives到分布式缓存
list FILE[S], list JAR[S], list ARCHIVE[S] : 输出已经添加到分布式缓存的资源。
list FILE[S] *, list JAR[S] *,list ARCHIVE[S] * : 检查给定的资源是否添加到分布式缓存
delete FILE[S] *,delete JAR[S] *,delete ARCHIVE[S] * : 从分布式缓存删除指定的资源
! : 从Hive shell执行一个shell命令
dfs : 从Hive shell执行一个dfs命令
string> : 执行一个Hive 查询,然后输出结果到标准输出
source FILE : 在CLI里执行一个hive脚本文件