58同城数据库架构设计思路(下)
《58同城数据库架构设计思路》(下)
WOT(World Of Tech)2015,互联网运维与开发者大会将在北京举行,会上58同城分享了《大数据量下,58同城mysql实战(上)》的主题(回复“同城”查看)。
DTCC(Database Tech Conference China)2015,中国数据库技术大会举办在即,会上58同城将分享《数据库架构师做什么?58同城数据库架构设计思路(下)》,大会内容抢先看,一起来看看58同城怎么玩数据库架构设计的。
58同城数据库架构设计思路
(1)可用性设计
解决思路:复制+冗余
副作用:复制+冗余一定会引发一致性问题
保证“读”高可用的方法:复制从库,冗余数据,如下图
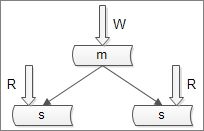
带来的问题:主从不一致
解决方案:见下文
保证“写”高可用的一般方法:双主模式,即复制主库(很多公司用单master,此时无法保证写的可用性),冗余数据,如下图

带来的问题:双主同步key冲突,引不一致
解决方案:
a)方案一:由数据库或者业务层保证key在两个主上不冲突
b)方案二:见下文
58同城保证“写”高可用的方法:“双主”当“主从”用,不做读写分离,在“主”挂掉的情况下,“从”(其实是另外一个主),顶上,如下图

优点:读写都到主,解决了一致性问题;“双主”当“主从”用,解决了可用性问题
带来的问题:读性能如何扩充?解决方案见下文
(2)读性能设计:如何扩展读性能
最常用的方法是,建立索引
建立非常多的索引,副作用是:
a)降低了写性能
b)索引占内存多了,放在内存中的数据就少了,数据命中率就低了,IO次数就多了
但是否想到,不同的库可以建立不同的索引呢?如下图
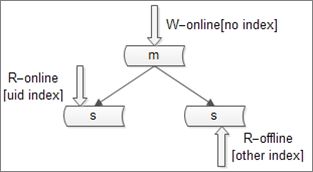
TIPS:不同的库可以建立不同索引
主库只提供写,不建立索引
online从库只提供online读,建立online读索引
offline从库只提供offline读,建立offline读索引
提高读性能常见方案二,增加从库
上文已经提到,这种方法会引发主从不一致问题,从库越多,主从时延越长,不一致问题越严重
这种方案很常见,但58没有采用
提高读性能方案三,增加缓存
传统缓存的用法是:
a)发生写请求时,先淘汰缓存,再写数据库
b)发生读请求时,先读缓存,hit则返回,miss则读数据库并将数据入缓存(此时可能旧数据入缓存),如下图

带来的问题:
a)如上文所述,数据复制会引发一致性问题,由于主从延时的存在,可能引发缓存与数据库数据不一致
b)所有app业务层都要关注缓存,无法屏蔽“主+从+缓存”的复杂性
58同城缓存使用方案:服务+数据+缓存
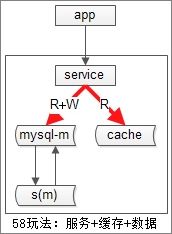
好处是:
1)引入服务层屏蔽“数据库+缓存”
2)不做读写分离,读写都到主的模式,不会引发不一致
(3)一致性设计
主从不一致解决方案
方案一:引入中间件
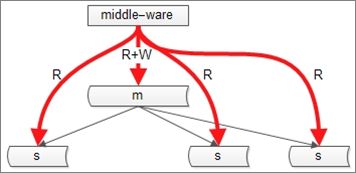
中间件将key上的写路由到主,在一定时间范围内(主从同步完成的经验时间),该key上的读也路由到主
方案二:读写都到主
上文已经提到,58同城采用了这种方法,不做读写分离,不会不一致
数据库与缓存不一致解决方案
两次淘汰法
异常的读写时序,或导致旧数据入缓存,一次淘汰不够,要进行二次淘汰
a)发生写请求时,先淘汰缓存,再写数据库,额外增加一个timer,一定时间(主从同步完成的经验时间)后再次淘汰
b)发生读请求时,先读缓存,hit则返回,miss则读数据库并将数据入缓存(此时可能旧数据入缓存,但会被二次淘汰淘汰掉,最终不会引发不一致)
(4)扩展性设计
(4.1)58同城秒级别数据扩容
需求:原来水平切分为N个库,现在要扩充为2N个库,希望不影响服务,在秒级别完成
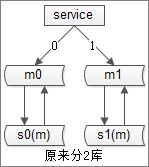
最开始,分为2库,0库和1库,均采用“双主当主从用”的模式保证可用性
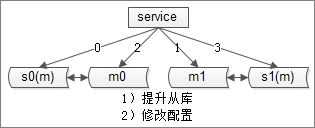
接下来,将从库提升,并修改服务端配置,秒级完成扩库
由于是2扩4,不会存在数据迁移,原来的0库变为0库+2库,原来的1库变为1库和3库
此时损失的是数据的可用性
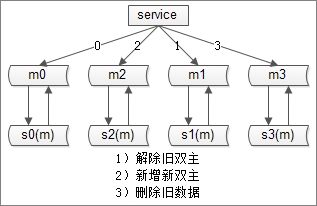
最后,解除旧的双主同步(0库和2库不会数据冲突),为了保证可用性增加新的双主同步,并删除掉多余的数据
这种方案可以秒级完成N库到2N库的扩容。
存在的问题:只能完成N库扩2N库的扩容(不需要数据迁移),非通用扩容方案(例如3库扩4库就无法完成)
(4.2)非指数扩容,数据库增加字段,数据迁移
[这些方法在(上)篇中都已经介绍过,此处不再冗余,有兴趣的朋友回复“同城”回看(上)篇]
方案一:追日志方案
方案二:双写方案
(4.3)水平切分怎么切
四类场景覆盖99%拆库业务
a)“单key”场景,用户库如何拆分: user(uid, XXOO)
b)“1对多”场景,帖子库如何拆分: tiezi(tid, uid, XXOO)
c)“多对多”场景,好友库如何拆分: friend(uid, friend_uid, XXOO)
d)“多key”场景,订单库如何拆分:order(oid, buyer_id, seller_id, XXOO)
[这些拆库方案在(上)篇中都已经介绍过,此处不再冗余,有兴趣的朋友回复“同城”回看(上)篇]
(5)海量数据下,SQL怎么玩
不会这么玩
a)各种联合查询
b)子查询
c)触发器
d)用户自定义函数
e)“事务”都用的很少
原因:对数据库性能影响极大
拆库后,IN查询怎么玩[回复“同城”回看(上)篇]
拆库后,非Partition key的查询怎么玩[回复“同城”回看(上)篇]
拆库后,夸库分页怎么玩?[回复“同城”回看(上)篇]
问题的提出与抽象:ORDER BY xxx OFFSET xxx LIMIT xxx
单机方案:ORDER BY time OFFSET 10000 LIMIT 100
分库后的难题:如何确认全局偏移量
分库后传统解决方案:查询改写+内存排序
a)ORDER BY time OFFSET 0 LIMIT 10000+100
b)对20200条记录进行排序
c)返回第10000至10100条记录
优化方案一:增加辅助id,以减少查询量
优化方案二:模糊查询
a)业务上:禁止查询XX页之后的数据
b)业务上:允许模糊返回 => 第100页数据的精确性真这么重要么?
最后的大招!!!(由于时间问题,只在DTCC2015上分享了哟)
优化方案三:终极方案,业务无损,查询改写与两段查询
需求:ORDER BY x OFFSET 10000 LIMIT 4; 如何在分库下实现(假设分3库)
步骤一、查询改写: ORDER BY x OFFSET 3333 LIMIT 4
[4,7,9,10] <= 1库返回
[3,5,6,7] <= 2库返回
[6,8,9,11] <= 3库返回
步骤二、找到步骤一返回的min和max,即3和11
步骤三、通过min和max二次查询:ORDER BY x WHERE x BETWEEN 3 AND 11
[3,4,7,9,10] <= 1库返回,4在1库offset是3333,于是3在1库的offset是3332
[3,5,6,7,11] <= 2库返回,3在2库offset是3333
[3,5,6,8,9,11] <= 3库返回,6在3库offset是3333,于是3在3库的offset是3331
步骤四、找出全局OFFSET
3是全局offset3332+3333+3331=9996
当当当当,跳过3,3,3,4,于是全局OFFSET 10000 LIMIT 4是[5,5,6,6]
总结:58同城数据库架构设计思路
(1)可用性,解决思路是冗余(复制)
(1.1)读可用性:多个从库
(1.2)写可用性:双主模式 or 双主当主从用(58的玩法)
(2)读性能,三种方式扩充读性能
(2.1)增加索引:主从上的索引可以不一样
(2.2)增加从库
(2.3)增加缓存:服务+缓存+数据一套(58的玩法)
(3)一致性
(3.1)主从不一致:引入中间层 or 读写都走主库(58的玩法)
(3.2)缓存不一致:双淘汰来解决缓存不一致问题
(4)扩展性
(4.1)数据扩容:提升从库,double主库,秒级扩容
(4.2)字段扩展:追日志法 or 双写法
(4.3)水平切分
(单key)用户库如何拆分:, user(uid XXOO)
(1对多)帖子库如何拆分: tiezi(tid, uid, XXOO)
(多对多)好友库如何拆分: friend(uid, friend_uid, XXOO)
(多key)订单库如何拆分:order(oid, buyer_id, seller_id, XXOO)
(5)SQL玩法
(5.0)不这么玩:联合查询,子查询,触发器,自定义函数,事务
(5.1)IN查询:分发MR or 拼装成不同SQL语句
(5.2)非partition key查询:定位一个库 or 分发MR
(5.3)夸库分页
(5.3.1)修改sql语句,服务内排序
(5.3.2)引入特殊id,减少返回数量
(5.3.3)业务优化,允许模糊查询
(5.3.4)查询改写,二段查询
至此,58同城数据实战(上) + 58同城数据库设计(下)的内容全部完成。
【完】
回复【mongo】,阅读《一分钟了解mongoDB》
回复【leveldb】,阅读《Google-levelDB简介》
回复【join】,阅读《两幅图秒懂sql中的join》
回复【mysql】,阅读《mysql数据库中间件》
回复【赶集】,阅读《赶集mysql军规》
回复【同城】,阅读《58同城mysql实战(上)》
回复【数据库】,阅读《58同城数据库架构设计思路(下)》
小游戏:
回大于10的整数,返回随机好文(试试看哟,猜猜怎么实现的?)
如果觉得有收获,各位兄弟帮忙转发一下哈。