牛客网面试试题华为
试题1:

s = input()
print(len(s.split()[-1]))
解析:这道题不难,主要的考点是split函数的用法,split函数主要用于字符串的切分,
split(" 切分字符",num),其中前一个参数为切分字符,后一个参数为切分次数。
如:
u ="www.doiido.com.cn"
print(u.split('.',1))
输出结果:['www', 'doiido.com.cn']
题目2:
解法1:
target_str=input()
str2=input()
j=0
for i in target_str:
if i.upper()== str2 or i.lower()==str2:
j=j+1
print(j)
解法2:
a=input().lower()
b=input().lower()
print(a.count(b))
解析:这道题的难度在于首先我们的字符串中含有数字、字符以及数字,而后面的匹配字符也应该包括这三个部分,所以我们只需要用后面的匹配字符去进行匹配就行了,但是其中有要求不区分大小写,所以我们在进行匹配时要采用upper、lower函数去转换匹配字符,这样的话,来跳过不区分大小写的要求。
题目3:

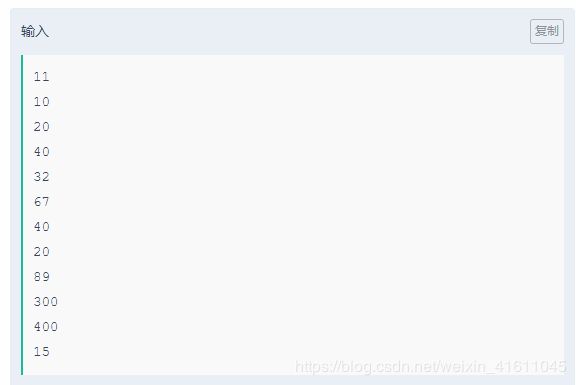
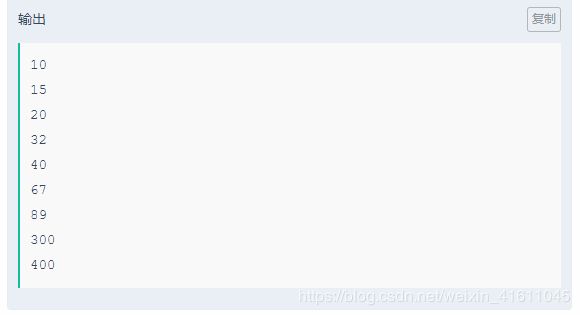
while True:
try:
#如果程序运行成功,即一开始输入的数字数量个数和后面的数字输入个数相同,则执行程序
n=int(input())
inputArray=[]
for i in range(n):
a=input()
inputArray.append(int(a))
uni_inputArray=sorted(set(inputArray))
for j in uni_inputArray:
print(j)
except:
#如果输入的数字数量,和后面的数字数量不匹配的话,则退出这个程序
break
解析:这个题的难点在于try和except,因为我们要考虑输入的数字数量和输入的数字个数不符的情况,我们就得将程序退出。
题目4:


错误解法:
自己编写的程序,可以看出程序中调用了很多的虚拟变量,其最后的结果为调用了太多的内存而不能通过测试。
str1=input()
str2=input()
n1=len(str1)
n2=len(str2)
list1=[str1,str2]
list2=[]
for i in list1:
while True:
a=i[:8]
b=i[8:]
if len(b) <= 8:#切分后的字符串不用再切分
if len(b)==0: #a的长度小于8
for i in range(8-len(a)):
a=a+str(0)
list2.append(a)
break
else:#a的长度为8个字符,b的长度小于8
list2.append(a)
for i in range(8-len(b)):
b=b+str(0)
list2.append(b)
break
else:
list2.append(a)
for i in list2:
print(i)
解法2:由于程序中并不需要将切分后的字符串保存,只用打印出来所以,我们不用刻意用list去保存数据,可以直接将字符串截取并打印替换,具体程序如下所示:
str1=input()
str2=input()
def cal_8(string):
n=len(string)
if n<=8:
print(string+"0"*(8-n))
else:
while len(string)>8:
#将字符串打印
print(string[:8])
#将打印后的字符串剔除
string=string[8:]
print(string+"0"*(8-len(string)))
cal_8(str1)
cal_8(str2)
试题6:
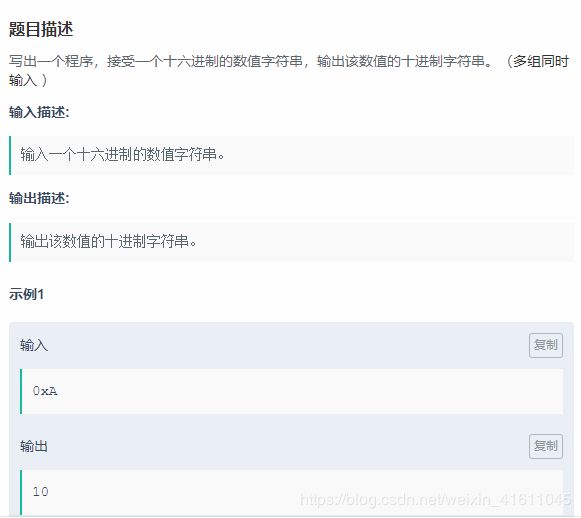
解法1:
python中int函数包含数位进制的转化
while True:
try:
string = input()
print(int(string, 16))
except:
break
解法2:
通过字典转换
while True:
try:
str1=input()
str1=list(str1)
str1.remove("x")
dict_list={"0":0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9,"A":10,"B":11,"C":12,"D":13,"E":14,"F":15}
result=0
n=len(str1)
for i in str1:
result=result+dict_list[i]*16**(n-1)
n=n-1
print(result)
except:
break
试题7:
求质数
根据质数的定义,在判断一个数n是否是质数时,只要用1至n-1去除n,看看能否整除即可。
还有更好的办法:先找一个数m,使m的平方大于n,再用小于等于m的质数去除n(n为被除数),如果都不能整除,则n必然是质数。如我们要判断1993是不是质数,50*50>1993,那么只要用1993除以<50的质数看是否能整除,若不能即为质数。100以内的质数有25个,还是比较好记的,只要记熟100以内质数,就可以快速判断10000以内的数是不是质数。
代码:
import math
def checknum(n):
#检查是否为质数
result=math.ceil(n**0.5)
#找出2到result+1的数
for i in range(2,result+1):
if n%i==0:
#如果n是2直接是质数
if n==2:
return True
#如果n在2到n中能找到整除数,则标记n为非质数
else:
return False
break
if i==result #如果寻找到result还没有发现整除的数,则标记n为质数:
return True
while True:
try:
int1=int(input())
#进行向上取整
result1=math.ceil(int1*0.5)
S=True
while S:
#判断输入的数自身是不是质数,如果是直接输出
if checknum(int1)==True:
S=False
print(int1,end=" ")
else:
#如果自身不是质数
for i in range(2,result1+1):
#在2到result中的数进行整除搜寻,并不断保留被除之后的数,注:这里进行输出的除数一定是从小到大的
if int1%i==0 and checknum(i):
int1=int(int1/i)
print(i,end=" ")
#每次搜索到除数后直接跳出,开始第二次的保留除数的搜寻
break
except:
break
试题7:
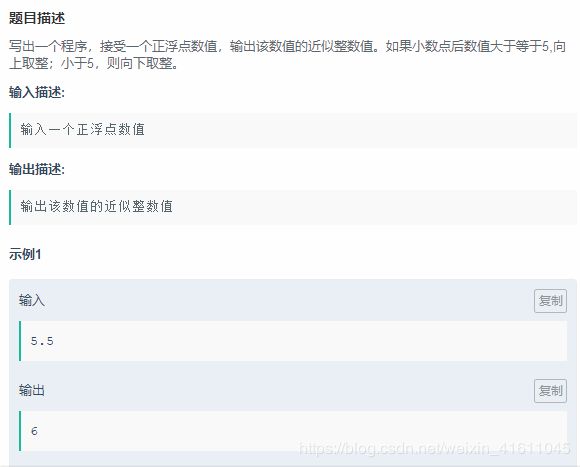
解法1:
while True:
try:
str1=input()
for i in range(len(str1)):
if str1[i] == ".":
point_back=str1[i+1:]
print(point_back)
if int(point_back) >= 5:
print(int(str1) + 1)
print(1)
else:
print(int(str1))
print(2)
if i==len(str1)-1:
print(int(str1))
except:
break
解法2:
import math
while True:
try:
str1=input()
for i in range(len(str1)):
if str1[i] == ".":
point_back=str1[i+1:]
if int(point_back) >= 5:
print(math.floor(float((str1))) + 1)
else:
print(math.floor(float(str1)))
if i==len(str1)-1:
print(int(str1))
except:
break
解法2,对字符串进行了遍历,先找其中是否包含小数点,如果包含则对小数点后面的字符串进行4舍5入,但是注意,这里有个很重要的函数int(),我们知道int()是将字符串整数变为整型,而不是将浮点数的整型变为整型,所以此题要防止使用int,而使用float()
试题8:
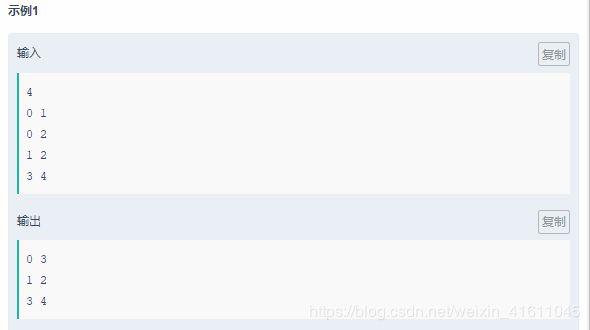
合并索引表
题目描述
数据表记录包含表索引和数值,请对表索引相同的记录进行合并,即将相同索引的数值进行求和运算,输出按照key值升序进行输出。
输入描述:
先输入键值对的个数
然后输入成对的index和value值,以空格隔开
输出描述:
输出合并后的键值对(多行)
错解1:
while True:
try:
num=input()
d={}
for i in range(int(num)):
[key,val]=input().split()
if key in d:
d[key]=d[key]+int(val)
else:
d[key]=int(val)
print(d)
dex=sorted(d)
for i in dex:
print(str(i)+" "+str(d[i]))
except:
break
解析:这个程序的错误过程在于,sorted(d),因为d是一个字典,其中的键值是字符串,sorted对字符串进行排序时需要的时间较久,所以要用数字的方式。即将字典的键位改为数字即可
正解1:
while True:
try:
num=input()
d={}
b=[]
for i in range(int(num)):
[key,val]=input().split()
if key in d:
d[key]=d[key]+int(val)
else:
d[key]=int(val)
for i in d:
b.append(int(i))
for i in sorted(b):
print(str(i)+" "+str(d[str(i)]))
except:
break
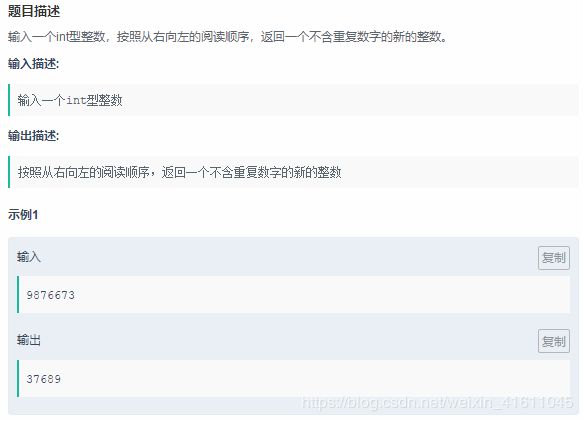
试题9:
str1=input()
d={}
str1=str1[::-1]
#key值对应数字,value对应索引位置
for i in range(len(str1)):
if str1[i] not in d:
d[str1[i]]=i
d_new=dict(zip(d.values(),d.keys()))
lis=[d_new[i] for i in sorted(d_new)]
str2=("").join(lis)
print(int(str2))
这道题的思路是还是先将字符串进行颠倒,然后进行字典的索引查找,key值对应数字,而value值对应改数字第一次出现的位置,字符串遍历结束,然后通过key值和value值互换的方法,互换key和value,并按照value排序,再将数字拼接
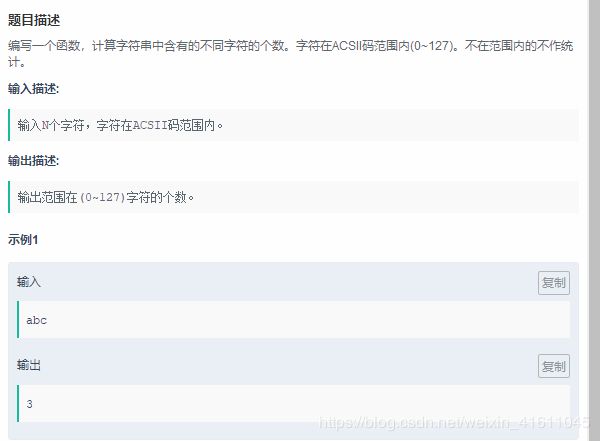
试题10:
代码:
str1=input()
lis=[i for i in str1]
j=0
for i in set(lis):
if ord(i)>=0 and ord(i)<=127:
j=j+1
print(j)
解析:先将字符串去重再用ord()函数进行转移并统计字符个数
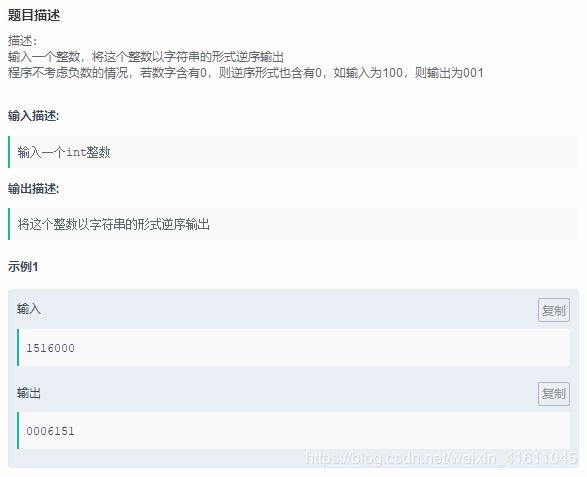
试题11:
代码:
解法1:
一个最无赖的方法:
str1=input()
str1=str1[::-1]
print(str1)
解析:直接用到其中的[::-1]颠倒字符串
解法2:
str1=input()
str1_reverse=[str1[-i-1] for i in range(len(str1))]
print(("").join(str1_reverse))
解析:进行字符串倒置的颠倒,直接利用索引,一般来说0代表字符串的第一个字符,而-1代表字符串的最后一个字符。
试题12:
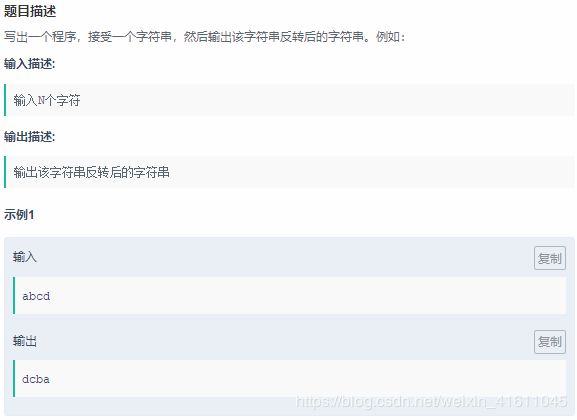
这个题目和试题11类似:
代码:
str1=input()
str1_reverse=[str1[-i-1] for i in range(len(str1))]
print(("").join(str1_reverse))
试题13:
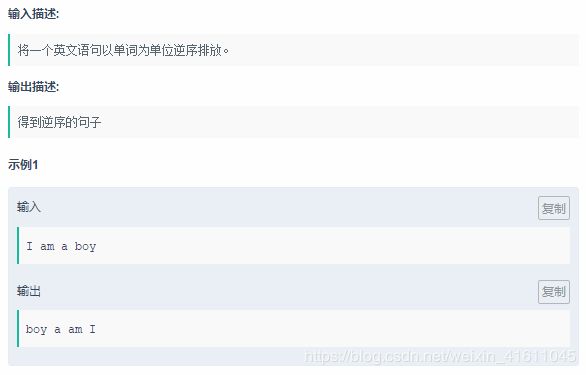
代码:
str1=input()
lis=str1.split()
lis2=[lis[-i-1] for i in range(len(lis))]
print((" ").join(lis2))
解析:题目的处理方法和11、12类似。
试题14:

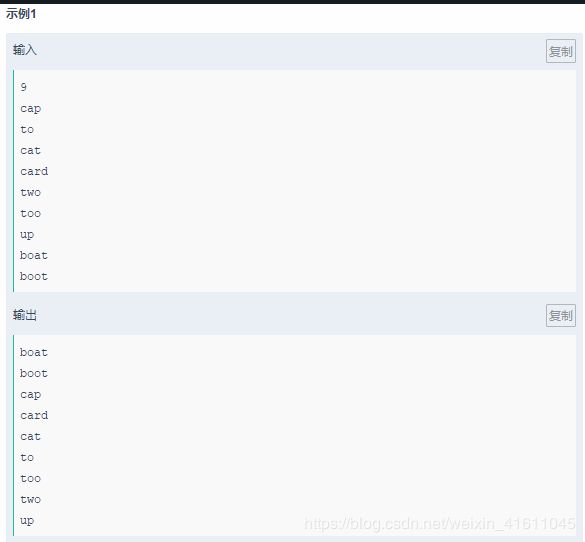
代码 :
对于字符串的比较,python会自动将其转化为ASCII码值再进行比较,所以python会自动比较字符串的大小
如:
![]()
法1:利用sort或者sorted函数
法1我就不细讲
法2:通过自己设置字符串比较函数喝
"""定义字符串比较函数,其基本方式为按字典排序,但是如果同序列比较,
但是后一个字符串比前#一个字符串多,则后大于前,如:
compare("abc","abc") 返回True,compare("abc","abcd") 返回True"""
def compare_string (str1,str2):
len1=len(str1)
len2=len(str2)
for i in range(min(len1,len2)):
if str1[i]试题15:
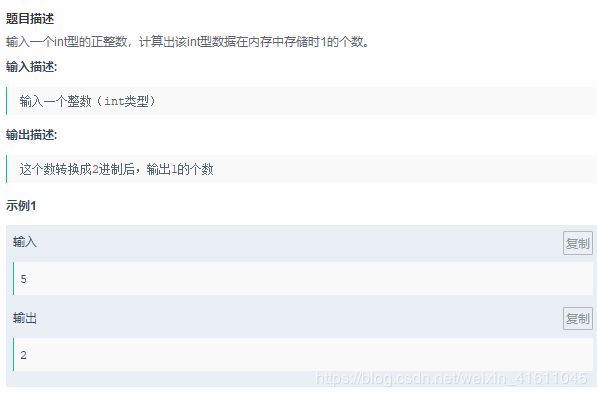
代码:
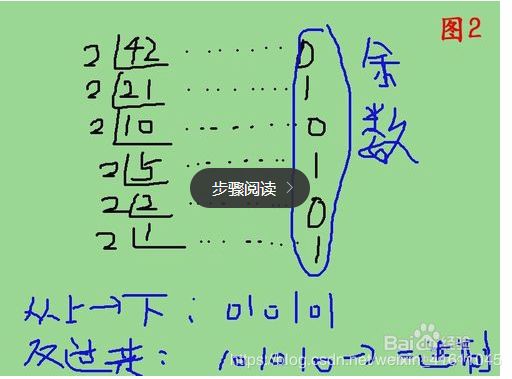
import math
#定义二进制转10进制函数
def ten_to_two(num):
d=[]
while True:
left=num%2
num=math.floor(num/2)
d.append(left)
if num==1:
break
d.append(1)
return d[::-1]
num=int(input())
#利用sum求1的个数
print(sum(ten_to_two(num)))
解析:要先搞懂10进制转二进制的方法
试题16:
题目描述
王强今天很开心,公司发给N元的年终奖。王强决定把年终奖用于购物,他把想买的物品分为两类:主件与附件,附件是从属于某个主件的,下表就是一些主件与附件的例子:
主件 附件
电脑 打印机,扫描仪
书柜 图书
书桌 台灯,文具
工作椅 无
如果要买归类为附件的物品,必须先买该附件所属的主件。每个主件可以有 0 个、 1 个或 2 个附件。附件不再有从属于自己的附件。王强想买的东西很多,为了不超出预算,他把每件物品规定了一个重要度,分为 5 等:用整数 1 ~ 5 表示,第 5 等最重要。他还从因特网上查到了每件物品的价格(都是 10 元的整数倍)。他希望在不超过 N 元(可以等于 N 元)的前提下,使每件物品的价格与重要度的乘积的总和最大。
设第 j 件物品的价格为 v[j] ,重要度为 w[j] ,共选中了 k 件物品,编号依次为 j 1 , j 2 ,……, j k ,则所求的总和为:
v[j 1 ]*w[j 1 ]+v[j 2 ]*w[j 2 ]+ … +v[j k ]*w[j k ] 。(其中 * 为乘号)
请你帮助王强设计一个满足要求的购物单。
输入描述:
输入的第 1 行,为两个正整数,用一个空格隔开:N m
(其中 N ( <32000 )表示总钱数, m ( <60 )为希望购买物品的个数。)
从第 2 行到第 m+1 行,第 j 行给出了编号为 j-1 的物品的基本数据,每行有 3 个非负整数 v p q
(其中 v 表示该物品的价格( v<10000 ), p 表示该物品的重要度( 1 ~ 5 ), q 表示该物品是主件还是附件。如果 q=0 ,表示该物品为主件,如果 q>0 ,表示该物品为附件, q 是所属主件的编号)
输出描述:
输出文件只有一个正整数,为不超过总钱数的物品的价格与重要度乘积的总和的最大值( <200000 )。
代码:
goods= [[800, 2, 0], [400, 3, 0] , [500, 2, 0],[400, 5, 1], [300, 5, 1],[2000,5,1]] #物品单
N=1000 #钱数
m=6 #物品数
#形成一个m+1行,N+1列的矩阵,因为我们形成的最佳矩阵中,前0行,0列都是0
def func_max(N,m,goods):
a=[[0]*(N+1) for i in range(m+1)]
for i in range(1,m+1):
for j in range(10,N+1,10):
#如果是主件
if goods[i-1][2]==0:
if goods[i-1][0]<=j: #如果背包容量大于要买的主件商品
a[i][j]=max(a[i-1][j],a[i-1][j-goods[i-1][0]]+goods[i-1][0]*goods[i-1][1])
else: #如果要买的东西是附件
if goods[i-1][0]+goods[goods[i-1][2]-1][0]>j: #如果背包容量小于我们要买的主键和附件
#此时当前价格就等于排除此件商品,当前钱数可以买到的最大值
a[i][j]=a[i-1][j]
else:
a[i][j]=max(a[i-1][j],a[i-1][j-goods[i-1][0]-goods[goods[i-1][2]-1][0]]+
goods[i-1][0]*goods[i-1][1]+goods[goods[i-1][2]-1][0]*goods[goods[i-1][2]-1][1])
print(a[m][int(N/10)*10])
func_max(N,6,goods)
解析:这是一道变化后的动态规划问题,其根本还是背包问题的变种,详情可以看我的博客中动态规划的总结。注意解这道题的需要有个小技巧,由于我们买附件的时候必须买主件,如果主件已经选购了则比较好解决 ,如果没有的话,此时得把主键一并考虑了,且还要考虑主件其他附件购买时得情况,为了解决方便,我们必须将主件放在列表中的前面。
试题17:

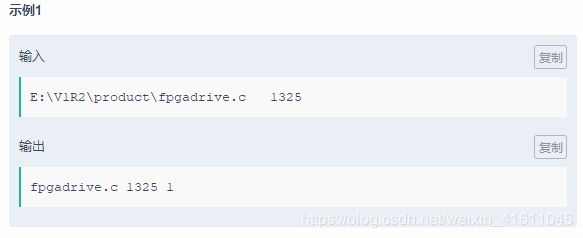
代码:
自己编写:
while True:
try:
d={}
while True:
list1=input().split()
if list1==[]:
break
count=0
mistake=list1[1]
#print(mistake)
f_n=list1[0].split('\\')
f_n=f_n[-1][-16:]
count=count+1
if f_n in d:
if mistake in d[f_n][0]:
count1=0
for z in d[f_n][0]:
count1=count1+1
if z==mistanke:
d[f_n][1][count1]=d[f_n][1][count1]+1
else:#文件名相同,但错误行数不同
d[f_n][0].append(mistake)
d[f_n][1].append(1)
else:
d[f_n]=[[mistake],[1]]
if count>8:
break
#print(d)
for i in d.keys():
#print(i)
j=d[i]
#print(j)
for z in range(len(j[0])):
#print(z)
print(i,end=" ")
print(j[0][z],end=" ")
print(j[1][z],end=" ")
except:
break
标准答案:
name=[]
dict={}
while True:
try:
string=input().strip().split(" ")
if len(string)==0:
break
file_name=string[0].split("\\")[-1]
if len(file_name)>16:
file_name=file_name[-16:]
line_num=string[-1]
dict_name=file_name+" "+str(line_num)
if dict_name not in dict.keys():
dict[dict_name]=1
name.append(dict_name)
else:
dict[dict_name]+=1
except:
break
for item in name[-8:]:
print(item+" "+str(dict[item]))