《Recent Advances in Deep Learning for Object Detection 》笔记
最近看了一篇目标检测的综述,之前对目标检测的认识不是很多,所以简单地记录一下笔记,由于是很早之前写的,对目标检测的很多概念都还不是很清楚,简单记录一下。这篇论文主要讲了目前的目标检测算法的一些设置、检测范式、基准等,包括了传统算法和深度学习算法,主要侧重深度学习算法部分。
一、传统方法
传统的目标检测算法主要是三个步骤:
1、候选框生成(proposal generation):候选框生成,主要是筛选并提取出可能包含目标的区域,通常为矩形框;
2、特征向量提取(feature vector extraction):对每个ROI提取图像的特征向量;
3、区域分类(region classification):利用ROI的特征向量来分类区域所属的目标类别。
通常,第一步产生的候选框通常会采用滑动窗口来扫描整个图像,这些候选框也就是ROI,同时为了适应目标的多尺度,通常也会将图像和滑动窗口设置为多个尺寸;第二步的特征提取,通常会每个窗口都提取固定长度的特征向量,这些特征通常是采用低级视觉描述子来编码的,例如,SIFT、Haar、HOG、SURF等对图像的尺度、光照、旋转具有鲁棒性的特征算法;第三步则是为了学习区域分类,为每个区域分配一个目标类别,在深度学习前的传统算法时代,用得比较多的是SVM、bagging、级联(cascade)学习和adaboost。
2007-2009年, DPMs (Deformable Part Based Machines)连续赢得目标检测挑战赛Pascal VOC,之后传统方法的改进没有再带来VOC目标检测的太大的提升,也说明了传统的目标检测算法性能基本到了极限或者瓶颈,原因如下:
1、候选框生成阶段,需要提取非常多的ROI,但是,这些ROI中有很多是冗余的,分类过程容易带来较大的误报率FPR,同时,窗口和尺度等都是人为设计的,对目标的匹配表现不良好;
2、特征描述子基本都是人为的基于低级视觉特征设计的,对于更复杂的上下文很难获取到具有代表性的语义信息; 3、整个检测过程中,三个环节都是独立设计和优化,所以通常很难做到系统性的全局优化;
二、深度学习方法
2.1、算法综述
深度学习方法很大程度上是深度神经网络,尤其是深度卷积神经网络(Deep Convolutional Neural Networks, DCNN)的应用,早期神经网络由Fukushima设计提出,后经Yann Lecun等人利用随机梯度下降法(Stochastic Gradient Descent, SGD)和反向传播算法(Back-propagation)进行优化,但是存在几个问题:
1、缺少大规模的标注数据,容易导致过拟合;
2、计算资源限制了应用;
3、与SVM相比,理论研究较弱;
2012年,ILSVRC(ImageNet dataset and showed significant improvement on Large Scale Visual Recognition Challenge)和GPU计算资源的提升使DCNN表现出了优于传统算法的性能。 基于深度学习的目标检测算法的发展历程如图2.1所示,在2019年前后,开始进入无锚点的目标检测(红色)和基于AutoML的目标检测(绿色):

图2.1 基于深度学习的目标检测算法发展历程
目前基于深度学习的目标检测算法大致上可以分为两个大类:二阶检测器(two-stage detectors)和一阶检测器(one-stage detections)。二阶检测器的代表模型是Region-based CNN及其变种,主要步骤为:
1、候选框生成稀疏的区域集合并提取局部区域特征;
2、根据区域特征预测区域的目标分类;
一阶检测器的主要代表是YOLO及其变种,其步骤不包含候选框生成,而是直接对图像每个位置的对象进行分类预测,而不进行级联区域分类操作。总的来说两者各有优势,二阶的表现往往比一阶好,但是一阶明显具有很高的运行效率,更能满足实时性的目标检测应用要求。 目前目标检测算法的算法和应用情况如图2.2和表2.1所示,同时也是本文的主要介绍思路。

图2.2目标检测算法与应用情况

图2.2目标检测算法与应用情况
2.2、检测设置
检测设置主要分两种:基于边界框级别定位的普通目标检测(Vanilla Object Detection, bbox-level localization)和基于像素级别或模板级别定位的实例分割(Instance Segmentation, pixel-level or mask-level localization)。 普通目标检测应用较广,且很多传统算法都是采用普通目标检测方法;实例分割则是比较新的做法,提供更精细的像素级分类预测,对空间错位更敏感,对空间信息的处理要求也更高。
2.3、检测范式
2.3.1、二阶检测
二阶检测器的两个步骤为:候选框生成、候选框预测。第一阶段,先检测可能存在对象的区域,基本思路是以高的召回率生成候选框,使图像红的所有对象属于至少一个候选框区域;第二阶段是对这些候选框区域预测正确的标签。
1、R-CNN
R-CNN是典型的二阶检测代表,在Pascal VOC2010上取得了53.7%的mAP。R-CNN主要分三步:i)、候选框生成;ii)、特征提取;iii)、区域分类。
缺点如下:i)、每个候选框由DCNN提取,重复计算,训练和测试耗时;ii)、R-CNN三个步骤是独立的,无法提供全局优化;iii)、选择性搜索依赖于低级视觉线索,无法适应复杂环境,且无法用GPU加速。
2、SPP-net
SPP-net基于R-CNN的加速改进,利用DCNN计算全图特征,并加入了空间金字塔池化(Spatial Pyramid Pooling,SPP)提取固定长度特征向量。
SPP-net缺点如下:i)、训练SPP-net依然是多阶段训练,无法做到全局优化;ii)、SPP层无法与CNN的BP共用,因此无法从SPP层更新参数到前面的卷积层。
3、Fast R-CNN
Fast R-CNN是类似SPP-net的进一步改进,不用SPP层改用ROI池化来提取区域特征,并连接到一个(C+1类)的全连接层,C类是目标类,1是背景类。
Fast R-CNN可以提供端到端的全局优化,因此训练和应用速度得到提升;但缺点是候选框生成步骤上依然依赖传统算法,也就是无法学习的低级视觉特征。
4、Faster R-CNN
Faster R-CNN是对Fast R-CNN的进一步改进,也就是在候选框生成步骤中加入了可学习的Region Proposal Network(RPN),因此整个框架是可以进行端到端的全局优化。Faster R-CNN之后,很多目标检测算法都是基于此改进。
但是Faster R-CNN的缺点有:i)、候选框生成步骤的计算与区域分类步骤的计算是无法共享的;ii)、很难做多尺度目标检测,也很难检测到小目标。
5、FPN
FPN(Feature Pyramid Networks)将具有丰富语义信息的深层特征与具有空间信息的浅层特征相结合,实现多尺度目标检测,因此在很多领域如视频检测、人体姿态识别等有应用。
6、Mask R-CNN
Mask R-CNN根据候选框(proposals)和最好的结果(reported state-of-the-art results)来同时预测目标边界框(bounding boxes)和分割掩膜(segmentation masks),使整个目标检测过程更灵活。
7、Mask Scoring R-CNN
Mask Scoring R-CNN是基于Mask R-CNN的改进,加入学习预测掩膜的质量,并校准掩膜质量和掩膜识别分数之间的不对准。

图2.3 二阶目标检测算法
2.3.2、一阶检测
不同于二阶检测器,一阶检测器不生成候选框,二十将图像的每个位置都看作潜在对象,然后再将每个感兴趣区域分类为背景或者目标对象。
1、OverFeat
OverFeat将DCNN改为全卷积目标检测器(fully convolutional object detector),将DCNN的最后的全连接层。OverFeat网络对输入的每个区域预测目标的存在,再基于相同的DCNN特征,学习边界框回归来优化预测区域。同时为了解决多尺度目标检测,对输入图像进行多尺度缩放再用模型推导后合并为最终的特征。
OverFeat的缺点是分类器和回归器的训练是分开的,没有进行联合优化,也就是没有做到全局优化。
2、YOLO
YOLO(You Only Look Once),将目标检测视为回归问题,将整个图像空间划分为固定数量的网格单元,对每个单元预测是否有目标,边界框的坐标和大小以及目标的分类。YOLO省略了候选框生成步骤,直接端到端进行优化,速度非常快。
缺点:i)、给定位置仅检测两个目标,对小目标和拥挤物体不适合;ii)、仅使用最后一个特征图,不适合多尺度和多纵横比的目标检测。
3、SSD
SSD(Single-Shot Mulibox Detector),同YOLO一样也划分网格,但每个网格生成一组具有多尺度和宽高比的锚点,每个锚点由回归学习的4值偏移量优化,并由分类器分配(C + 1)分类概率。SSD对多个特征图预测对象,并能检测大尺寸物体。SSD通过端到端训练,使用预测图中的定位损失和分类损失的加权和优化整个网络,将不同特征图的所有检测结果合并作为最终输出。
4、RetinaNet
没有候选框生成步骤,一阶检测器容易出现背景和目标类别不均衡问题,RetinaNet通过focal loss抑制容易负样本的梯度,而不是简单的丢弃;然后使用金字塔网络检测不同尺度的目标。
5、YOLOv2
YOLOv2引入基于ImageNet数据集训练的更好的深度卷积网络做基础,借鉴了SSD的做法,提出更好的锚点先验策略,即对训练数据执行K均值聚类(而不是手动设置),同时也加入BN层(Batch Normalization layers)和多尺度的训练技术。
6、CornerNet
前面提到的都是基于锚点的检测,还有一些基于无锚的检测算法,是预测边界框的关键点来实现。CornerNet就是无锚框架的一种,不使用锚点,而是将目标检测视为对角检测,在特征图的每个位置预测类热图(Class heatmaps)、成对嵌入(pair embeddings)和角偏移量(corner offsets)。
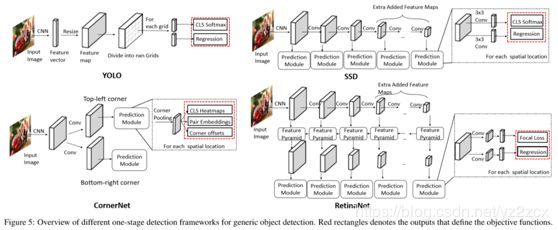
图2.4 一阶目标检测算法
2.3、骨干架构
在目标检测中常用的CNN骨干架构有深度方向发展的:VGG16、ResNet及其变种(如DenseNe、ResNeXt)、MobileNet;宽度方向发展的:GoogleNet和inception模块。 前面这几个网络都是基于图像分类任务作为目标检测任务的预训练架构,与目标检测存在一定冲突,因此,出现了DetNet、Hourglass Network等网络。
2.4、候选框生成
候选框生成目前主要有:
1、传统计算机视觉方法,可以分为三个阶段:目标分数 (Objectness Score based methods)衡量候选框包含目标的可能性、亚像素合并 (Superpixels Merging)、种子分割(Seed Segmentation)从多个种子区域开始,为每个种子点生成前景和背景分割;
2、基于锚点的方法:RPN(Region Proposal Network)、S3FD(Single Shot Scaleinvariant Face Detector)、DeRPN(Dimension-Decomposition Region Proposal Network)、DeepProposals、RefineDet(Single-Shot Refinement Neural Network)、Cascade R-CNN等;
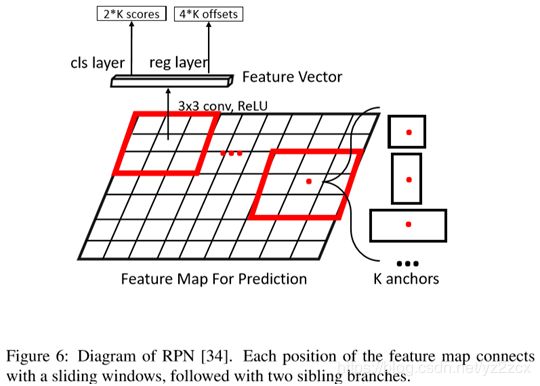
图2.5 RPN示意图
3、基于特征点算法有两个类别,基于角点的和基于中心的。基于角点的有Denet、CornerNet等;基于中心的有FSAF(feature-selection-anchor-free)、CenterNet等;
4、其他算法:AZnet。
2.5、特征表达学习
2.5.1、多尺度学习
多尺度学习主要利用CNN中的一个特性,网络的浅层特征是包含比较多的空间信息,其分辨率相对较高、感受野相对较小,适合检测小物体;深层特征包含较多的语义信息,感受野相对较大,对光照、平移具有较强的鲁棒性,适合检测大物体。
目前主要有四种范式:图像金字塔(Image Pyramid)、预测金字塔(Prediction Pyramid)、综合特征(Integrated Features)、特征金字塔(Feature Pyramid)。
1、图像金字塔
图像金字塔的做法有:i)、将输入图像缩放到不同尺度,训练不同分类器;ii)、将输入图像缩放到同一尺度(设计一个轻量级比例感知网络)再用单尺度网络检测;iii)、训练多个尺度相关的检测器,每个检测器负责一定比例的目标;
典型网络有:SNIP(Scale Normalization for Image Pyramids)。
2、综合特征
设计单一尺度网络,将不同层的的特征融合为一个综合的特征用于学习和分类。其中多数算法会用到跳级连接(skip connections)、ROI池化(ROI Pooling)、反卷积层(Deconvolutional)等。
典型网络有:ION(Inside-Outside Network)、HyperNet、MLKP(Multi-scale Location-aware Kernel Representation)。
3、预测金字塔
训练的时候将多层特征综合训练,预测的时候是对多个层进行的,每个层负责一定尺度的目标。
典型网络:SSD、MSCNN(Multi-scale Deep Convolutional Neural Network)、RFBNet(Receptive Field Block Net)。
4、特征金字塔
特征金字塔结合了综合特征和预测金字塔的两种做法,既融合深浅层特征,又做了多尺度预测。 典型网络:FPN(Feature Pyramid Network)及其变种。
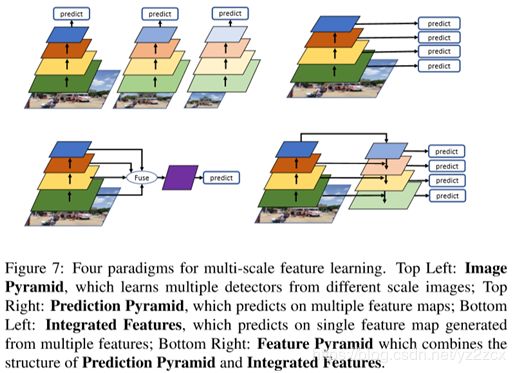
图2.6 四种多尺度学习范式
2.5.2、区域特征编码
区域特征编码(Region Feature Encoding )是对候选框生成步骤生成的各个候选框区域进行图像特征提取和编码。常见的操作有R-CNN的基于双线性插值缩放;ROI Pooing、ROI Warping、ROI Align、以及改进的PrROIPooling(Precise ROI Pooing)、PSROIPooling(Position Sensitive ROI Pooing)等;
典型网络:CoupleNet等。
2.5.3、语境推理
语境推理(Contextual Reasoning)是分析图像中的语境信息,用于提高目标检测的性能。主要有两种:全局语境推理和区域语境推理。
全局语境推理(Global context reasoning)应该是加入了目标检测图像中的背景信息。主要采用的网络模型有ION、DeepId、Faster R-CNN的改进等。
区域语境推理(Region Context Reasoning)则是编码区域周围的语境信息,并学习目标与周围语境之间的推理关系。主要采用的网络有:SMN(Spatial Memory Network)、SIN(Structure Inference Net)、GBDNet(GatedBi-DirectionalCNN)等。
2.5.4、可形变特征学习
可形变特征学习(Deformable Feature Learning)主要是应对目标检测任务中的对非刚性、易形变的目标的检测。深度学习之前常用的是DPMs(Deformable Part based Models)算法,而深度学习算法中则是用模型来检测目标的各个部位。主要的网络结构有:DeepID,比较新的研究中有提出可形变的卷积层。
2.6、学习策略
学习策略在深度学习的应用中主要分训练阶段和测试阶段。
2.6.1、训练阶段
1、数据增强
数据增强(Data Augmentation)主要操作:镜像、旋转、随即裁剪、缩放、颜色调整等
2、不平衡采样
不平衡采样(Imbalance Sampling),因为在候选框生成阶段生成的很多区域中其实都是不包含目标的,就导致实际包含目标的正样本太少,而包含背景的负样本又太多,造成正负样本不平衡(imbalance of negative and positive samples)。
正负样本不平衡会引起类别不平衡(class imbalance)和差异不平衡(difficulty imbalance),类别不平衡中由于负样本多于正样本,导致在反向传播算法中,负样本的值会占主导;差异不平衡与类别不平衡相关,由于类别不平衡导致分类器容易对背景负样本进行分类,而对正样本的分类反而变得困难。
对类别不平衡,在二阶检测器中,R-CNN和Fast R-CNN主要是筛选掉大部分负样本,并限制候选框生成的区域在大约2000个。Fast R-CNN还进一步限制正负样本比例在1:3。还有的做法是固定前景和背景的样本比例,但是对负样本的选择,会偏向选择有较高的分类损失的负样本。
对差异不平衡,在类别设计上,采用C+1类,也就是多了背景类来训练;在损失函数上,设计了梯度协调机制GHM(gradient harmonizing mechanism)。
3、定位优化
定位优化(Localization Refinement):i)、生成高质量的候选框,R-CNN使用了L2辅助边界回归器,Fast R-CNN则使用了平滑的L1回归器;ii)、迭代的边界回归器;iii)、LocNe:模拟每个边界框的分布并优化学习到的预测结果;iiii)、优化网络结构或目标函数:Multi-Path Network、Fitness-NMS、Grid R-CNN。
4、级联学习
级联学习(Cascade learning),是一种粗糙到精细的学习策略,从给定分类器的输出搜集信息,通过级联的方式构建强分类器。
深度学习目标检测任务中的做法有CRAFT(Cascade Region-proposal-network And FasT-rcnn)、RefineDet、Cascade R-CNN等。
5、其他 其它算法中有:i)、Adversarial Learning,对抗学习,主要有GAN,如用于小目标检测的Perceptual GAN、A-Fast-R-CNN;ii)、Training from Scratch,重新训练,不依赖基于分类任务训练的预训练模型,有DSOD (Deeply Supervised Object Detectors)等;iii)、Knowledge Distillation,知识蒸馏。
2.6.2、测试阶段
目标检测算法的预测是一组密集预测,因此不能直接作为预测输出。同时也需要一定策略来提升测试阶段的预测输出。
1、删除重复
删除重复(Duplicate Removal),非极大值抑制是常用的方法。一阶检测器同个目标周围的候选框可能会有相同的分数导致出现假阳性;二阶检测器的边界框回归容易将一些候选框回归到同一个目标,也容易导致这样的问题。因此引入NMS。
NMS根据预测值排序同个类下所有候选框,取最大预测值的框为M,计算M与其他框B的IoU,大于一定值B的分数就置零。
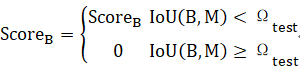
但是容易出现某些目标就刚好出现在Ω_test范围内而漏掉,因此引入Soft-NMS,就是对IoU(B,M)≥Ω_test情况下的Score_B做一个函数映射:
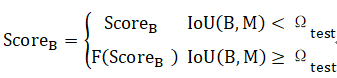
2、模型加速
模型加速(Model Acceleration):i)、R-FCN提取空间敏感的特征图并与空间敏感ROI池化共享计算损失,但特征图的通道数量随着类别数量的增加会随之明显增加;ii)、Light Head R-CNN极大降低特征图的通道数量(1024 to 16)而不是共享计算,因此计算成本较低。iii)、改用更有效率的网络骨架,MobileNet、PVANet或者TensorRT来优化模型。
3、其它
不同尺度的目标构建不同尺度的图像等。
2.7、应用
2.7.1、人脸检测
人脸检测(Face detection)与通用的目标检测之间的不同:i)、人脸的尺度方位更大。且遮挡、模糊等情况更常见;ii)、人脸有更强的结构信息,且只有一个检测目标。
早期的人脸检测是通过滑动窗口、密集图像网格来手动编码,并用于训练和定位目标。主要有基于Haar特征的AdaBoost分类器算法。
深度学习方法有:基于Fast R-CNN或SSD、一阶的S3FD、SSH(Single Stage Headless Face Detector)、Scale Aware Face network、基于RetinaNet的、MTCNN、Face MegNet、FDNet、CMSRCNN(Contextual Multi-Scale Region-based Convolution Neural Network)、PyramidBox等。
2.7.2、行人检测
行人检测(Pedestrian Detection) 与通用的目标检测之间的不同:i)、行人目标的结构性较好,宽高比例比较固定,但尺度范围非常大;ii)、行人检测的拥挤、遮挡、模糊的问题更严重;iii)、环境复杂,有更多硬性负样本(如交通灯、邮箱等)。
传统方法主要利用滑动窗口策略利用积分通道特征定位对象,并用SVM等来实现区域分类器。因此早期工作会集中在用于分类的稳定的特征描述子的构建上,如HOG。
深度学习方法有利用级联深度神经网络(cascade of deep convolutional networks)、利用决策树分类多尺度特征图、SAFRCNN(Scale-aware Fast R-CNN)、SDP(Scale Dependent Pooling)和CRC(Cascaded Rejection Classifiers)、OR-CNN(Occlusion-aware R-CNN)、DeepParts等。
2.7.3、其它
logo检测(Logo detection),难度是logo可能会更小,非刚性变换更强;
Existing detection algorithms,检测图像或视频中是否有某目标,主要是视频中,与目标出现的时间和空间都有关系;
其他的还有车辆检测、交通信号检测、骨架检测等。
2.8、检测基准
2.8.1、通用检测基准
1、数据集

2、评价指标

2.8.2、人脸检测基准
1、数据集

2、评价指标

2.8.3、行人检测基准
1、数据集

2、评价指标

* 评价指标中出现的符号与定义

2.8.4、算法对比
1、VOC数据集

2、MS COCO

2.8.5、未来方向
1、可扩展的候选框生成策略(Scalable Proposal Generation Strategy)
2、有效的上下文信息编码(Effective Encoding of Contextual Information)
3、基于自动机器学习的检测(Detection based on Auto Machine Learning(AutoML)),耗GPU,但最近的进展不错。
4、针对对象检测的新基准(Emerging Benchmarks for Object Detection)
5、少样本目标检测(Low-shot Object Detection)
6、适合目标检测任务的骨干架构(Backbone Architecture for Detection Task)
7、其它研究问题(Other Research Issues):大批量学习(large batch learning)和增量学习(incremental learning)
论文:https://arxiv.org/pdf/1908.03673.pdf
北风初秋至,吹我章华台。
浮云多暮色,似从崦嵫来。
枯桑鸣中林,络纬响空阶。
翩翩飞蓬征,怆怆游子怀。
故乡不可见,长望始此回。
-- 《古八变歌》