MySQL函数使用
1. UUID()函数
UUID是可以生成时间、空间上都独一无二的值,是随机+规则组合而成,UUID产生的是字符串类型值,固定长度为 36 个字符。
例:
SELECT UUID(),UUID(),LENGTH(UUID()),CHAR_LENGTH(UUID());
![]()
2. IF()函数语法:
IF(expr1,expr2,expr3);如果expr1是TRUE那么返回expr2否则返回expr3。IF()返回一个数字或字符串值,取决于它被使用的上下文。
例:
SELECT IF(1>2,2,3); -- 3
SELECT IF(1<2,'yes','no'); -- 'yes'
SELECT IF(STRCMP('test','test1'),'yes','no'); -- 'no'
SELECT IF(sva=1,'男','女');3. IFNULL()函数语法:
IFNULL(expr1,expr2);如果expr1是NULL则返回expr2,否则返回expr1。IFNULL()返回一个数字或字符串值,取决于它被使用的上下文环境。
例:
SELECT IFNULL(666,888); -- 666
SELECT IFNULL(NULL,'111'); -- 1114. COALESCE()函数语法:
COALESCE(value1,value2,...);
COALESCE函数需要许多参数,并返回第一个非NULL参数。如果所有参数都为NULL,则COALESCE函数返回NULL。
例:
SELECT COALESCE(NULL, 0); -- 0
SELECT COALESCE(NULL, NULL); -- NULL
SELECT COALESCE(NULL,NULL,'111',NULL,'222') AS test; -- 111
要替换结果集中的NULL值,可以使用COALESCE函数,如username为空时替换为'XXX' :
SELECT uid,city,COALESCE(username, 'XXX') AS username FROM user_info ;
5. STRCMP()函数语法:
STRCMP(expr1,expr2);如果expr1等于expr2则返回STRCMP()返回0,若根据当前分类次序第一个参数小于第二个则返回 -1,其它情况返回 1 。
例:
SELECT STRCMP(123, 123); -- 0
SELECT STRCMP(123, 122); -- 1
SELECT STRCMP(123, 124); -- -1
SELECT STRCMP('abc', 'abc'); -- 0
SELECT STRCMP('abc', 'abb'); -- 1
SELECT STRCMP('abc', 'abd'); -- -16. CASE()函数语法:
-- 格式一:
CASE <单值表达式>
WHEN <表达式值> THEN
WHEN <表达式值> THEN
...
WHEN <表达式值> THEN
ELSE
END
-- 格式二:
CASE
WHEN <表达式判断值> THEN
WHEN <表达式判断值> THEN
...
WHEN <表达式判断值> THEN
ELSE
END 例:
-- 格式一:简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他'
END
-- 格式二:Case搜索函数
CASE
WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他'
END这两种方式可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。 还有一个需要注意的问题,Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
7. CAST()函数语法:
SELECT CAST(expr as type);CAST(字段名 AS 转换的类型 ) 其中类型可以为:
BINARY[(N)] 二进制
SIGNED [INTEGER] 有符号(整数)
UNSIGNED [INTEGER] 无符号(整数)
CHAR [(N)]字符型
DATE 日期型
TIME 时间型
DATETIME 日期和时间型
DECIMAL 浮点类型/小数
例:
/*
表名:table1
字段:date_time:2017-11-15 17:20:50
*/
SELECT CAST(date_time AS SIGNED) AS date_time FROM table1; -- 20171115172050
SELECT CAST(date_time AS UNSIGNED) AS date_time FROM table1; -- 20171115172050
SELECT CAST(date_time AS CHAR) AS date_time FROM table1; -- 2017-11-15 17:20:50
SELECT CAST(date_time AS DATE) AS date_time FROM table1; -- 2017-11-15
SELECT CAST(date_time AS TIME) AS date_time FROM table1; -- 17:20:50
SELECT CAST(date_time AS DATETIME) AS date_time FROM table1; -- 2017-11-15 17:20:50
/*
表名:table2
字段:num:30
*/
select cast(num as decimal(10, 2)) as num from table2; -- 30.00※ DECIMAL数据类型用于要求非常高的精确度的计算中,这些类型允许指定数值的精确度和计数方法作为选择参数。精确度在这里是指为这个值保存的有效数字的总个数,而计数方法表示小数点后数字的个数。例如:DECIMAL(10, 2)可以存储8位整数2位小数位的数字,其中10是小数点左右两边的数字个数之和(不包括小数点),2代表小数点右边的小数位数或数字个数。
8. 字符串截取函数:left(),right(),substring(),substring_index()。还有 mid(),substr()。其中 mid(),substr() 等价于 substring() 函数,substring()的功能非常强大和灵活。
/*字符串截取:LEFT(str, len)*/
SELECT LEFT('Hello word',3); -- Hel
/*字符串截取:RIGHT(str, len)*/
SELECT RIGHT('Hello word',3); -- ord
/*字符串截取:SUBSTRING(str, pos); SUBSTRING(str, pos, len);*/
/*从字符串的第 3 个字符位置开始截取直到结束*/
SELECT SUBSTRING('Hello word', 3); -- llo word
/*从字符串的第 3 个字符位置开始截取 取 6 个字符*/
SELECT SUBSTRING('Hello word', 3, 6); -- llo wo
/*从字符串的第 3 个字符位置(倒数)开始截取直到结束*/
SELECT SUBSTRING('Hello word', -3); -- ord
/*从字符串的第 6 个字符位置(倒数)开始截取 取 3 个字符*/
SELECT SUBSTRING('Hello word', -6, 3); -- o w
※ 函数 SUBSTRING(str , pos , len)中, pos 可以是负值,但 len 不能取负值。
/*字符串截取:substring_index(str,delim,COUNT)*/
/*截取第二个 '.' 之前的所有字符*/
SELECT SUBSTRING_INDEX('www.practice.com','.',2); -- www.practice
/*截取第二个 '.' (倒序)之后的所有字符*/
SELECT SUBSTRING_INDEX('www.practice.com','.',-2); -- practice.com
/*如果在字符串中找不到 delimit 参数指定的值则返回整个字符串*/
SELECT SUBSTRING_INDEX('www.practice.com','.cn',1); -- www.practice.com实例:
-- 查询某个字段后两位字符
SELECT RIGHT(user_name, 2) AS user_name FROM user_info LIMIT 10;
-- 从应该字段取后两位字符更新到另外一个字段
UPDATE user_info SET u_name=RIGHT(user_name, 2);9. GROUP_CONCAT()函数语法:
GROUP_CONCAT(expr);以某个唯一字段分组,去除重复冗余的字段的值打印在一行,逗号分隔(默认)。
例1: 以id分组,将price字段的值打印在一行,逗号分隔。
SELECT id,GROUP_CONCAT(price) FROM lc_commodity_info GROUP BY id;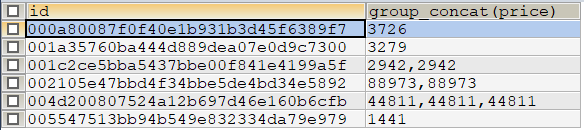
例2: 以id分组,将price字段的值打印在一行,"#" 分隔。
SELECT id,GROUP_CONCAT(price SEPARATOR '#') FROM lc_commodity_info GROUP BY id;
例3: 以id分组,将去除重复冗余的price字段的值打印在一行,逗号分隔。
SELECT id,GROUP_CONCAT(DISTINCT price) FROM lc_commodity_info GROUP BY id;例4: 以id分组,将price字段的值打印在一行,逗号分隔,按照price倒序排列。
SELECT id,GROUP_CONCAT(price ORDER BY price DESC) FROM lc_commodity_info GROUP BY id;
10. WITH ROLLUP是用来在分组统计数据的基础上再进行统计汇总,即用来得到group by的汇总信息。
例:
SELECT COALESCE(sage,'汇总') AS age,COUNT(*) AS num FROM age GROUP BY sage WITH ROLLUP;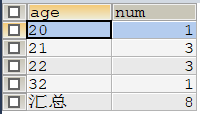
转载请注明出处:BestEternity亲笔。