对抗样本(论文解读四): Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
准备写一个论文学习专栏,先以对抗样本相关为主,后期可能会涉及到目标检测相关领域。
内容不是纯翻译,包括自己的一些注解和总结,论文的结构、组织及相关描述,以及一些英语句子和相关工作的摘抄(可以用于相关领域论文的写作及扩展)。
平时只是阅读论文,有很多知识意识不到,当你真正去着手写的时候,发现写完之后可能只有自己明白做了个啥。包括从组织、结构、描述上等等很多方面都具有很多问题。另一个是对于专业术语、修饰、语言等相关的使用,也有很多需要注意和借鉴的地方。
本专栏希望在学习总结论文核心方法、思想的同时,期望也可以学习和掌握到更多论文本身上的内容,不论是为自己还有大家,尽可能提供更多可以学习的东西。
当然,对于只是关心论文核心思想、方法的,可以只关注摘要、方法及加粗部分内容,或者留言共同学习。
Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
HanXu1 YaoMa2 HaochenLiu3 DebayanDeb4 HuiLiu5 JiliangTang6 AnilJain7
Michigan State University, {[email protected]}
论文公布于2019/9/17,是目前已知最新且较全的相关综述文章,对于相关方向具有很大的学习和扩展意义。
综述较长,分上下篇,此为上篇。
**
Abstract
**
Deep neural networks (DNN) have achieved unprecedented success in numerous machine learning tasks in various domains. However, the existence of adversarial examples raises our concerns in adopting deep learning to safety-critical applications.
本文提供了一个系统且全面的关于主流攻击和相关成功防御的综述。对于最受欢迎的3种数据类型:图像、图及文本,回顾了其相应最先进的攻击算法及防御对策。( the main threats of attacks and the success of corresponding countermeasures)
1.Introduction
Deep neural networks have become increasingly popular and successful in many machine learning tasks. 引
Because of these accomplishments, deep learning techniques are also applied in safety-critical tasks. For example, in autonomous vehicles, Similarly, in the financial fraud detection systems, Therefore, the safety issues of deep neural networks become a major concern. 引
For example, perturbing only a couple of edges can mislead the graph neural networks, (Z¨ugner et al., 2018), or inserting typos to a sentence can fool text classification or dialogue systems, (Ebrahimi et al., 2017). 关于图和文本的应用
To deal with the threat of adversarial examples,studies have been published with the aim to find countermeasures to protect deep neural networks. 相应防御方法大致可分为3类:
1)gradient masking,因为许多攻击方法都是基于模型的梯度信息,因此掩盖或混淆梯度可以达到相应的防御效果;
2) Robust Optimization, 训练一个鲁棒的模型可以抵御对抗样本;
3)Adversary Detection, 在将样本送入模型之前分辨开干净和对抗样本。
综述的主要框架如下:第二部分介绍一些定义和概念,及提供了攻击和防御的基本分类;三和四部分主要介绍了图像分类场景下的攻防技术;第五部分简要介绍了一些关于对抗样本现象的研究解释;六和七部分分别回顾了图数据和文本数据的相关研究。
2.Definitions and Notations
2.1.Threat Model
2.1.1.ADVERSARY’S GOAL
• Poisoning Attack vs Evasion Attack :
Poisoning attacks 为攻击者注入或改变一些假的样本到训练集,从而造成训练模型的在一些测试集上的失败。例如,基于web的存储库和“蜜罐”( web-based repositories and “honeypots”)经常收集恶意软件示例以进行训练,这为对手提供了毒害数据的机会。
Evasion attacks,原模型固定,只是创建一些假的样本来逃避或欺骗模型。
• Targeted Attack vs Non-Targeted Attack
基于原有模型,对于给定的对抗样本,使其预测为指定目标或者使原有预测错误。
2.1.2.ADVERSARY’S KNOWLEDGE
• White-Box Attack
对于攻击者可以获得目标模型的网络架构、参数和梯度等信息,然后利用这些信息设计对抗样本。白盒攻击被广泛研究,因为模型结构和参数的公开有助于人们清楚地了解DNN模型的弱点,并可以进行数学分析。
• Black-Box Attack
目标模型内部设置未知,只能通过模型的输入输出之间的关系了探索其脆弱性,相比更加符合实际应用。
• Semi-white (grey) Box Attack
白盒设置下训练一个对抗样本生成器,,,(不了解)
2.1.3. VICTIM MODELS
A Conventional Machine Learning Models
SVM、 fully-connected shallow neural networks for the MNIST 、Bayesian
( require domain knowledge and human feature engineering)
B DNNs
end-to-end learning algorithms、 learn objects’ underlying structures and attributes、 non-explicitness nature of DNNs,
(a)Fully-Connected Neural Networks

通过回传计算梯度![]() ,表示输出针对于输入改变的响应。
,表示输出针对于输入改变的响应。
(b)Convolutional Neural Networks
聚合局部特征学习图像目标表征,可以视为FC的稀疏版本:大部分权重都为0.其训练算法和梯度计算同FC。
© Graph Convolutional Networks
一个流行的图数据节点分类模型。通过聚合相邻节点信息来学习每一个节点的表征,并输出预测分数F(v,X):

X为输入图的特征矩阵,A^依赖于图的度矩阵和邻接矩阵。
(d)Recurrent Neural Networks
于处理序列数据,如NLP。RNN模型,尤其是LSTM,可以存储记忆先前的信息,然后利用先前序列的有用信息预测后一步的序列。
2.2.Security Evaluation
Robustness” and “Adversarial Risk” 是用来描述DNN模型在单个样本和总体上的对抗性的两个术语。
2.2.1.ROBUSTNESS
最小扰动:

2.2.2. ADVERSARIAL RISK (LOSS)
对抗损失:

3.Generating Adversarial Examples
这一部分主要介绍图像分类领域生成对抗样本的主流方法。
数据集包括MNIST、CIFATR10、ImageNet
3.1.White-box Attacks

扰动足够小,且分类器C分类错误t = y.
3.1.1.BIGGIO’S ATTACK
在MNIST数据集上,基于SVMs及3层FC,通过优化判别式函数(最小化)来实现攻击。

3.1.2.SZEGEDY’S L-BFGS ATTACK
攻击dnns图像分类器,目标函数:

引入近似的损失函数:

In the optimization objective of this problem, the first term imposes the similarity between x’ and x. The second term encourages to search x’ which has a small loss value to label t, so the classifier C will be very likely to predict x0 as t.
3.1.3. FAST GRADIENT SIGN METHOD
一步法快速产生对抗样本:

(这里的加减有些不太明白,一步实现攻击效果?有待代码研究)

3.1.4. DEEP FOOL
在数据点x周围学习一个分类器决策边界,找到一条可以使x超过决策边界的路径:
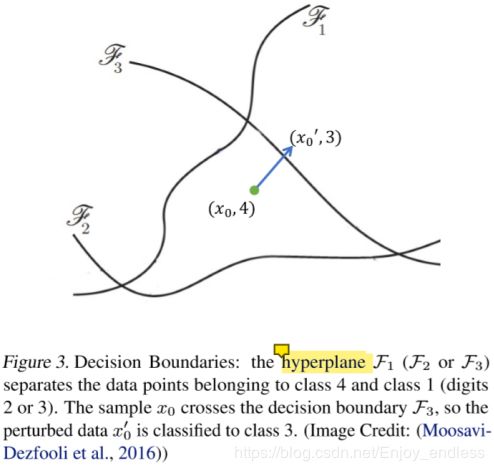
计算样本x0到决策边界的正交向量,并按照向量移动样本x0,直到x0’分类错误。
其 DeepFool (Moosavi-Dezfooli et al., 2016)实验表明,对于通常的DNN图像分类模型,几乎所有的测试样本都非常接近他们的决策边界,如LeNet超过90%的样本可以被小的扰动(l无穷范数小于0.1)所攻击.
3.1.5. JACOBIAN-BASED SALIENCY MAP ATTACK
利用雅可比矩阵 建模输入改变的响应。
建模输入改变的响应。
通过对模型输出影响最大的像素进行连续操作,可以认为是一种贪婪攻击算法。
3.1.6. BASIC ITERATIVE METHOD (BIM) / PROJECTED GRADIENT DESCENT (PGD) ATTACK
一步攻击FGSM的迭代法,

Clip函数负责使其扰动控制在参数范围内,步长alpha较小,步数确保其达到扰动边界。
启发式的寻找具有最大损失的对抗样本。
3.1.7. CARLINI & WAGNER’S ATTACK
寻找最小的扰动,
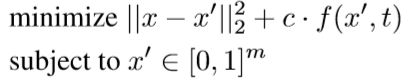
这里的f()利用的是边际损失函数,而非L-BFGS里面用的交叉熵损失。
(这里也没有细讲,有待根据原论文进一步研究)
3.1.8. GROUND TRUTH ATTACK
Attacks and defenses keep improving to defeat each other.
寻找理论上的最小扰动对抗样本。
3.1.9. OTHER Lp ATTACKS
之前的工作大部分聚焦于L2或L无穷范数的限制扰动,其他的Lp攻击:
(a)One-pixel Attack. 使用L0范数,限制扰动x’-x的L0范数将会限制扰动像素的个数。基于VGG16,超过63.5%的CIFAR10测试样本都可以通过只改变一个像素达到攻击的目的。
(b)EAD: Elastic-Net Attack. 同时限制扰动的L1和L2范数,实验表明,之前针对L无穷及L2的防御仍然对于基于L1的攻击很脆弱。
3.1.10.UNIVERSAL ATTACK
之前的攻击都是针对于特定目标样本的,Moosavi-Dezfooli et al., 2017a 试图寻找一个通用扰动,可以攻击不同样本:
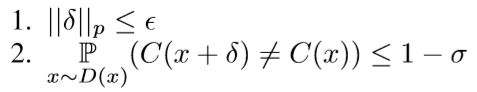
分类器C,数据集D(x),“通用”反例的存在揭示了DNN分类器在所有输入样本上的固有弱点。
3.1.11. SPATIALLY TRANSFORMED ATTACK
之前的攻击都是改变像素即改变图像颜色密度, Xiao et al. (2018b) 提出了通过空间变换:平移、旋转或扭曲局部图像特征,达到攻击目的:

3.1.12. UNRESTRICTED ADVERSARIAL EXAMPLES
生成不受限的对抗样本,即不需要看起来和原样本一样,但是仍然要是人看起来合理的样本。
3.2 Physical World Attack
物理世界的对抗目标, For example, Eykholt et al. (2017) attach stickers on road signs that can severely threaten autonomous cars’ sign recognizer.
3.2.1. CHECKING ADVERSARIAL EXAMPLES IN PHYSICAL WORLD
将之前基于FGSM、BIM等方法产生的对抗样本打印出来,改变不同视角、光照等外界条件,实验表明这些对抗样本仍具有攻击性,尤其是基于FGSM产生的。
3.2.2. EYKHOLT’S ATTACK ON ROAD SIGN

方法流程:
1、寻找攻击区域:通过限制L1范数, ,L1攻击会产生稀疏扰动;
,L1攻击会产生稀疏扰动;
2、在攻击区域内使用L2范数攻击产生贴附条的颜色;
3、打印贴附,可以从很多距离和角度愚弄自动驾驶。
(这一个防御其实很简单,不过攻击方法有些意思,跑过源码,可以研究一下)
3.2.3. ATHALYE’S 3D ADVERSARIAL OBJECT
首先创建了物理3D的对抗物体,对于一个有纹理的3D对象,他们首先优化对象的纹理,这样渲染的图像就可以从不同的角度观看。保持距离、光线、旋转、背景等鲁棒性。

这是一篇相关综述文章,内容较长,分2部分完成,后续见下一部分。