一文教你如何使用 MongoDB 和 HATEOAS 创建 REST Web 服务


作者 | Ion Pascari
译者 | 天道酬勤 责编 | 徐威龙
封图| CSDN 下载于视觉中国
最近,作者在把HATEOAS实现到REST Web服务时遇到了一件有趣的事情,而且他也很幸运地尝试了一个名为MongoDB的NoSQL数据库,他发现该数据库在许多不需要管理实务的不同情况下非常方便。因此,今天他将和我们分享这种经验。也许我们中的一些人可能会学到一些新的东西,即使已经已经学过,但仍然可以对已经学知识有一个巩固复习。
下面我们来看一下作者是如何使用MongoDB和HATEOAS创建REST Web服务,该服务可以实现Richardson成熟度模型的第三级。
首先,我们来介绍一下REST,然后逐步介绍HATEOAS和MongoDB。那么,REST是什么呢?

REST
万维网联盟指出,REST是一个如何构建Web服务的模型。REST Web是WWW(基于HTTP)的子集,其中代理提供统一的接口语义,本质上是创建,检索,更新和删除,而不是任意或特定于应用程序的接口,并且仅通过交换表示来操纵资源。
那么,现在我们知道REST是什么了,作者将简要列出Roy Fielding在其论文的第五章中提到的所有约束:
客户端-服务器:以这样的方式实施服务:将用户界面关注点(客户端获得可移植性)与数据存储关注点(服务器获得可伸缩性)分离开来。
无状态:在客户端和服务器之间实现通信时,服务器在处理请求时永远不会利用储存在服务器上下文中的任何信息,而与会话相关的所有信息都存储在客户端中。
缓存:当可以(隐式或显式)缓存请求的响应时,客户端应获取缓存的响应。
统一接口:所有REST服务都应依赖组件之间相同的统一设计。接口应与提供的服务解耦。
分层系统:客户端永远不知道它们是直接连接到服务器还是连接到某些中间服务器。例如,请求可以通过代理,该代理具有负载平衡或共享缓存的功能。

Richardson成熟度模型

图1:Richardson成熟度模型的级别
正如Martin Fowler所说,该模型是“由Leonard Richardson开发的模型,它将REST方法的主要元素分解为三个步骤。这些步骤引入了资源、HTTP动词和超媒体控件”。
这里简要介绍一下这些级别:
POX沼泽:只有一种资源和一种请求方法POST,并且只有一种通信方式XML。
资源:我们坚持使用POST方法,但是我们获得了更多可以处理的资源。
HTTP动词:目前在适当的情况下(资源),我们正在使用其他HTTP方法,例如GET或DELETE。通常,CRUD操作在此处实现。
超媒体控件:HATEOAS(应用程序状态的超文本引擎),应为客户端提供一个使用服务的启动链接,然后,每个响应都应包含指向该服务其他可能性的超链接。
既然我们知道了REST,并且已经介绍了它的成熟度模型,接下来我们再简要介绍一个NoSQL数据库MongoDB,然后,我们将进行演示!

为什么选择HATEOAS?
首先,我们要指出REST并不容易,没有真正理解REST的人会说这很容易。通常,对于短期内不会增长或更改的小型服务,如果你达到了第二级(HTTP动词),那就更好了。
那么那些正在增长的大型服务呢?很多人会说,只要你做第二级就可以了。为什么?因为HATEOAS是使REST变得复杂的原因之一,这是困难的。如果你真的想获得其优势,则必须在客户端上编写更多代码——处理错误、如何解释资源、如何分析提供的链接和服务器来构建全面而有用的链接等。让我们来看看HATEOAS其中的一些优势:
可用性:客户端开发人员可以根据你提供的链接来有效地使用、了解和探索你的服务。而且,他们可以想象你项目的框架。
可伸缩性:遵循所提供的链接而不是不依赖于服务的代码更改来构造链接的客户端。
灵活性:提供服务较老版本和较新版本的链接,使你可以轻松地与基于旧版本的客户端和基于新版本的客户端进行互操作。
有效性:依赖HATEOAS的客户端永远不必担心服务器上的新版本或代码更改(如硬编码的版本)。
松耦合:HATEOAS通过分配构建和提供链接到服务器的职责来促进客户端和服务器之间的松耦合。

NoSQL?MongoDB?
那么,什么是NoSQL数据库?从名称“非SQL”或“非关系型”衍生而来,这些数据库不使用类似SQL的查询语言,通常称为结构化存储。这些数据库自1960年就已经存在,但是直到现在一些大公司(例如Google和Facebook)开始使用它们时,这些数据库才流行起来。该数据库最明显的优势是摆脱了一组固定的列、连接和类似SQL的查询语言的限制。
有时,NoSQL这个名称也可能表示“不仅仅SQL”,来确保它们可能支持SQL。 NoSQL数据库使用诸如键值、宽列、图形或文档之类的数据结构,并且可以如JSON之类的不同格式存储。
MongoDB是一种无模式的NoSQL数据库,它是面向文档的,因此,如上所述,它提供了高性能和良好的可伸缩性,并且是跨平台的。 之所以推荐MongoDB,是因为它具有完整的索引支持,JSON格式的对象存储结构简单明了,出色的动态文档查询支持,不必将应用程序对象转换到到数据库对象以及MongoDB的专业支持。

准备使用MongoDB来编写代码
现在我们准备进行正题。让我们构建一个简单的EmployeeManager Web服务,我们将使用它来演示与MongoDB连接的HATEOAS。
为了引导我们的应用程序,我们将使用Spring Initializr。我们将使用Spring HATEOAS和Spring Data MongoDB作为依赖项。你应该看到类似下图2所示的内容。

图2 :引导应用程序
配置完成后,下载zip并将其作为Maven项目导入你喜欢的IDE中。
首先,让我们配置application.properties。要获得MongoDB连接,你应该处理以下参数:
spring.data.mongodb.host= //Mongo server host
spring.data.mongodb.port= //Mongo server port
spring.data.mongodb.username= //Login user
spring.data.mongodb.password= //Password
spring.data.mongodb.database= //Database name
一般来说,如果所有内容都是全新安装的,并且你没有更改或修改任何Mongo属性,则只需提供一个数据库名称(已经通过GUI创建了一个数据库名称)。
spring.data.mongodb.database = EmployeeManager
另外,为了启动Mongo实例,作者创建了一个.bat,它指向安装文件夹和数据文件夹。它是这样的:
"C:\Program Files\MongoDB\Server\3.6\bin\mongod" --dbpath D:\Inther\EmployeeManager\warehouse-data\db
现在,我们来快速创建模型。这里有两个模型,员工模型和部门模型。检查它们,确保有没有参数、getter、setter、equals方法和hashCode生成的构造函数。(不用担心,所有代码都在GitHub上,你可以稍后查看它:https://github.com/theFaustus/EmployeeManager。)
public class Employee {
private String employeeId;
private String firstName;
private String lastName;
private int age;
}
public class Department {
private String department;
private String name;
private String description;
private List employees;
}
现在我们已经完成了模型的制作,让我们来创建存储库,以便来测试持久性。存储库如下所示:
public interface EmployeeRepository
extends MongoRepository {
}
public interface DepartmentRepository
extends MongoRepository{
}
如上所示,这里没有方法,因为大家都知道Spring Data中的中心接口被命名为Repository,在其之上是CrudRepository,它提供了处理模型的基本操作。
在CrudRepository之上,我们有PagingAndSortingRepository,它为我们提供了一些扩展功能,来简化分页和排序访问。在我们的案例中,最重要的是MongoRepository,它用于严格处理我们的Mongo实例。
因此,对于我们的案例来说,除了那些现成的方法外,我们不需要任何其他方法,但是仅出于学习目的,作者在这里要提到的是你可以添加其他查询方法的两种方法:
“惰性”(查询创建):此策略将尝试通过分析查询方法的名称并推断关键字(例如findByLastnameAndFirstname)来构建查询。
编写查询:这里没有什么特别的。例如,只用@Query注释你的方法,然后自己编写查询。你也可以在MongoDB中编写查询。下面是基于JSON的查询方法的示例:
@Query("{ 'firstname' : ?0 }")
List findByTheEmployeesFirstname(String firstname);
至此,我们已经可以测试我们持久性如何工作。我们只需要对模型进行一些调整即可。通过调整,作者的意思是我们需要注释一些东西。Spring Data MongoDB使用MappingMongoConverter将对象映射到文档,下面是我们将要使用的一些注释:
@Id :字段级别注释,指出你的哪个字段是身份标识。
@Document :类级别的注释,用于表示该类将被持久化到数据库中。
@DBRef :描述参考性的字段级别注释。
注释完成后,我们可以使用CommandLineRunner获取数据库中的一些数据,CommandLineRunner是一个接口,用于在应用程序完全启动时(即在run()方法之前)运行代码段。在下面,你可以看一下作者的Bean配置。
@Bean public CommandLineRunner init(EmployeeRepository employeeRepository, DepartmentRepository departmentRepository) {
return (args) -> {
employeeRepository.deleteAll();
departmentRepository.deleteAll();
Employee e = employeeRepository.save(new Employee("Ion", "Pascari", 23));
departmentRepository.save(new Department("Service Department", "Service Rocks!", Arrays.asList(e)));
for (Department d : departmentRepository.findAll()) {
LOGGER.info("Department: " + d);
}
};
}
我们已经创建了一些模型,并对它们进行了持久化。现在,我们需要一种与他们交互的方式。如上所说,所有代码都可以在GitHub上找到,因此作者在这里将仅向我们展示一个域服务(接口和实现)。
接口如下:
public interface EmployeeService {
Employee saveEmployee(Employee e);
Employee findByEmployeeId(String employeeId);
void deleteByEmployeeId(String employeeId);
void updateEmployee(Employee e);
boolean employeeExists(Employee e);
List findAll();
void deleteAll();
}
接口的实现如下:
@Service public class EmployeeServiceImpl implements EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
@Override
public Employee saveEmployee(Employee e) {
return employeeRepository.save(e);
}
@Override
public Employee findByEmployeeId(String employeeId) {
return employeeRepository.findOne(employeeId);
}
@Override
public void deleteByEmployeeId(String employeeId) {
employeeRepository.delete(employeeId);
}
@Override
public void updateEmployee(Employee e) {
employeeRepository.save(e);
}
@Override
public boolean employeeExists(Employee e) {
return employeeRepository.exists(Example.of(e));
}
@Override
public List findAll() {
return employeeRepository.findAll();
}
@Override
public void deleteAll() {
employeeRepository.deleteAll();
}
}
这里没有什么特别的要注意的,下面我们将继续讨论最后一个难题——控制器!你可以在下面看到员工资源的控制器实现。
@RestController
@RequestMapping("/employees")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@RequestMapping(value = "/list/", method = RequestMethod.GET)
public HttpEntity> getAllEmployees() {
List employees = employeeService.findAll();
if (employees.isEmpty()) {
return new ResponseEntity<>(HttpStatus.NO_CONTENT);
} else {
return new ResponseEntity<>(employees, HttpStatus.OK);
}
}
@RequestMapping(value = "/employee/{id}", method = RequestMethod.GET)
public HttpEntity getEmployeeById(@PathVariable("id") String employeeId) {
Employee byEmployeeId = employeeService.findByEmployeeId(employeeId);
if (byEmployeeId == null) {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
} else {
return new ResponseEntity<>(byEmployeeId, HttpStatus.OK);
}
}
@RequestMapping(value = "/employee/", method = RequestMethod.POST)
public HttpEntity saveEmployee(@RequestBody Employee e) {
if (employeeService.employeeExists(e)) {
return new ResponseEntity<>(HttpStatus.CONFLICT);
} else {
Employee employee = employeeService.saveEmployee(e);
URI location = ServletUriComponentsBuilder .fromCurrentRequest().path("/employees/employee/{id}")
.buildAndExpand(employee.getEmployeeId()).toUri();
HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.setLocation(location);
return new ResponseEntity<>(httpHeaders, HttpStatus.CREATED);
}
}
@RequestMapping(value = "/employee/{id}", method = RequestMethod.PUT)
public HttpEntity updateEmployee(@PathVariable("id") String id, @RequestBody Employee e) {
Employee byEmployeeId = employeeService.findByEmployeeId(id);
if(byEmployeeId == null){
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
} else {
byEmployeeId.setAge(e.getAge());
byEmployeeId.setFirstName(e.getFirstName());
byEmployeeId.setLastName(e.getLastName());
employeeService.updateEmployee(byEmployeeId);
return new ResponseEntity<>(employeeService, HttpStatus.OK);
}
}
@RequestMapping(value = "/employee/{id}", method = RequestMethod.DELETE)
public ResponseEntity deleteEmployee(@PathVariable("id") String employeeId) {
employeeService.deleteByEmployeeId(employeeId);
return new ResponseEntity<>(HttpStatus.NO_CONTENT);
}
@RequestMapping(value = "/employee/", method = RequestMethod.DELETE)
public ResponseEntity deleteAll() {
employeeService.deleteAll();
return new ResponseEntity<>(HttpStatus.NO_CONTENT);
}
}
因此,对于上面实现的所有方法,我们将自己定位在Richardson成熟度模型的第二级,因为我们使用了HTTP动词并实现了CRUD操作。现在,我们有了与数据进行交互的方法,并且可以使用Postman,我们可以如下图3所示检索资源,或者可以如下图4所示添加新资源。
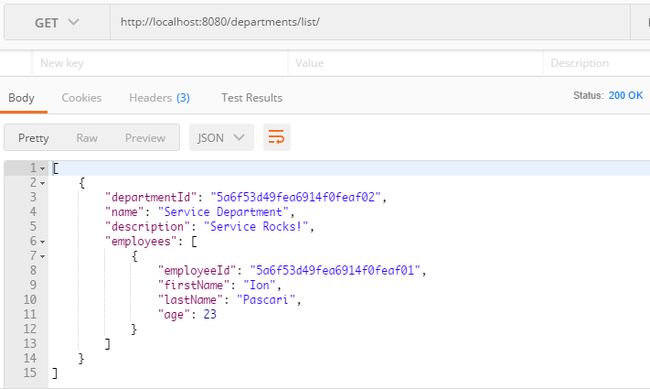 图3 :检索JSON中的部门列表
图3 :检索JSON中的部门列表
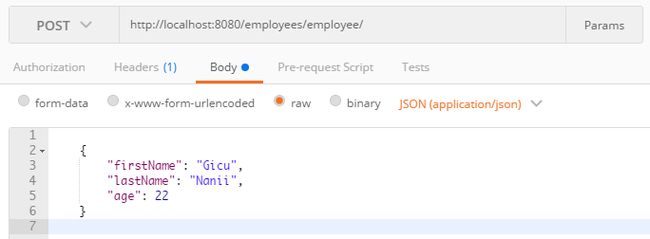 图4:JSON中添加新员工
图4:JSON中添加新员工

HATEOAS即将来临
绝大多数人都止步于此,因为通常情况下,对他们或Web服务而言,这已经就足够了,但这不是我们在这里的原因。因此,如前所述,支持HATEOAS或超媒体驱动的站点的Web服务应该能够提供有关如何使用和导航Web服务的信息,方法是包含与响应之间具有某种关系的链接。

你可以将HATEOAS想象成一个路标。当你开车的时候,这些标志会指引你。例如,如果你需要到达机场,则只需遵循指示标志,如果你需要返回,则再次遵循指示标志就可以了,而且你一直知道你可以待在哪里、停车或开车等等。
让我们实现资源表示形式附带的链接,我们必须通过扩展ResourceSupport来继承add()方法来调整模型,这给我们提供一个不错的选择,可以为资源表示形式设置值,而无需添加任何新字段 。
@Document
public class Employee extends ResourceSupport{...}
现在,让我们开始创建链接。为此,Spring HATEOAS提供了一个Link对象来存储这种信息,并提供CommandLinkBuilder来构建它。
假设我们想要为员工id添加一个GET响应的链接。
@RequestMapping(value = "/employee/{id}", method = RequestMethod.GET)
public HttpEntity getEmployeeById(@PathVariable("id") String employeeId) {
Employee byEmployeeId = employeeService.findByEmployeeId(employeeId);
if (byEmployeeId == null) {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
} else { byEmployeeId.add(linkTo(methodOn(EmployeeController.class).getEmployeeById(byEmployeeId.getEmployeeId())).withSelfRel());
return new ResponseEntity<>(byEmployeeId, HttpStatus.OK);
}
}
如果你注意到以下几个方法:
add():设置链接值的方法。
linkTo(Class controller):一个静态导入的方法,该方法允许创建一个新的ControllerLinkBuilder,它的基类指向控制器类。
methodOn(Class controller,Object ... parameters):静态导入的方法,它创建到控制器类的间接引用,从而能够从该类调用方法并使用其返回类型。
withSelfRel():一种最终创建链接的方法,该链接默认具有指向自身的关系。
现在,GET将产生以下响应:
{
"employeeId": "5a6f67519fea6938e0196c4d",
"firstName": "Ion",
"lastName": "Pascari",
"age": 23,
"_links": {
"self": {
"href": "http://localhost:8080/employees/employee/5a6f67519fea6938e0196c4d"
}
}
}
响应不仅包含员工的详细信息,还包含可在其中导航的自链接URL。
_links代表资源表示的新设置值。
self代表链接指向的关系类型。在这种情况下,它是一个自引用超链接。也可能有其他类型的关系,例如指向另一个类(我们将在稍后介绍)。
href是标识资源的URL。
现在,假设我们要为部门列表添加指向GET响应的链接。在这里,事情变得越来越有趣,因为部门不仅指向自己,也指向员工,员工也指向自己和他们的列表。因此,让我们看一下代码:
@RequestMapping(value = "/list/", method = RequestMethod.GET)
public HttpEntity> getAllDepartments() {
List departments = departmentService.findAll();
if (departments.isEmpty()) {
return new ResponseEntity<>(HttpStatus.NO_CONTENT)
} else {
departments.forEach(d -> d.add(linkTo(methodOn(DepartmentController.class).getAllDepartments()).withRel("departments")));
departments.forEach(d -> d.add(linkTo(methodOn(DepartmentController.class).getDepartmentById(d.getDepartmentId())).withSelfRel()));
departments.forEach(d -> d.getEmployees().forEach(e -> { e.add(linkTo(methodOn(EmployeeController.class).getAllEmployees()).withRel("employees"));
e.add(linkTo(methodOn(EmployeeController.class).getEmployeeById(e.getEmployeeId())).withSelfRel());
}));
return new ResponseEntity<>(departments, HttpStatus.OK);
}
}
因此,此代码将产生以下响应:
{
"departmentId": "5a6f6c269fea690904a02657",
"name": "Service Department",
"description": "Service Rocks!",
"employees": [
{
"employeeId": "5a6f6c269fea690904a02656",
"firstName": "Ion",
"lastName": "Pascari",
"age": 23,
"_links": {
"employees": {
"href": "http://localhost:8080/employees/list/"
},
"self": {
"href": "http://localhost:8080/employees/employee/5a6f6c269fea690904a02656"
}
}
}
],
"_links": {
"departments": {
"href": "http://localhost:8080/departments/list/"
},
"self": {
"href": "http://localhost:8080/departments/department/5a6f6c269fea690904a02657"
}
}
}
除了存在一些未命名为self的关系链接之外,没有任何改变。这些是作者之前谈到的其他类型的关系,它们是与withRel(String rel)建立在一起的:
withRel(String rel):一种方法,该方法最终以指向给定rel的关系创建Link。
恭喜你, 到这里,我们可以说已经达到了Richardson成熟度模型的第3级,当然,我们之所以没有这样做,是因为我们需要对Web服务进行更多的检查和改进,例如提供有关资源状态或任何其他事物的链接,但是我们几乎做到了!
你可以在此处获得完整的GitHub源代码:
https://github.com/theFaustus/EmployeeManager
希望你能喜欢,如果有不清楚的地方或其他意见,欢迎评论区留言告诉我们或者和我们讨论。


推荐阅读:另一种声音:容器是不是未来?
GitHub 疑遭中间人攻击,最大暗网托管商再被黑!
漫画:什么是 “模因” ?
1 分钟抗住 10 亿请求!某些 App 怎么做到的?| 原力计划
2020,国产AI开源框架“亮剑”TensorFlow、PyTorch
探索比特币独特时间链、挖矿费用及场外交易的概念
真香,朕在看了!