Pandas学习总结——4. Pandas变形 之 透视表 & 变形方法
文章目录
- 1 透视表
- 1.1 pivot与pivot_table
- 1.2 交叉表(crosstab)
- 2 其他变形方法
- 2.1 melt
- 2.2 压缩与展开(stack 和 unstack)
- 3 哑变量与因子化
- 3.1 Dummy Variable(哑变量)
- 3.2 factorize方法
- 4 问题与练习
- 4.1 问题
1 透视表
1.1 pivot与pivot_table
pivot函数可将某一列作为新的cols。但pivot函数具有很强的局限性,除了功能上较少之外,还不允许values中出现重复的行列索引对(pair)
# 将Gender的元素作为新的列,列值为Height的数值
df.pivot(index='ID',columns='Gender',values='Height')
# 下面程序会报错!!!因为school中含有重复的索引
df.pivot(index='School',columns='Gender',values='Height')
pivot_table函数的功能更多,但速度较慢。下面介绍常用参数:- aggfunc:对组内进行聚合统计,可传入各类函数,默认为’mean’;
- margins:为
True时汇总边际状态; - margins_name:边际状态名字,默认为
all - index行、columns列、values值都可以是多级,此时参数为列表形式;
pd.pivot_table(df,index='ID',columns='Gender',values='Height')
# aggfunc举例
pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum'])
# margins举例
pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum'],margins=True, margins_name='边际')
# 行、列、值为多级 举例
pd.pivot_table(df,index=['School','Class'],
columns=['Gender','Address'],
values=['Height','Weight'])
1.2 交叉表(crosstab)
交叉表是一种特殊的透视表,典型的用途如分组统计。交叉表不支持多级分组
# 统计关于 街道 和 性别 分组的频数
pd.crosstab(index=df['Address'],columns=df['Gender'])
重要参数:
- values和aggfunc:分组对某些数据进行聚合操作,这两个参数必须成对出现;
- 除了边际参数
margins外,还引入了normalize参数,可选'all','index','columns'参数值。
2 其他变形方法
2.1 melt
melt函数可以认为是pivot函数的逆操作,将unstacked状态的数据,压缩成stacked,使“宽”的DataFrame变“窄”。
参数说明:
id_vars:需要保留的列;value_vars:需要stack的一组列
df_m = df[['ID','Gender','Math']]
df.pivot(index='ID',columns='Gender',values='Math')
pivoted = df.pivot(index='ID',columns='Gender',values='Math')
result = pivoted.reset_index().melt(id_vars=['ID'],value_vars=['F','M'],value_name='Math').dropna().set_index('ID').sort_index()

2.2 压缩与展开(stack 和 unstack)
(1)stack
- 这是最基础的变形函数,总共只有两个参数:level和dropna
- stack函数可以看做将横向的索引放到纵向,因此功能类似与melt,参数level可指定变化的列索引是哪一层(或哪几层,需要列表)
df_s = pd.pivot_table(df,index=['Class','ID'],columns='Gender',values=['Height','Weight'])
df_s.groupby('Class').head(2)
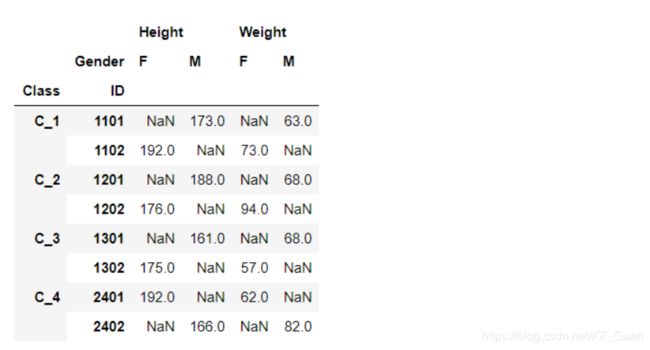
df_stacked = df_s.stack()
df_stacked.groupby('Class').head(2)
df_stacked = df_s.stack(0)
df_stacked.groupby('Class').head(2)
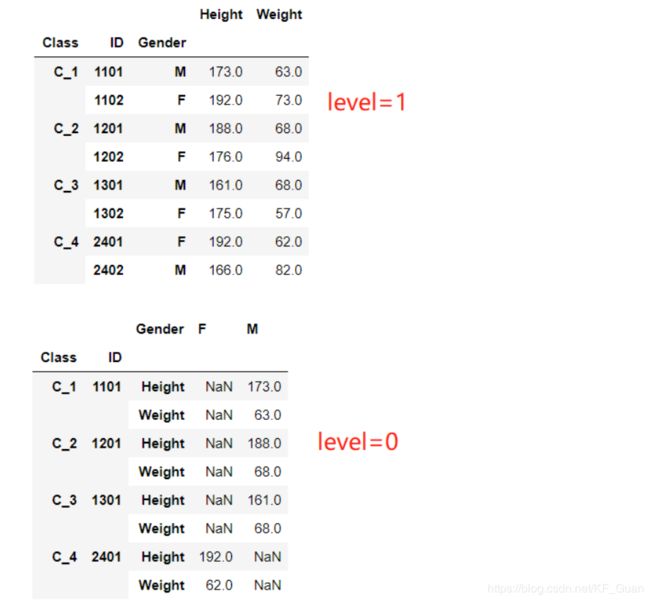
(2)unstack
- stack的逆函数,功能上类似于pivot_table
3 哑变量与因子化
3.1 Dummy Variable(哑变量)
get_dummies函数,其功能主要是进行one-hot编码;
df_d = df[['Class','Gender','Weight']]
pd.get_dummies(df_d[['Class','Gender']]).join(df_d['Weight'])

3.2 factorize方法
- 主要用于自然数编码,并且缺失值会被记做-1,其中sort参数表示是否排序后赋值
codes, uniques = pd.factorize(['b', None, 'a', 'c', 'b'], sort=True)
display(codes)
display(uniques)

4 问题与练习
4.1 问题
(1)上面提到了许多变形函数,如melt/crosstab/pivot/pivot_table/stack/unstack函数,请总结它们各自的使用特点。
- melt:压缩DataFrame,合并某些数据;
- crosstab:分组统计;
- pivot:展开DataFrame,拆开某些项作为新列;
- pivot_table:基本功能同pivot,但功能更丰富;
- stack:展开数据;
- unstack:合并数据。
(2)变形函数和多级索引是什么关系?哪些变形函数会使得索引维数变化?具体如何变化?
- 变形函数有些类似多级索引的形式,都是将某个大项中相同的值提出,然后作为新的索引。变形函数一般在列索引上操作,多级索引可以是行多级索引,也可以是列多级索引。(不知道这样理解对不对,请有知道的读者评论区指正。多多指教.jpg)
- pivot和pivot_table:使列索引维数变化,增加的维数为colums参数的类别数减一。
- melt:除了列数减少,行数增加为stack前各值的穷举,用NAN填充。
(3)请举出一个除了上文提过的关于哑变量方法的例子。
(4)使用完stack后立即使用unstack一定能保证变化结果与原始表完全一致吗?
- 不一定。
(5)透视表中涉及了三个函数,请分别使用它们完成相同的目标(任务自定)并比较哪个速度最快。
(6)既然melt起到了stack的功能,为什么再设计stack函数?
- stack()只有level和dropna两个参数,只能进行简单的stack功能;而melt则提供了id_vars、value_vars和value_name来将一些index旋转到columns,功能上更加灵活和高级。
如什么问题,欢迎留言交流,觉得有用的小伙伴顺手点个赞吧。
你的肯定是我创作的最大动力!