Mysql优化大分页查询
如题,年前做了一个需求,涉及到Mysql大分页查询,整理一下,希望对需要的小伙伴有帮助。
文章目录
- 背景
- 分页查询的性能瓶颈
- B+树简述
- B+比起二叉查找树,有什么优势?
- 分页查询过程
- 测试集
- 解决方法
- 1 延迟关联法:
- 2 主键阈值法
- 最后
背景
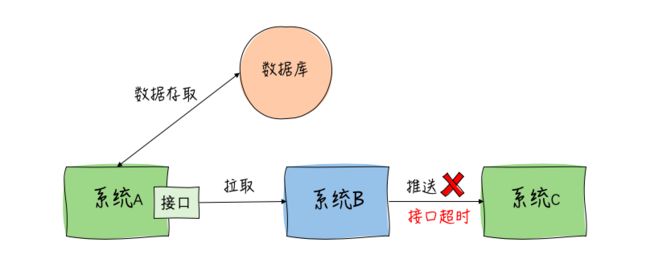
系统结构如上图。经过排查是因为系统B拉取数据时间太长导致的推送超时。
系统B拉取数据的方法是根据_tiemstamp(数据操作时间)分页查询系统A的接口,即:
SELECT 字段名
FROM 表名
WHERE _timestamp >= beginTime AND _timestamp <= endTime
LIMIT n, m;
由于该数据是从其他数据源中导入的,所以_timestamp这个字段值几乎相同,这就导致了在我们的查询范围内存在大约150万的数据。一般遇到这种情况,首先想到的就是是否需要给_timestamp添加索引,这张表上是存在_timestamp索引的。那么为什么还会出现这个问题呢?这就要从分页查询本身说起了。
分页查询的性能瓶颈
B+树简述
首先我们要了解InnoDB存储引擎中的B+数索引。这里我简单总结一下:
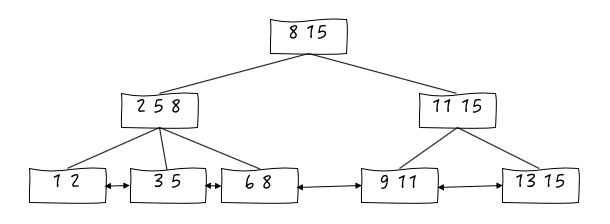
上图是一颗B+树,通过观察我们可以发现它的一些特点:
1.每个节点中子节点个个数不能少于m/2个,不能大于m个(B+树是一颗m叉树,图中m=3)
2.根节点的节点个数可以超过m/2个,这是一个例外
上述两点特性是为了保证B+树的查询效率。
节点数超过m越多,在总节点数相同的情况下,树的高度h就越小,此时m叉数就会向链表退化(O(logn)->O(n))。
节点数小于m/2越多,在总节点数相同的情况下,树的高度h就越高,此时查询数据,就需要经历更多次的IO
3.m叉树非叶子节点只存储索引,不存储数据
4.通过链表将叶子节点串联在一起,这样可以方便按区间查找。
B+比起二叉查找树,有什么优势?
更矮,这就减少了IO次数。
由于非叶子节点不存储数据,上图查询任何数据,都需要3次IO,查询性能更稳定
由于叶子节点使用了链表连接,范围查询更简便。
分页查询过程
1.首先通过非主键索引查询出所有条件的主键
2.通过主键索引,定位到数据
3.不断重复上述操作
4.根据分页条件,确定返回数据的启始位置以及数据量
5.返回数据
可以看出,初始位置值越大,定位时需要查询的数据就越多,查询效率也会越低
测试集
为了测试优化效果,我准备了150万测试数据(需要跑几分钟)。
# 建表语句
CREATE TABLE `test`(
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(512) NOT NULL DEFAULT '无' COMMENT '创建人',
`_timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `ix_timestamp` (`_timestamp`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';
# 建表语句
CREATE TABLE `test`(
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(512) NOT NULL DEFAULT '无' COMMENT '创建人',
`_timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `ix_timestamp` (`_timestamp`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';
# 通过存储过程导入数据
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1500000)do
insert into test values(i, i, now());
set i=i+1;
end while;
end;;
delimiter ;
call idata();
接着,我们看一下使用索引的情况下,分页查询语句的耗时情况。
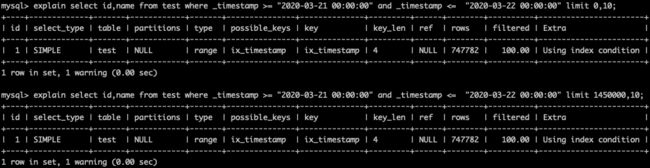
可以看出,在使用索引的情况下,无论初始位置是0,还是145万,Mysql都会扫描所有符合条件的数据,然后找到初始位置的数据,向后查偏移量个数据,最后返回。
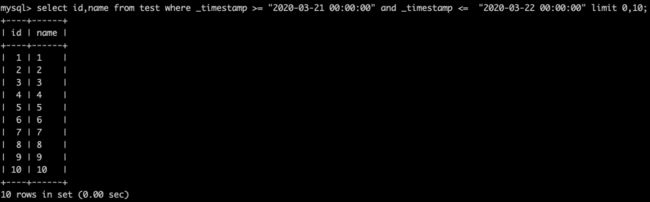
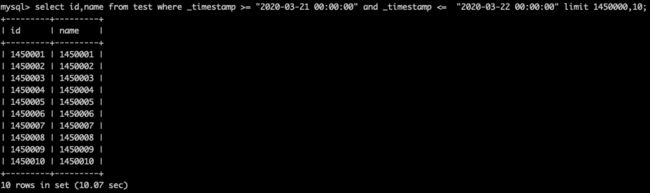
这两条语句的执行速度差距非常大,大约3个数量级(0.00sec,10 sec)
解决方法
针对于limit,有很多优化的方法,比如前端加缓存、或者使用分页加载的方式展示数据。(大部分用户请求数据的初始开始都不会很大)。在我们的使用场景中,调大超时时间的阈值也是可以的。
但是回到问题本身,问题出现的原因就是分页语句随着初始位置的增加,会有性能问题,所以治本的办法,是对这个语句进行优化,有两个优化方法:
1 延迟关联法:
我们先查询出符合要求的主键(由于查询的字段有索引,该索引的叶子节点就是主键,通过索引覆盖我们可以省去一次回表操作。)
然后再通过主键索引查询数据,这就省去了遍历数据找初始位置数据的过程
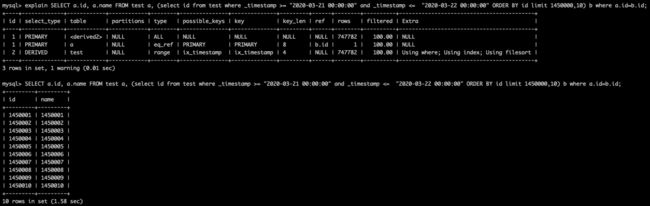
通过延迟关联的方法,我们将10sec的耗时降低到了1.58sec,优化了将近1个数量级。
2 主键阈值法
如果你的主键是自增的,那么就可以通过条件推算出符合条件的主键最大值&最小值(这里也是通过索引覆盖省去了一次回表操作)
然后再根据阈值,取数据即可,同样省去了遍历数据找初始位置数据的过程
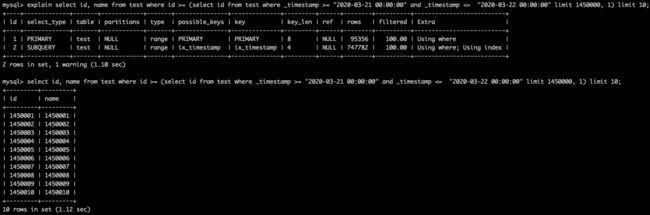
通过主键阈值法的方法,我们将10sec的耗时降低到了1.12sec,优化了1个数量级
最后
最后对文章做一下补充说明:
1.文中优化效果是仅凭借调用一次SQL的耗时给出的,并不科学,仅仅是为了让大家有一个直观的概念。
2.无论是延迟关联法,还是主键阈值法。思想都是一样的,先把符合条件的主键找到,然后通过主键去定位符合条件的数据,这里优化了2个点:1.通过索引覆盖避免了回表;2.通过主键直接定位数据的方法,省去了在数据集中查询初始位置的过程
3.优化的效果随数据量增加而增强。万级别的数据优化效果可能并不明显。
最后,期待您的订阅和点赞,专栏每周都会更新,希望可以和您一起进步,同时也期待您的批评与指正!
