java并发
title: java并发
date: 2019-01-16 22:08:05
updated: 2020-03-06 22:48:33
categories: java
tags:
- java
此文档为java并发的学习总结
java并发总结图

day1
并发模拟–工具
postman–http请求模拟,也可以进行简单的并发测试
AB(apacheBench)–并发测试(只有命令行,没有图形界面)
jMeter–压力测试,并AB更强大,实际用的更多(有图形界面)
并发模拟–代码
CountDownLatch–阻塞线程并保证线程在某种特定条件下继续执行
Semaphore–阻塞线程并控制同一时间的并发量
CountDownLatch+Semaphore通常与线程池一起使用
package com.mmall.concurrency;
import com.mmall.concurrency.annoations.NotThreadSafe;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
@Slf4j
@NotThreadSafe
public class ConcurrencyTest {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
public static int count = 0;
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool(); //线程池
final Semaphore semaphore = new Semaphore(threadTotal); //阻塞线程并控制同一时间的并发量
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);//阻塞线程并保证线程在某种特定条件下继续执行
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}", count);
}
private static void add() {
count++;
}
}
线程安全性的原子性
线程安全性的几种原子性–对比:
1.Atomic: 竞争激烈时能维持常态,比Lock性能好; 只能同步一个值
2.synchronized: 不可中断锁,适合竞争不激烈,可读性好
3.Lock: 可中断锁,多样化同步,竞争激烈时维持常态
1.原子性–Atomic包实现线程安全
java中的atomic包实现原子性,atomic包内部是通过CAS来实现原子性的。CAS:CompareAndSwap
1.AtomicXXX: CAS、Unsafe.compareAndSwapInt
2.AtomicLong与LongAdder
有了AtomicInteger,进一步有了AtomicLong,再进一步有了LongAdder,需要LongAdder的原因如下:
CAS底层实现是一个死循环,直到主存和工作内存数据相同才修改,否则一直循环,这个在有时候可能修改失败的概率很大,影响性能,那么LongAdder的优点就是利用AtomicLong,JVM会把int拆分成多个cell,最后合并cell即可,将单点的atomic压力分散成多个cell的压力。
3.AtomicReference、AtomicIntegerFieldUpdater
AtomicReference中的compareAndSet()方法参数分别代表:expectedValue、updateValue,如果是expectedValue则更新为updateValue
AtomicIntegerFieldUpdater中的字段必须使用volatile
4.AtomicStampedReference:解决CAS的ABA问题
CAS的ABA问题:其他线程将A改为B又改回A,当前线程读A没有影响,但是这不符合设计要求了,因此我们将每个线程的修改操作都附一个版本号Stamp,此A非彼A,这样解决了ABA问题
2.原子性–锁实现线程安全
JDK中锁的实现有两种方法:
1.synchronized: 依赖JVM
2.Lock: 依赖特殊的cpu指令,代码层面实现,J.U.C的AQS组件中的ReentrantLock
synchronized实现线程安全(着重介绍)
四种synchronized的修饰用法及作用范围,一定注意其作用范围
1.修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2.修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3.修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4.修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象
示例:
// 修饰一个代码块
public void test1(int j) {
synchronized (this) {
for (int i = 0; i < 10; i++) {
log.info("test1 {} - {}", j, i);
}
}
}
// 修饰一个方法
public synchronized void test2(int j) {
for (int i = 0; i < 10; i++) {
log.info("test2 {} - {}", j, i);
}
}
// 修饰一个类
public static void test1(int j) {
synchronized (SynchronizedExample2.class) {
for (int i = 0; i < 10; i++) {
log.info("test1 {} - {}", j, i);
}
}
}
// 修饰一个静态方法
public static synchronized void test2(int j) {
for (int i = 0; i < 10; i++) {
log.info("test2 {} - {}", j, i);
}
}
//测试
public static void main(String[] args) {
SynchronizedExample1 example1 = new SynchronizedExample1();
SynchronizedExample1 example2 = new SynchronizedExample1();
ExecutorService executorService = Executors.newCachedThreadPool();//线程池
executorService.execute(() -> {
example1.test2(1);
});
executorService.execute(() -> {
example2.test2(2);
});
}
使用synchronized保证线程安全的实例:
package com.mmall.concurrency.example.count;
import com.mmall.concurrency.annoations.ThreadSafe;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
@Slf4j
@ThreadSafe
public class CountExample3 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
public static int count = 0;
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}", count);
}
//这里加了synchronized就线程安全了,使用简单容易
private synchronized static void add() {
count++;
}
}
线程安全性的可见性
什么是线程间的可见性?
一个线程对共享变量值的修改,能够及时的被其他线程看到。
什么是共享变量?
如果一个变量在多个线程的工作内存中都存在副本,那么这个变量就是这几个线程的共享变量。
导致共享变量在线程间不可见的原因:
1.线程的交叉执行
2.重排序结合线程交叉执行
3.共享变量更新后的值没有在工作内存与主内存间及时更新
java语言层面支持的可见性实现方式有两种:
1.synchronized
2.volatile
1.synchronized的可见性:
JMM关于synchronized的两条规定: 这样简单使用synchronized就可以实现线程安全了
1.线程解锁前(退出synchronized代码块之前),必须把共享变量的最新值刷新到主内存中,也就是说线程退出synchronized代码块值后,主内存中保存的共享变量的值已经是最新的了
2.线程加锁时(进入synchronized代码块之后),将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值(注意:加锁与解锁需要是同一把锁)
两者结合:线程解锁前对共享变量的修改在下次加锁时对其他线程可见
2.volatile的可见性:
volatile能够保证volatile变量的可见性。
volatile如何实现内存可见性?
深入来说:通过加入内存屏障和禁止重排序优化来实现的。具体如下:
1.对volatile变量执行写操作时,会在写操作后加入一条store屏障指令
2.对volatile变量执行读操作时,会在读操作前加入一条load屏障指令
通俗的讲:volatile变量在每次被线程访问时,都强迫从主内存中重读该变量的值,而当该变量发生变化时,又会强迫线程将最新的值刷新到主内存。这样任何时刻,不同的线程总能看到该变量的最新值。
线程写volatile变量的过程:
1.改变线程工作内存中volatile变量副本的值
2.将改变后的副本的值从工作内存刷新到主内存
线程读volatile变量的过程:
1.从主内存中读取volatile变量的最新值到线程的工作内存中
2.从工作内存中读取volatile变量的副本
注意:volatile保证可见性,但是不保证原子性,实例如下(线程不安全)
public class CountExample4 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
//加了volatile但是还是线程不安全
public static volatile int count = 0;
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}", count);
}
private static void add() {
count++;
// 1、可见性:count读是最新的
// 2、+1 但是这里两个线程都对count=5进行+1,再写,原子性不保证了
// 3、可见性:count写是最新的
}
}
synchronized和volatile的比较
1.volatile不需要加锁,比synchronized更轻量级,不会阻塞线程
2.从内存可见性角度讲,volatile读操作=进入synchronized代码块(加锁),volatile写操作=退出synchronized代码块(解锁)
3.synchronized既能保证可见性,又能保证原子性,而volatile只能保证可见性,不能保证原子性
线程安全性的有序性
有序性是指程序在执行的时候,程序的代码执行顺序和语句的顺序是一致的。
为什么会出现不一致的情况呢?
这是由于重排序的缘故。在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
解决方法:happens-before原则
发布对象
有时,我们会发现线程可以通过public方法获取的成员变量的引用进行修改,这样发布对象的话就是线程不安全的,如下:
public class UnsafePublish {
private String[] states = {"a", "b", "c"};
public String[] getStates() {
return states;
}
public static void main(String[] args) {
UnsafePublish unsafePublish = new UnsafePublish();
log.info("{}", Arrays.toString(unsafePublish.getStates()));//out:[a,b,c]
//我们会发现线程可以通过public方法获取的成员变量的引用进行修改,这是不安全的
unsafePublish.getStates()[0] = "d";
log.info("{}", Arrays.toString(unsafePublish.getStates()));//out:[d,b,c]
}
}
单例模式(四种常用方法)
1.饿汉式
/**
* 饿汉模式
* 单例实例在类装载时进行创建
*/
@ThreadSafe
public class SingletonExample2 {
// 私有构造函数
private SingletonExample2() {
}
// 单例对象
private static SingletonExample2 instance = new SingletonExample2();
// 静态的工厂方法
public static SingletonExample2 getInstance() {
return instance;
}
}
2.懒汉式(double-check)
但是注意:double-check还是线程不安全(指令重排序的问题)–解决:volatile或者枚举
/**
* 懒汉模式 -> double-check单例模式
* 单例实例在第一次使用时进行创建
*/
@NotThreadSafe
public class SingletonExample4 {
// 私有构造函数
private SingletonExample4() {
}
// 1、memory = allocate() 分配对象的内存空间
// 2、ctorInstance() 初始化对象
// 3、instance = memory 设置instance指向刚分配的内存
// JVM和cpu优化,发生了指令重排,因此不是线程安全
// 1、memory = allocate() 分配对象的内存空间
// 3、instance = memory 设置instance指向刚分配的内存
// 2、ctorInstance() 初始化对象
// 单例对象
private static SingletonExample4 instance = null;
// 静态的工厂方法
public static SingletonExample4 getInstance() {
if (instance == null) { // 双重检测机制 // B
synchronized (SingletonExample4.class) { // 同步锁
if (instance == null) {
instance = new SingletonExample4(); // A - 3
}
}
}
return instance;
}
}
3.枚举模式(最线程安全):
/**
* 枚举模式:最安全
*/
@ThreadSafe
@Recommend 推荐使用
public class SingletonExample7 {
// 私有构造函数
private SingletonExample7() {
}
public static SingletonExample7 getInstance() {
return Singleton.INSTANCE.getInstance();
}
private enum Singleton {
INSTANCE;
private SingletonExample7 singleton;
// JVM保证这个方法绝对只调用一次
Singleton() {//在枚举的构造方法中创建对象
singleton = new SingletonExample7();
}
public SingletonExample7 getInstance() {
return singleton;
}
}
}
对象逸出
双重检测机制不能保证线程安全–原因:指令重排–解决:volatile
Day2
线程安全策略–不可变对象
1.final关键字实现不可变对象:
final修饰类:不能被继承
final修饰方法:锁定方法不被继承类修改
final修饰变量:基本数据类型变量(不可修改),引用类型变量(不能再指向新对象)
public class ImmutableExample1 {
private final static Integer a = 1;
private final static String b = "2";
private final static Map<Integer, Integer> map = Maps.newHashMap();
static {
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
}
public static void main(String[] args) {
// a = 2; //值不可变
// b = "3";
// map = Maps.newHashMap();//引用类型不能指向别的对象
map.put(1, 3); //但是可以对引用的对象进行修改
log.info("{}", map.get(1));
}
private void test(final int a) {
// a = 1;//类型是final,也是不能修改
}
}
2.工具包实现不可变对象:
这两个工具:连引用的对象都不能被修改了,比final更牛逼
1.Collections.unmodifiableXXX
2.guava.immutable
Collections.unmodifiableXXX
public class ImmutableExample2 {
private static Map<Integer, Integer> map = Maps.newHashMap();
static {
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
map = Collections.unmodifiableMap(map);//这样map引用的对象都不能被修改
}
public static void main(String[] args) {
map.put(1, 3);//不能修改了,抛出异常
log.info("{}", map.get(1));//2
}
}
guava.immutableXXX
public class ImmutableExample3 {
private final static ImmutableList<Integer> list = ImmutableList.of(1, 2, 3);
private final static ImmutableSet set = ImmutableSet.copyOf(list);
private final static ImmutableMap<Integer, Integer> map = ImmutableMap.of(1, 2, 3, 4);
private final static ImmutableMap<Integer, Integer> map2 = ImmutableMap.<Integer, Integer>builder()
.put(1, 2).put(3, 4).put(5, 6).build();
public static void main(String[] args) {
// list.add(1);//抛出异常,不能被修改
// map.put(1,3);//抛出异常,不能被修改
// map2.put(1,3);//抛出异常,不能被修改
System.out.println(map2.get(3));//out: 4 取值没问题,可以取
}
}
线程安全策略–线程封闭
实现好的并发是一件困难的事情,所以很多时候我们都想躲避并发。避免并发最简单的方法就是线程封闭。什么是线程封闭呢?
线程封闭就是把对象封装到一个线程里,只有这一个线程能看到此对象。那么这个对象就算不是线程安全的也不会出现任何安全问题。实现线程封闭有哪些方法呢?
1:ad-hoc线程封闭: 程序控制实现,最糟糕,忽略
2:栈封闭: 局部变量,无并发问题
**栈封闭是我们编程当中遇到的最多的线程封闭。**什么是栈封闭呢?简单的说就是局部变量。多个线程访问一个方法,此方法中的局部变量都会被拷贝一分儿到线程栈中。所以局部变量是不被多个线程所共享的,也就不会出现并发问题。所以能用局部变量就别用全局的变量,全局变量容易引起并发问题。
3.ThreadLocal封闭
使用ThreadLocal是实现线程封闭的最好方法。**ThreadLocal内部维护了一个Map,Map的key是每个线程的名称,而Map的值就是我们要封闭的对象。**每个线程中的对象都对应着Map中一个值,也就是ThreadLocal利用Map实现了对象的线程封闭。
线程安全策略–非线程安全的类与方法
1.StringBuilder不安全 --> 解决:StringBuffer安全(底层用了synchronized)
2.simpleDateFormat不安全 --> 解决1:将simpleDateFormat变量弄成局部变量,在线程中创建,栈封闭,安全; 解决2:第三方包JodaTime.DateTimeFormat
3.Collection(ArrayList/HashSet/HashMap等)都不安全—> 解决:同步容器,下面着重介绍
4.先检查再执行:if(condition(a)){handle(a);}可能不安全 --> 解决:加锁/atomic CAS算法等方法
线程安全–同步容器
同步容器:用来解决Collections(ArrayList/HashSet/HashMap等)线程不安全的问题
1.ArrayList不安全 --> Vector, Stack
2.HashMap不安全 --> HashTable(key, value不能为null)
3.Collections.synchronizedXXX(List,Set,Map)
Vector在某些情况下还是线程不安全。
Vector线程安全例子:
public class VectorExample1 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
private static List<Integer> list = new Vector<>();//在本例中线程安全
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", list.size());
}
private static void update(int i) {
list.add(i);
}
}
Vector线程不安全的例子:运行就报错,out of index
public class VectorExample2 {
private static Vector<Integer> vector = new Vector<>();
public static void main(String[] args) {
while (true) {
for (int i = 0; i < 10; i++) {
vector.add(i);
}
Thread thread1 = new Thread() {
public void run() {
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);//多个线程可能remove多了
}
}
};
Thread thread2 = new Thread() {
public void run() {
for (int i = 0; i < vector.size(); i++) {
vector.get(i);
}
}
};
thread1.start();
thread2.start();
}
}
}
Collections.synchronizedXXX(List,Set,Map)线程安全的,举个例子:
private static Map map = Collections.synchronizedMap(new HashMap<>());
demo:
public class CollectionsExample1 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
private static List<Integer> list = Collections.synchronizedList(Lists.newArrayList());
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", list.size());
}
private static void update(int i){
list.add(i);
}
}
fail-fast机制
在遍历集合时尽量不要在遍历同时进行remove等修改操作(原因:fail-fast机制),
fail-fast机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变
解决方法:若在多线程环境下使用fail-fast机制的集合,建议使用“java.util.concurrent包下的类”去取代“java.util包下的类”; 或者先记下来,遍历完再remove等操作。
例子如下:
public class VectorExample3 {
// java.util.ConcurrentModificationException
private static void test1(Vector<Integer> v1) { // foreach
for(Integer i : v1) {
if (i.equals(3)) {
v1.remove(i);
}
}
}
// java.util.ConcurrentModificationException
private static void test2(Vector<Integer> v1) { // iterator
Iterator<Integer> iterator = v1.iterator();
while (iterator.hasNext()) {
Integer i = iterator.next();
if (i.equals(3)) {
v1.remove(i);
}
}
}
// success
private static void test3(Vector<Integer> v1) { // for
for (int i = 0; i < v1.size(); i++) {
if (v1.get(i).equals(3)) {
v1.remove(i);
}
}
}
public static void main(String[] args) {
Vector<Integer> vector = new Vector<>();
vector.add(1);
vector.add(2);
vector.add(3);
// test1(vector);//异常
// test2(vector);//异常
test3(vector);
}
}
线程安全–并发容器J.U.C
J.U.C–java.util.concurrent
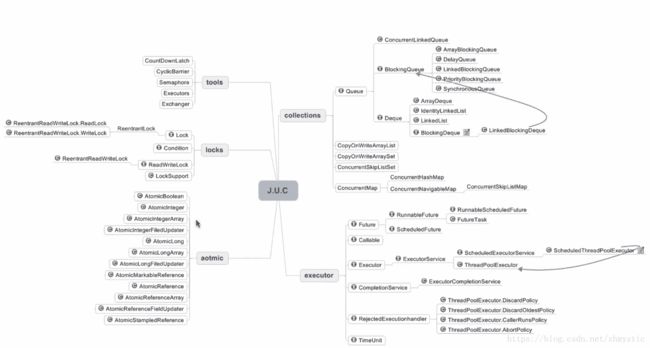
图中没有AQS,AbstractQueuedSynchronizer(AQS)是锁机制实现的核心所在。是这五大部分很多东西实现的前提。
ArrayList --> CopyOnWriteArrayList线程安全(读操作不加锁,写操作底层是锁;且先copy另外开辟空间,这样就线程安全了)
private static List list = new CopyOnWriteArrayList<>();`
HashSet --> CopyOnWriteArraySet
TreeSet --> ConcurrentSkipListSet
3.(重点,面试经常考):
HashMap --> ConcurrentHashMap
TreeMap--> ConcurrentSkipListMap
由于ConcurrentHashMap、ConcurrentSkipListMap经过优化后具有很高的并发性,因此面试中常考
一、Hashmap
1.Hashmap的数据结构:
HashMap的底层就是一个数组结构,而数组中的每一项又是一个链表结构;
当我们新建一个HashMap的时候,就会初始化一个数组出来。
HashMap有两个参数影响它的性能,一个是初始容量(默认是16),一个是加载因子(默认是0.75)。
容量是哈希表中桶的数量。初始容量只是哈希表在创建时的容量;
加载因子是哈希表在容量自动增加之前,可以达到多满的一个尺度。如果达到了加载因子的值 ,那么会调用resize方法进行扩容。将容量进行翻倍。
这两个值在初始化时构造函数是可以自定义的。
2.Hashmap的寻址方式:
对于一个新插入的数据,或者我们需要读取的数据。Hashmap会对它的key按照一定的计算规则计算出的哈希值并对数组长度进行取模。结果作为它数组中的index。但是在计算机中取模的代价比较大,所以Hashmap要求数组的长度必须为2的N次方,此时呢它将key的哈希值对2的N-1次方进行与运算,结果与取模相同的。
Hashmap并不要求用户在初始化的时候指定容量必须传入的N次方的整数,而是在初始化时根据传入的参数计算出一个满足的容量值。源码中的tableSizeFor方法即可看到。
总所周知,Hashmap的线程不安全,其实主要体现在刚才的resize方法可能会出现死循环(出现循环链表),以及使用迭代器会出现FastFail。
当Hashmap得size超过容量乘加载因子的时候,就会进行扩容。就是创建了一个新的长度为原容量2倍的数组。并将原数组全部重新插入到现数组中,这个方法我们成为rehash。这个方法不保证线程安全,并且在多线程环境下可能会出现死循环。
二.HashMap–>ConcurrentHashMap(key\value不允许空值)
1.ConcurrentHashMap的数据结构:
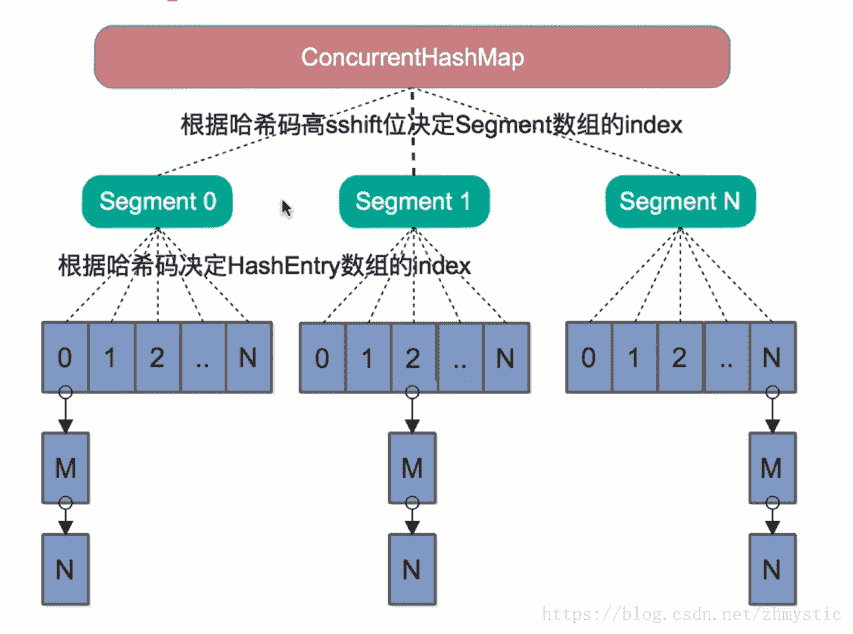
也是数组+链表结构,但是最外层不像HashMap直接是个大的数组,而是Segment数组,每个Segment里面是跟HashMap结构差不多的链表数组
Java7之前是分段锁。Java8之后在链表长度超过一定长度之后(默认是8),链表转化为了红黑树,提高并发性
三.ConcurrentSkipListMap
ConcurrentSkipListMap的效率一般没有ConcurrentHashMap高,但是也有优点。
1.可以保证有序性
2.并发数越大,越能体现优势
一个demo,线程安全:
public class ConcurrentSkipListMapExample {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
private static Map<Integer, Integer> map = new ConcurrentSkipListMap<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", map.size());
}
private static void update(int i) {
map.put(i, i);
}
}
线程安全–并发容器J.U.C之AQS
详看:Java并发包基石-AQS详解
慕课网实战·高并发探索(十一):并发容器J.U.C – AQS组件CountDownLatch、Semaphore、CyclicBarrier
AQS: AbstractQueuedSynchronizer,它是一个Java提高的底层同步工具类。AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列("CLH"队列)来完成获取资源线程的排队工作。用一个int类型的变量表示同步状态,并提供了一系列的CAS操作来管理这个同步状态。AQS的主要作用是为Java中的并发同步组件提供统一的底层支持,例如ReentrantLock,CountdowLatch就是基于AQS实现的,用法是通过继承AQS实现其模版方法,然后将子类作为同步组件的内部类。
AQS设计思想:
1.使用Node实现FIFO队列,可以用于构建锁或者其他同步装置的基础框架。
利用int类型标识状态。在AQS类中有一个叫做state的成员变量
/**
* The synchronization state.
*/
private volatile int state;
2.基于AQS有一个同步组件,叫做ReentrantLock。在这个组件里,stste表示获取锁的线程数,假如state=0,表示还没有线程获取锁,1表示有线程获取了锁。大于1表示重入锁的数量。
3.继承:子类通过继承并通过实现它的方法管理其状态(acquire和release方法操纵状态)。
4.可以同时实现排它锁和共享锁模式(独占、共享),站在一个使用者的角度,AQS的功能主要分为两类:独占和共享。它的所有子类中,要么实现并使用了它的独占功能的api,要么使用了共享锁的功能,而不会同时使用两套api,即便是最有名的子类ReentrantReadWriteLock也是通过两个内部类读锁和写锁分别实现了两套api来实现的。
AQS主要组件:
CountdowLatch 通过计数来保证线程是否需要阻塞
Semaphore 表现剩余的许可数
ReentrantLock 表现拥有它的线程已经请求了多少次锁
AQS支持两种同步方式:
- 独占式
- 共享式
AQS组件之CountdowLatch
通过一个计数来保证线程是否需要被阻塞。实现一个或多个线程等待其他线程执行的场景。
我们定义一个CountDownLatch,通过给定的计数器为其初始化,该计数器是原子性操作,保证同时只有一个线程去操作该计数器。调用该类await方法的线程会一直处于阻塞状态。只有其他线程调用countDown方法(每次使计数器-1),使计数器归零才能继续执行。
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
test(threadNum); //需要被等待的线程执行的方法
} catch (Exception e) {
log.error("exception", e);
} finally {
countDownLatch.countDown();
}
});
}
countDownLatch.await();
log.info("finish");//必须在countDownLatch减为0后才会执行await()后面的代码
exec.shutdown();
可以看到,线程池必须在countDownLatch减为0后才会执行await()后面的代码
AQS组件之Semaphore
用于保证同一时间并发访问线程的数目。
信号量在操作系统中是很重要的概念,Java并发库里的Semaphore就可以很轻松的完成类似操作系统信号量的控制。Semaphore可以很容易控制系统中某个资源被同时访问的线程个数。
在数据结构中我们学过链表,链表正常是可以保存无限个节点的,而Semaphore可以实现有限大小的列表。
使用场景:仅能提供有限访问的资源。比如数据库连接。
Semaphore使用acquire方法和release方法来实现控制:
代码:
public class SemaphoreExample1 {
private final static int threadCount = 20;
public static void main(String[] args) throws Exception {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(3);//一个线程可访问的许可总数
for (int i = 0; i < threadCount; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
semaphore.acquire(); // 获取一个许可
test(threadNum);
semaphore.release(); // 释放一个许可
} catch (Exception e) {
log.error("exception", e);
}
});
}
exec.shutdown();
}
private static void test(int threadNum) throws Exception {
log.info("{}", threadNum);
Thread.sleep(1000);
}
}
AQS组件之CyclicBarrier
也是一个同步辅助类,它允许一组线程相互等待,直到到达某个公共的屏障点(循环屏障)才一起执行
通过它可以完成多个线程之间相互等待,只有每个线程都准备就绪后才能继续往下执行后面的操作。
每当有一个线程执行了await方法,计数器就会执行+1操作,待计数器达到预定的值,所有的线程再同时继续执行。由于计数器释放之后可以重用(reset方法),所以称之为循环屏障。
CyclicBarrier与CountDownLatch区别:
- 1、CyclicBarrier计数器可重复用
- 2、CyclicBarrier描述一个或多个线程等待其他线程的关系/多个线程相互等待
代码:
public class CyclicBarrierExample1 {
private static CyclicBarrier barrier = new CyclicBarrier(5);
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int threadNum = i;
Thread.sleep(1000);
executor.execute(() -> {
try {
race(threadNum);
} catch (Exception e) {
log.error("exception", e);
}
});
}
executor.shutdown();
}
private static void race(int threadNum) throws Exception {
Thread.sleep(1000);
log.info("{} is ready", threadNum);
barrier.await();//等待多个线程准备好一起执行
log.info("{} continue", threadNum);
}
}
out:
0 is ready
1 is ready
2 is ready
3 is ready
4 is ready
0 continue
1 continue
2 continue
3 continue
4 continue
5 is ready...
AQS组件之ReentrantLock
ReentrantLock
java中有两类锁,一类是Synchronized,而另一类就是J.U.C中提供的锁。ReentrantLock与Synchronized都是可重入锁,本质上都是lock与unlock的操作。接下来我们介绍三种J.U.C中的锁,其中 ReentrantLock使用synchronized与之比对介绍。
ReentrantLock与synchronized的区别
可重入性:两者的锁都是可重入的,差别不大,有线程进入锁,计数器自增1,等下降为0时才可以释放锁
锁的实现:synchronized是基于JVM实现的(用户很难见到,无法了解其实现),ReentrantLock是JDK实现的。
性能区别:在最初的时候,二者的性能差别差很多,当synchronized引入了偏向锁、轻量级锁(自选锁)后,二者的性能差别不大,官方推荐
synchronized(写法更容易、在优化时其实是借用了ReentrantLock的CAS技术,试图在用户态就把问题解决,避免进入内核态造成线程阻塞)
功能区别:
-
1.便利性:synchronized更便利,它是由编译器保证加锁与释放。ReentrantLock是需要手动释放锁,所以为了避免忘记手工释放锁造成死锁,所以最好在finally中声明释放锁。
-
2.锁的细粒度和灵活度,ReentrantLock优于synchronized
public class LockExample2 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
public static int count = 0;
private final static Lock lock = new ReentrantLock();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}", count);
}
private static void add() {
lock.lock();//上锁
try {
count++;
} finally {
lock.unlock();//解锁
}
}
}
还有个ReadWriteLock读写锁
Java不可重入锁和可重入锁理解
Java不可重入锁和可重入锁理解
所谓不可重入锁(自旋锁),即若当前线程执行某个方法已经获取了该锁,那么在方法中尝试再次获取锁时,就会获取不到被阻塞。
所谓可重入,意味着线程可以进入它已经拥有的锁的同步代码块儿。
java中的synchronized、ReentrantLock都是可重入锁
乐观锁与悲观锁
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制(如stampedLock)。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
Day.3
J.U.C之FutureTask
当想获取线程返回结果时,应该实现callable接口,而FutureTask就是超级方便的东西,使用它就行。。FutureTask 表现任务的状态(尚未开始、运行、完成和取消)
FutureTask是J.U.C中的类,是一个可删除的异步计算类。这个类提供了Future接口的的基本实现,使用相关方法启动和取消计算,查询计算是否完成,并检索计算结果。只有在计算完成时才能使用get方法检索结果;如果计算尚未完成,get方法将会阻塞。一旦计算完成,计算就不能重新启动或取消(除非使用runAndReset方法调用计算)。
Runnable与Callable对比
通常实现一个线程我们会使用继承Thread的方式或者实现Runnable接口,这两种方式有一个共同的缺陷就是在执行完任务之后无法获取执行结果。从Java1.5之后就提供了Callable与Future,这两个接口就可以实现获取任务执行结果。
Future接口提供了一系列方法用于控制线程执行计算
FutureTask
Future实现了RunnableFuture接口,而RunnableFuture接口继承了Runnable与Future接口,所以它既可以作为Runnable被线程中执行,又可以作为callable获得返回值。
FutureTask支持两种参数类型,Callable和Runnable,在使用Runnable 时,还可以多指定一个返回结果类型。
当使用future接口:
public class FutureExample {
static class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
}
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
Future<String> future = executorService.submit(new MyCallable());
log.info("do something in main");
Thread.sleep(1000);
String result = future.get();
log.info("result:{}", result);
}
}
out:
do something in callable
do something in main
result:Done
使用FutureTask更方便(out是一样的):
public class FutureTaskExample {
public static void main(String[] args) throws Exception {
FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
});
new Thread(futureTask).start();
log.info("do something in main");
Thread.sleep(1000);
String result = futureTask.get();
log.info("result:{}", result);
}
}
J.U.C之ForkJoin
ForkJoin是Java7提供的一个并行执行任务的框架,是把大任务分割成若干个小任务,待小任务完成后将结果汇总成大任务结果的框架。主要采用的是工作窃取算法,工作窃取算法是指某个线程从其他队列里窃取任务来执行。 这个思想和MapReduce算法类似

在窃取过程中两个线程会访问同一个队列,为了减少窃取任务线程和被窃取任务线程之间的竞争,通常我们会使用双端队列来实现工作窃取算法。被窃取任务的线程永远从队列的头部拿取任务,窃取任务的线程从队列尾部拿取任务。
一个1~100和的任务示例:
public class ForkJoinTaskExample extends RecursiveTask<Integer> {
public static final int threshold = 2;
private int start;
private int end;
public ForkJoinTaskExample(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= threshold;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle);
ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待任务执行结束合并其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkjoinPool = new ForkJoinPool();
//生成一个计算任务,计算1+2+3+4
ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100);
//执行一个任务
Future<Integer> result = forkjoinPool.submit(task);
try {
log.info("result:{}", result.get());
} catch (Exception e) {
log.error("exception", e);
}
}
}
J.U.C之BlockingQueue阻塞队列
阻塞情况:1、当队列满了进行入队操作; 2、当队列空了的时候进行出队列操作
BlockingQueue阻塞队列主要应用场景:生产者消费者模型,是线程安全的

想使用阻塞队列就使用它的实现类即可,如ArrayBlockingQueue、DelayQueue、DalayQueue、LinkedBlockingQueue、PriorityBlockingQueue、SynchronusQueue(这里不一一介绍了)
J.U.C之线程池(重点)
new Thread的弊端
1.每次new Thread 新建对象,性能差
2.线程缺乏统一管理,可能无限制的新建线程,相互竞争,可能占用过多的系统资源导致死机或者OOM(out of memory 内存溢出),这种问题的原因不是因为单纯的new一个Thread,而是可能因为程序的bug或者设计上的缺陷导致不断new Thread造成的。
3.缺少更多功能,如更多执行、定期执行、线程中断。
线程池的好处
1.重用存在的线程,不需要每次都创建,减少对象创建、消亡的开销,性能好
2.可有效控制最大并发线程数,提高系统资源利用率,同时可以避免过多资源竞争,避免阻塞。
3.提供定时执行、定期执行、单线程、并发数控制等功能。
线程池核心类-ThreadPoolExecutor
参数说明:ThreadPoolExecutor一共有七个参数,这七个参数配合起来,构成了线程池强大的功能。
corePoolSize:核心线程数量
maximumPoolSize:线程最大线程数
workQueue:阻塞队列,存储等待执行的任务,很重要,会对线程池运行过程产生重大影响
keepAliveTime:线程没有任务执行时最多保持多久时间终止(当线程中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交核心线程外的线程不会立即销毁,而是等待,直到超过keepAliveTime)
unit:keepAliveTime的时间单位
threadFactory:线程工厂,用来创建线程,有一个默认的工场来创建线程,这样新创建出来的线程有相同的优先级,是非守护线程、设置好了名称)
rejectHandler:当拒绝处理任务时(阻塞队列满)的策略(AbortPolicy默认策略直接抛出异常、CallerRunsPolicy用调用者所在的线程执行任务、DiscardOldestPolicy丢弃队列中最靠前的任务并执行当前任务、DiscardPolicy直接丢弃当前任务)
线程池生命周期

running:能接受新提交的任务,也能处理阻塞队列中的任务
shutdown:不能处理新的任务,但是能继续处理阻塞队列中任务
stop:不能接收新的任务,也不处理队列中的任务
tidying:如果所有的任务都已经终止了,这时有效线程数为0
terminated:最终状态
使用Executor创建线程池
使用Executor可以创建四种线程池:分别对应四种线程池初始化方法。
1、Executors.newCachedThreadPool
创建一个可缓存的线程池,如果线程池的长度超过了处理的需要,可以灵活回收空闲线程。如果没有可回收的就新建线程。
2、newFixedThreadPool
定长线程池,可以线程现成的最大并发数,超出在队列等待
3、newSingleThreadExecutor
单线程化的线程池,用唯一的一个共用线程执行任务,保证所有任务按指定顺序执行(FIFO、优先级…)
4、newScheduledThreadPool
定长线程池,支持定时和周期任务执行
public class ThreadPoolExample1 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
executorService.execute(new Runnable() {
@Override
public void run() {
log.info("task:{}", index);
}
});
}
executorService.shutdown();
}
}
多线程并发扩展–死锁
死锁产生的必要条件
互斥条件:进程对锁分配的资源进行排他性使用
请求和保持条件:线程已经保持了一个资源,但是又提出了其他请求,而该资源已被其他线程占用
不剥夺条件:在使用时不能被剥夺,只能自己用完释放
环路等待条件:资源调用是一个环形的链
死锁示例:
public class DeadLock implements Runnable {
public int flag = 1;
//静态对象是类的所有对象共享的
private static Object o1 = new Object(), o2 = new Object();
@Override
public void run() {
if (flag == 1) {
synchronized (o1) {
try {
log.info("flag:{}", flag);
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o2) {
log.info("1");
}
}
}
if (flag == 0) {
synchronized (o2) {
try {
log.info("flag:{}", flag);
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o1) {
log.info("0");
}
}
}
}
public static void main(String[] args) {
DeadLock td1 = new DeadLock();
DeadLock td2 = new DeadLock();
td1.flag = 1;
td2.flag = 0;
//td1,td2都处于可执行状态,但JVM线程调度先执行哪个线程是不确定的。
//td2的run()可能在td1的run()之前运行
new Thread(td1).start();
new Thread(td2).start();
}
}
out:
flag:0
flag:1....
多线程并发的最佳实践
1.使用本地变量
2.使用不可变类
3.使用线程池的Executor,而不是直接new Thread执行
4.宁可使用同步(countdownLatch/semaphore)也不要使用线程的wait/notify
5.使用blockingqueue实现生产-消费模式
6.使用并发集合(CopyonWriteArrayList/concurrentHashMap)而不是加了锁的同步集合(synchronizedXXX)
7.使用semaphore创建有界的访问
8.宁可使用同步代码块,也不使用同步的方法
9.避免使用静态变量(静态变量在并发情况下会出现很多问题,避免使用)
高并发之扩容思路
读操作扩展(如博客系统):memcached、redis、CDN缓存
写操作扩展(如订单系统):Cassandra、Hbase等
高并发之缓存思路
缓存分类
本地缓存:编程实现(成员变量、局部变量、静态变量)、Guava Cache
分布式缓存:Memcached、Redis(更常用)
缓存清空策略:FIFO、LFU、LRU、过期时间、随机
FIFO:先进先出,优先保证最新数据的有效性
LFU:最少使用策略,优先保证高频数据的有效性
LRU:最近使用策略,优先保证热点数据的有效性
关于Memcached\Redis请左转详看:吐血强推_Nosql简介 Redis,Memchche,MongoDb的区别
jRedis的demo
0.application.properties
# redis
jedis.host = 127.0.0.1
jedis.port = 6379
1.RedisConfig
public class RedisConfig {
@Bean(name = "redisPool")
public JedisPool jedisPool(@Value("${jedis.host}") String host,
@Value("${jedis.port}") int port) {
return new JedisPool(host, port);
}
}
2.RedisClient:指定jedisPool,自定义set和get方法,当然还可以写更多的方法功能
public class RedisClient {
@Resource(name = "redisPool")
private JedisPool jedisPool;
public void set(String key, String value) throws Exception {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set(key, value);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
public String get(String key) throws Exception {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
return jedis.get(key);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
3.CacheController:调用redis
@Controller
@RequestMapping("/cache")
public class CacheController {
@Autowired
private RedisClient redisClient;
@RequestMapping("/set")
@ResponseBody
public String set(@RequestParam("k") String k, @RequestParam("v") String v)
throws Exception {
redisClient.set(k, v);
return "SUCCESS";
}
@RequestMapping("/get")
@ResponseBody
public String get(@RequestParam("k") String k) throws Exception {
return redisClient.get(k);
}
}
4.启动项目 + 启动redis-server,在postman中输入请求:
http://localhost:8080/cache/set?k=test1&v=1 – success
http://localhost:8080/cache/get?k=test1 – 1
面试常考的一致性Hash算法
面试必备:什么是一致性Hash算法?

一个hash环,顺时针找
高并发之消息队列
为什么要使用消息队列?
主要原因是由于在高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。
消息队列特性
业务无关:只做消息分发(业务解耦)
FIFO:先投递先到达
容灾:节点的动态增删和消息的持久化
性能:吞吐量提升,系统内部通信效率提高
广播
错峰与流控
Apache Kafka消息队列
消息持久化
高吞吐
RabbitMQ消息队列
可视化界面
高并发之应用拆分
**拆分原则:**业务优先、循序渐进、重构+分层、可靠测试
应用之间的通信:RPC(dubbo等)、消息队列
高并发其他知识点
常见限流算法:计数器算法、漏斗桶算法、令牌桶算法
数据库切库: 主从库,主库实时,从库异步
数据库分表:mybatis分表插件shardbatis2.0
高可用的一些手段:
1.任务调度系统分布式:elastic-job + zookeeper
2.主备切换:apache curator + zookeeper分布式锁实现。两台服务器交替进行服务
3.监控报警机制
面试必备:HashMap、Hashtable、ConcurrentHashMap的原理与区别