CNN进化史
猫神经元
RECEPTIVE FIELDS, BINOCULAR INTERACTION AND FUNCTIONAL ARCHITECTURE IN THE CAT’S VISUAL CORTEX-1961
创新点(innovation):
- Hubel和Wiesel在1958年的猫视觉皮层实验中,首次观察到视觉初级皮层的神经元对移动的边缘刺激敏感,并定义了简单和复杂细胞,发现了视功能柱结构。
- 提出了receptive field的概念
- 在猫的头颅上开了一个洞,插入电极,然后在猫清醒的时候在它眼前播放幻灯片,来分析它的大脑皮层产生的电信号。最终得出结论是猫的眼睛在观看物体时,大脑皮层上的不同区域的脑细胞会针对于这个物体的不同区域做出反应,然后所有细胞的反应结合到一起才能让猫识别出这个物体。
Neocognitron
Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position-1980
观点(view):
- 仿照猫神经元的网络结构可以实现自组织学习
创新点(innovation):
- 提出了类似卷积的结构(不一定是正方形)
- 类似于的hebb学习规则的学习方式
- 结果有很强的鲁棒性

卷积神经网络的雏形
Backpropagation applied to handwritten zip code recognition-1989
观点(view):
- 减少参数来减少对算力的要求
- 神经网络可以从原始图片中学习,而不用从特征向量中学习
创新点(Innovation):
- 采用反向传播的方法来更新参数
- 采用convolution->convolution->fully connection的结构

LeCun-5
Gradient-Based Learning Applied to Document Recognition-1998:
观点(view):
- Etest−Etrain=k(hn)α E t e s t − E t r a i n = k ( h n ) α , n n 是数据量
- 机器学习:raw input-feature extraction module->feature vector-classifier module->class score,传统的模式识别特征提取是固定的。神经网络特征提取也是可训练的。
创新点(Innovation):
- 提出了convolution->maxpool->fully connection的CNN结构

AlexNet
ImageNet Classification with Deep Convolutional Neural Networks-2012:
观点(view):
- 增加数据量和算力,性能会提升
- 去掉任意一个卷积层,性能都会下降,说明深度很重要
创新点(Innovation)
- Architecture:
- ReLU Nonlinearity: training error rate比tanh下降的快;只要有训练数据一部分是正值,训练就可以进行;不需要对数据进行归一化
- Local Response Normalization: 可以提高泛化能力(generalization), reduces our top-1 and top-5 error rates by 1.4% and 1.2%
- Overlapping Pooling: 2,2->3,2,reduces the top-1 and top-5 error rates by 0.4% and 0.3%
- 使用了group convolution,减少参数和合理利用GPU内存
- ReducingOverfitting
- Dropout: 相当于bagging许多模型,
- Data Augmentation: reduces the top-1 error rate by over 1%,翻转、随机剪裁
- weight decay: L2 regularization
Details of learning:
- using stochastic gradient descent with a batch size of 128 examples, momentum of 0.9, and weight decay of 0.0005.
- initialized the weights in each layer from a zero-mean Gaussian distribution with standard deviation 0.01.
- initialized the neuron biases in the second, fourth, and fifth convolutional layers, as well as in the fully-connected hidden layers, with the constant 1. 防止ReLU的范围全都跑到0

ZFNet
Visualizing and Understanding Convolutional Networks-2013
观点(view):
- 卷积神经网络成功原因:大量的标注数据,GPU的算力,更好的正则化(e.g., dropout)
- 如果不理解内在机制,开发新的方法就变成了试错(trial-and-error)
- 网络越深,学到的特征越抽象
创新点(Innovation):
- 提出了反卷积(把卷积核反过来,对下层的每个点做卷积),反池化(把最大值填到记录最大值的位置上),反激活(直接采用relu)
- 可视化之后发现,从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。
- 在网络训练过程中,
- 特征图可能会出现sudden jumps
- 低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。
- 从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此在训练网络的时候,不要着急看结果,需要保证网络收敛。
- 发现将图像进行旋转平移时,层数越深,变换提取到的特征差距越小
- 发现在训练过程中,前几层很快就收敛了,后面的层还会有很大变化。
- 通过可视化,将AlexNet的第一层卷积核大小11*11优化为7*7,步长从4优化为2。因为发现改变之后特征图更清晰,没有锯齿状的地方。
- 遮住关键部位对预测结果影响很大,不关键的部位影响一般

Network In Network
Network In Network-2014
观点(view):
- NINs enhance model discriminability for local patches within the receptive field.
- 全连层是ConvNet与传统神经网络的桥梁,卷积层是提取特征,全连层作为分类器。但是全连层易于过拟合,Hinton采用dropout来防止过拟合
创新点(Innovation):
- 多层感知卷积层(Mlpconv Layer):使用 Conv+MLP 代替传统卷积层,增强网络提取抽象特征和泛化的能力;
- 全局平均池化层(Global Average Pooling):使用平均池化代替全连接层,很大程度上减少参数空间,便于加深网络和训练,有效防止过拟合。it is more native to the convolution structure by enforcing correspondences between feature maps and categories.加强特征与结果的联系
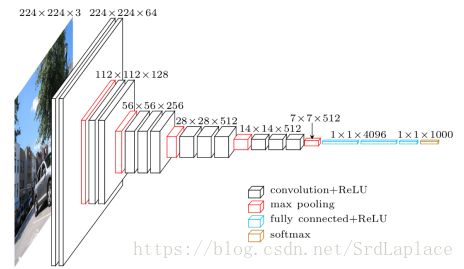
VGG
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION-10 Apr 2015
观点(view):神经网络越深,准确率越高,发现lrn没啥用
创新点(Innovation):
- increasing depth using an architecture with very small (3x3) convolution filters
- learning rate decreased
- 预训练
训练(train):
- batch size was set to 256, momentum to 0.9.
- The training was regularised by weight decay (the L2 penalty multiplier set to 5*10-4) and dropout regularisation for the first two fully-connected layers (dropout ratio set to 0.5).
- The learning rate was initially set to 10-2, and then decreased by a factor of 10 when the validation set accuracy stopped improving
- In total, the learning rate was decreased 3 times, and the learning was stopped after 370K iterations (74 epochs).
- 先训练浅层的,然后再用浅层的作为FC和前几个conv的初始值训练深层的。
- Data Augmentation
GoogLeNet-Inception-V1
Going deeper with convolutions - 17 Sep 2014
观点(view):
- 增加网络的深度(层数)和宽度(每层的神经元的数量)可以提高准确率
- 灵感来自灵长类视觉皮层的神经科学模型,使用一系列不同尺寸的固定滤波器来处理多个尺度。
- 增加网络大小会使得所使用的计算资源大大增加,而且如果增加的容量被低效地使用(例如,如果大多数权重最终接近于零),那么大量的计算被浪费了。解决这两个问题的根本途径是把结构从完全连接转向稀疏连接,即使在卷积内也是应该如此。
- 1x1卷积有两个作用:降维,以消除计算瓶颈;增加非线性。
- The Inception architecture是作者在找寻稀疏结构中发现的,经过大量的实验测试,这是最优的稀疏结构。
创新点(Innovation):
- The Inception architecture
- 辅助分类器
- 大量使用1x1卷积结构
- 利用softmax简单平均作为模型融合。其他方法,例如少数服从多数和分类器平均,但是它们的性能低于简单的平均值。
- 使用多种测试策略,确保没有过拟合。
训练(train):
- 使用DistBelief分布式机器学习系统进行训练,使用适量的模型和数据并行。
- GoogLeNet network could be trained to convergence using few high-end高端 GPUs within a week, the main limitation being the memory usage.
- Our training used asynchronous stochastic gradient descent with 0.9 momentum, fixed learning rate schedule (decreasing the learning rate by 4% every 8 epochs).
- Polyak averaging was used to create the final model used at inference time.(优化过程中最后几个步的模型参数的平均)
- 由于竞赛的图像采样方法的变化,我们反复训练了已经收敛的网络,很难给出有参考价值的超参数选择,例如dropout和learning rate。
- 使用了7个版本的GoogLeNet,然后进行融合,成绩大为提升


Highway Networks
Highway Networks - 3 Nov 2015
观点(view):
- Inspired by Long Short Term Memory recurrent neural networks.
- Plain networks become much harder to optimize with increasing depth, while highway networks with up to 100 layers can still be optimized well.
创新点(Innovation):
- highway network architecture: y=H(x,WH)⋅T(x,WT)+x⋅C(x,WC) y = H ( x , W H ) ⋅ T ( x , W T ) + x ⋅ C ( x , W C )
训练(train):
- a negative bias initialization was sufficient for learning to proceed in very deep networks for various zero-mean initial distributions of WH W H and different activation functions used by H H .
Batch Normalization + Inception V2
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift - 13 Feb 2015
观点(view):
- SGD是深度学习能够实现的基础,但是由于前几层参数的变化,每层的输入分布在训练过程中发生变化,我们把这种现象称为internal covariate shift(内部协变量漂移)。我们希望每层的分布是稳定的,所以需要进行归一化。
- BN正则化了网络,减少了对dropout的需要。使用BN使得使用有饱和区的非线性神经元成更加方便,不用担心训练时被卡住。
- 加入BN之后,发现训练速度提升明显,精度也有提升
- The batch-normalized network enjoys the higher test accuracy. 原因在于不加BN的网络每层的分布会随训练的进行而改变,而下一层拟合的是以前的分布。
- 提高了精度,计算量增加很小,和奇异值分解的方法殊途同归。
创新点(Innovation):
- Batch Normalization
- 把原来的GoogLeNet的5x5的卷积核改进为两组3x3的卷积核级联(Inception V2)
训练(train):
- Increase learning rate
- Remove Dropout
- Reduce the L2 L 2 weight regularization
- Accelerate the learning rate decay
- Remove Local Response Normalization
- Shuffle training examples more thoroughly(彻底)
- Reduce the photometric distortions(光度失真,数据增强)

Inception V3
Rethinking the Inception Architecture for Computer Vision - 11 Dec 2015
观点(view):
- 设计神经网络要兼顾效率和精度
- General Design Principles:
- Avoid representational bottlenecks, especially early in the network.
- 特征图的维度应该缓慢减小。
- 卷积每层激活程度越高,更容易(判别特征)和(训练)。(感觉池化有这个作用)
- Spatial aggregation(空间聚合,1*1的卷积核降维)can be done over lower dimensional embeddings without much or any loss in representational power.(原因是相邻单位结果之间有很强相关性导致在降维过程中信息损失很少。由于这些信号应该有很多冗余,降低维度甚至可以促进更快的学习。 )
- Balance the width and depth of the network. 增加网络的宽度和深度可以提高网络质量。如果两者并行增加,可以达到恒定计算量的条件下的最佳改进。因此计算预算应该在网络的深度和宽度之间平衡分配。
- 尽管这些原则可能是有道理的,但使用它们来提高网络外的质量并非易事。(微笑)
- GoogLeNet的高性能来自于降维。1x1的卷积核可以被视为分解卷积的特殊情况。
- 减小卷积核不但可以减小参数数量,还可以减少乘法数量。
- 一个5x5的卷积可以看成时一个5x5范围内的全连接,我们可以采用卷积替代全连接的思路分解卷积——3*3的卷积后面跟一个3x3的全连接卷积。进行实验之后可知,第一层3x3之后加ReLU的效果总是强于直接线性激活。
- 大于3*3的卷积核总能分解成一系列3x3的卷积,接下来的问题是还能不能更小,例如2x2。
但是实验结果是使用非对称的卷积总会好于2x2的卷积。例如1个3x1之后接一个1x3,总体的感受野还是3x3,而且参数少了很多,计算量小于2x2的。 - auxiliary classifiers promote more stable learning and better convergence.
- 训练开始时似乎辅助分类器没啥用,达到高精度时提高了精度。
- we argue that the auxiliary classifiers act as regularizer.
- 使用one-hot编码时,softmax优化会带来两个问题:over-fitting,因为实际是某个标签的概率不可能是1,logit不可能无穷大;其次,one-hot编码鼓励最大的logit和所有其他logit之间的差异变大,因为softmax的梯度再0到1之间有界,降低了模型的adapt.直觉上,这是因为模型对其预测过于自信。
创新点(Innovation):
- Model Regularization via Label Smoothing: label-smoothing regularization(LSR)
- Factorizing Convolutions: nxn -> (nx1+1xn) or (nx1 stack 1xn)
- 讨论低分辨率的效果(detection时会用到,训练很多模型来适应分辨率太浪费了,希望将图片直接放缩之后直接可以用原来的模型)。
训练(train):
- with batch size 32 for 100 epochs
- earlier experiments used momentum with a decay of 0.9, while best models were achieved using RMSProp with decay of 0.9 and ϵ ϵ = 1.0.
- used a learning rate of 0.045, decayed every two epoch using an exponential rate of 0.94.
- gradient clipping with threshold 2.0 was found to be useful to stabilize the training.
- Model evaluations are performed using a running average of the parameters computed over time.
ResNet
Deep Residual Learning for Image Recognition 10 Dec 2015
观点(view):
- 随着深度的增加,training error和test error有可能反而上升。这不是因为过拟合,而是因为深层网络难以优化。
- 发现110 and 1202 layers的ResNet训练误差差不多,测试误差1202 layers差一些。We argue that this is because of overfitting.
创新点(Innovation):
- Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. H(x)=F(x)+x H ( x ) = F ( x ) + x can be realized by feedforward neural networks with “shortcut connections”( skipping one or more layers, identity mapping).
- Deeper Bottleneck Architectures: 1x1->3x3->1x1 convolutions, where the 1x1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3x3 layer a bottleneck with smaller input/output dimensions.
训练(train):
- The image is resized with its shorter side randomly sampled in [256, 480] for scale augmentation.
- We adopt batch normalization(BN) right after each convolution and before activation.
- We initialize the weights as in [K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.]
- We use SGD with a mini-batch size of 256.
- The learning rate starts from 0.1 and is divided by 10 when the error plateaus, and the models are trained for up to 60×104 60 × 10 4 iterations.
- We use a weight decay of 0.0001 and a momentum of 0.9.
- We do not use dropout.
- In testing, average the scores at multiple scales (images are resized such that the shorter side is in {224, 256, 384, 480, 640})

Spatial Transformer Network
Spatial Transformer Networks - 4 Feb 2016
观点(view):
- 最大池化使得CNN有一定的旋转平移不变性。
创新点(Innovation):
- 学习一个类似于注意力模型的Spatial Transformer module
Inception-v4, Inception-ResNet
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning - 23 Aug 2016
创新点(Innovation):
- the combination of Inception architecture and Residual connections
- 多种卷积分解stacking成的Inception模块(V4)
SQUEEZENET
SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE - 4 Nov 2016
观点(view):
- With equivalent accuracy, smaller CNN architectures offer at least three advantages:
- Smaller CNNs require less communication across servers during distributed training.
- Smaller CNNs require less bandwidth(带宽) to export a new model from the cloud to an autonomous car.
- Smaller CNNs are more feasible to deploy on FPGAs and other hardware with limited memory.
- 其他减少参数的方式:SVD分解全连矩阵;Network Pruning;quantization;designed a hardware accelerator
- ARCHITECTURAL DESIGN STRATEGIES:
- Replace 3x3 filters with 1x1 filters.
- Decrease the number of input channels to 3x3 filters.
- Downsample late in the network so that convolution layers have large activation maps.
创新点(Innovation):
- the Fire module: a squeeze convolution layer (which has only 1x1 filters), feeding into an expand layer that has a mix of 1x1 and 3x3 convolution filters.- - 核心思想:减少3x3conv,1x1减少通道,延迟pool


Xception
Xception: Deep Learning with Depthwise Separable Convolutions - 4 Apr 2017
观点(view):
- Inception背后的基本假设是channel之间的相关性和空间相关性充分解耦。
创新点(Innovation):
- Depthwise separable convolutions
- 结合了ResNet和SeparableConv
训练(train):
- On ImageNet:
- Optimizer: SGD
- Momentum: 0.9
- Initial learning rate: 0.045
- Learning rate decay: decay of rate 0.94 every 2 epochs
- On JFT:
- Optimizer: RMSprop
- Momentum: 0.9
- Initial learning rate: 0.001
- Learning rate decay: decay of rate 0.9 every 3,000,000 samples

ResNeXt
Aggregated Residual Transformations for Deep Neural Networks - 11 Apr 2017.
观点(view):
- 两种策略,简单模型stacking和split-transform-merge
- cardinality基数(变换集的大小)是一个具体的,可测量的维度,除了宽度和深度的维度之外,它是至关重要的。
创新点(Innovation):
- ResNeXt module:分成若干个路线,然后再加起来,再结合ResNet的结构

FRACTALNET
FRACTALNET: ULTRA-DEEP NEURAL NETWORKS WITHOUT RESIDUALS - 26 May 2017
观点(view):
- 分型网络减少了对训练的trick的依赖。
- 减少对数据增强的依赖
- 相当于teacher-student模型
创新点(Innovation):
- FRACTALNET:分型结构的网络
- global drop-path:正则化;为用户提供了速度(浅)和精度(深)之间的权衡选择。
训练(train):
- We train fractal networks using stochastic gradient descent with momentum. As now standard, we employ batch normalization together with each conv layer (convolution, batch norm, then ReLU).

MobileNets
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications - 17 Apr 2017
观点(view):
- 训练更小的网络的关键:fully factorized convolutions,depthwise separable filters,bottleneck。
- 压缩的方法:因式分解,数字的量化,向量的量化,剪枝。
- depthwise separable convolutions将output channels和size of the kernel解耦合。

ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
Devices - 7 Dec 2017
观点(view):
- Group Convolution很好用
- 连续两组Group Convolution会使得第二组Group Convolution没用用到全局通道的信息

DensNet
Densely Connected Convolutional Networks - 28 Jan 2018
观点(view):
- 使得模型更紧凑,特征图数目更少


MobileNetV2
MobileNetV2: Inverted Residuals and Linear Bottlenecks - 2 Apr 2018
观点(view):
- 非线性的Bottlenecks会损失信息
- 通道变多使得非线性表达能力更强

SENet
Squeeze-and-Excitation Networks - 5 Apr 2018
观点(view):
- 适应性地重新校准 channel-wise feature responses by explicitly modelling interdependencies between channels. (有点像通道上的注意力模型)

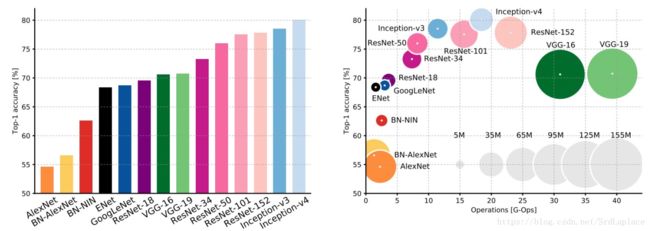
总体性能对比