标准化(BN)与激活函数(BN在 激活函数前,在卷积后 )_
这里写自定义目录标题
- 概念性东西
- 1、内部协变量转移
- 2、 covariate shift 现象
- 3、白化
- 4、如何让神经网络每个隐藏层节点的激活输入分布固定下来呢?
- 5、如何解决隐藏层神经元梯度消失问题
- 6、 用什么样的指标来判断是否已经出现了covariate shift现象
- 7. Batch Normalization
- 8、Batch Normalization 的优点
- 9、 Activation Function
- 10、多层神经网络梯度消失与梯度爆炸问题
- 11、 如何解决梯度消失和梯度爆炸问题
概念性东西
1、内部协变量转移
所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐藏层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
2、 covariate shift 现象
训练集的数据分布和预测集的数据分布不一致,这样的情况下如果我们在训练集上训练出一个分类器,肯定在预测集上不会取得比较好的效果。这种训练集和预测集样本分布不一致的问题就叫做“covariate shift”现象。
3、白化
就是对输入数据分布变换到0均值,单位方差的正态分布
4、如何让神经网络每个隐藏层节点的激活输入分布固定下来呢?
深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,
其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠
近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的
梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任
意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较
标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较
大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
5、如何解决隐藏层神经元梯度消失问题
对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。

这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的线性激活x=WU+B,这里的U才是t-1层神经元的输出。某个神经元对应的原始的激活x通过减去mini-Batch内m个实例获得的m个激活x求得的均值E(x)并除以求得的方差Var(x)来进行转换。

我们训练过程中采用batch 随机梯度下降,上面的E(xk)指的是每一批训练数据神经元xk的平均值;然后分母就是每一批数据神经元xk激活度的一个标准差了。
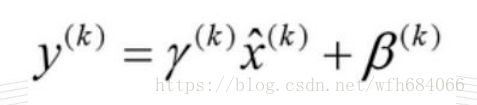
变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度
。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
6、 用什么样的指标来判断是否已经出现了covariate shift现象
MCC(Matthews correlation coefficient),这个指标本质上是用一个训练集数据和预测集数据之间的相关系数,取值在[-1,1]之间,如果是1就是强烈的正相关,0就是没有相关性,-1就是强烈的负相关。
7. Batch Normalization
在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。

可能学完了上面的算法,你只是知道它的一个训练过程,一个网络一旦训练完了,就没有了min-batch这个概念了。测试阶段我们一般只输入一个测试样本,看看结果而已。因此测试样本,前向传导的时候,上面的均值u、标准差σ 要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差都是固定不变的。我们可以采用这些数值来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和 σ 计算公式如下:
![]()
对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:

对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
8、Batch Normalization 的优点
1、不仅仅极大提升了训练速度,收敛过程大大加快;
2、还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;
3、另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。
9、 Activation Function
激活函数包含饱和激活函数与非饱和激活函数。常见的sigmoid 和tanh 属于“饱和激活函数”,而ReLU及其变体则属于“非饱和激活函数”。通常情况下,使用“非饱和激活函数”的优势在于两点:
.首先,“非饱和激活函数”能解决所谓的“梯度消失”问题。
其次,它能加快收敛速度。
10、多层神经网络梯度消失与梯度爆炸问题
层数比较多的神经网络模型在训练的时候会出现梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
1
对于下图所示中含有3个隐藏层的神经网络:
产生的梯度消失问题:隐藏层中靠近输出层的hidden layer 3的权值更新相对正常,但是靠近输入层的hidden layer1的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,扔接近于初始化的权值。这就导致hidden layer 1 相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习。
梯度爆炸的情况:当初始的权值过大,靠近输入层的hidden layer 1的权值变化比靠近输出层的hidden layer 3的权值变化更快,就会引起梯度爆炸的问题。
11、 如何解决梯度消失和梯度爆炸问题
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
1、用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
2、用批量标准化,即Batch Normalization。
3、LSTM的结构设计也可以改善RNN中的梯度消失问题。