Spark源码和调优简介 Spark Core

作者:calvinrzluo,腾讯 IEG 后台开发工程师
本文基于 Spark 2.4.4 版本的源码,试图分析其 Core 模块的部分实现原理,其中如有错误,请指正。为了简化论述,将部分细节放到了源码中作为注释,因此正文中是主要内容。
Spark Core
RDD
RDD(Resilient Distributed Dataset),即弹性数据集是 Spark 中的基础结构。RDD 是 distributive 的、immutable 的,可以被 persist 到磁盘或者内存中。
对 RDD 具有转换操作和行动操作两种截然不同的操作。转换(Transform)操作从一个 RDD 生成另一个 RDD,但行动(Action)操作会去掉 RDD 的 Context。例如take是行动操作,返回的是一个数组而不是 RDD 了,如下所示
scala> var rdd1 = sc.makeRDD(Seq(10, 4, 2, 12, 3))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[40] at makeRDD at :21
scala> rdd1.take(1)
res0: Array[Int] = Array(10)
scala> rdd1.take(2)
res1: Array[Int] = Array(10, 4)
转换操作是 Lazy 的,直到遇到一个 Eager 的 Action 操作,Spark 才会生成关于整条链的执行计划并执行。这些 Action 操作将一个 Spark Application 分为了多个 Job。
常见的Action 操作包括:reduce、collect、count、take(n)、first、takeSample(withReplacement, num, [seed])、takeOrdered(n, [ordering])、saveAsTextFile(path)、saveAsSequenceFile(path)、saveAsObjectFile(path)、countByKey()、foreach(func)。
常见 RDD
RDD 是一个抽象类abstract class RDD[T] extends Serializable with Logging,在 Spark 中有诸如ShuffledRDD、HadoopRDD等实现。每个 RDD 都有对应的compute方法,用来描述这个 RDD 的计算方法。需要注意的是,这些 RDD 可能被作为某些 RDD 计算的中间结果,例如CoGroupedRDD,对应的,例如MapPartitionsRDD也可能是经过多个 RDD 变换得到的,其决定权在于所使用的算子。
我们来具体查看一些 RDD。
ParallelCollectionRDD
这个 RDD 由parallelize得到scala> val arr = sc.parallelize(0 to 1000) arr: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at:24 HadoopRDDclass HadoopRDD[K, V] extends RDD[(K, V)] with LoggingFileScanRDD
这个 RDD 一般从spark.read.text(...)语句中产生,所以实现在sql 模块中。class FileScanRDD( @transient private val sparkSession: SparkSession, readFunction: (PartitionedFile) => Iterator[InternalRow], @transient val filePartitions: Seq[FilePartition]) extends RDD[InternalRow](sparkSession.sparkContext, Nil "InternalRow") {MapPartitionsRDDclass MapPartitionsRDD[U, T] extends RDD[U]这个 RDD 是
map、mapPartitions、mapPartitionsWithIndex操作的结果。注意,在较早期的版本中,
map会得到一个MappedRDD,filter会得到一个FilteredRDD、flatMap会得到一个FlatMappedRDD,不过目前已经找不到了,统一变成MapPartitionsRDDscala> val a3 = arr.map(i => (i+1, i)) a3: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at map at:25 scala> val a3 = arr.filter(i => i > 3) a3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at filter at :25 scala> val a3 = arr.flatMap(i => Array(i)) a3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at flatMap at :25 join操作的结果也是MapPartitionsRDD,这是因为其执行过程的最后一步flatMapValues会创建一个MapPartitionsRDDscala> val rdd1 = sc.parallelize(Array((1,1),(1,2),(1,3),(2,1),(2,2),(2,3))) rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[8] at parallelize at:24 scala> val rdd2 = sc.parallelize(Array((1,1),(1,2),(1,3),(2,1),(2,2),(2,3))) rdd2: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[9] at parallelize at :24 scala> val rddj = rdd1.join(rdd2) rddj: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[12] at join at :27 ShuffledRDDShuffledRDD用来存储所有 Shuffle 操作的结果,其中K、V很好理解,C是 Combiner Class。class ShuffledRDD[K, V, C] extends RDD[(K, C)]以
groupByKey为例scala> val a2 = arr.map(i => (i+1, i)) a2: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at map at:25 scala> a2.groupByKey res1: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[3] at groupByKey at :26 注意,
groupByKey需要 K 是 Hashable 的,否则会报错。scala> val a2 = arr.map(i => (Array.fill(10)(i), i)) a2: org.apache.spark.rdd.RDD[(Array[Int], Int)] = MapPartitionsRDD[2] at map at:25 scala> a2.groupByKey org.apache.spark.SparkException: HashPartitioner cannot partition array keys. at org.apache.spark.rdd.PairRDDFunctions不能识别此Latex公式: anonfun$combineByKeyWithClassTag$1.apply(PairRDDFunctions.scala:84) at org.apache.spark.rdd.PairRDDFunctionsanonfun CoGroupedRDDclass CoGroupedRDD[K] extends RDD[(K, Array[Iterable[_]])]首先,我们需要了解一下什么是
cogroup操作,这个方法有多个重载版本。如下所示的版本,对this或other1或other2的所有的 key,生成一个RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2])),表示对于这个 key,这三个 RDD 中所有值的集合。容易看到,这个算子能够被用来实现 Join 和 Union(不过后者有点大材小用了)def cogroup[W1, W2](other1: RDD[(K, W1 "W1, W2")], other2: RDD[(K, W2)], partitioner: Partitioner) : RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))]这里的
Partitioner是一个abstract class,具有numPartitions: Int和getPartition(key: Any): Int两个方法。通过继承Partitioner可自定义分区的实现方式,目前官方提供有RangePartitioner和HashPartitioner等。UnionRDDclass UnionRDD[T] extends RDD[T]UnionRDD一般通过union算子得到scala> val a5 = arr.union(arr2) a5: org.apache.spark.rdd.RDD[Int] = UnionRDD[7] at union at:27 CoalescedRDD
常见 RDD 外部函数
Spark 在 RDD 之外提供了一些外部函数,它们可以通过隐式转换的方式变成 RDD。
PairRDDFunctions
这个 RDD 被用来处理 KV 对,相比RDD,它提供了groupByKey、join等方法。以combineByKey为例,他有三个模板参数,从 RDD 过来的K和V以及自己的C。相比 reduce 和 fold 系列的(V, V)=> V,这多出来的C使combineByKey更灵活,通过combineByKey能够将V变换为C。
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = {
//实现略
}
OrderedRDDFunctions
这个用来提供sortByKey、filterByRange等方法。
Spark 的架构概览
Spark 在设计上的一个特点是它和下层的集群管理是分开的,一个 Spark Application 可以看做是由集群上的若干进程组成的。因此,我们需要区分 Spark 中的概念和下层集群中的概念,例如我们常见的 Master 和 Worker 是集群中的概念,表示节点;而 Driver 和 Executor 是 Spark 中的概念,表示进程。根据爆栈网,Driver 可能位于某个 Worker 节点中,或者位于 Master 节点上,这取决于部署的方式
在官网上给了这样一幅图,详细阐明了 Spark 集群下的基础架构。SparkContext是整个 Application 的管理核心,由 Driver 来负责管理。SparkContext负责管理所有的 Executor,并且和下层的集群管理进行交互,以请求资源。
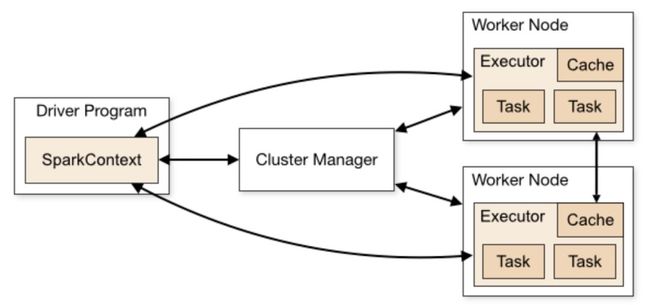
在 Stage 层次及以上接受DAGScheduler的调度,而TaskScheduler则调度一个 Taskset。在 Spark on Yarn 模式下,CoarseGrainedExecutorBackend 和 Executor 一一对应,它是一个独立于 Worker 主进程之外的一个进程,我们可以 jps 查看到。而 Task 是作为一个 Executor 启动的一个线程来跑的,一个 Executor 中可以跑多个 Task。
在实现上,CoarseGrainedExecutorBackend继承了ExecutorBackend这个 trait,作为一个IsolatedRpcEndpoint,维护Executor对象实例,并通过创建的DriverEndpoint实例的与 Driver 进行交互。
在进程启动时,CoarseGrainedExecutorBackend调用onStart()方法向 Driver 注册自己,并产生一条"Connecting to driver的 INFO。CoarseGrainedExecutorBackend通过DriverEndpoint.receive方法来处理来自 Driver 的命令,包括LaunchTask、KillTask等。这里注意一下,在 scheduler 中有一个CoarseGrainedSchedulerBackend,里面实现相似,在看代码时要注意区分开。
有关 Executor 和 Driver 的关系,下面这张图更加直观,需要说明的是,一个 Worker 上面也可能跑有多个 Executor,每个 Task 也可以在多个 CPU 核心上面运行

Spark 上下文
在代码里我们操作一个 Spark 任务有两种方式,通过 SparkContext,或者通过 SparkSession
SparkContext 方式
SparkContext 是 Spark 自创建来一直存在的类。我们通过 SparkConf 直接创建 SparkContextval sparkConf = new SparkConf().setAppName("AppName").setMaster("local") val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")SparkSession 方式
SparkSession 是在 Spark2.0 之后提供的 API,相比 SparkContext,他提供了对 SparkSQL 的支持(持有SQLContext),例如createDataFrame等方法就可以通过 SparkSession 来访问。
在builder.getOrCreate()的过程中,虽然最终得到的是一个 SparkSession,但实际上内部已经创建了一个 SparkContext,并由这个 SparkSession 持有。
val spark: SparkSession = SparkSession.builder() // 得到一个Builder
.master("local").appName("AppName").config("spark.some.config.option", "some-value")
.getOrCreate() // 得到一个SparkSession
// SparkSession.scala
val sparkContext = userSuppliedContext.getOrElse {
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
// set a random app name if not given.
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(java.util.UUID.randomUUID().toString)
}
SparkContext.getOrCreate(sparkConf)
// Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions.
}
applyExtensions(sparkContext.getConf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS).getOrElse(Seq.empty),extensions)
session = new SparkSession(sparkContext, None, None, extensions)
SparkEnv
SparkEnv持有一个 Spark 实例在运行时所需要的所有对象,包括 Serializer、RpcEndpoint(在早期用的是 Akka actor)、BlockManager、MemoryManager、BroadcastManager、SecurityManager、MapOutputTrackerMaster/Worker 等等。
SparkEnv 由 SparkContext 创建,并在之后通过伴生对象SparkEnv的get方法来访问。
在创建时,Driver 端的 SparkEnv 是 SparkContext 创建的时候调用SparkEnv.createDriverEnv创建的。Executor 端的是其守护进程CoarseGrainedExecutorBackend创建的时候调用SparkEnv.createExecutorEnv方法创建的。这两个方法最后都会调用create方法
// Driver端
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master, conf))
}
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
// Executor端
// CoarseGrainedExecutorBackend.scala
val env = SparkEnv.createExecutorEnv(driverConf, arguments.executorId, arguments.bindAddress,
arguments.hostname, arguments.cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor", backendCreateFn(env.rpcEnv, arguments, env))
arguments.workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
// SparkEnv.scala
// create函数
val blockManager = new BlockManager(...)
Spark 的任务调度
Spark 的操作可以分为两种,Transform 操作是 Lazy 的,而 Action 操作是 Eager 的。每一个 Action 会产生一个 Job。
Spark 的 Transform 操作可以分为宽依赖(ShuffleDependency)和窄依赖(NarrowDependency)操作两种,其中窄依赖还有两个子类OneToOneDependency和RangeDependency。窄依赖操作表示父 RDD 的每个分区只被子 RDD 的一个分区所使用,例如union、map、filter等的操作;而宽依赖恰恰相反。宽依赖需要 shuffle 操作,因为需要将父 RDD 的结果需要复制给不同节点用来生成子 RDD,有关ShuffleDependency将在下面的 Shuffle 源码分析中详细说明。当 DAG 的执行中出现宽依赖操作时,Spark 会将其前后划分为不同的 Stage,在下一章节中将具体分析相关代码。
在 Stage 之下,就是若干个 Task 了。这些 Task 也就是 Spark 的并行单元,通常来说,按照当前 Stage 的最后一个 RDD 的分区数来计算,每一个分区都会启动一个 Task 来进行计算。我们可以通过rdd.partitions.size来获取一个 RDD 有多少个分区。
Task 具有两种类型,ShuffleMapTask和ResultTask。其中ResultTask是ResultStage的 Task,也就是最后一个 Stage 的 Task。
Spark 的存储管理
为了实现与底层细节的解耦,Spark 的存储基于 BlockManager 给计算部分提供服务。类似于 Driver 和 Executor,BlockManager 机制也分为 BlockManagerMaster 和 BlockManager。Driver 上的 BlockManagerMaster 对于存在与 Executor 上的 BlockManager 统一管理。BlockManager 只是负责管理所在 Executor 上的 Block。
BlockManagerMaster 和 BlockManager 都是在 SparkEnv 中创建的,
// Mapping from block manager id to the block manager's information.
val blockManagerInfo = new concurrent.TrieMap[BlockManagerId, BlockManagerInfo]( "BlockManagerId, BlockManagerInfo")
val blockManagerMaster = new BlockManagerMaster(
registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(
rpcEnv,
isLocal,
conf,
listenerBus,
// 是否使用ExternalShuffleService读取持久化在磁盘上的数据
if (conf.get(config.SHUFFLE_SERVICE_FETCH_RDD_ENABLED)) {
externalShuffleClient
} else {
None
}, blockManagerInfo)),
registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_HEARTBEAT_ENDPOINT_NAME,
new BlockManagerMasterHeartbeatEndpoint(rpcEnv, isLocal, blockManagerInfo)),
conf,
isDriver)
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,
blockManagerPort, numUsableCores, blockManagerMaster.driverEndpoint)
// NB: blockManager is not valid until initialize() is called later.
val blockManager = new BlockManager(
executorId,
rpcEnv,
blockManagerMaster,
serializerManager,
conf,
memoryManager,
mapOutputTracker,
shuffleManager,
blockTransferService,
securityManager,
externalShuffleClient)
Driver 节点和 Executor 节点的 BlockManager 之间的交互可以使用下图来描述,在此就不详细说明。
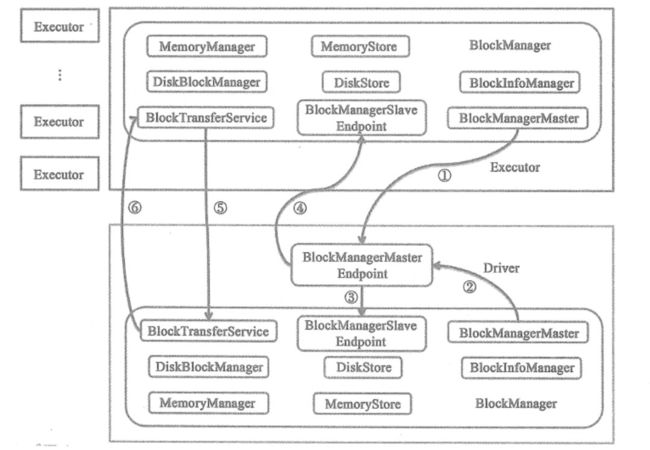
BlockId 和 BlockInfo
抽象类BlockId被用来唯一标识一个 Block,具有全局唯一的名字,通常和一个文件相对应。BlockId有着确定的命名规则,并且和它实际的类型有关。
如果它是用来 Shuffle 的ShuffleBlockId,那么他的命名就是
String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId
抑或它是用来 Broadcast 的BroadcastBlockId,他的命名就是
"broadcast_" + broadcastId + (if (field == "") "" else "_" + field)
或者它是一个 RDD,它的命名就是
"rdd_" + rddId + "_" + splitIndex
通过在 Spark.log 里面跟踪这些 block 名字,我们可以了解到当前 Spark 任务的执行和存储情况。
BlockInfo中的level项表示这个 block 的存储级别。
// BlockInfoManager.scala
private[storage] class BlockInfo(
val level: StorageLevel,
val classTag: ClassTag[_],
val tellMaster: Boolean) {
持久化
Spark 提供了如下的持久化级别,其中选项为useDisk、useMemory、useOffHeap、deserialized、replication,分别表示是否采用磁盘、内存、堆外内存、反序列化以及持久化维护的副本数。其中反序列化为 false 时(好绕啊),会对对象进行序列化存储,能够节省一定空间,但同时会消耗计算资源。需要注意的是,cache操作是persist的一个特例,等于MEMORY_ONLY的 persist。所有的广播对象都是MEMORY_AND_DISK的存储级别
object StorageLevel extends scala.AnyRef with scala.Serializable {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true) // 默认存储类别
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
}
想在 Spark 任务完成之后检查每一个 RDD 的缓存状况是比较困难的,虽然在 Spark EventLog 中,我们也能看到在每一个 RDD 的 RDD Info 中有一个 StorageLevel 的条目。RDDInfo的源码建议我们可以通过(Use Disk||Use Memory)&&NumberofCachedPartitions这样的条件来判断一个 RDD 到底有没有被 cache。但实际上,似乎 EventLog 里面的NumberofCachedPartitions、Memory Size、Disk Size永远是 0,这可能是只能在执行过程中才能看到这些字段的值,毕竟 WebUI 的 Storage 标签就只在执行时能看到。不过(Use Disk||Use Memory)在 cache 调用的 RDD 上是 true 的,所以可以以这个 RDD 为根做一个 BFS,将所有不需要计算的 RDD 找出来。
BlockInfoManager
BlockInfoManager用来管理 Block 的元信息,例如它维护了所有 BlockId 的 BlockInfo 信息infos: mutable.HashMap[BlockId, BlockInfo]。不过它最主要的功能还是为读写 Block 提供锁服务
本地读 Block
本地读方法位于 BlockManager.scala 中,从前叫getBlockData,现在叫getLocalBlockData,名字更易懂了。getLocalBlockData的主要内容就对 Block 的性质进行讨论,如果是 Shuffle 的,那么就借助于ShuffleBlockResolver。
ShuffleBlockResolver是一个 trait,它有两个子类IndexShuffleBlockResolver和ExternalShuffleBlockResolver,它们定义如何从一个 logical shuffle block identifier(例如 map、reduce 或 shuffle)中取回 Block。这个类维护 Block 和文件的映射关系,维护 index 文件,向BlockStore提供抽象。
// BlockManager.scala
override def getLocalBlockData(blockId: BlockId): ManagedBuffer = {
if (blockId.isShuffle) {
// 如果这个BlockId是Shuffle的,那么就通过shuffleManager的shuffleBlockResolver来获取BlockData
shuffleManager.shuffleBlockResolver.getBlockData(blockId)
} else {
// 否则使用getLocalBytes
getLocalBytes(blockId) match {
case Some(blockData) =>
new BlockManagerManagedBuffer(blockInfoManager, blockId, blockData, true)
case None =>
// If this block manager receives a request for a block that it doesn't have then it's
// likely that the master has outdated block statuses for this block. Therefore, we send
// an RPC so that this block is marked as being unavailable from this block manager.
reportBlockStatus(blockId, BlockStatus.empty)
throw new BlockNotFoundException(blockId.toString)
}
}
}
我们看getLocalBytes函数,它带锁地调用doGetLocalBytes
def getLocalBytes(blockId: BlockId): Option[BlockData] = {
logDebug(s"Getting local block $blockId as bytes")
assert(!blockId.isShuffle, s"Unexpected ShuffleBlockId $blockId")
blockInfoManager.lockForReading(blockId).map { info => doGetLocalBytes(blockId, info) }
}
上面的这一段代码会在 spark.log 中产生类似下面的 Log,我们由此可以对 Block 的用途,存储级别等进行分析。
19/11/26 17:24:52 DEBUG BlockManager: Getting local block broadcast_3_piece0 as bytes
19/11/26 17:24:52 TRACE BlockInfoManager: Task -1024 trying to acquire read lock for broadcast_3_piece0
19/11/26 17:24:52 TRACE BlockInfoManager: Task -1024 acquired read lock for broadcast_3_piece0
19/11/26 17:24:52 DEBUG BlockManager: Level for block broadcast_3_piece0 is StorageLevel(disk, memory, 1 replicas)
doGetLocalBytes负责根据 Block 的存储级别,以最小的代价取到序列化后的数据。从下面的代码中可以看到,Spark 认为序列化一个对象的开销是高于从磁盘中读取一个已经序列化之后的对象的开销的,因为它宁可从磁盘里面取也不愿意直接从内存序列化。
private def doGetLocalBytes(blockId: BlockId, info: BlockInfo): BlockData = {
val level = info.level
logDebug(s"Level for block $blockId is $level")
// 如果内容是序列化的,先尝试读序列化的到内存和磁盘。
// 如果内容是非序列化的,尝试序列化内存中的对象,最后抛出异常表示不存在
if (level.deserialized) {
// 因为内存中是非序列化的,尝试能不能先从磁盘中读到非序列化的。
if (level.useDisk && diskStore.contains(blockId)) {
// Note: Spark在这里故意不将block放到内存里面,因为这个if分支是处理非序列化块的,
// 这个块可能被按照非序列化对象的形式存在内存里面,因此没必要在在内存里面存一份序列化了的。
diskStore.getBytes(blockId)
} else if (level.useMemory && memoryStore.contains(blockId)) {
// 不在硬盘上,就序列化内存中的对象
new ByteBufferBlockData(serializerManager.dataSerializeWithExplicitClassTag(
blockId, memoryStore.getValues(blockId).get, info.classTag), true)
} else {
handleLocalReadFailure(blockId)
}
} else {
// 如果存在已经序列化的对象
if (level.useMemory && memoryStore.contains(blockId)) {
// 先找内存
new ByteBufferBlockData(memoryStore.getBytes(blockId).get, false)
} else if (level.useDisk && diskStore.contains(blockId)) {
// 再找磁盘
val diskData = diskStore.getBytes(blockId)
maybeCacheDiskBytesInMemory(info, blockId, level, diskData)
.map(new ByteBufferBlockData(_, false))
.getOrElse(diskData)
} else {
handleLocalReadFailure(blockId)
}
}
}
Spark 的内存管理
在 Spark 1.6 之后,内存管理模式发生了大变化,从前版本的内存管理需要通过指定spark.memory.useLegacyMode来手动启用,因此在这里只对之后的进行论述。
Spark 内存布局
如下图所示,Spark 的堆内存空间可以分为 Spark 托管区、用户区和保留区三块。

其中保留区占 300MB,是固定的。托管区的大小由spark.memory.fraction节制,而1 - spark.memory.fraction的部分用户区。这个值越小,就越容易 Spill 或者 Cache evict。这个设置的用途是将 internal metadata、user data structures 区分开来。从而减少对稀疏的或者不常出现的大对象的大小的不准确估计造成的影响(限定词有点多,是翻译的注释、、、)。默认spark.memory.fraction是 0.6。
// package.scala
private[spark] val MEMORY_FRACTION = ConfigBuilder("spark.memory.fraction")
.doc("...").doubleConf.createWithDefault(0.6)
Spark 的托管区又分为 Execution 和 Storage 两个部分。其中 Storage 主要用来缓存 RDD、Broadcast 之类的对象,Execution 被用来存 Mapside 的 Shuffle 数据。
Storage 和 Execution 共享的内存,spark.storage.storageFraction(现在应该已经改成了spark.memory.storageFraction)表示对 eviction 免疫的 Storage 部分的大小,它的值越大,Execution 内存就越小,Task 就越容易 Spill。反之,Cache 就越容易被 evict。默认spark.memory.storageFraction是 0.5。
// package.scala
private[spark] val MEMORY_STORAGE_FRACTION = ConfigBuilder("spark.memory.storageFraction")
.doc("...").doubleConf.checkValue(v => v >= 0.0 && v < 1.0, "Storage fraction must be in [0,1)").createWithDefault(0.5)
Storage 可以借用任意多的 Execution 内存,直到 Execution 重新要回。此时被 Cache 的块会被从内存中 evict 掉(具体如何 evict,根据每个 Block 的存储级别)。Execution 也可以借用任意多的 Storage 的,但是 Execution 的借用不能被 Storage 驱逐,原因是因为实现起来很复杂。我们在稍后将看到,Spark 没有一个统一的资源分配的入口。
除了堆内内存,Spark 还可以使用堆外内存。
MemoryManager
Spark 中负责文件管理的类是MemoryManager,它是一个抽象类,被SparkEnv持有。在 1.6 版本后引入的UnifiedMemoryManager是它的一个实现。
// SparkEnv.scala
val memoryManager: MemoryManager = UnifiedMemoryManager(conf, numUsableCores)
UnifiedMemoryManager实现了诸如acquireExecutionMemory等方法来分配内存。通过在acquireExecutionMemory时传入一个MemoryMode可以告知是从堆内请求还是从堆外请求。需要注意的是,这类的函数并不像malloc一样直接去请求一段内存,并返回内存的地址,而是全局去维护每个 Task 所使用的内存大小。每一个 Task 在申请内存(new 对象)之前都会去检查一下自己有没有超标,否则就去 Spill。也就是说MemoryManager实际上是一个外挂式的内存管理系统,它不实际上托管内存,整个内存还是由 JVM 管理的。
对 Task 的 Execution 内存使用进行跟踪的这个机制被实现ExecutionMemoryPool中,如下面的代码所示。
// ExecutionMemoryPool.scala
// 保存每一个Task所占用的内存大小
private val memoryForTask = new mutable.HashMap[Long, Long]( "Long, Long")
当然,有ExecutionMemoryPool就也有StorageMemoryPool,他们都不出所料继承了MemoryPool。而以上这些 Pool 最后都被MemoryManager所持有。
// MemoryManager.scala
@GuardedBy("this")
protected val onHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.ON_HEAP)
@GuardedBy("this")
protected val offHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.OFF_HEAP)
@GuardedBy("this")
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP)
@GuardedBy("this")
protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.OFF_HEAP)
请求内存的流程
我们知道,在 Shuffle 操作中有两个内存使用大户ExecutorSorter和ExternalAppendOnlyMap,都继承了Spillable,从而实现了在内存不足时进行 Spill。我们查看对应的maybeSpill方法,它调用了自己父类MemoryConsumer中的acquireExecutionMemory方法。
由于从代码注释上看似乎MemoryConsumer包括它引用到的TaskMemoryManager类都与 Tungsten 有关,所以我们将在稍后进行研究。目前只是列明调用过程,因为如果其中涉及要向 Spark 托管内存请求分配,最终调用的还是UnifiedMemoryManager中的对应方法。
// Spillable.scala
// 在maybeSpill方法中
val granted = acquireMemory(amountToRequest)
// MemoryConsumer.scala
public long acquireMemory(long size) {
long granted = taskMemoryManager.acquireExecutionMemory(size, this);
used += granted;
return granted;
}
// TaskMemoryManager.java
public long acquireExecutionMemory(long required, MemoryConsumer consumer) {
assert(required >= 0);
assert(consumer != null);
MemoryMode mode = consumer.getMode();
synchronized (this) {
long got = memoryManager.acquireExecutionMemory(required, taskAttemptId, mode);
...
// Executor.scala
// TaskMemoryManager中的memoryManager,其实就是一个UnifiedMemoryManager
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
下面,我们来看acquireExecutionMemory的详细实现。它前面会首先根据memoryMode选择使用的MemoryPool,是堆内的,还是堆外的。然后它会有个函数maybeGrowExecutionPool,用来处理在需要的情况下从 Storage 部分挤占一些内存回来。我们可以在稍后详看这个方法。现在,我们发现acquireExecutionMemory会往对应的MemoryPool发一个调用acquireMemory。
// UnifiedMemoryManager.scala
override private[memory] def acquireExecutionMemory(
...
// 实际上是一个ExecutionMemoryPool
executionPool.acquireMemory(
numBytes, taskAttemptId, maybeGrowExecutionPool, () => computeMaxExecutionPoolSize)
}
// MemoryManager.scala
@GuardedBy("this")
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP)
由于我们讨论的场景就是请求堆内的执行内存,所以就进入ExecutionMemoryPool.scala查看相关代码。在 Spark 中,会尝试保证每个 Task 能够得到合理份额的内存,而不是让某些 Task 的内存持续增大到一定的数量,然后导致其他人持续地 Spill 到 Disk。
如果有 N 个任务,那么保证每个 Task 在 Spill 前可以获得至少1 / 2N的内存,并且最多只能获得1 / N。因为N是持续变化的,所以我们需要跟踪活跃 Task 集合,并且持续在等待 Task 集合中更新1 / 2N和1 / N的值。这个是借助于同步机制实现的,在 1.6 之前,是由ShuffleMemoryManager来仲裁的。
// ExecutionMemoryPool.scala
// 保存每一个Task所占用的内存大小
private val memoryForTask = new mutable.HashMap[Long, Long]( "Long, Long")
private[memory] def acquireMemory(
numBytes: Long,
taskAttemptId: Long,
maybeGrowPool: Long => Unit = (additionalSpaceNeeded: Long) => Unit,
computeMaxPoolSize: () => Long = () => poolSize): Long = lock.synchronized {
assert(numBytes > 0, s"invalid number of bytes requested: $numBytes")
// TODO: clean up this clunky method signature
// 如果我们没有Track到这个Task,那么就加到memoryForTask
if (!memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) = 0L
// 通知wait集合中的Task更新自己的numTasks
lock.notifyAll()
}
// TODO: simplify this to limit each task to its own slot
// 尝试寻找,直到要么我们确定我们不愿意给它内存(因为超过1/N)了,
// 或者我们有足够的内存提供。注意我们保证每个Task的1/2N的底线
while (true) {
val numActiveTasks = memoryForTask.keys.size
val curMem = memoryForTask(taskAttemptId)
// 在每一次迭代中,首先尝试从Storage借用的内存中拿回部分内存。
// 这是必要的,否则可能发生竞态,此时新的Storage Block会再把这个Task需要的执行内存拿回来。
maybeGrowPool(numBytes - memoryFree)
// maxPoolSize是内存池扩容之后可能的最大大小。
// 通过这个值,可以计算所谓的1/N和1/2N具体有多大。在计算时必须考虑可能被释放的内存(例如evicting cached blocks),否则就会导致SPARK-12155的问题
val maxPoolSize = computeMaxPoolSize()
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
// 最多再给这么多内存
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
// 实际上能给这么多内存
val toGrant = math.min(maxToGrant, memoryFree)
// 虽然我们尝试让每个Task尽可能得到1/2N的内存,
// 但由于Task数量是动态变化的,可能在N增长前,老的Task就把内存吃完了
// 所以如果我们给不了这么多内存的话,就让它睡在wait上面
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free")
lock.wait()
} else {
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
}
0L // Never reached
}
Tungsten 内存管理机制
Tungsten 不依赖于 Java 对象,所以堆内和堆外的内存分配都可以支持。序列化时间相比原生的要加快很多。其优化主要包含三点:
Memory Management and Binary Processing
Cache-aware computation
Code generation
这个是为了解决在 Spark 2.0 之前 SparkSQL 使用的Volcano中大量的链式next()导致的性能(虚函数等)问题。
在内存管理部分,能看到诸如TaskMemoryManager.java的文件;在稍后的 Shuffle 部分,能看到诸如UnsafeWriter.java的文件。这些 Java 文件在实现上就有对 Tungsten 的使用,因为用到了 sun.misc.Unsafe 的 API,所以使用 Tungsten 的 shuffle 又叫 Unsafe shuffle。
在MemoryManager中持有了 Tungsten 内存管理机制的核心类tungstenMemoryAllocator: MemoryAllocator。并设置了tungstenMemoryMode指示其分配内存的默认位置,如果MEMORY_OFFHEAP_ENABLED是打开的且MEMORY_OFFHEAP_SIZE是大于 0 的,那么默认使用堆外内存。
TaskMemoryManager
TaskMemoryManager这个对象被用来管理一个 Task 的堆内和对外内存分配,因此它能够调度一个 Task 中各个组件的内存使用情况。当组件需要使用TaskMemoryManager提供的内存时,他们需要继承一个MemoryConsumer类,以便向TaskMemoryManager请求内存。TaskMemoryManager中集成了普通的内存分配机制和 Tungsten 内存分配机制。
普通分配 acquireExecutionMemory
我们跟踪TaskMemoryManager.acquireExecutionMemory相关代码,它先尝试从MemoryManager直接请求内存:
// TaskMemoryManager.scala
public long acquireExecutionMemory(long required, MemoryConsumer consumer) {
assert(required >= 0);
assert(consumer != null);
MemoryMode mode = consumer.getMode();
// 如果我们在分配堆外内存的页,并且受到一个对堆内内存的请求,
// 那么没必要去Spill,因为怎么说也只是Spill的堆外内存。
// 不过现在改这个风险很大。。。。
synchronized (this) {
long got = memoryManager.acquireExecutionMemory(required, taskAttemptId, mode);
如果请求不到,那么先尝试让同一个TaskMemoryManager上的其他的 Consumer Spill,以减少 Spill 频率,从而减少 Spill 出来的小文件数量。主要是根据每个 Consumer 的内存使用排个序,从而避免重复对同一个 Consumer 进行 Spill,导致产生很多小文件。
...
if (got < required) {
TreeMap> sortedConsumers = new TreeMap<>();
for (MemoryConsumer c: consumers) {
if (c != consumer && c.getUsed() > 0 && c.getMode() == mode) {
long key = c.getUsed();
List list =
sortedConsumers.computeIfAbsent(key, k -> new ArrayList<>(1));
list.add(c);
}
}
...
现在,我们对排序得到的一系列sortedConsumers进行 spill,一旦成功释放出内存,就立刻向 MemoryManager 去请求这些内存,相关代码没啥可看的,故省略。如果内存还是不够,就 Spill 自己,如果成功了,就向 MemoryManager 请求内存。
...
// call spill() on itself
if (got < required) {
try {
long released = consumer.spill(required - got, consumer);
if (released > 0) {
logger.debug("Task {} released {} from itself ({})", taskAttemptId,
Utils.bytesToString(released), consumer);
got += memoryManager.acquireExecutionMemory(required - got, taskAttemptId, mode);
}
} catch (ClosedByInterruptException e) {
...
}
}
consumers.add(consumer);
logger.debug("Task {} acquired {} for {}", taskAttemptId, Utils.bytesToString(got), consumer);
return got;
}
}
Tungsten 分配 allocatePage
TaskMemoryManager还有个allocatePage方法,用来获得MemoryBlock,这个是通过 Tungsten 机制分配的。TaskMemoryManager使用了类似操作系统中分页的机制来操控内存。每个“页”,也就是MemoryBlock对象,维护了一段堆内或者堆外的内存。页的总数由PAGE_NUMBER_BITS来决定,即对于一个 64 位的地址,高PAGE_NUMBER_BITS(默认 13)位表示一个页,而后面的位表示在页内的偏移。当然,如果是堆外内存,那么这个 64 位就直接是内存地址了。有关使用分页机制的原因在TaskMemoryManager.java有介绍,我暂时没看懂。
需要注意的是,即使使用 Tungsten 分配,仍然不能绕开UnifiedMemoryManager机制的管理,所以我们看到在allocatePage方法中先要通过acquireExecutionMemory方法注册,请求到逻辑内存之后,再通过下面的方法请求物理内存
// TaskMemoryManager.scala
long acquired = acquireExecutionMemory(size, consumer);
if (acquired <= 0) {
return null;
}
page = memoryManager.tungstenMemoryAllocator().allocate(acquired);
Spark Job 执行流程分析
Job 阶段
下面我们通过一个 RDD 上的 Action 操作 count,查看 Spark 的 Job 是如何运行和调度的。特别注意的是,在 SparkSQL 中,Action 操作有不同的执行流程,所以宜对比着看。count通过全局的SparkContext.runJob启动一个 Job,这个函数转而调用DAGScheduler.runJob。Utils.getIteratorSize实际上就是遍历一遍迭代器,以便统计 count。
// RDD.scala
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
// Utils.scala
def getIteratorSize(iterator: Iterator[_]): Long = {
var count = 0L
while (iterator.hasNext) {
count += 1L
iterator.next()
}
count
}
在参数列表里面的下划线_的作用是将方法转为函数,Scala 中方法和函数之间有一些区别,在此不详细讨论。
下面查看runJob函数。比较有趣的是clean函数,它调用ClosureCleaner.clean方法,这个方法用来清理$outer域中未被引用的变量。因为我们要将闭包func序列化,并从 Driver 发送到 Executor 上面。序列化闭包的过程就是为每一个闭包生成一个可序列化类,在生成时,会将这个闭包所引用的外部对象也序列化。容易发现,如果我们为了使用外部对象的某些字段,而序列化整个对象,那么开销是很大的,因此通过clean来清除不需要的部分以减少序列化开销。
此外,getCallSite用来生成诸如s"$lastSparkMethod at $firstUserFile:$firstUserLine"这样的字符串,它实际上会回溯调用栈,找到第一个不是在 Spark 包中的函数,即$lastSparkMethod,它是导致一个 RDD 创建的函数,比如各种 Transform 操作、sc.parallelize等。
// SparkContext.scala
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
// CheckPoint机制
rdd.doCheckpoint()
}
private[spark] def clean[F <: AnyRef](f: F, checkSerializable: Boolean = true "spark] def clean[F <: AnyRef"): F = {
ClosureCleaner.clean(f, checkSerializable)
f
}
我们发现,传入的 func 只接受一个Iterator[_]参数,但是其形参声明却是接受TaskContext和Iterator[T]两个参数。这是为什么呢?这是因为runJob有不少重载函数,例如下面的这个
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int]): Array[U] = {
val cleanedFunc = clean(func)
runJob(rdd, (ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it), partitions)
}
下面我们查看DAGScheduler.runJob函数,它实际上就是调用submitJob,然后等待 Job 执行的结果。由于 Spark 的DAGScheduler是基于事件循环的,它拥有一个DAGSchedulerEventProcessLoop类型的变量eventProcessLoop,不同的对象向它post事件,然后在它的onReceive循环中会依次对这些事件调用处理函数。
我们需要注意的是partitions不同于我们传入的rdd.partitions,前者是一个Array[Int],后者是一个Array[Partition]。并且在逻辑意义上,前者表示需要计算的 partition,对于如 first 之类的 Action 操作来说,它只是 rdd 的所有 partition 的一个子集,我们将在稍后的submitMissingTasks函数中继续看到这一点。
def runJob[T, U](... "T, U"): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// 下面就是在等了
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
def submitJob[T, U](
rdd: RDD[T], // target RDD to run tasks on,就是被执行count的RDD
func: (TaskContext, Iterator[T]) => U, // 在RDD每一个partition上需要跑的函数
partitions: Seq[Int],
callSite: CallSite, // 被调用的位置
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 检查是否在一个不存在的分区上创建一个Task
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException( "Attempting to access a non-existent partition: " + p + ". " + "Total number of partitions: " + maxPartitions)}
// jobId是从后往前递增的
val jobId = nextJobId.getAndIncrement()
if (partitions.isEmpty) {
val time = clock.getTimeMillis()
// listenerBus是一个LiveListenerBus对象,从DAGScheduler构造时得到,用来做event log
// SparkListenerJobStart定义在SparkListener.scala文件中
listenerBus.post(SparkListenerJobStart(jobId, time, Seq[StageInfo]( "StageInfo"), SerializationUtils.clone(properties)))
listenerBus.post(SparkListenerJobEnd(jobId, time, JobSucceeded))
// 如果partitions是空的,那么就直接返回
return new JobWaiter[U](this, jobId, 0, resultHandler "U")
}
assert(partitions.nonEmpty)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter[U](this, jobId, partitions.size, resultHandler "U")
// 我们向eventProcessLoop提交一个JobSubmitted事件
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
// DAGSchedulerEvent.scala
private[scheduler] case class JobSubmitted(
jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties = null)
extends DAGSchedulerEvent
下面我们具体看看对JobSubmitted的响应
// DAGScheduler.scala
private[scheduler] def handleJobSubmitted(...) {
var finalStage: ResultStage = null
// 首先我们尝试创建一个`finalStage: ResultStage`,这是整个Job的最后一个Stage。
try {
// func: (TaskContext, Iterator[_]) => _
// 下面的语句是可能抛BarrierJobSlotsNumberCheckFailed或者其他异常的,
// 例如一个HadoopRDD所依赖的HDFS文件被删除了
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
...
// DAGScheduler.scala
private def createResultStage(...): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
这里createResultStage所返回的ResultStage继承了Stage类。Stage类有个rdd参数,对ResultStage而言就是finalRDD,对ShuffleMapStage而言就是ShuffleDependency.rdd
// DAGScheduler.scala
def createShuffleMapStage[K, V, C](
shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
...
下面我们来看看checkBarrierStageWithNumSlots这个函数,因为它会抛出BarrierJobSlotsNumberCheckFailed这个异常,被handleJobSubmitted捕获。这个函数主要是为了检测是否有足够的 slots 去运行所有的 barrier task。屏障调度器是 Spark 为了支持深度学习在 2.4.0 版本所引入的一个特性。它要求在 barrier stage 中同时启动所有的 Task,当任意的 task 执行失败的时候,总是重启整个 barrier stage。这么麻烦是因为 Spark 希望能够在 Task 中提供一个 barrier 以供显式同步。
// DAGScheduler.scala
private def checkBarrierStageWithNumSlots(rdd: RDD[_]): Unit = {
val numPartitions = rdd.getNumPartitions
val maxNumConcurrentTasks = sc.maxNumConcurrentTasks
if (rdd.isBarrier() && numPartitions > maxNumConcurrentTasks) {
throw new BarrierJobSlotsNumberCheckFailed(numPartitions, maxNumConcurrentTasks)
}
}
// DAGScheduler.scala
...
case e: BarrierJobSlotsNumberCheckFailed =>
// If jobId doesn't exist in the map, Scala coverts its value null to 0: Int automatically.
// barrierJobIdToNumTasksCheckFailures是一个ConcurrentHashMap,表示对每个BarrierJob上失败的Task数量
val numCheckFailures = barrierJobIdToNumTasksCheckFailures.compute(jobId,
(_: Int, value: Int) => value + 1)
...
if (numCheckFailures <= maxFailureNumTasksCheck) {
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(JobSubmitted(jobId, finalRDD, func,
partitions, callSite, listener, properties))
},
timeIntervalNumTasksCheck,
TimeUnit.SECONDS
)
return
} else {
// Job failed, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
listener.jobFailed(e)
return
}
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// Job submitted, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
...
下面开始创建 Job。ActiveJob表示在DAGScheduler里面运行的一个 Job。
Job 只负责向“叶子”Stage 要结果,而之前 Stage 的运行是由DAGScheduler来调度的。这是因为若干 Job 可能共用同一个 Stage 的计算结果,我这样说的根据是在 Stage 类的定义中的jobIds字段是一个HashSet,也就是说它可以属于多个 Job。所以将某个 Stage 强行归属到某个 Job 是不符合 Spark 设计逻辑的。
// DAGScheduler.scala
...
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
// 在这里会打印四条日志,这个可以被用来在Spark.log里面定位事件
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
...
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 从最后一个stage开始调用submitStage
submitStage(finalStage)
}
Stage 阶段
Stage 是如何划分的呢?又是如何计算 Stage 之间的依赖的?我们继续查看submitStage这个函数,对于一个 Stage,首先调用getMissingParentStages看看它的父 Stage 能不能直接用,也就是说这个 Stage 的 rdd 所依赖的所有父 RDD 能不能直接用,如果不行的话,就要先算父 Stage 的。在前面的论述里,我们知道,若干 Job 可能共用同一个 Stage 的计算结果,而不同的 Stage 也可能依赖同一个 RDD。
private def submitStage(stage: Stage) {
// 找到这个stage所属的job
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 如果依赖之前的Stage,先列出来,并且按照id排序
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
// 运行这个Stage
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
// 先提交所有的parent stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
下面具体查看getMissingParentStages这个函数,可以看到,Stage 的计算链是以最后一个 RDD 为树根逆着向上遍历得到的,而这个链条的终点要么是一个ShuffleDependency,要么是一个所有分区都被缓存了的 RDD。
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ListBuffer[RDD[_]]
// 这里是个**DFS**,栈是手动维护的,主要是为了防止爆栈
waitingForVisit += stage.rdd
def visit(rdd: RDD[_]): Unit = {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
// 如果这个RDD有没有被缓存的Partition,那么它就需要被计算
for (dep <- rdd.dependencies) {
// 我们检查这个RDD的所有依赖
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
// 我们发现一个宽依赖,因此我们创建一个新的Shuffle Stage,并加入到missing中(如果不存在)
// 由于是宽依赖,所以我们不需要向上找了
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
// 如果是一个窄依赖,就加入到waitingForVisit中
// prepend是在头部加,+=是在尾部加
waitingForVisit.prepend(narrowDep.rdd)
}
}
}
}
}
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.remove(0))
}
missing.toList
}
Task 阶段
下面是重头戏submitMissingTasks,这个方法负责生成 TaskSet,并且将它提交给 TaskScheduler 低层调度器。
partitionsToCompute计算有哪些分区是待计算的。根据 Stage 类型的不同,findMissingPartitions的计算方法也不同。
// DAGScheduler.scala
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
...
// ResultStage.scala
override def findMissingPartitions(): Seq[Int] = {
val job = activeJob.get
(0 until job.numPartitions).filter(id => !job.finished(id))
}
// ActiveJob.scala
val numPartitions = finalStage match {
// 对于ResultStage,不一定得到当前rdd的所有分区,例如first()和lookup()的Action,
// 因此这里是r.partitions而不是r.rdd.partitions
case r: ResultStage => r.partitions.length
case m: ShuffleMapStage => m.rdd.partitions.length
}
// ShuffleMapStage.scala
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions)
}
// MapOutputTrackerMaster.scala
def findMissingPartitions(shuffleId: Int): Option[Seq[Int]] = {
shuffleStatuses.get(shuffleId).map(_.findMissingPartitions())
}
这个outputCommitCoordinator是由SparkEnv维护的OutputCommitCoordinator对象,它决定到底谁有权利向输出写数据。在 Executor 上的请求会通过他持有的 Driver 的OutputCommitCoordinatorEndpoint的引用发送给 Driver 处理
// DAGScheduler.scala
...
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// 在检测Tasks是否serializable之前,就要SparkListenerStageSubmitted,
// 如果不能serializable,那就在这**之后**给一个SparkListenerStageCompleted
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
...
用getPreferredLocs计算每个分区的最佳计算位置,它实际上是调用getPreferredLocsInternal这个函数。这个函数是一个关于visit: HashSet[(RDD[_], Int)]的递归函数,visit 用(rdd, partition)元组唯一描述一个分区。getPreferredLocs的计算逻辑是这样的:
如果已经 visit 过了,就返回 Nil
如果是被 cached 的,通过
getCacheLocs返回 cache 的位置如果 RDD 有自己的偏好位置,例如输入 RDD,那么使用
rdd.preferredLocations返回它的偏好位置如果还没返回,但 RDD 有窄依赖,那么遍历它的所有依赖项,返回第一个具有位置偏好的依赖项的值
理论上,一个最优的位置选取应该尽可能靠近数据源以减少网络传输,但目前版本的 Spark 还没有实现
// DAGScheduler.scala
...
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
// 如果有非致命异常就创建一个新的Attempt,并且abortStage(这还不致命么)
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
...
下面,我们开始 attempt 这个 Stage,我们需要将 RDD 对象和依赖通过closureSerializer序列化成taskBinaryBytes,然后广播得到taskBinary。当广播变量过大时,会产生一条Broadcasting large task binary with size的 INFO。
// DAGScheduler.scala
...
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
// 如果没有Task要执行,实际上就是skip了,那么就没有Submission Time这个字段
if (partitionsToCompute.nonEmpty) {
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
}
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: 也许可以将`taskBinary`放到Stage里面以避免对它序列化多次。
// 一堆注释看不懂
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes and partitions are both effected by the checkpoint status. We need
// this synchronization in case another concurrent job is checkpointing this RDD, so we get a
// consistent view of both variables.
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
// 注意这里的stage.func已经被ClosureCleaner清理过了
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
...
// 广播
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
...
}
下面,我们根据 Stage 的类型生成 Task。
// DAGScheduler.scala
...
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
...
}
我们将生成的tasks包装成一个TaskSet,并且提交给taskScheduler。
// DAGScheduler.scala
...
if (tasks.nonEmpty) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
如果 tasks 是空的,说明任务就已经完成了,打上 DEBUG 日志,并且调用submitWaitingChildStages
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
stage match {
case stage: ShuffleMapStage =>
logDebug(s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})")
markMapStageJobsAsFinished(stage)
case stage : ResultStage =>
logDebug(s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})")
}
submitWaitingChildStages(stage)
}
}
Shuffle
Shuffle 机制是 Spark Core 的核心内容。在 Stage 和 Stage 之间,Spark 需要 Shuffle 数据。这个流程包含上一个 Stage 上的 Shuffle Write,中间的数据传输,以及下一个 Stage 的 Shuffle Read。如下图所示:

Shuffle 类操作常常发生在宽依赖的 RDD 之间,这类算子需要将多个节点上的数据拉取到同一节点上进行计算,其中存在大量磁盘 IO、序列化和网络传输开销,它们可以分为以下几点来讨论。
当 Spark 中的某个节点故障之后,常常需要重算 RDD 中的某几个分区。对于窄依赖而言,父 RDD 的一个分区只对应一个子 RDD 分区,因此丢失子 RDD 的分区,重算整个父 RDD 分区是必要的。而对于宽依赖而言,父 RDD 会被多个子 RDD 使用,而可能当前丢失的子 RDD 只使用了父 RDD 中的某几个分区的数据,而我们仍然要重新计算整个父 RDD,这造成了计算资源的浪费。
当使用 Aggregate 类(如groupByKey)或者 Join 类这种 Shuffle 算子时,如果选择的key上的数据是倾斜(skew)的,会导致部分节点上的负载增大。对于这种情况除了可以增加 Executor 的内存,还可以重新选择分区函数(例如在之前的 key 上加盐)来平衡分区。
Shuffle Read 操作容易产生 OOM,其原因是尽管在BlockStoreShuffleReader中会产生外部排序的resultIter,但在这之前,ExternalAppendOnlyMap先要从 BlockManager 拉取数据(k, v)到自己的currentMap中,如果这里的v很大,那么就会导致 Executor 的 OOM 问题。可以从PairRDDFunctions的文档中佐证这一点。在Dataset中并没有reduceByKey,原因可能与 Catalyst Optimizer 的优化有关,但考虑到groupByKey还是比较坑的,感觉这个举措并不明智。
Shuffle 考古
在 Spark0.8 版本前,Spark 只有 Hash Based Shuffle 的机制。在这种方式下,假定 Shuffle Write 阶段(有的也叫 Map 阶段)有W个 Task,在 Shuffle Read 阶段(有的也叫 Reduce 阶段)有R个 Task,那么就会产生W*R个文件。这样的坏处是对文件系统产生很大压力,并且 IO 也差(随机读写)。由于这些文件是先全量在内存里面构造,再 dump 到磁盘上,所以 Shuffle 在 Write 阶段就很可能 OOM。
为了解决这个问题,在 Spark 0.8.1 版本加入了 File Consolidation,以求将W个 Task 的输出尽可能合并。现在,Executor 上的每一个执行单位都生成自己独一份的文件。假定所有的 Executor 总共有C个核心,每个 Task 占用T个核心,那么总共有C/T个执行单位。考虑极端情况,如果C==T,那么任务实际上是串行的,所以写一个文件就行了。因此,最终会生成C/T*R个文件。
但这个版本仍然没有解决 OOM 的问题。虽然对于 reduce 这类操作,比如count,因为是来一个 combine 一个,所以只要你的 V 不是数组,也不想强行把结果 concat 成一个数组,一般都没有较大的内存问题。但是考虑如果我们执行groupByKey这样的操作,在 Read 阶段每个 Task 需要得到得到自己负责的 key 对应的所有 value,而我们现在每个 Task 得到的是若干很大的文件,这个文件里面的 key 是杂乱无章的。如果我们需要得到一个 key 对应的所有 value,那么我们就需要遍历这个文件,将 key 和对应的 value 全部存放在一个结构比如 HashMap 中,并进行合并。因此,我们必须保证这个 HashMap 足够大。既然如此,我们很容易想到一个基于外部排序的方案,我们为什么不能对 key 进行外排呢?确实在 Hadoop MapReduce 中会做归并排序,因此 Reducer 侧的数据按照 key 组织好的了。但 Spark 在这个版本没有这么做,并且 Spark 在下一个版本就这么做了。
在 Spark 0.9 版本之后,引入了ExternalAppendOnlyMap,通过这个结构,SparkShuffle 在 combine 的时候如果内存不够,就能 Spill 到磁盘,并在 Spill 的时候进行排序。当然,内存还是要能承载一个 KV 的,我们将在稍后的源码分析中深入研究这个问题。
终于在 Spark1.1 版本之后引入了 Sorted Based Shuffle。此时,Shuffle Write 阶段会按照 Partition ID 以及 key 对记录进行排序。同时将全部结果写到一个数据文件中,同时生成一个索引文件,Shuffle Read 的 Task 可以通过该索引文件获取相关的数据。
在 Spark 1.5,Tungsten内存管理机制成为了 Spark 的默认选项。如果关闭spark.sql.tungsten.enabled,Spark 将采用基于 Kryo 序列化的列式存储格式。
Shuffle Read 端源码分析
Shuffle Read 一般位于一个 Stage 的开始,这时候上一个 Stage 会给我们留下一个 ShuffledRDD。在它的compute方法中会首先取出shuffleManager: ShuffleManager。
ShuffleManager是一个 Trait,它的两个实现就是org.apache.spark.shuffle.hash.HashShuffleManager和org.apache.spark.shuffle.sort.SortShuffleManager
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
val metrics = context.taskMetrics().createTempShuffleReadMetrics()
SparkEnv.get.shuffleManager // 由SparkEnv维护的ShuffleManager
...
接着,我们调用shuffleManager.getReader方法返回一个BlockStoreShuffleReader,它用来读取[split.index, split.index + 1)这个区间内的 Shuffle 数据。接着,它会调用SparkEnv.get.mapOutputTracker的getMapSizesByExecutorId方法。
getMapSizesByExecutorId返回一个迭代器Iterator[(BlockManagerId, Seq[(BlockId, Long, Int)])],表示对于某个BlockManagerId,它所存储的 Shuffle Write 中间结果,包括BlockId、大小和 index。
具体实现上,这个方法首先从传入的dep.shuffleHandle中获得当前 Shuffle 过程的唯一标识shuffleId,然后它会从自己维护的shuffleStatuses中找到shuffleId对应的MapStatus,它应该有endPartition-startPartition这么多个。接着,对这些MapStatus,调用convertMapStatuses获得迭代器。在compute中,实际上就只取当前split这一个 Partition 的 Shuffle 元数据。
...
.getReader(dep.shuffleHandle, split.index, split.index + 1, context, metrics) // 返回一个BlockStoreShuffleReader
.read().asInstanceOf[Iterator[(K, C)]]
}
ShuffleManager通过调用BlockStoreShuffleReader.read返回一个迭代器Iterator[(K, C)]。在BlockStoreShuffleReader.read方法中,首先得到一个ShuffleBlockFetcherIterator
// BlockStoreShuffleReader.scala
override def read(): Iterator[Product2[K, C]] = {
val wrappedStreams = new ShuffleBlockFetcherIterator(
...
) // 返回一个ShuffleBlockFetcherIterator
.toCompletionIterator // 返回一个Iterator[(BlockId, InputStream)]
ShuffleBlockFetcherIterator用fetchUpToMaxBytes()和 fetchLocalBlocks()分别读取 remote 和 local 的 Block。在拉取远程数据的时候,会统计bytesInFlight、reqsInFlight等信息,并使用maxBytesInFlight和maxReqsInFlight节制。同时,为了允许 5 个并发同时拉取数据,还会设置targetRemoteRequestSize = math.max(maxBytesInFlight / 5, 1L)去请求每次拉取数据的最大大小。通过ShuffleBlockFetcherIterator.splitLocalRemoteBytes,现在改名叫partitionBlocksByFetchMode函数,可以将 blocks 分为 Local 和 Remote 的。关于两个函数的具体实现,将单独讨论。
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
// CompletionIterator相比普通的Iterator的区别就是在结束之后会调用一个completion函数
// CompletionIterator通过它伴生对象的apply方法创建,传入第二个参数即completionFunction
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter "(Any, Any)")
...
经过一系列转换,我们得到一个interruptibleIter。接下来,根据是否有 mapSideCombine 对它进行聚合。这里的dep来自于BaseShuffleHandle对象,它是一个ShuffleDependency。在前面 Spark 的任务调度中已经提到,ShuffleDependency就是宽依赖。
// BlockStoreShuffleReader.scala
...
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
这里的aggregator是Aggregator[K, V, C],这里的K、V和C与熟悉combineByKey的是一样的。需要注意的是,在 combine 的过程中借助了ExternalAppendOnlyMap,这是之前提到的在 Spark 0.9 中引入的重要特性。通过调用insertAll方法能够将interruptibleIter内部的数据添加到ExternalAppendOnlyMap中,并在之后更新 MemoryBytesSpilled、DiskBytesSpilled、PeakExecutionMemory 三个统计维度,这也是我们在 Event Log 中所看到的统计维度。
// Aggregator.scala
case class Aggregator[K, V, C] (
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C) {
def combineValuesByKey(
iter: Iterator[_ <: Product2[K, V]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, V, C](createCombiner, mergeValue, mergeCombiners "K, V, C")
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}
def combineCombinersByKey(
iter: Iterator[_ <: Product2[K, C]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, C, C](identity, mergeCombiners, mergeCombiners "K, C, C")
// 同上
}
/** Update task metrics after populating the external map. */
private def updateMetrics(context: TaskContext, map: ExternalAppendOnlyMap[_, _, _]): Unit = {
Option(context).foreach { c =>
c.taskMetrics().incMemoryBytesSpilled(map.memoryBytesSpilled)
c.taskMetrics().incDiskBytesSpilled(map.diskBytesSpilled)
c.taskMetrics().incPeakExecutionMemory(map.peakMemoryUsedBytes)
}
}
}
在获得 Aggregate 迭代器之后,最后一步,我们要进行排序,这时候就需要用到ExternalSorter这个对象。
// BlockStoreShuffleReader.scala
...
val resultIter = dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
val sorter = new ExternalSorter[K, C, C](context, ordering = Some(keyOrd "K, C, C"), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// Use completion callback to stop sorter if task was finished/cancelled.
context.addTaskCompletionListener[Unit](_ => {
sorter.stop()
})
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop( "Product2[K, C], Iterator[Product2[K, C]]"))
case None =>
aggregatedIter
}
ExternalAppendOnlyMap 和 AppendOnlyMap
我们查看ExternalAppendOnlyMap的实现。ExternalAppendOnlyMap拥有一个currentMap管理在内存中存储的键值对们。和一个DiskMapIterator的数组spilledMaps,表示 Spill 到磁盘上的键值对们。
@volatile private[collection] var currentMap = new SizeTrackingAppendOnlyMap[K, C]
private val spilledMaps = new ArrayBuffer[DiskMapIterator]
先来看currentMap,它是一个SizeTrackingAppendOnlyMap。这个东西实际上就是一个AppendOnlyMap,不过给它加上了统计数据大小的功能,主要是借助于SizeTracker中afterUpdate和resetSamples两个方法。我们知道非序列化对象在内存存储上是不连续的,我们需要通过遍历迭代器才能知道对象的具体大小,而这个开销是比较大的。因此,通过SizeTracker我们可以得到一个内存空间占用的估计值,从来用来判定是否需要 Spill。
下面,我们来看currentMap.insertAll这个方法
// AppendOnlyMap.scala
def insertAll(entries: Iterator[Product2[K, V]]): Unit = {
if (currentMap == null) {
throw new IllegalStateException(
"Cannot insert new elements into a map after calling iterator")
}
// 我们复用update函数,从而避免每一次都创建一个新的闭包(编程环境这么恶劣的么。。。)
var curEntry: Product2[K, V] = null
val update: (Boolean, C) => C = (hadVal, oldVal) => {
if (hadVal)
// 如果不是第一个V,就merge
// mergeValue: (C, V) => C,
mergeValue(oldVal, curEntry._2)
else
// 如果是第一个V,就新建一个C
// createCombiner: V => C,
createCombiner(curEntry._2)
}
while (entries.hasNext) {
curEntry = entries.next()
val estimatedSize = currentMap.estimateSize()
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
if (maybeSpill(currentMap, estimatedSize)) {
// 如果发生了Spill,就重新创建一个currentMap
currentMap = new SizeTrackingAppendOnlyMap[K, C]
}
// key: K, updateFunc: (Boolean, C) => C
currentMap.changeValue(curEntry._1, update)
addElementsRead()
}
}
可以看出,在insertAll中主要做了两件事情:
遍历
curEntry <- entries,并通过传入的update函数进行 Combine 在内部存储上,AppendOnlyMap,包括后面将看到的一些其他 KV 容器,都倾向于将(K, V)对放到哈希表的相邻两个位置,这样的好处应该是避免访问时再进行一次跳转。下面的代码是
AppendOnlyMap.changeValue的实现,它接受一个updateFunc用来更新一个指定K的值。updateFunc接受第一个布尔值,用来表示是不是首次出现这个 key。我们需要注意,AppendOnlyMap里面 null 是一个合法的键,但同时null又作为它里面的哈希表的默认填充,因此它里面有个对null特殊处理的过程。// AppendOnlyMap.scala // 这里的nullValue和haveNullValue是用来单独处理k为null的情况的,下面会详细说明 private var haveNullValue = false // 有关null.asInstanceOf[V]的花里胡哨的语法,详见 https://stackoverflow.com/questions/10749010/if-an-int-cant-be-null-what-does-null-asinstanceofint-mean private var nullValue: V = null.asInstanceOf[V] def changeValue(key: K, updateFunc: (Boolean, V) => V): V = { // updateFunc就是从insertAll传入的update assert(!destroyed, destructionMessage) val k = key.asInstanceOf[AnyRef] if (k.eq(null)) { if (!haveNullValue) { // 如果这时候还没有null的这个key,就新创建一个 incrementSize() } nullValue = updateFunc(haveNullValue, nullValue) haveNullValue = true return nullValue } var pos = rehash(k.hashCode) & mask var i = 1 while (true) { // 乘以2的原因是他按照K1 V1 K2 V2这样放的 val curKey = data(2 * pos) if (curKey.eq(null)) { // 如果对应的key不存在,就新创建一个 // 这也是为什么前面要单独处理null的原因,这里的null被用来做placeholder了 // 可以看到,第一个参数传的false,第二个是花里胡哨的null val newValue = updateFunc(false, null.asInstanceOf[V]) data(2 * pos) = k data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] incrementSize() return newValue } else if (k.eq(curKey) || k.equals(curKey)) { // 又是从Java继承下来的花里胡哨的特性 val newValue = updateFunc(true, data(2 * pos + 1).asInstanceOf[V]) data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] return newValue } else { // 再散列 val delta = i pos = (pos + delta) & mask i += 1 } } null.asInstanceOf[V] // Never reached but needed to keep compiler happy }估计
currentMap的当前大小,并调用currentMap.maybeSpill向磁盘 Spill。我们将在单独的章节论述SizeTracker如何估计集合大小,先看具体的 Spill 过程,可以梳理出shouldSpill==true的情况
1、elementsRead % 32 == 0
2、currentMemory >= myMemoryThreshold
3、 通过acquireMemory请求的内存不足以扩展到2 * currentMemory的大小,关于这一步骤已经在内存管理部分详细说明了,在这就不详细说了// Spillable.scala protected def maybeSpill(collection: C, currentMemory: Long): Boolean = { var shouldSpill = false if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { val amountToRequest = 2 * currentMemory - myMemoryThreshold // 调用对应MemoryConsumer的acquireMemory方法 val granted = acquireMemory(amountToRequest) myMemoryThreshold += granted shouldSpill = currentMemory >= myMemoryThreshold } shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold ... // MemoryConsumer.scala public long acquireMemory(long size) { long granted = taskMemoryManager.acquireExecutionMemory(size, this); used += granted; return granted; }下面就是真正 Spill 的过程了,其实就是调用 spill 函数。注意
_memoryBytesSpilled就是我们在 Event Log 里面看到的 Memory Spill 的统计量,他表示在 Spill 之后我们能够释放多少内存:// Spillable.scala ... // Actually spill if (shouldSpill) { _spillCount += 1 // 统计Spill的次数 logSpillage(currentMemory) spill(collection) _elementsRead = 0 // 重置强制Spill计数器_elementsRead _memoryBytesSpilled += currentMemory releaseMemory() } shouldSpill }
在insertAll之后,会返回一个迭代器,我们查看相关方法。可以发现如果spilledMaps都是空的,也就是没有 Spill 的话,就返回内存里面currentMap的iterator,否则就返回一个ExternalIterator。
对于第一种情况,会用SpillableIterator包裹一下。这个类在很多地方有定义,包括ExternalAppendOnlyMap.scala,ExternalSorter.scala里面。在当前使用的实现中,它实际上就是封装了一下Iterator,使得能够 spill,转换成CompletionIterator等。
对于第二种情况,ExternalIterator比较有趣,将在稍后进行讨论。
// ExternalAppendOnlyMap.scala
override def iterator: Iterator[(K, C)] = {
...
if (spilledMaps.isEmpty) {
// 如果没有发生Spill
destructiveIterator(currentMap.iterator)
} else {
// 如果发生了Spill
new ExternalIterator()
}
}
def destructiveIterator(inMemoryIterator: Iterator[(K, C)]): Iterator[(K, C)] = {
readingIterator = new SpillableIterator(inMemoryIterator)
readingIterator.toCompletionIterator
}
而currentMap.iterator实际上就是一个朴素无华的迭代器的实现。
// AppendOnlyMap.scala
def nextValue(): (K, V) = {
if (pos == -1) { // Treat position -1 as looking at the null value
if (haveNullValue) {
return (null.asInstanceOf[K], nullValue)
}
pos += 1
}
while (pos < capacity) {
if (!data(2 * pos).eq(null)) {
return (data(2 * pos).asInstanceOf[K], data(2 * pos + 1).asInstanceOf[V])
}
pos += 1
}
null
}
ExternalSorter
ExternalSorter的作用是对输入的(K, V)进行排序,以产生新的(K, C)对,排序过程中可选择进行 combine,否则输出的C == V。需要注意的是ExternalSorter不仅被用在 Shuffle Read 端,也被用在了 Shuffle Write 端,所以在后面会提到 Map-side combine 的概念。ExternalSorter具有如下的参数,在给定ordering之后,ExternalSorter就会按照它来排序。在 Spark 源码中建议如果希望进行 Map-side combining 的话,就指定ordering,否则就可以设置ordering为null
private[spark] class ExternalSorter[K, V, C](
context: TaskContext,
aggregator: Option[Aggregator[K, V, C]] = None,
partitioner: Option[Partitioner] = None,
ordering: Option[Ordering[K]] = None,
serializer: Serializer = SparkEnv.get.serializer)
extends Spillable[WritablePartitionedPairCollection[K, C]](context.taskMemoryManager( "WritablePartitionedPairCollection[K, C]"))
由于ExternalSorter支持有 combine 和没有 combine 的两种模式,因此对应设置了两个对象。map = new PartitionedAppendOnlyMap[K, C],以及buffer = new PartitionedPairBuffer[K, C]。其中,PartitionedAppendOnlyMap就是一个SizeTrackingAppendOnlyMap。PartitionedPairBuffer则继承了WritablePartitionedPairCollection,由于不需要按照 key 进行 combine,所以它的实现接近于一个 Array。
ExternalSorter.insertAll方法和之前看到的ExternalAppendOnlyMap方法是大差不差的,他也会对可以聚合的特征进行聚合,并且 TODO 上还说如果聚合之后的 reduction factor 不够明显,就停止聚合。
相比之前的 aggregator,ExternalSorter不仅能 aggregate,还能 sort。ExternalSorter在 Shuffle Read 和 Write 都有使用,而ExternalAppendOnlyMap只有在 Shuffle Read 中使用。所以为啥不直接搞一个ExternalSorter而是还要在前面垫一个ExternalAppendOnlyMap呢?为此,我们总结比较一下这两者:
首先,在insertAll时,ExternalAppendOnlyMap是一定要做 combine 的,而ExternalSorter可以选择是否做 combine,为此还有PartitionedAppendOnlyMap和PartitionedPairBuffer两种数据结构。
其次,在做排序时,ExternalAppendOnlyMap默认对内存中的对象不进行排序,只有当要 Spill 的时候才会返回AppendOnlyMap.destructiveSortedIterator的方式将内存里面的东西有序写入磁盘。在返回迭代器时,如果没有发生 Spill,那么ExternalAppendOnlyMap返回没有经过排序的currentMap,否则才通过ExternalIterator进行排序。而对ExternalSorter而言排序与否在于有没有指定ordering。如果进行排序的话,那么它会首先考虑 Partition,再考虑 Key。
ExternalIterator
下面我们来看ExternalAppendOnlyMap中ExternalIterator的实现。它是一个典型的外部排序的实现,有一个 PQ 用来 merge。不过这次的迭代器换成了destructiveSortedIterator,也就是我们都是排序的了。这个道理也是显而易见的,不 sort 一下,我们怎么和硬盘上的数据做聚合呢?
// ExternalAppendOnlyMap.scala
val mergeHeap = new mutable.PriorityQueue[StreamBuffer]
val sortedMap = destructiveIterator(currentMap.destructiveSortedIterator(keyComparator))
// 我们得到一个Array的迭代器
val inputStreams = (Seq(sortedMap) ++ spilledMaps).map(it => it.buffered)
inputStreams.foreach { it =>
val kcPairs = new ArrayBuffer[(K, C)]
// 读完所有具有所有相同hash(key)的序列,并创建一个StreamBuffer
// 需要注意的是,由于哈希碰撞的原因,里面可能有多个key
readNextHashCode(it, kcPairs)
if (kcPairs.length > 0) {
mergeHeap.enqueue(new StreamBuffer(it, kcPairs))
}
}
我们先来看看destructiveSortedIterator的实现
// AppendOnlyMap.scala
def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = {
destroyed = true
var keyIndex, newIndex = 0
// 下面这个循环将哈希表里面散乱的KV对压缩到最前面
while (keyIndex < capacity) {
if (data(2 * keyIndex) != null) {
data(2 * newIndex) = data(2 * keyIndex)
data(2 * newIndex + 1) = data(2 * keyIndex + 1)
newIndex += 1
}
keyIndex += 1
}
assert(curSize == newIndex + (if (haveNullValue) 1 else 0))
new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator)
// 这下面和前面实现大差不差,就省略了
new Iterator[(K, V)] {
...
}
}
下面我们来看看实现的next()接口函数,它是外部排序中的一个典型的归并过程。我们需要注意的是minBuffer是一个StreamBuffer,维护一个hash(K), V的ArrayBuffer,类似H1 V1 H1 V2 H2 V3这样的序列,而不是我们想的(K, V)流。因此其中是可能有哈希碰撞的。我们从mergeHeap中dequeue出来的StreamBuffer是当前hash(K)最小的所有K的集合。
override def next(): (K, C) = {
if (mergeHeap.isEmpty) {
// 如果堆是空的,就再见了
throw new NoSuchElementException
}
// Select a key from the StreamBuffer that holds the lowest key hash
// mergeHeap选择所有StreamBuffer中最小hash的,作为minBuffer
val minBuffer = mergeHeap.dequeue()
// minPairs是一个ArrayBuffer[T],表示这个StreamBuffer维护的所有KV对
val minPairs = minBuffer.pairs
val minHash = minBuffer.minKeyHash
// 从一个ArrayBuffer[T]中移出Index为0的项目
val minPair = removeFromBuffer(minPairs, 0)
// 得到非哈希的 (minKey, minCombiner)
val minKey = minPair._1
var minCombiner = minPair._2
assert(hashKey(minPair) == minHash)
// For all other streams that may have this key (i.e. have the same minimum key hash),
// merge in the corresponding value (if any) from that stream
val mergedBuffers = ArrayBuffer[StreamBuffer](minBuffer "StreamBuffer")
while (mergeHeap.nonEmpty && mergeHeap.head.minKeyHash == minHash) {
val newBuffer = mergeHeap.dequeue()
// 如果newBuffer的key和minKey相等的话(考虑哈希碰撞),就合并
minCombiner = mergeIfKeyExists(minKey, minCombiner, newBuffer)
mergedBuffers += newBuffer
}
// Repopulate each visited stream buffer and add it back to the queue if it is non-empty
mergedBuffers.foreach { buffer =>
if (buffer.isEmpty) {
readNextHashCode(buffer.iterator, buffer.pairs)
}
if (!buffer.isEmpty) {
mergeHeap.enqueue(buffer)
}
}
(minKey, minCombiner)
}
SizeTracker
首先在每次集合更新之后,会调用afterUpdate,当到达采样的 interval 之后,会takeSample。
// SizeTracker.scala
protected def afterUpdate(): Unit = {
numUpdates += 1
if (nextSampleNum == numUpdates) {
takeSample()
}
}
takeSample函数中第一句话就涉及多个对象,一个一个来看。
// SizeTracker.scala
private def takeSample(): Unit = {
samples.enqueue(Sample(SizeEstimator.estimate(this), numUpdates))
...
SizeEstimator.estimate的实现类似去做一个 state 队列上的 BFS。
private def estimate(obj: AnyRef, visited: IdentityHashMap[AnyRef, AnyRef]): Long = {
val state = new SearchState(visited)
state.enqueue(obj)
while (!state.isFinished) {
visitSingleObject(state.dequeue(), state)
}
state.size
}
visitSingleObject来具体做这个 BFS,会特殊处理 Array 类型。我们不处理反射,因为反射包里面会引用到很多全局反射对象,这个对象又会应用到很多全局的大对象。同理,我们不处理 ClassLoader,因为它里面会应用到整个 REPL。反正 ClassLoaders 和 Classes 是所有对象共享的。
private def visitSingleObject(obj: AnyRef, state: SearchState): Unit = {
val cls = obj.getClass
if (cls.isArray) {
visitArray(obj, cls, state)
} else if (cls.getName.startsWith("scala.reflect")) {
} else if (obj.isInstanceOf[ClassLoader] || obj.isInstanceOf[Class[_]]) {
// Hadoop JobConfs created in the interpreter have a ClassLoader.
} else {
obj match {
case s: KnownSizeEstimation =>
state.size += s.estimatedSize
case _ =>
val classInfo = getClassInfo(cls)
state.size += alignSize(classInfo.shellSize)
for (field <- classInfo.pointerFields) {
state.enqueue(field.get(obj))
}
}
}
}
然后我们创建一个Sample,并且放到队列samples中
private object SizeTracker {
case class Sample(size: Long, numUpdates: Long)
}
下面的主要工作就是计算一个bytesPerUpdate
...
// Only use the last two samples to extrapolate
// 如果sample太多了,就删除掉一些
if (samples.size > 2) {
samples.dequeue()
}
val bytesDelta = samples.toList.reverse match {
case latest :: previous :: tail =>
(latest.size - previous.size).toDouble / (latest.numUpdates - previous.numUpdates)
// If fewer than 2 samples, assume no change
case _ => 0
}
bytesPerUpdate = math.max(0, bytesDelta)
nextSampleNum = math.ceil(numUpdates * SAMPLE_GROWTH_RATE).toLong
}
我们统计到上次估算之后经历的 update 数量,并乘以bytesPerUpdate,即可得到总大小
// SizeTracker.scala
def estimateSize(): Long = {
assert(samples.nonEmpty)
val extrapolatedDelta = bytesPerUpdate * (numUpdates - samples.last.numUpdates)
(samples.last.size + extrapolatedDelta).toLong
}
Shuffle Write 端源码分析
Shuffle Write 端的实现主要依赖ShuffleManager中的ShuffleWriter对象,目前使用的ShuffleManager是SortShuffleManager,因此只讨论它。它是一个抽象类,主要有SortShuffleWriter、UnsafeShuffleWriter、BypassMergeSortShuffleWriter等实现。
SortShuffleWriter
private[spark] abstract class ShuffleWriter[K, V] {
/** Write a sequence of records to this task's output */
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
def stop(success: Boolean): Option[MapStatus]
}
SortShuffleWriter的实现可以说很简单了,就是将records放到一个ExternalSorter里面,然后创建一个ShuffleMapOutputWriter。shuffleExecutorComponents实际上是一个LocalDiskShuffleExecutorComponents。ShuffleMapOutputWriter是一个 Java 接口,实际上被创建的是LocalDiskShuffleMapOutputWriter
// SortShuffleWriter
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// 如果不需要进行mapSideCombine,那么我们传入空的aggregator和ordering,
// 我们在map端不负责对key进行排序,统统留给reduce端吧
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
dep.shuffleId, mapId, dep.partitioner.numPartitions)
...
紧接着,调用ExternalSorter.writePartitionedMapOutput将自己维护的map或者buffer(根据是否有 Map Side Aggregation)写到mapOutputWriter提供的partitionWriter里面。其过程用到了一个叫destructiveSortedWritablePartitionedIterator的迭代器,相比destructiveSortedIterator,它是多了 Writable 和 Partitioned 两个词。前者的意思是我可以写到文件,后者的意思是我先按照 partitionId 排序,然后在按照给定的 Comparator 排序。
接着就是commitAllPartitions,这个函数调用writeIndexFileAndCommit。
//
...
sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
val partitionLengths = mapOutputWriter.commitAllPartitions()
MapStatus被用来保存 Shuffle Write 操作的 metadata。
...
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId)
}
// LocalDiskShuffleMapOutputWriter.java
@Override
public long[] commitAllPartitions() throws IOException {
...
cleanUp();
File resolvedTmp = outputTempFile != null && outputTempFile.isFile() ? outputTempFile : null;
blockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, resolvedTmp);
return partitionLengths;
}
writeIndexFileAndCommit负责为传入的文件dataTmp创建一个索引文件,并原子地提交。注意到,到当前版本,每一个执行单元只会生成一份数据文件和一份索引。
// IndexShuffleBlockResolver.java
def writeIndexFileAndCommit(shuffleId: Int, mapId: Long, lengths: Array[Long], dataTmp: File): Unit
根据writeIndexFileAndCommit的注释,getBlockData会来读它写的块,这个getBlockData同样位于我们先前介绍过的IndexShuffleBlockResolver类中。
Reference
https://docs.scala-lang.org/zh-cn/tour/implicit-parameters.html
https://zhuanlan.zhihu.com/p/354409+
https://fangjian0423.github.io/20+/+/20/scala-implicit/
https://www.cnblogs.com/xia520pi/p/8745923.html
https://spark.apache.org/docs/latest/api/scala/index.html
https://blog.csdn.net/bluishglc/article/details/52946575
https://stackoverflow.com/questions/4386+7/what-is-the-formal-difference-in-scala-between-braces-and-parentheses-and-when
https://intellipaat.com/blog/dataframes-rdds-apache-spark/
https://indatalabs.com/blog/convert-spark-rdd-to-dataframe-dataset
https://tech.meituan.com/20+/04/29/spark-tuning-basic.html
https://endymecy.gitbooks.io/spark-programming-guide-zh-cn/content/programming-guide/rdds/rdd-persistences.html
https://forums.databricks.com/questions/+792/no-reducebekey-api-in-dataset.html
https://stackoverflow.com/questions/38383207/rolling-your-own-reducebykey-in-spark-dataset
https://litaotao.github.io/boost-spark-application-performance
https://www.iteblog.com/archives/+72.html
https://vimsky.com/article/2708.html
https://scastie.scala-lang.org/
https://www.jianshu.com/p/5c230+fa360
https://www.cnblogs.com/nowgood/p/ScalaImplicitConversion.html
https://stackoverflow.com/questions/+8+352/why-we-need-implicit-parameters-in-scala
https://stackoverflow.com/questions/3+08083/difference-between-dataframe-dataset-and-rdd-in-spark/39033308
https://stackoverflow.com/questions/3+06009/spark-saveastextfile-last-partition-almost-never-finishes
https://stackoverflow.com/questions/43364432/spark-difference-between-reducebykey-vs-groupbykey-vs-aggregatebykey-vs-combineb
https://blog.csdn.net/dabokele/article/details/52802+0
https://blog.csdn.net/zrc+902+article/details/527+593
https://stackoverflow.com/questions/3094++/spark-nullpointerexception-when-rdd-isnt-collected-before-map
https://twitter.github.io/scala_school/zh_cn/advanced-types.html
https://colobu.com/20+/05/+/Variance-lower-bounds-upper-bounds-in-Scala/
https://www.cnblogs.com/fillPv/p/5392+6.html
https://issues.scala-lang.org/browse/SI-7005
https://stackoverflow.com/questions/32900862/map-can-not-be-serializable-in-scala
http://www.calvinneo.com/2019/08/06/scala-lang/
http://www.calvinneo.com/2019/05/16/pandas/
深入理解 SPARK:核心思想与源码分析
http://www.calvinneo.com/2019/08/06/spark-sql/
https://zhuanlan.zhihu.com/p/67068559
http://www.jasongj.com/spark/rbo/
https://www.kancloud.cn/kancloud/spark-internals/45243
https://www.jianshu.com/p/4c5c2e535da5
http://jerryshao.me/20+/0+04/spark-shuffle-detail-investigation/
https://github.com/hustnn/TungstenSecret
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-shuffle-UnsafeShuffleWriter.html
https://blog.k2datascience.com/batch-processing-apache-spark-a670+008+7
https://stackoverflow.com/questions/45553492/spark-task-memory-allocation/45570944
https://0x0fff.com/spark-architecture-shuffle/
https://0x0fff.com/spark-memory-management/
https://www.slideshare.net/databricks/memory-management-in-apache-spark
https://www.linuxprobe.com/wp-content/uploads/20+/04/unified-memory-management-spark-+000.pdf
备注
腾讯互娱数据挖掘团队招聘后台开发实习生/正职,工作地点为深圳,有意者请发送简历到 jiaqiangwang [[AT]] tencent [[DOT]] com。
任职要求:
计算机相关专业本科及以上学历,有扎实的计算机理论基础;
熟悉 Python, C++, golang 等至少一种常用编程语言,有良好的代码习惯和丰富的实践经验;
有热情了解和尝试新技术、架构,较强的学习能力和逻辑思维能力;
较强的沟通能力,能够逻辑清晰地进行自我表达,团队合作意识强,与人沟通积极主动;
加分项:
对机器学习算法有较深的了解;
有分布式计算底层性能优化经验;
对机器学习有基本的了解,了解常见机器学习算法基本原理;
有基于分布式计算框架开发经验和大规模数据处理经验;