Spark Core笔记
文章目录
- Spark环境
- wordcount
- 本地
- Standalone
- 修改配置文件 关联日志 HA
- 配置历史服务器
- yarn
- mac本地模式
- Spark架构
- RDD
- RDD的核心属性
- RDD创建
- 从集合(内存)中创建RDD
- 从外部存储(文件)创建RDD
- RDD并行度与分区
- File的分区
- RDD转换算子
- 单value型
- map
- mapPartitions
- mapPartitionsWithIndex
- flatmap
- glom
- groupBy
- filter
- sample
- distinct
- coalesce
- repartition
- sortBy
- pipe
- 双Value类型
- intersection union subtract zip
- partitionBy
- reduceByKey
- groupByKey
- aggregateByKey
- foldByKey
- combineByKey
- sortByKey
- join
- leftOuterJoin cogroup
- 案例实操
- 行动算子
- reduce collect count first take
- takeOrdered
- sum aggregat fold countByKey
- save
- foreach
- 10种算子wordcount
- Spark序列化
- Spark依赖关系
- RDD血缘关系
- RDD依赖关系
- 窄依赖
- 宽依赖
- RDD阶段划分
- RDD任务划分
- RDD持久化
- 累加器
- 自定义累加器
- 广播变量
- Spark案例实操
- wordcount
- 三层架构模式
- TApplication
- TController
- TService
- TDao
- WordCountApplication
- WordCountController
- WordCountService
- WordCountDao
- 优化
- EnvUtil
- TApplication
- TDao
- WordCountService
- 电商需求Top10
- HotCategoryAnalysisTop10Application
- HotcategoryAnalysisTop10Controller
- HotCategoryAnalysisTop10Service
- HotCategoryAnalysisTop10Dao
- 优化1
- 优化2 读取次数
- 优化3 包装类
- 优化4 累加器
- 电商需求:Session统计
- 优化
- 电商需求:页面单跳转换率统计
- PageflowApplication
- PageflowController
- PageflowService
- PageflowDao
- 优化
- 案例四:
Spark环境

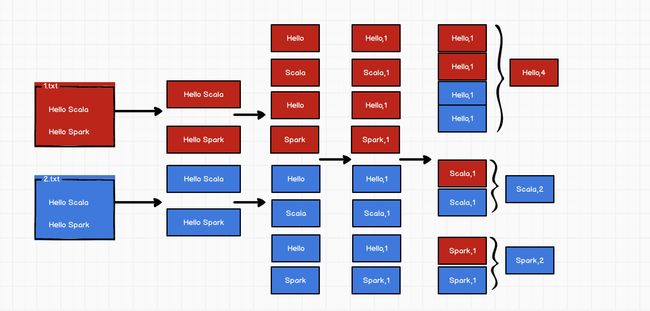
wordcount
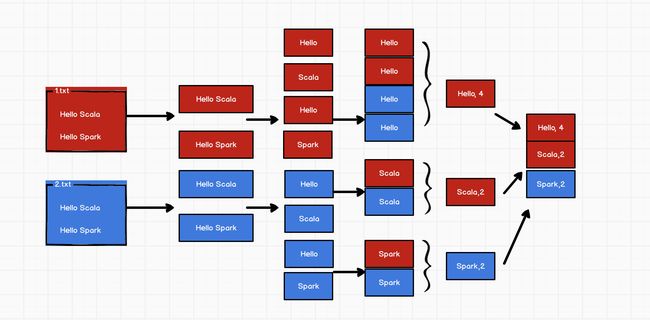
代码实现:
package com.vanas.bigdata.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-01 4:05 下午
*/
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
//Spark _WordCount
//Spark是一个计算框架
//开发人员是使用Spark框架的API实现计算功能
//1.准备Spark环境
//setMaster:设定spqrk环境的位置
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
//2.应该建立和Spark的连接
//jdbc:connection
val sc = new SparkContext(sparkConf)
//3.实现业务操作
//3.1读取指定目录下的数据文件(多个)
//参数path可以指向单一的文件也可以指向文件目录
//RDD:更适合并行计算的数据模型
val fileRDD: RDD[String] = sc.textFile("input")
//3.2将读取的内容进行扁平化操作,切分单词
val word: RDD[String] = fileRDD.flatMap(_.split(" "))
//3.3将分词后的数据进行分组(单词)
val groupRDD: RDD[(String, Iterable[String])] = word.groupBy(word => word)
//3.4将分组后的数据进行聚合(word,count)
val mapRDD: RDD[(String, Int)] = groupRDD.map {
case (word, iter) => {
(word, iter.size)
}
}
//3.5将聚合的结果采集后打印到控制台上
val wordCountArray: Array[(String, Int)] = mapRDD.collect()
println(wordCountArray.mkString(","))
//4.释放连接
sc.stop()
}
}
Spark
spark(分组同时聚合)
package com.vanas.bigdata.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-01 4:05 下午
*/
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
//Spark _WordCount
//Spark是一个计算框架
//开发人员是使用Spark框架的API实现计算功能
//1.准备Spark环境
//setMaster:设定spqrk环境的位置
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
//2.应该建立和Spark的连接
//jdbc:connection
val sc = new SparkContext(sparkConf)
//3.实现业务操作
//3.1读取指定目录下的数据文件(多个)
//参数path可以指向单一的文件也可以指向文件目录
//RDD:更适合并行计算的数据模型
val fileRDD: RDD[String] = sc.textFile("input")
//3.2将读取的内容进行扁平化操作,切分单词
val word: RDD[String] = fileRDD.flatMap(_.split(" "))
//3.3将分词后的数据进行结构的转换
//word=>(word,1)
val mapRDD: RDD[(String, Int)] = word.map(word => (word, 1))
//3.4将转换结构后的数据 根据单词进行分组聚合
//reduceByKey方法的作用表示根据数据key进行分组,然后对value进行统计聚合
val wordToSumRdd: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
//3.5将聚合的结果采集后打印到控制台上
val wordCountArray: Array[(String, Int)] = wordToSumRdd.collect()
println(wordCountArray.mkString(","))
//4.释放连接
sc.stop()
}
}
本地
解压缩
tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz -C /opt/module
cd /opt/module
mv spark-2.4.5-bin-without-hadoop-scala-2.12 spark-local
放jar包或者是改环境
[vanas@hadoop130 conf]$ vim spark-env.sh
SPARK_DIST_CLASSPATH=$(/opt/module/hadoop-3.1.3/bin/hadoop classpath)
[vanas@hadoop130 spark-local]$ bin/spark-shell --master local[*]
scala> sc.textFile("word.txt").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).collect
res2: Array[(String, Int)] = Array((p,3), (h,4), (" ",4), (j,1), (v,2), (r,3), (l,6), (s,3), (e,4), (a,5), (i,1), (k,3), (o,3))
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-2.4.5.jar \
10

Standalone
| Hadoop1 | Hadoop2 | Hadoop3 | |
|---|---|---|---|
| Spark | Worker Master | Worker | Worker |
tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz -C /opt/module
cd /opt/module
mv spark-2.4.5-bin-without-hadoop-scala-2.12 spark-standalone
放入jar包
修改配置文件 关联日志 HA
Slaves
[vanas@hadoop130 conf]$ mv slaves.template slaves
[vanas@hadoop130 conf]$ vim slaves
hadoop130
hadoop133
hadoop134
Spark-env.sh
8080=>资源监控页面=>Master
4040=>计算监控页面
Web 服务端口默认为8080
7077通信端口
8080有冲突所以改为8989
[vanas@hadoop130 conf]$ vim spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
#SPARK_MASTER_HOST=hadoop130
#SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop130,hadoop133,hadoop134
-Dspark.deploy.zookeeper.dir=/spark"
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop130:9820/directory
-Dspark.history.retainedApplications=30"
配置历史服务器
spark-defaults.conf
[vanas@hadoop130 conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop130:9820/directory
分发
xsync spark-standalone
启动
sbin/start-all.sh
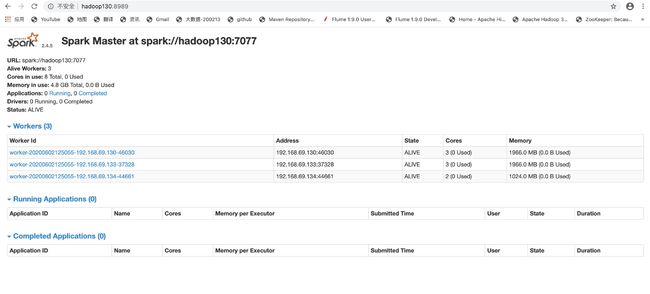
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop130:7077 \
./examples/jars/spark-examples_2.12-2.4.5.jar \
10
http://hadoop130:18080/

启动linux2的单独Master节点,此时linux2节点Master状态处于备用状态
[root@linux2 spark-standalone]# sbin/start-master.sh
提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop130:7077,hadoop133:7077 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-2.4.5.jar \
10
yarn
解压缩
tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz -C /opt/module
cd /opt/module
mv spark-2.4.5-bin-without-hadoop-scala-2.12 spark-yarn
修改配置文件
spark-env.sh
mv spark-env.sh.template spark-env.sh
[vanas@hadoop130 conf]$ vim spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop130:9820/directory
-Dspark.history.retainedApplications=30"
spark-defaults.conf
[vanas@hadoop130 conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop130:9820/directory
spark.yarn.historyServer.address=hadoop130:18080
spark.history.ui.port=18080
启动hdfs以及yarn集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-2.4.5.jar \
10
mac本地模式
scala> sc.textFile("/Users/vanas/Desktop/spark-2.4.5/bin/input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res3: Array[(String, Int)] = Array((word,1), (hello,3), (spark,2))
scala>
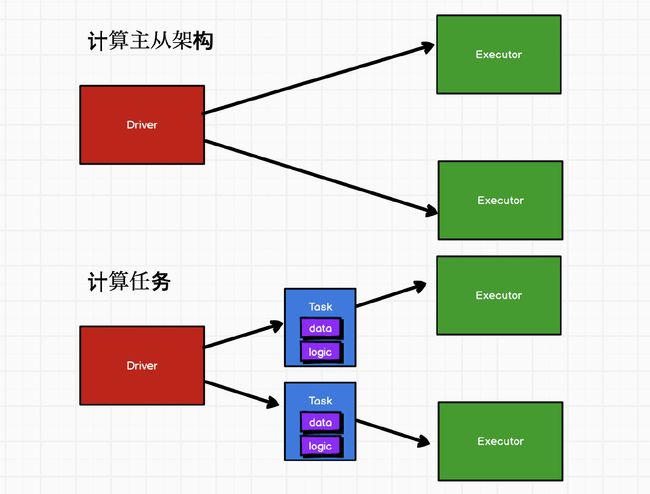
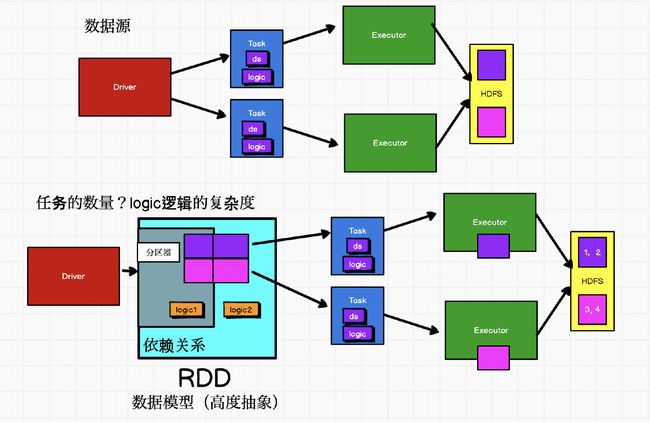
Spark架构
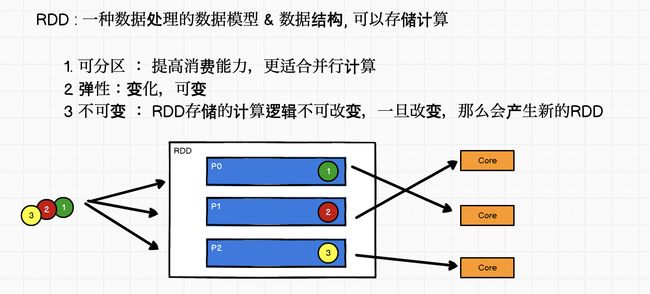
RDD
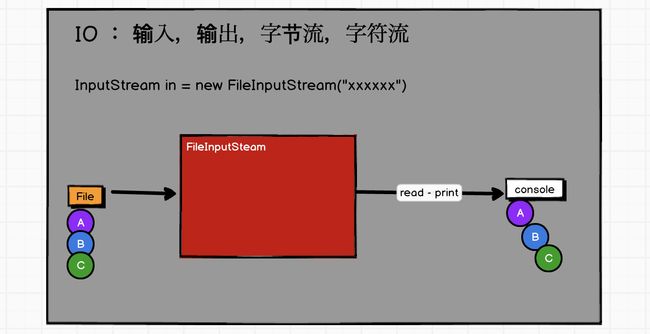
缓冲流
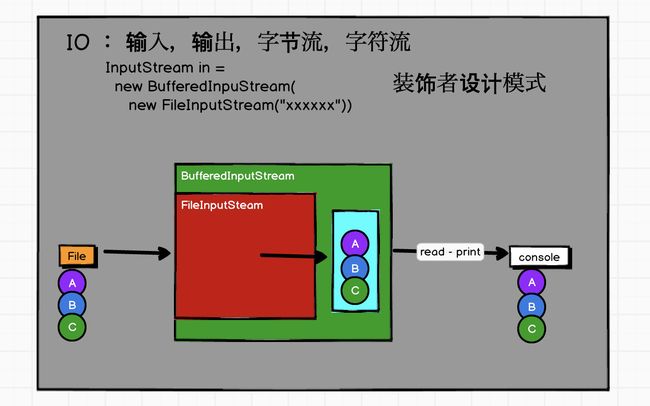
转换流

RDD
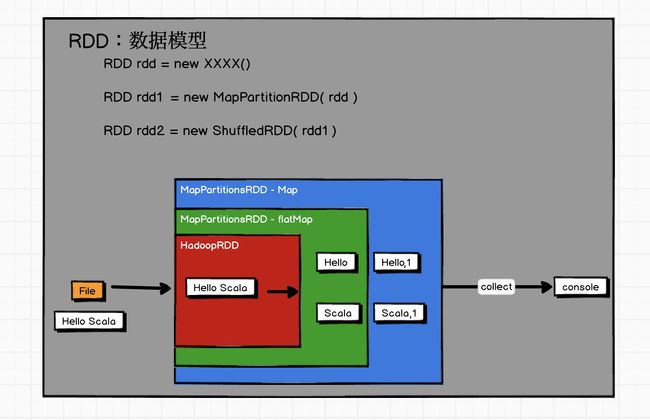
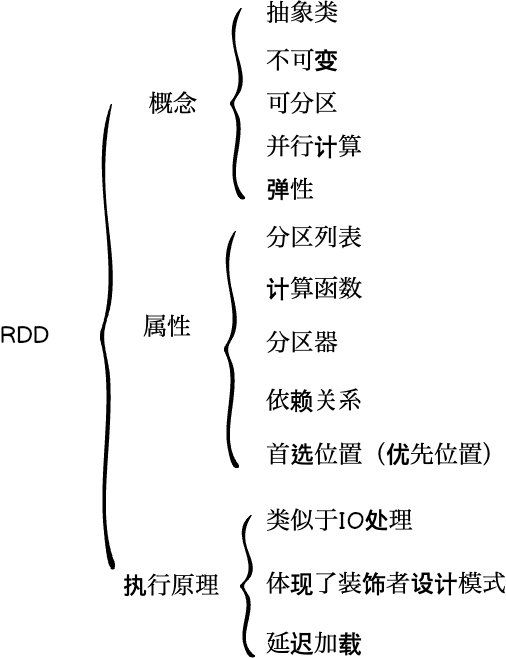
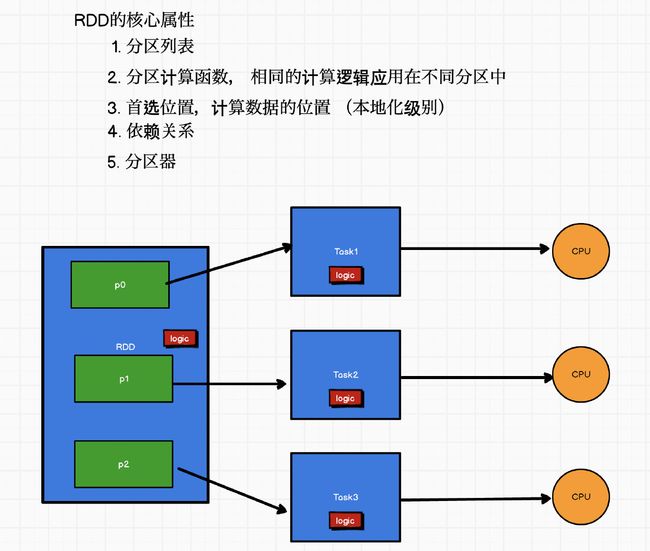
RDD的核心属性
不可变集合=>添加数据=>新的集合
RDD =>添加功能=>新的RDD
RDD创建
从集合(内存)中创建RDD
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark01_RDD_Memorry {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
// Spark -从内存中创建RDD
//1.parallelize:并行
val list = List(1, 2, 3, 4)
val rdd: RDD[Int] = sc.parallelize(list)
println(rdd.collect().mkString(","))
//makeRDD的底层代码其实就是调用paralleliz
val rdd1: RDD[Int] = sc.makeRDD(list)
println(rdd1.collect().mkString(","))
sc.stop()
}
}
并行度
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark03_RDD_Memory_Par {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
// Spark -从内存中创建RDD
//RDD中的分区的数量就是并行度,设定并行度,其实就在设定分区数量
//1.makeRDD的第一个参数:数据源
//2.makeRDD的第二个参数:默认并行度(分区的数量)
// parallelize
// numSlices: Int = defaultParallelism(默认并行度)
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
//并行度默认会从spark配置信息中获取spark.default.parallelism值
//如果获取不到指定参数,会采用默认值totalCores(机器的总核数)
//机器的总核数=当前环境中可用核数
//local=>单核(单线程)=>1
//local[4]=>4核(4个线程)=>4
//local[*]=>最大核数=>
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//println(rdd.collect().mkString(","))
//将RDD处理后的数据保存到分区文件中
rdd.saveAsTextFile("output")
sc.stop()
}
}
从外部存储(文件)创建RDD
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark02_RDD_File {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
// Spark -从磁盘(File)中创建RDD
//path:读取文件(目录)的路径
//path可以设定相对路径,如果是IDEA,那么相对路径的位置从项目的根开始查找
//path的路径根据环境的不同自动发生改变
//spark读取文件时,默认采用的是Hadoop读取文件的规则
//默认是一行一行的读取文件内容
//如果路径执行的为文件目录,那么目录中的文本文件都会被读取
val fileRDD: RDD[String] = sc.textFile("input")
//读取指定的文件
val fileRDD1: RDD[String] = sc.textFile("input/word.txt")
//文件路径可以采用通配符
val fileRDD2: RDD[String] = sc.textFile("input/word*.txt")
//文件路径还可以指向第三方存储系统:HDFS
val fileRDD3: RDD[String] = sc.textFile("hdfs://input/word*.txt")
println(fileRDD.collect().mkString(","))
sc.stop()
}
}
RDD并行度与分区
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark04_RDD_Memory_PartitionData {
def main(args: Array[String]): Unit = {
// Spark
//1.泛型
//def parallelize[T: ClassTag](
//seq: Seq[T],
//numSlices: Int = defaultParallelism): RDD[T] = withScope {
//assertNotStopped()
//new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
//}
//2.方法重写
//override def getPartitions: Array[Partition] = {
//val slices = ParallelCollectionRDD.slice(data, numSlices).toArray
//slices.indices.map(i => new ParallelCollectionPartition(id, i, slices(i))).toArray
//}
//3.伴生对象
//4.模式匹配 def slice=>seq match
//5.map
// def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = {
// if (numSlices < 1) {
// throw new IllegalArgumentException("Positive number of partitions required")
// }
// // Sequences need to be sliced at the same set of index positions for operations
// // like RDD.zip() to behave as expected
// def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
// (0 until numSlices).iterator.map { i =>
// val start = ((i * length) / numSlices).toInt
// val end = (((i + 1) * length) / numSlices).toInt
// (start, end)
// }
// }
// seq match {
// case r: Range =>
// positions(r.length, numSlices).zipWithIndex.map { case ((start, end), index) =>
// // If the range is inclusive, use inclusive range for the last slice
// if (r.isInclusive && index == numSlices - 1) {
// new Range.Inclusive(r.start + start * r.step, r.end, r.step)
// }
// else {
// new Range(r.start + start * r.step, r.start + end * r.step, r.step)
// }
// }.toSeq.asInstanceOf[Seq[Seq[T]]]
// case nr: NumericRange[_] =>
// // For ranges of Long, Double, BigInteger, etc
// val slices = new ArrayBuffer[Seq[T]](numSlices)
// var r = nr
// for ((start, end) <- positions(nr.length, numSlices)) {
// val sliceSize = end - start
// slices += r.take(sliceSize).asInstanceOf[Seq[T]]
// r = r.drop(sliceSize)
// }
// slices
// case _ =>
// val array = seq.toArray // To prevent O(n^2) operations for List etc
// positions(array.length, numSlices).map { case (start, end) =>
// array.slice(start, end).toSeq
// }.toSeq
// }
// }
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//内存中的集合数据按照平均分的方式进行分区处理
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
rdd.saveAsTextFile("output")
//12,34
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 4)
rdd1.saveAsTextFile("output1")
//1,2,3,4
//savaAsTextFile方法如果文件路径已经存在,会发生错误
//内存中的集合数据如果不能平均分,会将多余的数据放置在最后一个分区
//内存中数据的分区基本上就是平均分,如果不能够整除,会采用一个基本的算法实现分配
//List(1, 2, 3, 4,5)=>Array(1,2,3,4,5)
// (length=5,num=3)
//(0,1,2)
//=>0 =>(0,1) =>1
//=>1 =>(1,3) =>2
//=>2 =>(3,5) =>
//Array.slice=>切分数组=>(from,until)
val rdd2: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3)
rdd2.saveAsTextFile("output2")
//1,2,34
//1,23,45
sc.stop()
}
}
File的分区
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark05_RDD_File_Par {
def main(args: Array[String]): Unit = {
//math.min
//math.max
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
// Spark-从磁盘(File)中创建RDD
//textFile 第一个参数表示读取文件的路径
//textFile 第二个参数表示最小分区数
// 默认值为:math.min(defaultParallelism, 2)
// math.min(totalCores, 2)
//12,34
val fileRDD1: RDD[String] = sc.textFile("input/w.txt")
fileRDD1.saveAsTextFile("output1")
val fileRDD2: RDD[String] = sc.textFile("input/w.txt",1)
fileRDD2.saveAsTextFile("output2")
val fileRDD3: RDD[String] = sc.textFile("input/w.txt",4)
fileRDD3.saveAsTextFile("output3")
val fileRDD4: RDD[String] = sc.textFile("input/w.txt",3)
fileRDD4.saveAsTextFile("output4")
sc.stop()
}
}
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark06_RDD_File_PartitionData {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
// Spark-从磁盘(File)中创建RDD
//1.Spark读取文件采用的是Hadoop的读取规则
// 文件切片规则:以字节方式来切片
// 数据读取规则:以行为单位来读取
//2.问题
//文件到底切成几片(分区的数量)?
//文件字节数(10),预计切片数量(2)
//10/2 => 5byte
//totalSize =11
//goalSize = totalSiz /numSplits =11/2 =5...1 =>3
//所谓的最小分区数 ,取决于总的字节数是否能整除分区数并且剩余的字节达到一个比率 SPLIT_SLOP = 1.1; // 10% slop
//实际产生的分区数量可能大于最小分区数
//分区的数据如何存储的?
//分区数据是以行为单位读取的,而不是字节
//12,34
val fileRDD1: RDD[String] = sc.textFile("input/w.txt",2)
fileRDD1.saveAsTextFile("output")
sc.stop()
}
}
单一文件
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark07_RDD_File_PartitionData {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
// Spark-从磁盘(File)中创建RDD
//1.分几个区?
//10byte/4 = 2byte....2byte=>5
//0=>(0,2)
//1=>(2,4)
//2=>(4,6)
//3=>(6,8)
//4=>(8,10)
//2.数据如何存储?
//数据是以行的方式读取,但是会考虑偏移量(数据的offset)的设置
//1@@=>012
//2@@=>345
//3@@=>678
//4 =>9
//10byte/4 = 2byte....2byte=>5
//0=>(0,2)=>1
//1=>(2,4)=>2
//2=>(4,6)=>3
//3=>(6,8)=>
//4=>(8,10)=>4
//0 =>1
//1 =>2
//2 =>3
//3 =>
//4 =>4
val fileRDD1: RDD[String] = sc.textFile("input/w.txt",4)
fileRDD1.saveAsTextFile("output")
sc.stop()
//1
//2,3,4
//totalsize =6,num =2
//6/2 = 3 byte
//(0,0+3)=>(0,3)
//(3,3+3)=>(3,6)
//1@@=>012
//234=>345
//分2片的话 1,2,3,4在一个分区另一个是空
//val fileRDD1: RDD[String] = sc.textFile("input/w.txt",2)
}
}
多个文件
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark08_RDD_File_PartitionData {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//多个文件 1.txt 6byte 2.txt 6byte
//hadoop分区是以文件为单位进行划分的
//读取数据不能跨越文件
//12/2 =>6
//12/3 =>4
//1.txt =>(0,4)
// =>(4,6)
//2.txt =>(0,4)
// =>(4,6)
val fileRDD1: RDD[String] = sc.textFile("input",3)
fileRDD1.saveAsTextFile("output")
sc.stop()
}
}
RDD转换算子
单value型
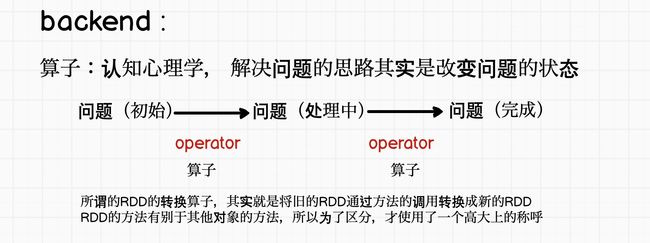
map
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark09_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//转换算子
//能够将旧的RDD通过方法转换为新的RDD,但是不会触发作业的执行
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//转换:旧rdd =>算子 =>新RDD
//val rdd1:RDD[Int] = rdd.map((i:Int)=>{i*2})
val rdd1:RDD[Int] = rdd.map(_*2)
//读取数据
//collect方法不会转换RDD,会触发作业的执行
//所以将collect这样的方法称之为行动(action)算子
val ints: Array[Int] = rdd1.collect()
sc.stop()
}
}
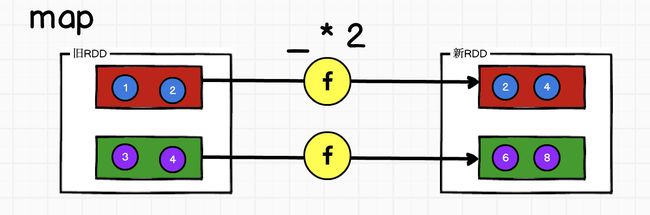
分区问题
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark10_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//2个分区12,34
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//分区问题
//RDD中有分区列表
//默认分区数量不变,数据会转换后输出
val rdd1: RDD[Int] = rdd.map(_ * 2)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
执行顺序问题
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark11_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//1,2,3,4 =>x map 1 =>x map 2
//1=>x map 1=>x map 2=> 2
//0-(1,2) 1A 1B 2A 2B
//1-(3,4) 3A 3B 4A 4B
//分区内数据是按照顺序依次执行,第一条数据所有的逻辑全部执行完毕后,才会执行下一条数据
//分区间数据执行没有顺序,而且无需等待
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd1: RDD[Int] = rdd.map(x => {
println("map A =" + x)
x
})
val rdd2: RDD[Int] = rdd1.map(x => {
println("map B =" + x)
x
})
println(rdd2.collect().mkString(","))
sc.stop()
}
}
小功能:从服务器日志数据apache.log中获取用户请求URL资源路径
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark12_RDD_Test {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//从服务器日志数据apache.log中获取用户请求URL资源路径
val fileRDD: RDD[String] = sc.textFile("input/apache.log")
//"aaaaabbbbbb" =>"aaaaa"
//A=>B
val urlRDD: RDD[String] = fileRDD.map(
line => {
val datas: Array[String] = line.split(" ")
datas(6)
}
)
urlRDD.collect().foreach(println)
sc.stop()
}
}
mapPartitions
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark13_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//mapPartitions
//以分区单位进行计算,和map算子很像
//区别就在于map算子是一个一个执行,而mapPartitions一个分区一个分区执行
//类似于批处理
//map方法是全量数据操作,不能丢失数据
//mapPartitions 一次性获取分区的所有数据,那么可以执行迭代器集合的所有操作
// 过滤,max,sum
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//3,4,1,2
val rdd: RDD[Int] = dataRDD.mapPartitions(
iter => {
iter.map(_ * 2)
}
)
println(rdd.collect.mkString(","))
val rdd1: RDD[Int] = dataRDD.mapPartitions(
iter => {
iter.filter(_ % 2 == 0)
}
)
println(rdd1.collect.mkString(","))
sc.stop()
}
}
小功能:获取每个数据分区的最大值
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark14_RDD_Test {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//mapPartitions
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 4, 3, 2, 5,6), 2)
//获取每个数据分区的最大值
//iter=>iter 要返回迭代器
val rdd: RDD[Int] = dataRDD.mapPartitions(
iter => {
List(iter.max).iterator
}
)
//4,6
println(rdd.collect.mkString(","))
sc.stop()
}
}
map和mapPartitions的区别
map算子每一次处理一条数据,而mapPartitions算子每一次将一个分区的数据当成一个整体进行数据处理,如果一个分区的数据没有完全处理完,那么所有的数据都不会释放,即使前面已经处理完的数据也不会释放。容易出现内存溢出,所以当内存空间足够大时,为了提高效率,推荐使用mapPartitions
有些时候,完成比完美更重要
mapPartitionsWithIndex
获取每个分区最大值以及分区号
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark15_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//mapPartitionsWithIndex
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//获取每个分区最大值以及分区号
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 3, 6, 2, 5), 2)
//iter=>iter
val rdd: RDD[Int] = dataRDD.mapPartitionsWithIndex(
(index, iter) => {
List(index, iter.max).iterator
}
)
println(rdd.collect.mkString(","))
sc.stop()
}
}
小功能:获取第二个数据分区的数据
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark16_RDD_Test {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//获取第二个数据分区的数据
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 3, 6, 2, 5), 2)
//获取的分区索引从0开始
val rdd: RDD[Int] = dataRDD.mapPartitionsWithIndex(
(index, iter) => {
if (index == 1) {
iter
} else {
Nil.iterator
}
}
)
println(rdd.collect.mkString(",")) //6,2,5
sc.stop()
}
}
flatmap
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark17_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//flatmap
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(List(1, 2), List(3, 4)))
val rdd: RDD[Int] = dataRDD.flatMap(list => list)
println(rdd.collect.mkString(",")) //1,2,3,4
sc.stop()
}
}
小功能:将List(List(1,2),3,List(4,5))进行扁平化操作
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark18_RDD_Test {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//将List(List(1,2),3,List(4,5))进行扁平化操作
val dataRDD: RDD[Any] = sc.makeRDD(List(List(1, 2), 3, List(4, 5)))
val rdd: RDD[Any] = dataRDD.flatMap(
data => {
data match {
case list: List[_] => list
case d => List(d)
}
}
)
println(rdd.collect.mkString(","))
sc.stop()
}
}
glom
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark19_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
//glom=>将每个分区的数据转换为数组
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd: RDD[Array[Int]] = dataRDD.glom()
rdd.foreach(
array => {
println(array.mkString(","))
}
)
sc.stop()
}
}
小功能:计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
//将每个分区的数据转化为数组
val glomRDD: RDD[Array[Int]] = dataRDD.glom()
//将数组中的最大值去出
//Array=>max
val maxRDD: RDD[Int] = glomRDD.map(array => array.max)
//将取出的最大值求和
val array: Array[Int] = maxRDD.collect()
println(array.sum)
sc.stop()
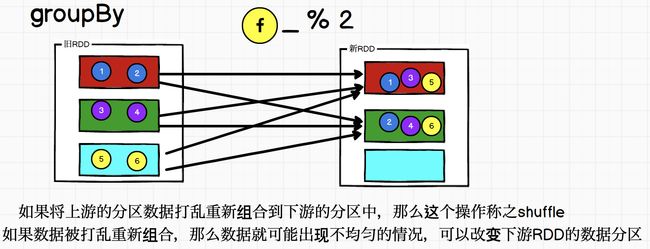
groupBy
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark20_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//获取每个分区最大值以及分区号
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
//分组
//groupBy方法可以根据指定的规则进行分组,指定的规则的返回值就是分组的key
//groupBy方法的返回值为元组
// 元组中的第一个元素,表示分组的key
// 元组中的第二个元素,表示相同key的数据形成的可迭代的集合
//groupBy方法执行完毕后,会将数据进行分组操作,但是分区是不会改变的
// 不同的组的数据会打乱在不同的分区中
//groupBy方法会导致数据不均匀,产生shuffle操作,如果想改变分区,可以传递参数
val rdd: RDD[(Int, Iterable[Int])] = dataRDD.groupBy(
num => {
num % 2
},2
)
rdd.saveAsTextFile("output")
//glom=>分区转换为array
println("分组后的数据分区的数量" + rdd.glom().collect().length) //3
rdd.collect().foreach {
case (key, list) => {
println("key:" + key + " list:" + list.mkString(","))
}
}
//key:0 list:2,4,6
//key:1 list:1,3,5
sc.stop()
}
}
小功能:将List(“Hello”, “hive”, “hbase”, “Hadoop”)根据单词首写字母进行分组
//将List("Hello", "hive", "hbase", "Hadoop")根据单词首写字母进行分组。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List("Hello", "hive", "hbase", "Hadoop"))
val result: RDD[(Char, Iterable[String])] = dataRDD.groupBy(word => {
word.substring(0, 1)
word.charAt(0)
//String(0)=>StringOps 隐式转换
word(0)
})
println(result.collect().mkString(","))
sc.stop()
小功能:从服务器日志数据apache.log中获取每个时间段访问量
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val fileRDD: RDD[String] = sc.textFile("input/apache.log")
val timeRDD: RDD[String] = fileRDD.map(
log => {
val datas: Array[String] = log.split(" ")
datas(3)
}
)
val hourRDD: RDD[(String, Iterable[String])] = timeRDD.groupBy(
time => {
time.substring(11, 13)
}
)
val result: RDD[(String, Int)] = hourRDD.map(kv => ((kv._1, kv._2.size)))
println(result.collect().mkString(","))
sc.stop()
小功能:WordCount
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[String] = sc.makeRDD(List("hello scala", "hello"))
dataRDD.flatMap(_.split(" ")).groupBy(word=>word).map(kv=>(kv._1,kv._2.size)).collect().mkString(",")
sc.stop()
}
filter
package com.vanas.bigdata.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark21_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
//过滤
//根据指定的规则对数据进行筛选和过滤,满足条件的数据保留,不满足的数据丢弃
val rdd: RDD[Int] = dataRDD.filter(
num => {
num % 2 == 0
}
)
rdd.collect().foreach(println)
sc.stop()
}
}
小功能:从服务器日志数据apache.log中获取2015年5月17日的请求路径
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val fileRDD: RDD[String] = sc.textFile("input/apache.log")
val timeRDD: RDD[String] = fileRDD.map(
log => {
val datas: Array[String] = log.split(" ")
datas(3)
}
)
val filterRDD: RDD[String] = timeRDD.filter(time => {
val vmd = time.substring(0, 10)
vmd == "17/05/2015"
})
filterRDD.collect().foreach(println)
sc.stop()
sample
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark27_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
//sample 用于从数据集中抽取数据
//第一个参数表示数据抽取后是否放回,可以重复抽取
// true:抽取后放回
// false:抽取不放回
//第二个参数表示数据抽取的几率(不放回的场合),重复抽取的次数(放回的场合)
//这里的几率不是数据能够被抽取的数据总量的比率,
//第三个参数表示随机数的种子,可以确定数据的抽取
//随机数不随机,所谓的随机数依靠随机算法实现
val dataRDD: RDD[Int] = rdd.sample(
withReplacement = false,
fraction = 0.5,
seed =1
)
// val dataRDD1: RDD[Int] = rdd.sample(
// withReplacement = true,
// fraction = 2
// )
println(dataRDD.collect().mkString(","))
// println(dataRDD1.collect().mkString(","))
sc.stop()
}
}
在实际开发中,往往会出现数据倾斜的情况,那么可以从数据倾斜的分区中抽取数据,查看数据的规则,分析后,可以进行改善处理,让数据更加均匀
distinct
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark28_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 1, 2, 4))
val rdd1: RDD[Int] = rdd.distinct()
//distinct可以改变分区的数量
val rdd2: RDD[Int] = rdd.distinct(2)
println(rdd1.collect().mkString(","))
println(rdd2.collect().mkString(","))
sc.stop()
}
}
coalesce
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark29_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 1, 1, 2, 2, 2), 6)
//[1,1,1] [2,2,2]
//[],[2,2,2]
val filterRDD: RDD[Int] = rdd.filter(num => num % 2 == 0)
//多=>少
//当数据过滤后,发现数据不够均匀,那么可以缩减分区
//val coalesceRDD: RDD[Int] = filterRDD.coalesce(1)
//coalesceRDD.saveAsTextFile("output")
//如果发现数据分区不合理,也可以缩减分区
val coalesceRDD: RDD[Int] = rdd.coalesce(2)
coalesceRDD.saveAsTextFile("output")
sc.stop()
}
}
Shuffle 相关

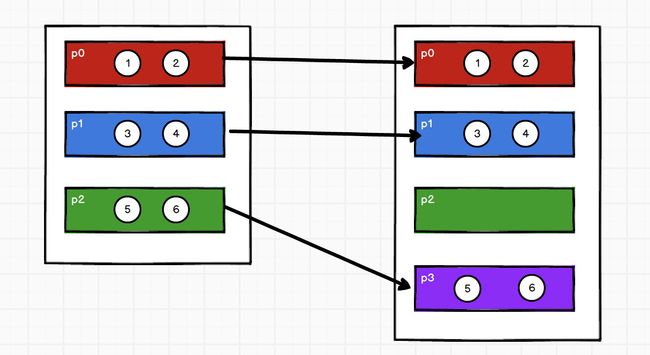
方法默认情况下无法扩大分区,因为默认不会将数据打乱重新组合,扩大分区时没有意义
如果想要扩大分区,那么必须使用shuffle,打乱数据,重新组合
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark30_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 1, 1, 2, 2, 2), 2)
//扩大分区
//coalesce主要目的是缩减分区,扩大分区时没有效果
//为什么不能扩大分区,因为在分区缩减时,数据不会打乱重新组合,没有shuffle的过程
//如果就是非得想要将数据扩大分区,那么必须打乱数据重新组合,必须使用shuffle
//coalesce方法第一个参数表示缩减分区后的分区数量
//coalesce方法第二个参数表示分区改变时,是否会打乱重新组合数据,默认不打乱
val coalesceRDD: RDD[Int] = rdd.coalesce(6,true)
coalesceRDD.saveAsTextFile("output")
sc.stop()
}
}
repartition
方法其实就是coalesce方法,只不过使用了shuffle操作,让数据更均衡些
可以有效防止数据倾斜问题
如果缩减分区,一般采用coalesce,如果扩大分区,就采用repartition
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark31_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 1, 1, 2, 2, 2), 3)
//缩减分区:coalesce
rdd.coalesce(2)
//扩大分区:repartition
//从底层源码的角度,repartition其实就是coalesce,并且肯定进行shuffle操作
rdd.repartition(6)
sc.stop()
}
}
sortBy
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark32_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 4, 2, 3), 3)
//sortBy
//默认排序规则为升序
//sortBy可以通过传递第二个参数改变排序的方式
//sortBy可以设定第三个参数改变分区
val sortRDD: RDD[Int] = rdd.sortBy(num => num, false)
println(sortRDD.collect().mkString(","))
sc.stop()
}
}
pipe
[root@linux1 data]# vim pipe.sh
#!/bin/sh
echo "Start"
while read LINE; do
echo ">>>"${LINE}
done
[root@linux1 data]# chmod 777 pipe.sh
bin/spark-shell
scala> val rdd = sc.makeRDD(List("hi","Hello","how","are","you"), 1)
scala> rdd.pipe("data/pipe.sh").collect()
res18: Array[String] = Array(Start, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
双Value类型
intersection union subtract zip
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark33_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[Int] = sc.makeRDD(List(1, 4, 3, 2), 2)
val rdd2: RDD[Int] = sc.makeRDD(List(3, 6, 5, 4), 2)
val rdd0: RDD[String] = sc.makeRDD(List("a","b","c","d"), 2)
//如果RDD数据类型不一致会怎么办?会发生错误
//rdd1.intersection(rdd0)
//rdd1.union(rdd0)
//zip没有问题可以拉链 如果数据分区不一致,会发生错误 如果数据分区中数据量不一致,也会发生错误
//(Int,String)
//val value: RDD[(Int, String)] = rdd1.zip(rdd0)
//1,2,3,4
//3,4,5,6
//并集,数据合并,分区也会合并
val rdd3: RDD[Int] = rdd1.union(rdd2)
//println(rdd3.collect().mkString(","))
rdd3.saveAsTextFile("output3")
//交集:保留最大分区数,分区数不变,数据被打乱重组,shuffle
val rdd4: RDD[Int] = rdd1.intersection(rdd2)
//println(rdd4.collect().mkString(","))
rdd4.saveAsTextFile("output4")
//差集 数据被打乱重组,shuffle
//当调用rdd的subtract方法时,以当前rdd的分区为主,所以分区数量等于当前rdd的分区数量
val rdd5: RDD[Int] = rdd1.subtract(rdd2)
//println(rdd5.collect().mkString(","))
rdd5.saveAsTextFile("output5")
//拉链 分区数不变
//2个rdd分区一致,但是数据量相同的场合:
//Exception: Can only zip RDDs with same number of elements in each partition
//2个rdd的分区不一致,数据也不相同,但是每个分区数据量一致:
//Exception: Can't zip RDDs with unequal numbers of partitons
val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2)
//println(rdd6.collect().mkString(","))
rdd6.saveAsTextFile("output6")
sc.stop()
}
}
partitionBy
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Spark34_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//k-v 类型的数据操作
//单值会报错 所以得是k-v
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
//Spqrk中很多的方法是基于Key进行操作的,所以数据格式为键值对(对偶元组)
//如果数据类型为k-v类型,那么Spark会给RDD自动补充很多新的功能(扩展)
//隐式转换(A=>B)
//partitionBy方法来自于PairRDDFUnction类
//RDD的伴生对象中提供了隐式函数,可以将RDD[k,v]转换为PairRDDFunctions类
//partitionBy根据指定的规则对数据进行分区
//groupBy=>coalesce
//repartition=>shuffle
//partitionBy参数为分区器对象
//分区器对象:RangePartitioner & HashPartitioner
//HashPartitioner分区规则是将当前数据的key进行取余操作
//HashPartitioner是spark默认的分区器
val rdd1: RDD[(String, Int)] = rdd.partitionBy(new HashPartitioner(2))
rdd1.saveAsTextFile("output")
//sortBy 使用了RangePartitionner 用的不多 要求数据的key必须能排序
sc.stop()
}
}
自定义分区器
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object Spark35_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//自定义分区器-自己决定数据放置在哪个分区做处理
//cba wnba nba
val rdd: RDD[(String, String)] = sc.makeRDD(
List(
("cba", "消息1"), ("cba", "消息2"), ("cba", "消息3"),
("nba", "消息4"), ("wnba", "消息5"), ("nba", "消息6")
), 1
)
val rdd1: RDD[(String, String)] = rdd.partitionBy(new MyPartitioner(3))
val rdd2: RDD[(Int, (String, String))] = rdd1.mapPartitionsWithIndex((index, datas) => {
datas.map(
data => (index, data)
)
})
rdd2.collect().foreach(println)
sc.stop()
}
//自定义分区器
//1.和Partitioner类发生关联,继承Partitionner
//2.重写方法
class MyPartitioner(num: Int) extends Partitioner {
//获取分区的数量
override def numPartitions: Int = {
num
}
//根据数据的key来决定数据在哪个分区中进行处理
//方法的返回值表示分区的编号(索引)
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case _ => 1
}
}
}
}
多次分区
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark36_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//自定义分区器-自己决定数据放置在哪个分区做处理
//cba wnba nba
val rdd: RDD[(String, String)] = sc.makeRDD(
List(
("cba", "消息1"), ("cba", "消息2"), ("cba", "消息3"),
("nba", "消息4"), ("wnba", "消息5"), ("nba", "消息6")
), 1
)
//多次使用分区器 分区器一样,不进行处理,不会再重分区
val rdd1: RDD[(String, String)] = rdd.partitionBy(new HashPartitioner(3))
val rdd2: RDD[(String, String)] = rdd1.partitionBy(new HashPartitioner(3))
sc.stop()
}
}
reduceByKey

package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark37_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//reduceByKey:根据数据的key进行分组,然后对value进行聚合
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("hello", 1), ("scala", 1), ("hello", 1)
)
)
//word=>(word,1)
//reduceByKey第一个参数表示相同key的value的聚合方式
//reduceByKey第二个参数表示聚合后的分区数量
val rdd1: RDD[(String, Int)] = rdd.reduceByKey(_ + _, 2)
println(rdd1.collect().mkString(","))
sc.stop()
}
}
rdeuceByKey是否为shuffle,cache缓存?
reduceByKey不一定会有shuffle
reduceByKey为了提高效率,默认有缓存的
package com.vanas.bigdata.spark.core.rdd.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 10:40 上午
*/
object Spark59_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
sc.setCheckpointDir("cp")
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 1, 2))
val mapRDD: RDD[(Int, Int)] = rdd.map(
num => {
println("map...")
(num, 1)
})
val reduceRDD: RDD[(Int, Int)] = mapRDD.reduceByKey(
(x, y) => {
println("reduce")
x + y
}
)
println(reduceRDD.collect().mkString(","))
println("**********************")
println(reduceRDD.collect().mkString(","))
sc.stop()
}
}
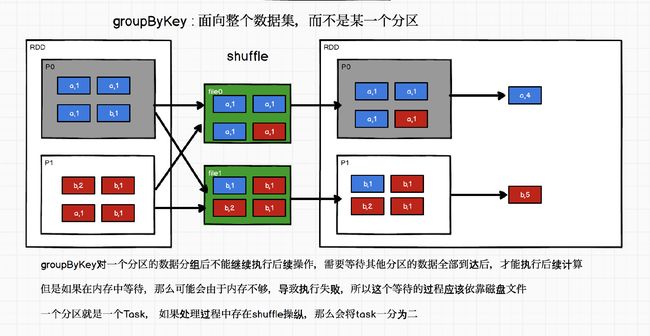
groupByKey
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark38_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("hello", 1), ("scala", 1), ("hello", 1)
)
)
//groupByKey:根据数据的key进行分组
//groupBy: 根据指定的规则对数据进行分组
//调用groupByKey后,返回数组的类型为元组
//元组的第一个元素表示的是用于分组的key
//元组的第二个元素表示的是分组后,相同key的value的集合
val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()
val wordToCount: RDD[(String, Int)] = groupRDD.map {
case (word, iter) => {
(word, iter.sum)
}
}
println(wordToCount.collect().mkString(","))
sc.stop()
}
}
reduceByKey和groupByKey的区别?
两个算子再实现相同的业务功能时,reduceBykey存在预聚合功能,所以性能比较高,推荐使用,但是,不是说一定就采用这个方法,与根据场景来选择
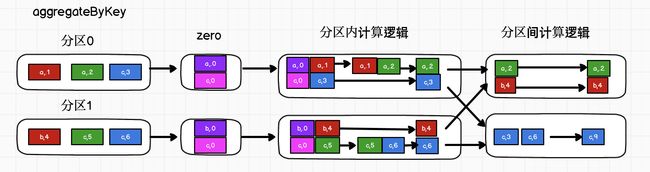
aggregateByKey
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark39_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//将分区内相同key取最大值,分区间相同的key求和
//分区内和分区间计算规则不一样
//reduceByKey :分区内和分区间计算规则相同
//0=>[(a,2),(c,3)]
//1=>[(b,4),(c,6)]
// =>[(a,2),(b,4),(c,9)]
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("c", 3),
("b", 4), ("c", 5), ("c", 6)
), 2
)
//aggregateByKey:根据key进行数据聚合
//Scala语法:函数柯里化
//方法有两个参数列表需要传递参数
//第一个参数列表中传递的参数为 zeroValue: 计算初始值
// 用于分区内进行计算时,当作初始值使用
//第二个参数列表中传递的参数为
// seqOp:分区内的计算规则 相同key的value计算
// combOp:分区间的计算规则 相同key的value的计算
val result: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
)
println(result.collect().mkString(","))
sc.stop()
}
}
foldByKey
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark40_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("c", 3),
("b", 4), ("c", 5), ("c", 6)
), 2
)
//如果分区内计算规则和分区间计算规则相同都是求和,那么他可以计算wordcount
//val result: RDD[(String, Int)] = rdd.aggregateByKey(10)(
// (x, y) => x + y,
// (x, y) => x + y
//)
//val result = rdd.aggregateByKey(0)(_ + _, _ + _)
//如果分区内计算规则和分区间计算规则相同,那么可以将aggregateByKey简化为另一个方法
val result: RDD[(String, Int)] = rdd.foldByKey(0)(_ + _)
println(result.collect().mkString(","))
//scala
//List().reduce(_+_)
//List().fold(0)(_+_)
//spark
//rdd.reduceByKey(_+_)
//rdd.foldByKey(0)(_+_)
sc.stop()
}
}
combineByKey
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3USgEKD8-1593324100595)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-05 下午9.32.09.png)]
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark41_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//combineByKey
//每个key的平均值:相同key的总和/相同key的数量
//0=>("a", 88), ("b", 95), ("a", 91)
//1=>("b", 93), ("a", 95), ("b", 98)
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)), 2
)
//rdd.reduceByKey(_ + _) //88,91 没有把2保存起来
//rdd.aggregateByKey(0)(_+_,_+_) 也不行
//88=>(88,1)+91=>(172,2)+95=>(274,3)
//计算时需要将val的格式发生改变,只需要第一个v发生改变结构即可
//如果计算时发现相同key的value不符合计算规格的格式的话,那么选择combineByKey
//combineByKey方法可以传递3个参数
//第一个参数表示的是将计算的第一个值转换结构
//第二个参数表示的是分区内的计算规则
//第三个参数表示的是分区间的计算规则
val result: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
result.map {
case (key, (total, cnt)) => {
(key, total / cnt)
}
}.collect().foreach(println)
sc.stop()
}
}
reduceByKey、foldByKey、aggregateByKey、combineByKey的区别?
从源码角度来讲,算子底层逻辑相同,
reduceByKey
createCombiner: V => C, //第一个value不进行处理 ,分区内和分区间计算规则相同
mergeValue: (C, V) => C, //分区内的计算规则
mergeCombiners: (C, C) => C) //分区间的计算规则
aggregateByKey
createCombiner: V => C, //初始值和第一个value使用分区内计算规则进行计算
mergeValue: (C, V) => C, //分区内的计算规则
mergeCombiners: (C, C) => C) //分区间的计算规则
foldByKey
createCombiner: V => C, //初始值和第一个value使用分区内计算规则进行计算
mergeValue: (C, V) => C, //分区内和分区间的计算规则相同
mergeCombiners: (C, C) => C)
combineByKey
createCombiner: V => C, //对第一个value进行处理
mergeValue: (C, V) => C, //分区内的计算规则
mergeCombiners: (C, C) => C) //分区间的计算规则
sortByKey
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark42_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(("a", 1), ("c", 3), ("b", 2))
)
//val sortRDD: RDD[(String, Int)] = rdd.sortByKey(true)
val rdd1: RDD[(User, Int)] = sc.makeRDD(
List(
(new User(), 1),
(new User(), 2),
(new User(), 3)
)
)
//其实就是sortBy
val sortRDD: RDD[(User, Int)] = rdd1.sortByKey()
println(sortRDD.collect().mkString(","))
sc.stop()
}
//如果自定义key排序,需要将key混入特质Ordered
class User extends Ordered[User] with Serializable {
override def compare(that: User): Int = {
1
}
}
}
join
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark43_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 1), ("b", 2), ("a", 6))
)
val rdd2: RDD[(String, Int)] = sc.makeRDD(
List(("b", 6), ("a", 4), ("c", 5),("a",3))
)
//join方法可以将两个rdd中相同的key的value连接在一起
val result: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
//也会有点笛卡尔乘积的意思 会与下面每个都匹配,存在shuffle,性能不高 ,能不用尽量不用
println(result.collect().mkString(","))
//(a,(1,4)),(a,(1,3)),(a,(6,4)),(a,(6,3)),(b,(2,6))
sc.stop()
}
}
如果key存在不相等呢?
如果key不相等对应的数据无法连接,如果key有重复的,那么数据会多次连接
leftOuterJoin cogroup
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark44_RDD_Operator {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 1), ("b", 2), ("c", 3),("c", 4))
)
val rdd2: RDD[(String, Int)] = sc.makeRDD(
List(("b", 5), ("a", 4),("b", 6))
)
//leftOuterJoin
//rightOuterJoin
val result: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
result.collect().foreach(println)
//cogroup 内部先连下 再与外部rdd连
val result1: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
result1.collect().foreach(println)
sc.stop()
}
}
案例实操
agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。
统计出每一个省份每个广告被点击数量排行的Top3
需求分析:
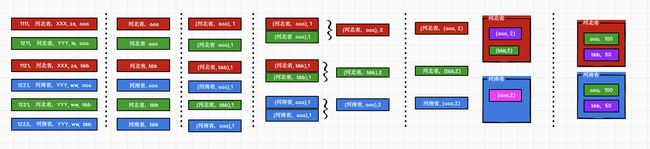
功能实现:
package com.vanas.bigdata.spark.rdd.operator.transfer
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-02 4:04 下午
*/
object Spark45_RDD_Operator_Req {
def main(args: Array[String]): Unit = {
//spark - RDD -算子(方法)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//统计出每一个省份每个广告被点击数量排行的Top3
//1.获取原始数据
val dataRDD: RDD[String] = sc.textFile("input/agent.log")
//2.将原始数据进行结构的转换,方便统计
//((省份-广告),1)
val mapRDD: RDD[(String, Int)] = dataRDD.map {
line => {
val datas: Array[String] = line.split(" ")
(datas(1) + "-" + datas(4), 1)
}
}
//3.将相同key的数据进行分组聚合
//((省份-广告),sum)
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
//4.将聚合后的结果进行结构的转换
//(省份,(广告,sum))
val mapRDD1: RDD[(String, (String, Int))] = reduceRDD.map {
case (key, sum) => {
val keys: Array[String] = key.split("-")
(keys(0), (keys(1), sum))
}
}
//5.将相同的省份的数据分在一个组中
//(省份,Iterator[(广告1,sum1),(广告2,sum2)])
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD1.groupByKey()
//6.将分组后的数据进行排序(降序),取前3 Top3
//scala mapvalues
val sortRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues(iter => {
iter.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(3)
})
//7.将数据采集到控制台打印
val result: Array[(String, List[(String, Int)])] = sortRDD.collect()
result.foreach(println)
sc.stop()
}
}
行动算子
package com.vanas.bigdata.spark.rdd.operator.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-06 11:34 上午
*/
object Spark46_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark 算子-行动算子
//所谓的行动算子,其实不会再产生 新的RDD,而是触发作业的执行
//行动算子执行后,会获取到作业的执行结果
//转换算子不会触发作业的执行,只是功能的扩展和包装
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//Spark的行动算子执行时,会产生Job对象,然后提交这个对象
val data: Array[Int] = rdd.collect()
data.foreach(println)
sc.stop()
}
}
reduce collect count first take
package com.vanas.bigdata.spark.rdd.operator.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-06 11:34 上午
*/
object Spark47_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark 算子-行动算子
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//reduce
//简化,规约
val i: Int = rdd.reduce(_ + _)
println(i)
//collect
//采集数据
//collect方法会将所有分区计算的结果拉取到当前节点Driver的内存中,可能会出现内存溢出
val array: Array[Int] = rdd.collect()
println(array.mkString(","))
//count
val cnt: Long = rdd.count()
println(cnt)
//first
val f: Int = rdd.first()
//take
val subarray: Array[Int] = rdd.take(3)
sc.stop()
}
}
Checkpoint 顺序,为什么会创建新的job?
Checkpoint是在运行作业之后执行的
checkpoint会创建新的job
takeOrdered
package com.vanas.bigdata.spark.rdd.operator.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-06 11:34 上午
*/
object Spark48_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark 算子-行动算子
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4))
//1,2,3,4=>1,2,3
//2,1,4=>1,2,4
val ints: Array[Int] = rdd.takeOrdered(3)//1,2,3
println(ints.mkString(","))
sc.stop()
}
}
sum aggregat fold countByKey
package com.vanas.bigdata.spark.rdd.operator.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-06 11:34 上午
*/
object Spark49_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark 算子-行动算子
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4), 2)
//sum
val d: Double = rdd.sum()
println(d)
//aggregate
//aggragateByKey:初始值只参与到分区内计算
//aggragate:初始值分区内计算会参与,同时分区间计算也会参与
val i: Int = rdd.aggregate(10)(_ + _, _ + _)
println(i) //40
//fold
val i1: Int = rdd.fold(10)(_ + _)
println(i1)
//countByKey
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 1), ("a", 1)
))
val stringToLong: collection.Map[String, Long] = rdd1.countByKey()
println(stringToLong)
val rdd2: RDD[String] = sc.makeRDD(List("a", "a", "a", "hello", "hello"))
val wordToCount: collection.Map[String, Long] = rdd2.countByValue()
println(wordToCount)
sc.stop()
}
}
save
package com.vanas.bigdata.spark.rdd.operator.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark50_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark 算子-行动算子
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4))
rdd.saveAsTextFile("output")
rdd.saveAsObjectFile("output1")
rdd.map((_, 1)).saveAsSequenceFile("output2")
sc.stop()
}
}
乱码解决方案
String s = "????"
byte[] bs = s.getBytes("ISO8859-1")
String okString = new String(bs,"UTF-8")
foreach
package com.vanas.bigdata.spark.rdd.operator.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-06 11:34 上午
*/
object Spark51_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark 算子-行动算子
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//foreach 方法
//集合的方法中的代码是在当前节点(Driver)中执行的
//foreach方法是在当前节点的内存中完成数据的循环
rdd.collect().foreach(println)
println("********************")
//foreach算子
//rdd的方法称之为算子
//算子的逻辑代码是在分布式计算节点Executor执行的
//foreach算子可以将循环在不同的计算节点完成
//算子之外的代码是在Driver端执行
rdd.foreach(println)
sc.stop()
}
}
10种算子wordcount
package com.vanas.bigdata.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-01 4:05 下午
*/
object Reduce_WordCount {
def main(args: Array[String]): Unit = {
//Spark _WordCount
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("a", "b", "c", "d"))
//reduce (Map,Map)=>Map
val mapRDD: RDD[Map[String, Int]] = rdd.map(word => Map[String, Int]((word, 1)))
val result: Map[String, Int] = mapRDD.reduce(
(map1, map2) => {
map1.foldLeft(map2)(
(map, kv) => {
val word = kv._1
val count = kv._2
map.updated(kv._1, map.getOrElse(word, 0) + count)
}
)
}
)
result.foreach(println)
sc.stop()
}
}
package com.vanas.bigdata.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-01 4:05 下午
*/
object Fold_WordCount {
def main(args: Array[String]): Unit = {
//Spark _WordCount
//groupByKey
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("a", "b", "c", "d"))
//1.groupBy
//2.groupByKey
//3.reduceByKey
//4.aggregateByKey
//5.foldByKey
//6.combineByKey
//7.countByKey
//8.countByValue
//9.reduce,fold,aggregate
//fold
val mapRDD: RDD[Map[String, Int]] = rdd.map(word => Map[String, Int]((word, 1)))
val result: Map[String, Int] = mapRDD.fold(Map[String, Int]())(
(map1, map2) => {
map1.foldLeft(map2)(
(map, kv) => {
val word = kv._1
val count = kv._2
map.updated(kv._1, map.getOrElse(word, 0) + count)
}
)
}
)
result.foreach(println)
//aggregate
val map: Map[String, Int] = rdd.aggregate(Map[String, Int]())(
(map, k) => {
map.updated(k, map.getOrElse(k, 0) + 1)
},
(map1, map2) => {
map1.foldLeft(map2)(
(map, kv) => {
val word = kv._1
val count = kv._2
map.updated(kv._1, map.getOrElse(word, 0) + count)
}
)
}
)
map.foreach(println)
sc.stop()
}
}
Spark序列化
package com.vanas.bigdata.spark.rdd.serial
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark52_Serial {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//Spark序列化
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
rdd.foreach(
num => {
val user = new User()
println("age= " + (user.age + num))
}
)
}
class User{
val age: Int = 20
}
}
//Exception: Task not serializable
//如果算子中使用了算子外的对象,那么执行时,需要保证这个对象能序列化
val user = new User()
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
rdd1.foreach(
num => {
println("age= " + (user.age + num))
}
)
class User extends Serializable {
val age: Int = 20
}
//样例类自动混入可序列化特质
//case class User(age: Int = 20)
//Scala闭包
val user1 = new User()
val rdd2: RDD[Int] = sc.makeRDD(List())
//Spark的算子的操作其实都是闭包,所以闭包有可能包含外部的变量
//如果包含外部的变量,那么就一定要保证这个外部变量可序列化
//所以Spark在提交作业之前,应该对闭包内的变量进行检测,检测是否能够序列化
//将这个操作为闭包检测
rdd2.foreach(
num => {
println("age= " + (user1.age + num)) //Exception
}
)
sc.stop()
}
class User{
val age: Int = 20
}
}
最简单的办法就是类序列化
package com.vanas.bigdata.spark.rdd.serial
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark53_Serial {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//3.创建一个RDD
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
//3.1创建一个Search对象
val search = new Search("hello")
//3.2 函数传递,打印:ERROR Task not serializable
search.getMatch1(rdd).collect().foreach(println)
//3.3 属性传递,打印:ERROR Task not serializable
search.getMatch2(rdd).collect().foreach(println)
//4.关闭连接
sc.stop()
}
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
//rdd.filter(this.isMatch)
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
//rdd.filter(x => x.contains(query))
val s = query //这样不序列化也可以
rdd.filter(x => x.contains(s))
}
}
}
Spark依赖关系
RDD血缘关系
package com.vanas.bigdata.spark.rdd.dep
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-06 3:44 下午
*/
object Spark54_Dep {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//new ParallelCollectionRDD
val rdd: RDD[String] = sc.makeRDD(List("hello scala", "hello spark"))
println(rdd.toDebugString)
println("---------------------------")
//new MapPartitionsRDD ->new ParallelCollectionRDD
val wordRDD: RDD[String] = rdd.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("---------------------------")
//new MapPartitionsRDD ->new MapPartitionsRDD
val mapRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
println(mapRDD.toDebugString)
println("---------------------------")
// new ShuffledRDD ->new MapPartitionsRDD
//shuffle
//如果Spark的计算的过程中某一个节点计算失败,那么框架会尝试重新计算
//Spark既然想重新计算,那么需要知道数据的来源,并且还要知道数据经历了哪些计算
//RDD不保存计算的数据,但是会保存元数据信息
val result: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
println(result.toDebugString)
println(result.collect().mkString(","))
sc.stop()
}
}
(1) ParallelCollectionRDD[0] at makeRDD at Spark54_Dep.scala:16 []
---------------------------
(1) MapPartitionsRDD[1] at flatMap at Spark54_Dep.scala:21 []
| ParallelCollectionRDD[0] at makeRDD at Spark54_Dep.scala:16 []
---------------------------
(1) MapPartitionsRDD[2] at map at Spark54_Dep.scala:26 []
| MapPartitionsRDD[1] at flatMap at Spark54_Dep.scala:21 []
| ParallelCollectionRDD[0] at makeRDD at Spark54_Dep.scala:16 []
---------------------------
(1) ShuffledRDD[3] at reduceByKey at Spark54_Dep.scala:35 []
+-(1) MapPartitionsRDD[2] at map at Spark54_Dep.scala:26 []
| MapPartitionsRDD[1] at flatMap at Spark54_Dep.scala:21 []
| ParallelCollectionRDD[0] at makeRDD at Spark54_Dep.scala:16 []
(scala,1),(spark,1),(hello,2)
RDD依赖关系
package com.vanas.bigdata.spark.rdd.dep
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark55_Dep {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("File-RDD")
val sc = new SparkContext(sparkConf)
//OneToOneDependency
//依赖关系中,现在的数据分区和依赖前的数据分区一一对应
val rdd: RDD[String] = sc.makeRDD(List("hello scala", "hello spark"))
println(rdd.dependencies)
println("---------------------------")
//OneToOneDependency
val wordRDD: RDD[String] = rdd.flatMap(_.split(" "))
println(wordRDD.dependencies)
println("---------------------------")
//OneToOneDependency
val mapRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
println(mapRDD.dependencies)
println("---------------------------")
//ShuffleDependenc(N:N)
val result: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
println(result.dependencies)
println(result.collect().mkString(","))
sc.stop()
}
}
List()
---------------------------
List(org.apache.spark.OneToOneDependency@5b78fdb1)
---------------------------
List(org.apache.spark.OneToOneDependency@60921b21)
---------------------------
List(org.apache.spark.ShuffleDependency@7ce7e83c)
(scala,1),(spark,1),(hello,2)
窄依赖
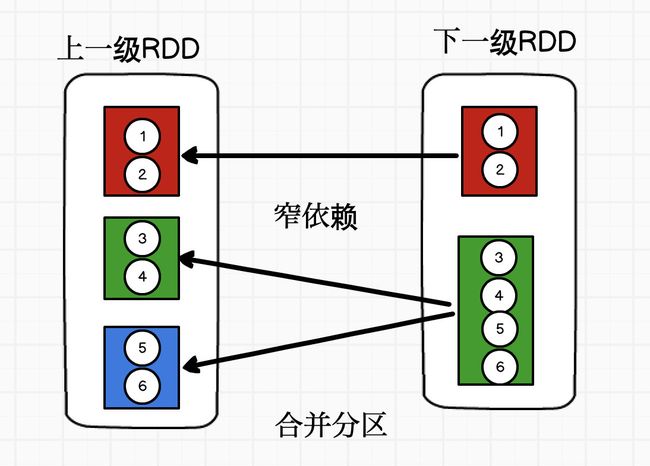
1对1的关系
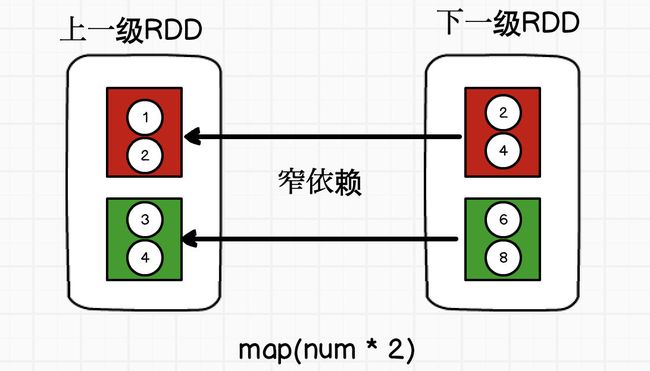
宽依赖

合并分区情况?
窄依赖 与别人无关
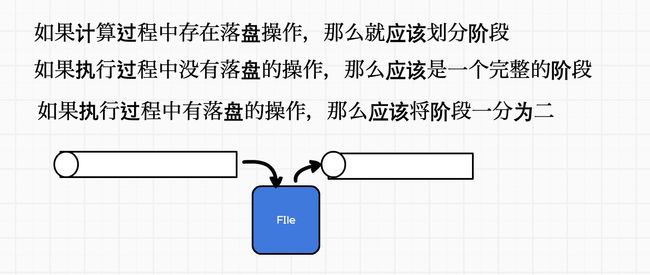
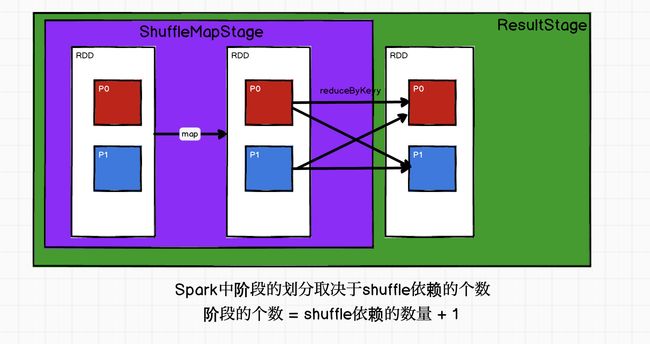
RDD阶段划分
scala> val rdd = sc.makeRDD(List(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at :24
scala> rdd.collect
res0: Array[Int] = Array(1, 2, 3, 4)
scala> val rdd = sc.makeRDD(List("hello scala","hello spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at makeRDD at :24
scala> rdd.flatMap(_.split(" ")).collect
res2: Array[String] = Array(hello, scala, hello, spark)
scala> rdd.flatMap(_.split(" ")).map((_,1)).collect
res3: Array[(String, Int)] = Array((hello,1), (scala,1), (hello,1), (spark,1))
scala> rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res5: Array[(String, Int)] = Array((spark,1), (scala,1), (hello,2))
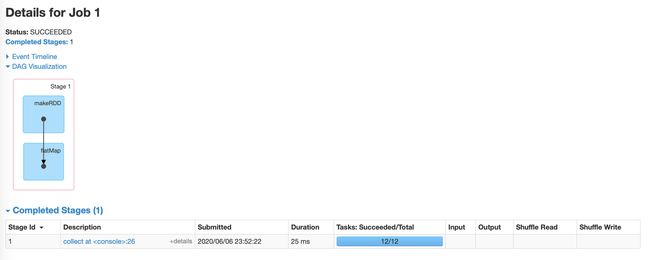

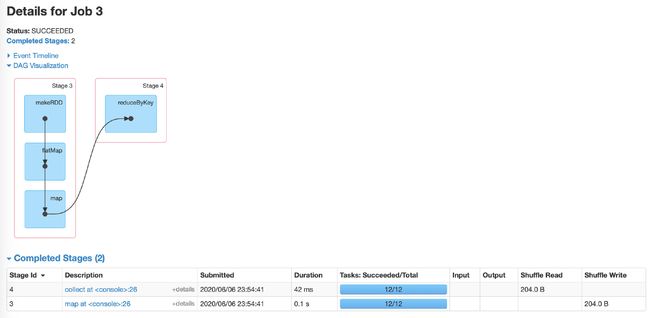
源码
val parents = getOrCreateParentStages(rdd, jobId)
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ArrayStack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
RDD任务划分
RDD持久化
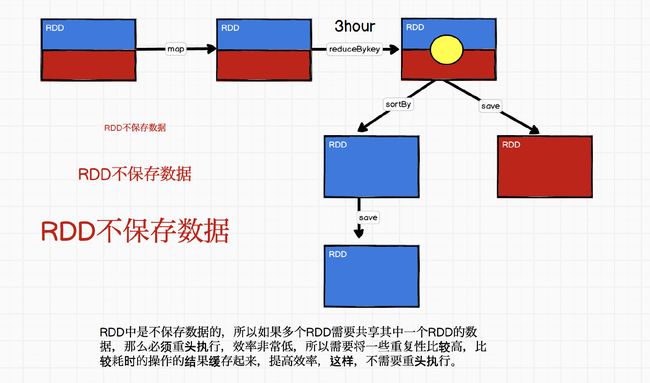
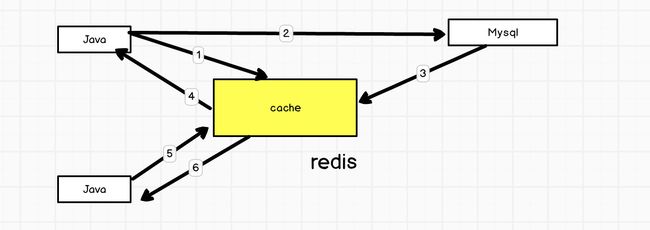
package com.vanas.bigdata.spark.rdd.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 10:40 上午
*/
object Spark55_Persist {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val mapRDD: RDD[(Int, Int)] = rdd.map(
num => {
println("map...")
(num, 1)
})
//将计算结果进行缓存,重复使用,提高效率
//默认缓存是存储在Excutor端的内存中,数据量大的时候该如何处理?
//缓存cache底层其实调用的persist方法
//persist方法在持久化数据时会采用不同的存储级别对数据进行持久化操作
//cache缓存的默认操作就是将数据保存到内存
//cache存储的数据在内存中,如果内存不够用,executor可以将内存的数据进行整理,然后可以丢弃数据
//如果由于executor端整理内存导致缓存的数据丢失,那么数据操作依然要重头执行
//如果cache后的数据重头执行数据操作的话,那么必须要遵序血缘关系所以chache操作不能删除血缘关系
val cacheRDD: mapRDD.type = mapRDD.cache()
println(cacheRDD.toDebugString)
//collect
println(cacheRDD.collect().mkString(","))
println("***************************")
//Save
println(cacheRDD.collect().mkString("&"))
//cacheRDD.saveAsTextFile("output")
sc.stop()
}
}
cache不返回也可以用?
def cache(): this.type = persist()
cache返回的RDD和当前的RDD是同一个
累加器
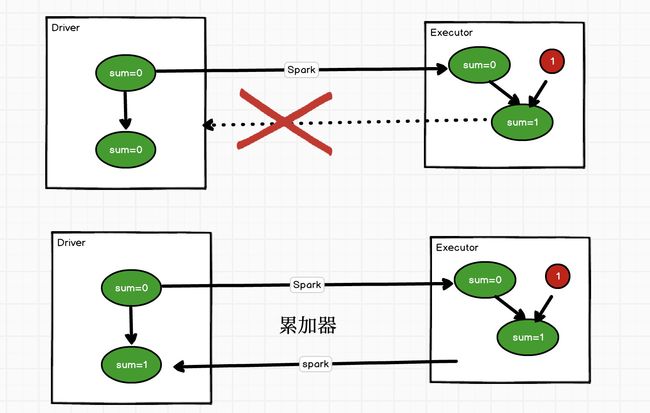
package com.vanas.bigdata.spark.acc
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 11:52 上午
*/
object Spark60_Acc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3)
))
//val sum: Int = rdd.reduce(_ + _)
//println("sum = " + sum)
var sum = 0
rdd.foreach {
case (word, count) => {
sum = sum + count
println(sum)
}
}
println("(a," + sum + ")") //0
sc.stop()
}
}
package com.vanas.bigdata.spark.acc
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 11:52 上午
*/
object Spark61_Acc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//使用累加器完成数据的累加
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//声明累加器变量
val sum: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(
num => {
//使用累加器
sum.add(num)
}
)
//获取累加器的结果
println("结果为=" + sum.value)
sc.stop()
}
}
累加器:分布式共享只写变量
所谓的累加器,一般的作用为累加(数值增加,数据的累加)数据
1.将累加器变量注册到spark中
2.执行计算时,spark会将累加器发送到executor执行计算
3.计算完毕后,executor会将累加器的计算结果返回到driver端
4.driver端获取到多个累加器的结果,然后两两合并,最后得到累加器的执行结果

累加器的merge方法什么时候调用的?
merge方法是在任务执行完成后由Driver端进行调用的
自定义累加器
package com.vanas.bigdata.spark.acc
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author Vanas
* @create 2020-06-08 11:52 上午
*/
object Spark63_Acc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//累加器:wordcount
val rdd: RDD[String] = sc.makeRDD(List("hello scala", "hello", "spark", "scala"))
//1.创建累加器
val acc = new MyWordCountAccumulator
//2.注册累加器
sc.register(acc)
//3.使用累加器
rdd.flatMap(_.split(" ")).foreach(
word => {
acc.add(word)
}
)
//4.获取累加器的值
println(acc.value)
sc.stop()
}
//自定义累加器
//1.继承AccumulatorV2,定义泛型[IN,OUT]
// IN:累加器输入的值的类型
// OUT:累加器返回结果的类型
//2.重写方法(6)
//3.copyAndReset must return a zero value copy
class MyWordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Int]] {
//存储wordcount的集合
var wordCountMap = mutable.Map[String, Int]()
//前3个方法是在做闭包检测序列化的时候调用的,序列化会执行很多次
//累加器是否初始化
override def isZero: Boolean = {
wordCountMap.isEmpty
}
//复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {
new MyWordCountAccumulator
}
//重制累加器
override def reset(): Unit = {
wordCountMap.clear()
}
//向累加器中增加值 ???值得是未知
override def add(word: String): Unit = {
//word =>wordcount
//wordCountMap(word) = wordCountMap.getOrElse(word, 0) + 1
wordCountMap.update(word, wordCountMap.getOrElse(word, 0) + 1)
}
//合并当前累加器和其他累加器
//合并累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
val map1 = wordCountMap
val map2 = other.value
wordCountMap = map1.foldLeft(map2)(
(map, kv) => {
map(kv._1) = map.getOrElse(kv._1, 0) + kv._2
map
}
)
}
//返回累加器的值(Out)
override def value: mutable.Map[String, Int] = {
wordCountMap
}
}
}
广播变量
package com.vanas.bigdata.spark.acc
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 11:52 上午
*/
object Spark64_BC {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//Spark 广播变量
//join会有笛卡尔乘积效果,数据量会急剧增多,如果有shuffle,那么性能会非常低
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
//(a,(1,1)),(b,(2,2)),(c,(3,3))
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
println(joinRDD.collect().mkString(","))
sc.stop()
}
}
package com.vanas.bigdata.spark.acc
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 11:52 上午
*/
object Spark65_BC {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//Spark 广播变量
//join会有笛卡尔乘积效果,数据量会急剧增多,如果有shuffle,那么性能会非常低
//为了解决join出现的性能问题,可以将数据独立出来,防止shuffle操作
//这样的话,会导致数据每个task会复制一份,那么executor内存中会有大量冗余,性能会受到影响
//所以可以采用广播变量,将数据保存到executor的内存中
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val list = List(("a", 4), ("b", 5), ("c", 6))
//(a,(1,1)),(b,(2,2)),(c,(3,3))
//("a", 1)=>(a,(1,4))
val rdd2 = rdd1.map {
case (word, count1) => {
var count2 = 0
for (kv <- list) {
val w = kv._1
val v = kv._2
if (w == word) {
count2 = v
}
}
(word, (count1, count2))
}
}
println(rdd2.collect().mkString(","))
sc.stop()
}
}
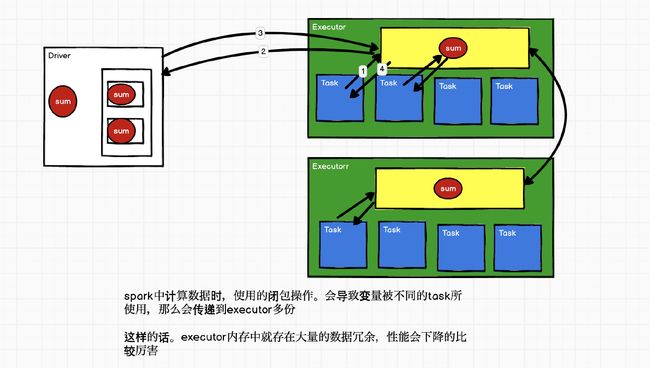
package com.vanas.bigdata.spark.acc
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-08 11:52 上午
*/
object Spark66_BC {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkConf)
//Spark 广播变量
//广播变量:分布式共享只读变量
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val list = List(("a", 4), ("b", 5), ("c", 6))
//声明广播变量
val bcList: Broadcast[List[(String, Int)]] = sc.broadcast(list)
val rdd2 = rdd1.map {
case (word, count1) => {
var count2 = 0
//使用广播变量
for (kv <- bcList.value) {
val w = kv._1
val v = kv._2
if (w == word) {
count2 = v
}
}
(word, (count1, count2))
}
}
println(rdd2.collect().mkString(","))
sc.stop()
}
}
Spark案例实操
wordcount
Spark添加依赖
<dependency>
<groupId>com.vanas.bigdatagroupId>
<artifactId>summer-frameworksartifactId>
<version>1.0-SNAPSHOTversion>
dependency>
Summer-framework
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>2.4.5version>
dependency>
dependencies>
三层架构模式
TApplication
package com.vanas.summer.framework.core
import java.net.{ServerSocket, Socket}
import com.vanas.summer.framework.util.PropertiesUtil
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-05-22 8:18 下午
*/
trait TApplication {
var envData: Any = null //为了得到环境变量
/**
* 开发原则:OCP开发原则 OpenClose(开闭原则)
* Open:开发的程序代码应该对功能拓展开放
* Close:在扩展的同时不应该对原有的代码进行修改
*
* 启动应用
* 1.函数柯里化
* 2.控制抽象
*
* t:参数类型:jdbc 、file、hive、kafka,soket,serverSocket
*/
def start(t: String)(op: => Unit): Unit = {
//1.初始化
if (t == "socket") {
envData = new Socket(PropertiesUtil.getValue("server.host"),
PropertiesUtil.getValue("server.port").toInt)
} else if (t == "serverSocket") {
envData = new ServerSocket(PropertiesUtil.getValue("server.port").toInt)
} else if (t == "spark") {
val sparkConf = new SparkConf().setMaster("local").setAppName("sparkApplication")
envData = new SparkContext(sparkConf)
}
//2.业务逻辑
try {
op
} catch {
case ex: Exception => println("业务执行失败" + ex.getMessage)
}
//3.环境关闭
if (t == "socket") {
val socket = envData.asInstanceOf[Socket]
if (socket.isClosed) {
socket.close()
}
} else if (t == "serverSocket") {
val server = envData.asInstanceOf[ServerSocket]
if (server.isClosed) {
server.close()
}
}else if (t =="spark"){
val sc: SparkContext = envData.asInstanceOf[SparkContext]
sc.stop()
}
}
}
TController
package com.vanas.summer.framework.core
/**
* @author Vanas
* @create 2020-06-08 4:57 下午
*/
trait TController {
//执行控制
def excute(): Unit
}
TService
package com.vanas.summer.framework.core
/**
* @author Vanas
* @create 2020-06-08 4:59 下午
*/
trait TService {
/**
* 数据分析
*/
def analysis():Any
}
TDao
package com.vanas.summer.framework.core
/**
* @author Vanas
* @create 2020-06-08 8:14 下午
*/
trait TDao {
}
WordCountApplication
package com.vanas.bigdata.spark.req.application
import com.vanas.bigdata.spark.req.controller.WordCountController
import com.vanas.summer.framework.core.TApplication
/**
* @author Vanas
* @create 2020-06-08 4:41 下午
*/
object WordCountApplication extends App with TApplication {
start("spark") {
val controller = new WordCountController
controller.excute()
}
}
WordCountController
package com.vanas.bigdata.spark.req.controller
import com.vanas.bigdata.spark.req.service.WordCountService
import com.vanas.summer.framework.core.TController
/**
* wordcount控制器
*
* @author Vanas
* @create 2020-06-08 8:11 下午
*/
class WordCountController extends TController {
private val wordCountService = new WordCountService
override def excute(): Unit = {
val wordCountArray: Array[(String, Int)] = wordCountService.analysis()
println(wordCountArray.mkString(","))
}
}
WordCountService
package com.vanas.bigdata.spark.req.service
import com.vanas.bigdata.spark.req.application.WordCountApplication.envData
import com.vanas.bigdata.spark.req.dao.WordCountDao
import com.vanas.summer.framework.core.TService
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-08 8:13 下午
*/
class WordCountService extends TService {
private val wordCountDao = new WordCountDao
/**
* 数据分析
*/
override def analysis() = {
val sc: SparkContext = envData.asInstanceOf[SparkContext]
val fileRDD: RDD[String] = sc.textFile("input/word.txt")
val word: RDD[String] = fileRDD.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = word.map(word => (word, 1))
val wordToSumRdd: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
val wordCountArray: Array[(String, Int)] = wordToSumRdd.collect()
wordCountArray
}
}
WordCountDao
package com.vanas.bigdata.spark.req.dao
import com.vanas.summer.framework.core.TDao
/**
* @author Vanas
* @create 2020-06-08 5:02 下午
*/
class WordCountDao extends TDao{
}
优化
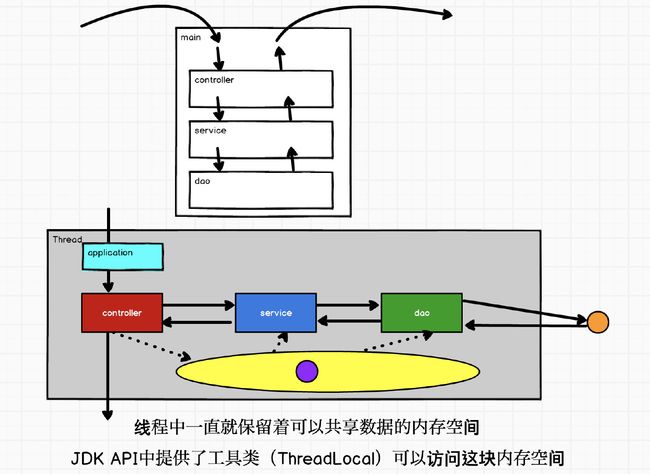
EnvUtil
共用内存空间
package com.vanas.summer.framework.util
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Vanas
* @create 2020-06-09 10:11 上午
*/
object EnvUtil {
private val scLocal = new ThreadLocal[SparkContext]
def getEnv() = {
//从当前线程的共享内存空间中获取环境对象
var sc: SparkContext = scLocal.get()
if (sc == null) {
//如果获取不到环境对象
val sparkConf = new SparkConf().setMaster("local").setAppName("sparkApplication")
//创建新的环境对象
sc = new SparkContext(sparkConf)
//保存到共享内存中
scLocal.set(sc)
}
sc
}
def clear() = {
getEnv.stop()
//将共享内存中的数据清除掉
scLocal.remove()
}
}
TApplication
package com.vanas.summer.framework.core
import java.net.{ServerSocket, Socket}
import com.vanas.summer.framework.util.{EnvUtil, PropertiesUtil}
/**
* @author Vanas
* @create 2020-05-22 8:18 下午
*/
trait TApplication {
var envData: Any = null //为了得到环境变量
/**
* 开发原则:OCP开发原则 OpenClose(开闭原则)
* Open:开发的程序代码应该对功能拓展开放
* Close:在扩展的同时不应该对原有的代码进行修改
* 启动应用
* 1.函数柯里化
* 2.控制抽象
*
* t:参数类型:jdbc 、file、hive、kafka,soket,serverSocket
*/
def start(t: String)(op: => Unit): Unit = {
//1.初始化
if (t == "socket") {
envData = new Socket(PropertiesUtil.getValue("server.host"),
PropertiesUtil.getValue("server.port").toInt)
} else if (t == "serverSocket") {
envData = new ServerSocket(PropertiesUtil.getValue("server.port").toInt)
} else if (t == "spark") {
envData = EnvUtil.getEnv()
}
//2.业务逻辑
try {
op
} catch {
case ex: Exception => println("业务执行失败" + ex.getMessage)
}
//3.环境关闭
if (t == "socket") {
val socket = envData.asInstanceOf[Socket]
if (socket.isClosed) {
socket.close()
}
} else if (t == "serverSocket") {
val server = envData.asInstanceOf[ServerSocket]
if (server.isClosed) {
server.close()
}
} else if (t == "spark") {
EnvUtil.clear()
}
}
}
TDao
package com.vanas.summer.framework.core
import com.vanas.summer.framework.util.EnvUtil
/**
* @author Vanas
* @create 2020-06-08 8:14 下午
*/
trait TDao {
def readFile(path: String) = {
EnvUtil.getEnv().textFile(path)
}
}
WordCountService
package com.vanas.bigdata.spark.req.service
import com.vanas.bigdata.spark.req.dao.WordCountDao
import com.vanas.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-08 8:13 下午
*/
class WordCountService extends TService {
private val wordCountDao = new WordCountDao
/**
* 数据分析
*/
override def analysis() = {
val fileRDD: RDD[String] = wordCountDao.readFile("input/word.txt")
val word: RDD[String] = fileRDD.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = word.map(word => (word, 1))
val wordToSumRdd: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
val wordCountArray: Array[(String, Int)] = wordToSumRdd.collect()
wordCountArray
}
}
电商需求Top10
HotCategoryAnalysisTop10Application
package com.vanas.bigdata.spark.req.application
import com.vanas.bigdata.spark.req.controller.HotcategoryAnalysisTop10Controller
import com.vanas.summer.framework.core.TApplication
/**
* @author Vanas
* @create 2020-06-09 10:36 上午
*/
object HotCategoryAnalysisTop10Application extends App with TApplication{
//热门品类前10应用程序
start("spark"){
val controller = new HotcategoryAnalysisTop10Controller
controller.excute()
}
}
HotcategoryAnalysisTop10Controller
package com.vanas.bigdata.spark.req.controller
import com.vanas.bigdata.spark.req.service.HotCategoryAnalysisTop10Service
import com.vanas.summer.framework.core.TController
/**
* @author Vanas
* @create 2020-06-09 10:40 上午
*/
class HotcategoryAnalysisTop10Controller extends TController {
private val hotCategoryAnalysisTop10Service = new HotCategoryAnalysisTop10Service
override def excute(): Unit = {
val result = hotCategoryAnalysisTop10Service.analysis()
result.foreach(println)
}
}
HotCategoryAnalysisTop10Service
package com.vanas.bigdata.spark.req.service
import com.vanas.bigdata.spark.req.dao.HotCategoryAnalysisTop10Dao
import com.vanas.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-09 10:39 上午
*/
class HotCategoryAnalysisTop10Service extends TService {
private val hotCategoryAnalysisTop10Dao = new HotCategoryAnalysisTop10Dao
/**
* 数据分析
*/
override def analysis() = {
//读取电商日志数据
val actionRDD: RDD[String] = hotCategoryAnalysisTop10Dao.readFile("input/user_visit_action.txt")
//对品类进行点击的统计
val clickRDD = actionRDD.map {
action => {
val datas = action.split("_")
(datas(6), 1)
}
}.filter(_._1 != "-1")
val categoryIdToClickCountRDD: RDD[(String, Int)] = clickRDD.reduceByKey(_ + _)
//对品类进行下单的统计
//line=>(category,orderCount)
//(品类1,品类2,品类3,10)
//(品类1,10),(品类2,10),(品类3,10)
val orderRDD = actionRDD.map {
action => {
val datas = action.split("_")
datas(8)
}
}.filter(_ != "null")
val orderToOneRDD: RDD[(String, Int)] = orderRDD.flatMap {
case (id) => {
val ids: Array[String] = id.split(",")
ids.map(id => (id, 1))
}
}
val categoryIdToOrderCountRDD: RDD[(String, Int)] = orderToOneRDD.reduceByKey(_ + _)
//对品类进行支付的统计
//(category,payCount)
val payRDD = actionRDD.map {
action => {
val datas = action.split("_")
datas(10)
}
}.filter(_ != "null")
val payToOneRDD: RDD[(String, Int)] = payRDD.flatMap {
case (id) => {
val ids: Array[String] = id.split(",")
ids.map(id => (id, 1))
}
}
val categoryIdTopPayCountRDD: RDD[(String, Int)] = payToOneRDD.reduceByKey(_ + _)
//将上面统计的结果转换结构
//tuple=>(元素1,元素2,元素3)
//(品类,点击数量),(品类,下单数量),(品类,支付数量)
//(品类,(点击数量,下单数量,支付数量))
val joinRDD: RDD[(String, (Int, Int))] = categoryIdToClickCountRDD.join(categoryIdToOrderCountRDD)
val joinRDD1: RDD[(String, ((Int, Int), Int))] = joinRDD.join(categoryIdTopPayCountRDD)
val mapRDD: RDD[(String, (Int, Int, Int))] = joinRDD1.mapValues {
case ((clickCount, orderCount), paycount) => {
(clickCount, orderCount, paycount)
}
}
//将转换结构后的数据进行排序(降序)
val sortRDD: RDD[(String, (Int, Int, Int))] = mapRDD.sortBy(_._2, false)
//将排序后的结果取前10名
val result: Array[(String, (Int, Int, Int))] = sortRDD.take(10)
result
}
}
HotCategoryAnalysisTop10Dao
package com.vanas.bigdata.spark.req.dao
import com.vanas.summer.framework.core.TDao
/**
* @author Vanas
* @create 2020-06-09 10:48 上午
*/
class HotCategoryAnalysisTop10Dao extends TDao{
}
优化1
优化缓存,笛卡尔乘积
/**
* 数据分析
*/
def analysis1() = {
//读取电商日志数据
val actionRDD: RDD[String] = hotCategoryAnalysisTop10Dao.readFile("input/user_visit_action.txt")
//优化 缓存
actionRDD.cache()
//对品类进行点击的统计
val clickRDD = actionRDD.map {
action => {
val datas = action.split("_")
(datas(6), 1)
}
}.filter(_._1 != "-1")
val categoryIdToClickCountRDD: RDD[(String, Int)] = clickRDD.reduceByKey(_ + _)
//对品类进行下单的统计
//line=>(category,orderCount)
//(品类1,品类2,品类3,10)
//(品类1,10),(品类2,10),(品类3,10)
val orderRDD = actionRDD.map {
action => {
val datas = action.split("_")
datas(8)
}
}.filter(_ != "null")
val orderToOneRDD: RDD[(String, Int)] = orderRDD.flatMap {
case (id) => {
val ids: Array[String] = id.split(",")
ids.map(id => (id, 1))
}
}
val categoryIdToOrderCountRDD: RDD[(String, Int)] = orderToOneRDD.reduceByKey(_ + _)
//对品类进行支付的统计
//(category,payCount)
val payRDD = actionRDD.map {
action => {
val datas = action.split("_")
datas(10)
}
}.filter(_ != "null")
val payToOneRDD: RDD[(String, Int)] = payRDD.flatMap {
case (id) => {
val ids: Array[String] = id.split(",")
ids.map(id => (id, 1))
}
}
val categoryIdTopPayCountRDD: RDD[(String, Int)] = payToOneRDD.reduceByKey(_ + _)
//将上面统计的结果转换结构
//tuple=>(元素1,元素2,元素3)
//(品类,点击数量),(品类,下单数量),(品类,支付数量)
//(品类,点击数量,0,0),(品类,(0,下单数量,0)),(品类,(0,0支付数量))
//(品类,(点击数量,下单数量,支付数量))
//优化 因为之前有笛卡尔乘积
//reduceByKey
val newCtegoryIdToCilickCountRDD: RDD[(String, (Int, Int, Int))] = categoryIdToClickCountRDD.map {
case (id, clickCount) => {
(id, (clickCount, 0, 0))
}
}
val newcategoryIdToOrderCountRDD: RDD[(String, (Int, Int, Int))] = categoryIdToOrderCountRDD.map {
case (id, orderCount) => {
(id, (0, orderCount, 0))
}
}
val newcategoryIdTopPayCountRDD: RDD[(String, (Int, Int, Int))] = categoryIdTopPayCountRDD.map {
case (id, payCount) => {
(id, (0, 0, payCount))
}
}
val countRDD: RDD[(String, (Int, Int, Int))] = newCtegoryIdToCilickCountRDD.union(newcategoryIdToOrderCountRDD).union(newcategoryIdTopPayCountRDD)
val reduceCountRDD: RDD[(String, (Int, Int, Int))] = countRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
//将转换结构后的数据进行排序(降序)
val sortRDD: RDD[(String, (Int, Int, Int))] = reduceCountRDD.sortBy(_._2, false)
//将排序后的结果取前10名
val result: Array[(String, (Int, Int, Int))] = sortRDD.take(10)
result
}
优化2 读取次数
优化文件读取次数
/**
* 数据分析
*/
def analysis2() = {
//读取电商日志数据
val actionRDD: RDD[String] = hotCategoryAnalysisTop10Dao.readFile("input/user_visit_action.txt")
//代码量少,性能好:文件不需要读取很多次,没有笛卡尔乘积和大量shuffle
//line =>
// click(1,0,0)
// order(0,1,0)
// pay(0,0,1)
val flatMapRDD: RDD[(String, (Int, Int, Int))] = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
//点击的场合
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
//下单的场合
val ids: Array[String] = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
//支付的场合
val ids: Array[String] = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
)
val reduceRDD: RDD[(String, (Int, Int, Int))] = flatMapRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
val result: Array[(String, (Int, Int, Int))] = reduceRDD.sortBy(_._2, false).take(10)
result
}
优化3 包装类
package com.vanas.bigdata.spark.core.req
/**
* @author Vanas
* @create 2020-06-09 2:40 下午
*/
package object bean {
case class HotCategory(
categoryId: String,
var clickCount: Int,
var orderCount: Int,
var payCount: Int
)
}
/**
* 数据分析
*/
def analysis3() = {
//读取电商日志数据
val actionRDD: RDD[String] = hotCategoryAnalysisTop10Dao.readFile("input/user_visit_action.txt")
//代码量少,性能好:文件不需要读取很多次,没有笛卡尔乘积和大量shuffle
//line =>
// click = HotCategory(1,0,0)
// order = HotCategory(0,1,0)
// pay = HotCategory(0,0,1)
val flatMapRDD = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
//点击的场合
List((datas(6), HotCategory(datas(6), 1, 0, 0)))
} else if (datas(8) != "null") {
//下单的场合
val ids: Array[String] = datas(8).split(",")
ids.map(id => (id, HotCategory(id, 0, 1, 0)))
} else if (datas(10) != "null") {
//支付的场合
val ids = datas(10).split(",")
ids.map(id => (id, HotCategory(id, 0, 0, 1)))
} else {
Nil
}
}
)
val reduceRDD = flatMapRDD.reduceByKey(
(c1, c2) => {
c1.clickCount = c1.clickCount + c2.clickCount
c1.orderCount = c1.orderCount + c2.orderCount
c1.payCount = c1.payCount + c2.payCount
c1
}
)
reduceRDD.collect().sortWith(
(left, right) => {
val leftHC: HotCategory = left._2
val rightHC: HotCategory = right._2
if (leftHC.clickCount > rightHC.clickCount) {
true
} else if (leftHC.clickCount == rightHC.clickCount) {
if (leftHC.orderCount > rightHC.orderCount) {
true
} else if (leftHC.orderCount == rightHC.orderCount) {
leftHC.payCount > rightHC.payCount
} else {
false
}
} else {
false
}
}
).take(10)
}
优化4 累加器
package com.vanas.bigdata.spark.core.req.helper
import com.vanas.bigdata.spark.core.req.bean.HotCategory
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
/**
* 热门品类累加器
* 1.继承AccumulatorV2,定义泛型[in,out]
* IN:(品类,行为类型)
* OUT:Map[品类,HotCategory]
* 2.重写方法(6)
*/
class HotCategoryAccumulator extends AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] {
val hotCategoryMap = mutable.Map[String, HotCategory]()
override def isZero: Boolean = hotCategoryMap.isEmpty
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] = {
new HotCategoryAccumulator
}
override def reset(): Unit = {
hotCategoryMap.clear()
}
override def add(v: (String, String)): Unit = {
val cid = v._1
val actionType = v._2
val hotCategory: HotCategory = hotCategoryMap.getOrElse(cid, HotCategory(cid, 0, 0, 0))
actionType match {
case "click" => hotCategory.clickCount += 1
case "order" => hotCategory.orderCount += 1
case "pay" => hotCategory.payCount += 1
case _ =>
}
hotCategoryMap(cid) = hotCategory
}
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCategory]]): Unit = {
other.value.foreach {
case (cid, hotCategory) => {
val hc: HotCategory = hotCategoryMap.getOrElse(cid, HotCategory(cid, 0, 0, 0))
hc.clickCount += hotCategory.clickCount
hc.orderCount += hotCategory.orderCount
hc.payCount += hotCategory.payCount
hotCategoryMap(cid) = hc
}
}
}
override def value: mutable.Map[String, HotCategory] = {
hotCategoryMap
}
}
/**
* 数据分析
*/
def analysis4() = {
//读取电商日志数据
val actionRDD: RDD[String] = hotCategoryAnalysisTop10Dao.readFile("input/user_visit_action.txt")
//对品类进行点击的统计
//使用累加器对数据进行聚合
val acc = new HotCategoryAccumulator
EnvUtil.getEnv().register(acc, "hotCategory")
//将数据循环,向累加器中放
actionRDD.foreach(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
//点击的场合
acc.add((datas(6), "click"))
} else if (datas(8) != "null") {
//下单的场合
val ids = datas(8).split(",")
ids.foreach(
id => {
acc.add((id, "order"))
}
)
} else if (datas(10) != "null") {
//支付的场合
val ids = datas(10).split(",")
ids.foreach(
id => {
acc.add((id, "pay"))
}
)
} else {
Nil
}
}
)
//获取累加器的值
val accValue: mutable.Map[String, HotCategory] = acc.value
val categories: mutable.Iterable[HotCategory] = accValue.map(_._2)
categories.toList.sortWith(
(leftHC, rightHC) => {
if (leftHC.clickCount > rightHC.clickCount) {
true
} else if (leftHC.clickCount == rightHC.clickCount) {
if (leftHC.orderCount > rightHC.orderCount) {
true
} else if (leftHC.orderCount == rightHC.orderCount) {
leftHC.payCount > rightHC.payCount
} else {
false
}
} else {
false
}
}
).take(10)
}
电商需求:Session统计
需求2:Top10热门品类中每个品类的Top10活跃Session统计
在上一个需求基础之上做
bean
package com.vanas.bigdata.spark.core.req
/**
* @author Vanas
* @create 2020-06-09 2:40 下午
*/
package object bean {
case class HotCategory(
categoryId: String,
var clickCount: Int,
var orderCount: Int,
var payCount: Int
)
//用户访问动作表
case class UserVisitAction(
date: String, //用户点击行为的日期
user_id: Long, //用户的ID
session_id: String, //Session的ID
page_id: Long, //某个页面的ID
action_time: String, //动作的时间点
search_keyword: String, //用户搜索的关键词
click_category_id: Long, //某一个商品品类的ID
click_product_id: Long, //某一个商品的ID
order_category_ids: String, //一次订单中所有品类的ID集合
order_product_ids: String, //一次订单中所有商品的ID集合
pay_category_ids: String, //一次支付中所有品类的ID集合
pay_product_ids: String, //一次支付中所有商品的ID集合
city_id: Long
) //城市 id
}
TService
package com.vanas.summer.framework.core
/**
* @author Vanas
* @create 2020-06-08 4:59 下午
*/
trait TService {
/**
* 数据分析
*/
def analysis(): Any = {
}
def analysis(data: Any): Any = {
}
}
HotCategorySessionAnalysisTop10Application
package com.vanas.bigdata.spark.core.req.application
import com.vanas.bigdata.spark.core.req.controller.HotCategorySessionAnalysisTop10Controller
import com.vanas.summer.framework.core.TApplication
/**
* @author Vanas
* @create 2020-06-09 10:36 上午
*/
object HotCategorySessionAnalysisTop10Application extends App with TApplication{
//热门品类前10应用程序
start("spark"){
val controller = new HotCategorySessionAnalysisTop10Controller
controller.excute()
}
}
HotCategorySessionAnalysisTop10Controller
package com.vanas.bigdata.spark.core.req.controller
import com.vanas.bigdata.spark.core.req.bean
import com.vanas.bigdata.spark.core.req.service.{HotCategoryAnalysisTop10Service, HotCategorySessionAnalysisTop10Service}
import com.vanas.summer.framework.core.TController
/**
* @author Vanas
* @create 2020-06-09 10:40 上午
*/
class HotCategorySessionAnalysisTop10Controller extends TController {
private val hotCategoryAnalysisTop10Service = new HotCategoryAnalysisTop10Service
private val hotCategorySessionAnalysisTop10Service = new HotCategorySessionAnalysisTop10Service
override def excute(): Unit = {
val categories: List[bean.HotCategory] = hotCategoryAnalysisTop10Service.analysis4()
val result = hotCategorySessionAnalysisTop10Service.analysis(categories)
result.foreach(println)
}
}
HotCategorySessionAnalysisTop10Service
package com.vanas.bigdata.spark.core.req.service
import com.vanas.bigdata.spark.core.req.bean
import com.vanas.bigdata.spark.core.req.dao.HotCategorySessionAnalysisTop10Dao
import com.vanas.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-09 10:39 上午
*/
class HotCategorySessionAnalysisTop10Service extends TService {
private val hotCategorySessionAnalysisTop10Dao = new HotCategorySessionAnalysisTop10Dao
/**
* 数据分析
*/
override def analysis(data: Any) = {
val top10: List[bean.HotCategory] = data.asInstanceOf[List[bean.HotCategory]]
//获取用户行为的数据
val actionRDD: RDD[bean.UserVisitAction] = hotCategorySessionAnalysisTop10Dao.getUserVisitAction("input/user_visit_action.txt")
//对数据进行过滤
//对用户的点击行为进行过滤
val fillterRDD: RDD[bean.UserVisitAction] = actionRDD.filter(
action => {
if (action.click_category_id != -1) {
var flg = false
top10.foreach(
hc => {
if (hc.categoryId.toLong == action.click_category_id) {
flg = true
}
}
)
flg
} else {
false
}
}
)
//将过滤后的数据进行处理
//(品类_session,1)=>(品类_session,sum)
val rdd: RDD[(String, Int)] = fillterRDD.map(
action => {
(action.click_category_id + "_" + action.session_id, 1)
}
)
val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey(_ + _)
//将统计后的结果进行结构转换
//(品类_session,sum)=>(品类,(session,sum))
val mapRDD: RDD[(String, (String, Int))] = reduceRDD.map {
case (key, count) => {
val ks: Array[String] = key.split("_")
(ks(0), (ks(1), count))
}
}
//将转换结构后的数据对品类进行分组
//(品类,Iterator[(session1,sum1),(session2,sum2)])
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupByKey()
//将分组后的数据进行排序取前10名
val resultRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues(
iter => {
iter.toList.sortWith(
(left, right) => {
left._2 > right._2
}
) .take(10)
}
)
resultRDD.collect()
}
}
HotCategorySessionAnalysisTop10Dao
package com.vanas.bigdata.spark.core.req.dao
import com.vanas.bigdata.spark.core.req.bean.UserVisitAction
import com.vanas.summer.framework.core.TDao
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-09 10:48 上午
*/
class HotCategorySessionAnalysisTop10Dao extends TDao{
def getUserVisitAction(path:String)={
val rdd: RDD[String] = readFile(path)
rdd.map(
line=>{
val datas: Array[String] = line.split("_")
UserVisitAction(
datas(0),
datas(1).toLong,
datas(2),
datas(3).toLong,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong
)
}
)
}
}
优化
过滤优化,广播变量
package com.vanas.bigdata.spark.core.req.service
import com.vanas.bigdata.spark.core.req.bean
import com.vanas.bigdata.spark.core.req.dao.HotCategorySessionAnalysisTop10Dao
import com.vanas.summer.framework.core.TService
import com.vanas.summer.framework.util.EnvUtil
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-09 10:39 上午
*/
class HotCategorySessionAnalysisTop10Service extends TService {
private val hotCategorySessionAnalysisTop10Dao = new HotCategorySessionAnalysisTop10Dao
/**
* 数据分析
*/
override def analysis(data: Any) = {
val top10: List[bean.HotCategory] = data.asInstanceOf[List[bean.HotCategory]]
val top10Ids: List[String] = top10.map(_.categoryId)
//使用广播变量实现数据的传播
val bcList: Broadcast[List[String]] = EnvUtil.getEnv().broadcast(top10Ids)
//获取用户行为的数据
val actionRDD: RDD[bean.UserVisitAction] = hotCategorySessionAnalysisTop10Dao.getUserVisitAction("input/user_visit_action.txt")
//对数据进行过滤
//对用户的点击行为进行过滤
val fillterRDD: RDD[bean.UserVisitAction] = actionRDD.filter(
action => {
if (action.click_category_id != -1) {
bcList.value.contains(action.click_category_id.toString)
//top10Ids.contains(action.click_category_id.toString)
} else {
false
}
}
)
//将过滤后的数据进行处理
//(品类_session,1)=>(品类_session,sum)
val rdd: RDD[(String, Int)] = fillterRDD.map(
action => {
(action.click_category_id + "_" + action.session_id, 1)
}
)
val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey(_ + _)
//将统计后的结果进行结构转换
//(品类_session,sum)=>(品类,(session,sum))
val mapRDD: RDD[(String, (String, Int))] = reduceRDD.map {
case (key, count) => {
val ks: Array[String] = key.split("_")
(ks(0), (ks(1), count))
}
}
//将转换结构后的数据对品类进行分组
//(品类,Iterator[(session1,sum1),(session2,sum2)])
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupByKey()
//将分组后的数据进行排序取前10名
val resultRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues(
iter => {
iter.toList.sortWith(
(left, right) => {
left._2 > right._2
}
) .take(10)
}
)
resultRDD.collect()
}
}
电商需求:页面单跳转换率统计
需求:
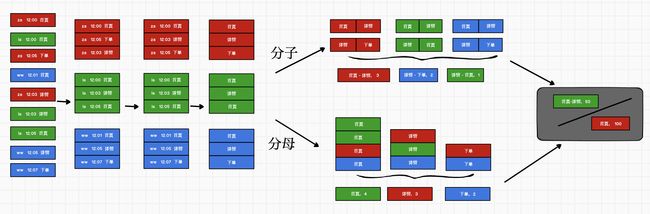
架构:
PageflowApplication
package com.vanas.bigdata.spark.core.req.application
import com.vanas.bigdata.spark.core.req.controller.PageflowController
import com.vanas.summer.framework.core.TApplication
/**
* @author Vanas
* @create 2020-06-10 9:49 下午
*/
object PageflowApplication extends App with TApplication {
start("spark") {
val controller = new PageflowController
controller.excute()
}
}
PageflowController
package com.vanas.bigdata.spark.core.req.controller
import com.vanas.bigdata.spark.core.req.service.PageflowService
import com.vanas.summer.framework.core.TController
/**
* @author Vanas
* @create 2020-06-10 10:28 下午
*/
class PageflowController extends TController {
private val pageflowService = new PageflowService
override def excute(): Unit = {
val result = pageflowService.analysis()
}
}
PageflowService
package com.vanas.bigdata.spark.core.req.service
import com.vanas.bigdata.spark.core.req.bean
import com.vanas.bigdata.spark.core.req.dao.PageflowDao
import com.vanas.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-10 10:28 下午
*/
class PageflowService extends TService {
private val pageflowDao = new PageflowDao
override def analysis() = {
//获取原始用户行为日志数据
val actionRDD: RDD[bean.UserVisitAction] =
pageflowDao.getUserVisitAction("input/user_visit_action.txt")
actionRDD.cache()
//计算分母
val pageToOneRDD: RDD[(Long, Int)] = actionRDD.map(
action => {
(action.page_id, 1)
}
)
val pageToSumRDD: RDD[(Long, Int)] = pageToOneRDD.reduceByKey(_ + _)
val pageCountArray: Array[(Long, Int)] = pageToSumRDD.collect()
pageCountArray
//计算分子
val sessionRDD: RDD[(String, Iterable[bean.UserVisitAction])] =
actionRDD.groupBy(_.session_id)
val pageFlowRDD: RDD[(String, List[(String, Int)])] = sessionRDD.mapValues(
iter => {
//将分组后的数据根据时间进行排序
val actions: List[bean.UserVisitAction] = iter.toList.sortWith(
(left, right) => {
left.action_time < right.action_time
}
)
//将排序后的数据进行结构的转换
//action=>pageid
val pageids: List[Long] = actions.map(_.page_id)
//将转换后的结果进行格式的转换
//1,2,3,4 (1-2)(2-3)(3-4)
val zipids: List[(Long, Long)] = pageids.zip(pageids.tail)
//((1-2),1)
zipids.map {
case (pageid1, pageid2) => {
(pageid1 + "-" + pageid2, 1)
}
}
}
)
//将分组后的数据进行结构转换
val pageidSumRDD: RDD[List[(String, Int)]] = pageFlowRDD.map(_._2)
//(1-2,1)
val pageflowRDD1: RDD[(String, Int)] = pageidSumRDD.flatMap(list => list)
//(1-2,sum)
val pageflowToSumRDD: RDD[(String, Int)] = pageflowRDD1.reduceByKey(_ + _)
//计算页面单跳转化率
//1-2/1
pageflowToSumRDD.foreach {
case (pageflow, sum) => {
val pageid: String = pageflow.split("-")( 0)
val value: Int = pageCountArray.toMap.getOrElse(pageid.toLong, 1)
println("页面跳转【" + pageflow + "】的转换率:" + (sum.toDouble / value))
}
}
}
}
PageflowDao
package com.vanas.bigdata.spark.core.req.dao
import com.vanas.bigdata.spark.core.req.bean.UserVisitAction
import com.vanas.summer.framework.core.TDao
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-10 10:31 下午
*/
class PageflowDao extends TDao{
def getUserVisitAction(path:String)={
val rdd: RDD[String] = readFile(path)
rdd.map(
line=>{
val datas: Array[String] = line.split("_")
UserVisitAction(
datas(0),
datas(1).toLong,
datas(2),
datas(3).toLong,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong
)
}
)
}
}
优化
过滤掉不需要的页面
override def analysis() = {
//对指定的页面流程进行页面单跳转换率的统计
//1,2,3,4,5,6,7
//1-2,2-3,3-4,4-5,5-6,6-7
//不用统计7 因为7 不出现
val flowIds = List(1, 2, 3, 4, 5, 6, 7)
val okFlowIds = flowIds.zip(flowIds.tail).map(t => (t._1 + "-" + t._2))
//获取原始用户行为日志数据
val actionRDD: RDD[bean.UserVisitAction] =
pageflowDao.getUserVisitAction("input/user_visit_action.txt")
actionRDD.cache()
//计算分母
//将数据过滤后再进行统计
val filterRDD: RDD[bean.UserVisitAction] = actionRDD.filter(
action => {
flowIds.init.contains(action.page_id.toInt)
}
)
val pageToOneRDD: RDD[(Long, Int)] = filterRDD.map(
action => {
(action.page_id, 1)
}
)
val pageToSumRDD: RDD[(Long, Int)] = pageToOneRDD.reduceByKey(_ + _)
val pageCountArray: Array[(Long, Int)] = pageToSumRDD.collect()
//计算分子
val sessionRDD: RDD[(String, Iterable[bean.UserVisitAction])] =
actionRDD.groupBy(_.session_id)
val pageFlowRDD: RDD[(String, List[(String, Int)])] = sessionRDD.mapValues(
iter => {
//将分组后的数据根据时间进行排序
val actions: List[bean.UserVisitAction] = iter.toList.sortWith(
(left, right) => {
left.action_time < right.action_time
}
)
//将排序后的数据进行结构的转换
//action=>pageid
val pageids: List[Long] = actions.map(_.page_id)
//将转换后的结果进行格式的转换
//1,2,3,4 (1-2)(2-3)(3-4)
val zipids: List[(Long, Long)] = pageids.zip(pageids.tail)
//((1-2),1)
zipids.map {
case (pageid1, pageid2) => {
(pageid1 + "-" + pageid2, 1)
}
}.filter {
case (ids, one) => {
okFlowIds.contains(ids)
}
}
}
)
//将分组后的数据进行结构转换
val pageidSumRDD: RDD[List[(String, Int)]] = pageFlowRDD.map(_._2)
//(1-2,1)
val pageflowRDD1: RDD[(String, Int)] = pageidSumRDD.flatMap(list => list)
//(1-2,sum)
val pageflowToSumRDD: RDD[(String, Int)] = pageflowRDD1.reduceByKey(_ + _)
//计算页面单跳转化率
//1-2/1
pageflowToSumRDD.foreach {
case (pageflow, sum) => {
val pageid: String = pageflow.split("-")(0)
val value: Int = pageCountArray.toMap.getOrElse(pageid.toLong, 1)
println("页面跳转【" + pageflow + "】的转换率:" + (sum.toDouble / value))
}
}
}
案例四:
package com.vanas.bigdata.spark.core.req.service
import java.text.SimpleDateFormat
import com.vanas.bigdata.spark.core.req.bean
import com.vanas.bigdata.spark.core.req.dao.PageflowDao
import com.vanas.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @author Vanas
* @create 2020-06-10 10:28 下午
*/
class PageflowTimeService extends TService {
private val pageflowDao = new PageflowDao
override def analysis() = {
//获取原始用户行为日志数据
val actionRDD: RDD[bean.UserVisitAction] =
pageflowDao.getUserVisitAction("input/user_visit_action.txt")
actionRDD.cache()
//根据会话ID对数据进行分组
val sessionRDD: RDD[(String, Iterable[bean.UserVisitAction])] =
actionRDD.groupBy(_.session_id)
val newRDD: RDD[(String, List[(Long, (Long, Int))])] = sessionRDD.mapValues(
iter => {
//将分组后的数据根据时间进行排序
val actions: List[bean.UserVisitAction] = iter.toList.sortBy(_.action_time)
//根据页面访问顺序获取页面的停留时间和次数(最后一个页面无法确定停留时间,暂时不需要考虑)
//(起始页面ID, ( 页面跳转时间差,停留1次 ))
actions.zip(actions.tail).map {
case (a1, a2) => {
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val t1 = sdf.parse(a1.action_time).getTime
val t2 = sdf.parse(a2.action_time).getTime
(a1.page_id, (t2 - t1, 1))
}
}
}
)
println("newRDD = " + newRDD.count())
//将转换结构后的数据按照起始页面进行统计
val reduceRDD: RDD[(Long, (Long, Int))] = newRDD.map(_._2).flatMap(list => list).reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
// 打印页面的平均停留时间。
reduceRDD.collect.foreach {
case (pageid, (totaltime, count)) => {
println(
s"""| 页面【$pageid】总访问时长${totaltime}
| 页面【$pageid】总访问次数${count}
| 页面【$pageid】平均停留时长为 :${totaltime / count}毫秒
| ***********************""".stripMargin)
}
}
}
}