linux基础命令使用详解
网络篇
ping
- ping -c 3 -q -s 65500 -t 255 -i 0.1 -f www.baidu.com
-c:指定ping的次数-q:只重结果不重过程-s: 默认情况下,ping命令是以64字节大小的数据包来测试网络联通性的,如需要改变默认数据包的大小,则可以使用参数-s选项。-t: 指定ping的TTL-i: 指定ping的时间间隔-f: 以尽可能快的速度来发送数据包
DNS
- DNS即Domain Name System,负责着整个互联网中“域名—IP地址”的管理和解析工作。
- DNS缓存,每个DNS服务器都有一个高速缓存区,里面存放“域名-IP”映射关系,缓存会设置期限,所以如果DNS服务器是从缓存中提取解析数据返回给用户的,会在返回内容中给出“Non-authoritative answer”的字样。
- 安装 bind-utils软件包,里面包括 host dig nslookup等命令
/etc/resolv.conf存放dns服务器地址- DNS协议五元组:DNS是用来做域名和资源转换的,而IP地址只是资源中的一种而已。资源是一个五元组{ DomainName、TimeToLive、Class、Type、Value }
- DomainName(域名):指我们要查询的那个域名。
- TimeToLive(生存期限):表示此域名在各DNS服务器缓存中应保存的时长。
- Class(类别):通常为IN,即Internet。另外还有CH(Chaos)和HS(Hesiod)两类,但目前几乎已经被淘汰了。
- Type(类型):指出这条记录的类型,包括8种,即SOA、A、MX、NS、CNAME、PTR、HINFO和TXT。
- Value(值):针对不同类型,会有不同的值。
- DNS的八种类型
- SOA: Start Of Authority,表示授权开始,可以获得针对一个域名的最基本信息,包括Mail:管理员邮箱地址、Minimum:外部DNS服务器如果要缓存本DNS服务器的授权数据保存时限等。
- A: IP地址
- MX: Mail eXchanger,当前域名对应的邮箱服务器
- NS: Name Server,给定域名下包含的DNS服务器信息
- CNAME: 别名
- PTR: 从IP地址查询其对应的域名的映射关系
- HINFO: 包含CPU和OS等信息
- TXT: 文本信息,标识有关此域名的一些信息
nslookup
$ nslookup www.baidu.com
//本次解析使用的DNS服务器的具体IP地址和端口
Server: 223.5.5.5
Address: 223.5.5.5#53
Non-authoritative answer:
www.baidu.com canonical name = www.a.shifen.com.
Name: www.a.shifen.com
Address: 61.135.169.121
Name: www.a.shifen.com
Address: 61.135.169.125- nslookup - 8.8.8.8 更改dns服务器地址,默认取
/etc/resolv.conf中第一条记录 - nslookup -type=soa 更改查询的类型。
dig
dig: Domain Information Groper,它是一个DNS查询工具,比nslookup更加强大。
- dig @dnsserver name querytype
- -f: 用-f选项实现从一个文件里读取内容批量查询。
- -t: 设置查询类型
- -q: 显示设置要查询的域名,提高命令的可读性
- -x: 逆向查询
dig +tcp @8.8.8.8 www.baidu.com: 采用TCP协议来进行DNS通信dig +trace roclinux.cn: 跟踪dig全过程dig +short www.baidu.com: 精简dig输出
iproute
net-tools软件包是Linux平台中非常老牌的工具包,包括arp、ifconfig、netstat、route等命令,普遍集成于各类Linux发行版中,但是Linux内核2.2版本对网络子系统进行了全面的重构后,net-tools工具集有些力不从心,iproute2做为后浪有将前浪拍在沙滩上的趋势。
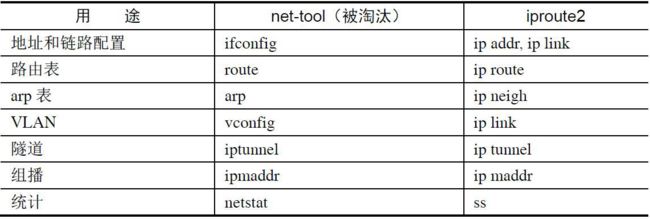
ss
- ss是 Socket Statistics的缩写,可以获取socket统计信息。ss能够显示更多更详细的有关网络连接状态的信息,而且比netstat更快速、更高效。
- ss一些常用的选项
ss -s: 查看当前服务器的网络连接统计ss -l: 查看所有打开的网络端口ss -a: 查看所有的socket连接-ta:表示只查看TCP sockets
ip
ip是用来管理网络设备和路由的强大命令。 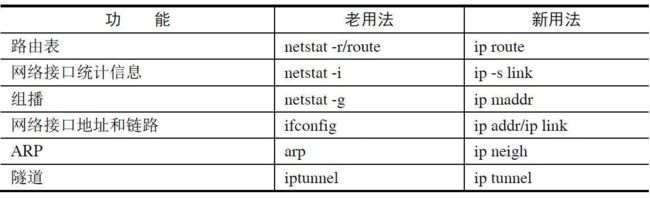
+ ip addr show 展示网络接口信息
+ ip addr add 192.168.1.111/24 dev p1p2 为网络接口添加一个IP地址
+ ip addr del 192.168.1.111/24 dev p1p2 针对一个网络接口删除其IP地址
+ ip route show 查看路由表
+ ip route add 192.168.2.0/24 via 192.168.1.254 增加一条路由规则
+ ip neigh show 查看本服务器的ARP列表
+ ip命令汇总表 
tcpdump
tcpdump -i eth0 -nn -X ‘port 53’ -c 1
- -i选项:即interface,用来指定网络接口
- -nn选项:意思是当tcpdump遇到协议号或端口号时,不要将这些数字转换成对应的协议名称或端口名称。
- -X选项:告诉tcpdump命令,需要把协议头和包内容都原原本本地显示出来。tcpdump会同时以16进制和ASCII的形式显示
- -c选项:是Count的含义,这个选项用来设置我们希望tcpdump帮我们抓几个包。
- -e选项: 增加以太网帧头部信息输出
- -l选项:让输出变为行缓冲,如果不加-l选项的话,那么只有当缓冲区全部占满时,tcpdump才会将缓冲区中的内容输出出来
- -t选项:输出时不打印时间戳
- -v选项:输出更详细的信息,在原有输出内容的基础之上,你还会看到tos值、ttl值、ID值、总长度、校验值等。
- -F选项: 指定过滤表达式所在的文件,
tcpdump -i eth0 -c 1 -t -F filter.txt - -w选项:将流量保存到文件中
- -r选项:读取raw packets文件
- -A选项:tcpdump只会显示ASCII形式的数据包内容
- 过滤流量
- host 指定主机名或IP地址
- net 指定网络段
- port 指定端口
- portwange 指定端口范围
- src(source) dst(destination) 过滤表达式中没有明确指出某个IP是src还是dst的话,那么默认策略是src或dst都会匹配到。
- proto[expr:size]语法
- proto就是protocol的缩写,表示这里要指定的是某种协议的名称,比如ip、tcp、icmp、udp等。
- proto[expr:size]中,expr用来指定数据报偏移量,表示从某个协议的数据报的第多少位开始提取内容,默认的起始位置是0。而size表示从偏移量的位置开始提取多少个字节
- 提取了特定内容之后,我们就需要设置我们的过滤条件了。我们可用的“比较操作符”包括:>、<、>=、<=、=和!=,共6个。
- 要想提取TCP协议的SYN、ACK和FIN字段 语法如下
tcp[tcpflags] & tcp-syn; tcp[tcpflags] & tcp-ack; tcp[tcpflags] & tcp-fin; tcpdump 'ip[2:2] > 576'打印IP包长度超过576字节的网络包。
nc
命令nc,全名netcat, 能胜任跟TCP/UDP相关的一切操作,可以打开TCP连接、发送UDP包、监听端口,端口扫描等等。
- 聊天
- 在A机器上执行
nc -l 12345 - 在B机器上
nc 116.255.245.207(A的IP地址) 12345
- 在A机器上执行
- 端口扫描
nc -z -v -n -w 2 127.0.0.1 20-23- -z选项:一旦建立连接后马上断开,而不发送和接收任何数据。
- -v选项:打印详细输出信息。
- -n选项:直接使用IP地址,而不使用域名服务器来查询其域名。
- -w选项:设置连接的超时时间,单位为秒。
- -u选项:使用UDP建立连接。上面命令无此设置,则表示使用TCP建立连接。
- 传输文件
- 文件发送端启动监听端口,准备好文件
nc -v -l 12345 < book_out.txt - 文件的接收端接收服务端的数据,并重定向到文件中
nc -v -n 116.255.245.207 12345 > book_in.txt
- 文件发送端启动监听端口,准备好文件
ssh-copy-id
一个脚本方便从A机器建立到B机器的ssh信任关系。
rsync
用于源端和目的端文件、文件夹的实时同步
wget
命令行下的网络下载工具,支持HTTP、HTTPS、FTP协议的下载。
进程和性能篇
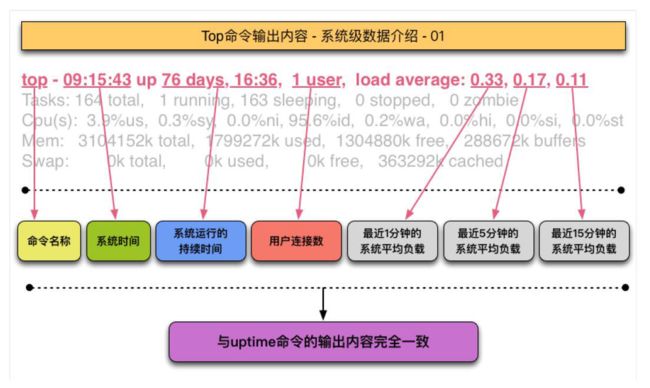
uptime
uptime命令,有两大功能:一个是查看机器的开机时长,另一个是查看CPU负载情况。
$ uptime
22:36:58 up 11:12, 1 user, load average: 0.00, 0.00, 0.00
系统当前时间 主机已运行时间 用户**连接**数 最近1、5、15分钟的系统平均负载
+ **系统平均负载:** 运行队列中的平均进程数,一般的经验来看,单核负载在0.7以下是安全的,超过0.7就需要进行优化了。
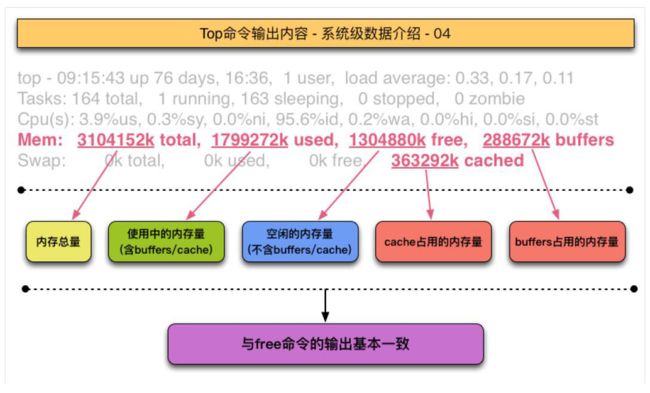
+ **/proc/loadavg**文件中也记载了系统平均负载信息。free
- buffers是块设备I/O相关的缓存页,数据先写到buffer中,再再后台慢慢写入设备。
- cached是普通文件相关的缓存页,从硬盘读取数据内容先暂存到cache里,减少从底盘读数据的次数。
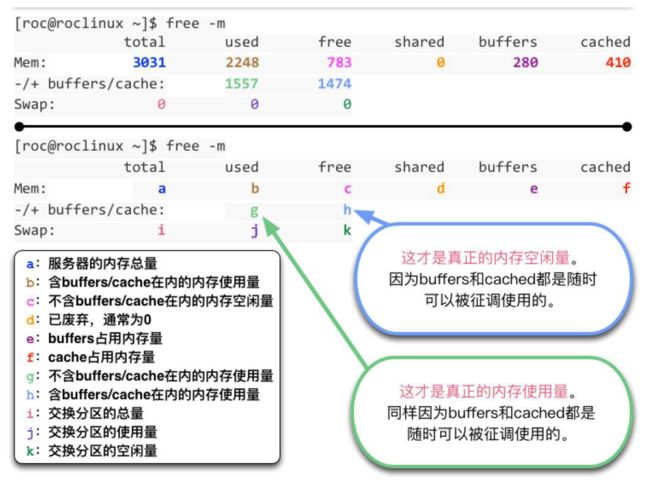
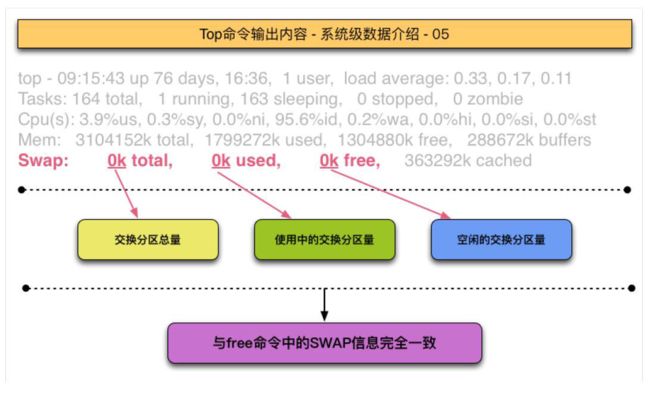
SWAP空间
SWAP(交换分区)和Windows中的虚拟内存都是将一部分硬盘空间虚拟成内存,来缓解内存使用紧张的问题。
+ 当Linux系统发现物理内存使用量不足时就会选择内存中较长时间没有被访问和更新的内存数据,将这些内存数据临时写到SWAP中,并释放内存中相应的空间
+ 等到某个程序要使用SWAP中的数据时,系统会再次从SWAP中读取之前保存的数据,并写回到物理内存中。
+ 对于服务器来说,SWAP建议设置为内存的1~2.5倍之间的数值,可以防止内存耗尽的窘境。
+ 如何定义内存不足?cat /proc/sys/vm/swappiness中的参数会来辅助控制“内存不足”的界限。 
vmstat
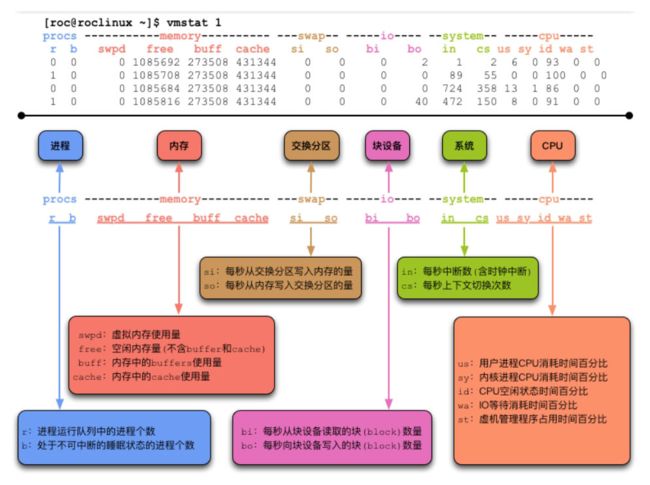
- vmstat输出的第一行数字,是自服务器启动至今的各项指标的平均值,而非最新状态值,从第二行开始的,才能反映服务器当前最新状态。
- 如果cache的数值较大,则说明系统缓存了较多的磁盘数据,利于磁盘I/O性能的提升。
- si和so则是读写SWAP的量,这两个值如果长期大于0,则表示系统需要经常读写交换分区,这会很消耗CPU资源和磁盘I/O性能。
- 如果free的数值很低,甚至接近0了,也不一定就是系统内存快耗尽了。要同时看buff和cache的量,大部分情况是buff和cache占用了很多内存资源,而当系统真正需要内存时,buff和cache是可以随时被系统征调回来的。
- 如果发现bi和bo的值很大,则说明系统正在进行大量的磁盘读写操作。
- 如果us的数值经常大于50%,则说明用户进程所占用的CPU时间较多
- 而sy是内核所消耗的CPU时间,这个数值不应该很高。如果很高,则一定是系统哪里出了问题。
- 如果wa较高,则说明CPU总是在等待I/O操作。这表明磁盘已经成为主要瓶颈
- r表示的是正在运行队列中的任务数,如果这个数值总是超过服务器的CPU核数,则说明CPU已经成为性能瓶颈
mpstat
- mpstat,全称是multiprocessor statistics,擅长多处理器的统计工作。
top
通过top,我们可以了解到服务器的CPU负载情况、内存状态、SWAP使用状况,以及详尽的进程级运行状态,可谓应有尽有。


进程数据 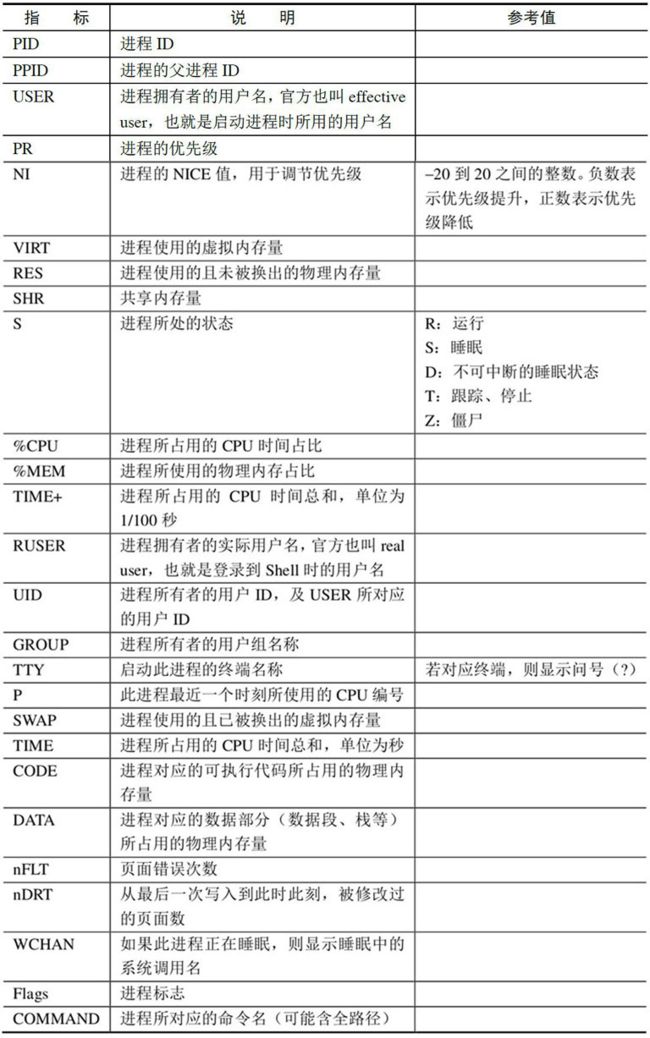
- VIRT(Virtal Memory)中文为虚拟内存。一个进程,无论是通过malloc/calloc系列函数申请的内存,还是堆/栈所占用的内存,抑或是全局变量等所占用的内存,都属于VIRT范畴。所以VIRT是进程所占用内存的最大集。 + RES(Resident Memory),中文叫作常驻内存。在malloc申请了物理内存空间之后,并非会立即使用到这块物理内存,所以,系统会在进程真正要使用到这块物理内存时,才正式将物理内存分配给这个进程。所以,RES表示的是一个进程真正在使用的物理内存的大小,而非申请的物理内存的大小。
iostat
iostat -d -k 1 3- -d选项:只显示磁盘的使用状态
- -k选项:使用KB作为单位
- 1: 采样时间,1s
- 3: 采样次数,3次
- iostat输出的第一组数据表示从系统启动到本命令执行期间的统计结果
- -x选项展示了更多的磁盘统计数据
pidof
- 查询一个运行程序的PID
pidof sshd - -x选项:找出Shell脚本的PID
- -s选项: 只输出一个PID
sar
将系统性能指标信息按时间间隔数据到文件中。
lsof
lsof,即list open files 用来查看进程打开的文件、目录和套接字等一系列信息。
lsof filename: 通过文件名来定位打开该文件的进程lsof -d N:根据文件描述符定位进程lsof -p PID:查询进程打开了哪些文件lsof -i[46] [protocol][@hostname|hostaddr][:service|port]:查看哪些程序占用端口
fuser
fuser和lsof功能对比 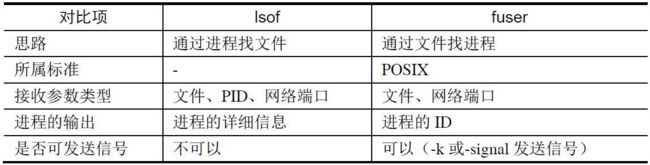
ps
查看服务器上有哪些进程,属于哪些用户,消耗了多少CPU资源,占了多少内存
+ a:显示各终端上的所有进程
+ u:展示进程所属的用户名
+ x: 对于没有关联到终端上的进程也展示出来
kill
kill [选项] [进程号]向进程发送特定信号- kill -l 查看kill可以发出哪些信号
nohup
要想让运行的命令不因用户注销、网络断开等因素而中断,有两个基本思路:
+ 让进程对SIGHUP信号免疫。免疫宗的成员有nohup和disown。
+ 让进程在新的会话中运行。会话宗的成员有setid和screen。
系统管理篇
uname
uname -a 展示系统信息 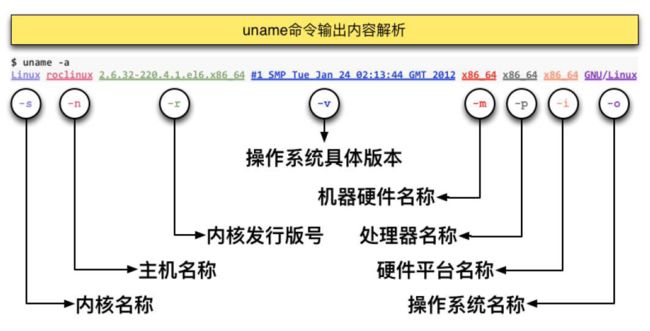
用户ID和用户组
- 实际用户,英文术语叫作real user id,就是登录Shell的那个时刻所使用的用户ID。用who am i所展示出来的就是“实际用户”。
- 登录进Shell之后,使用su或su-切换到的用户ID,叫作有效用户。用whoami所展示出来的就是“有效用户”。
service
service [服务名] [start/stop/restart/status]/etc/init.d目录下的这些文件就是可以通过service命令掌控的服务。- service只是一个脚本,它所做的只是把用户的操控动作(start/stop/restart/status)传递给/etc/init.d中相应的命令而已。
chkconfig
- /etc/init.d/中包含所有可用的服务;
- /etc/rc.d/中设置有7个文件夹,以rcN.d形式命名,分别对应7个运行等级;
- 每一个rcN.d文件夹中的文件全部是软链形式,分别链接到/etc/init.d/中的服务上,也就表明了当前的运行等级对应着哪些服务;
- rcN.d中的软链文件命名规则;
- K+整数+服务名;
- S+整数+服务名。
- 以K开头的软链文件,表示要关闭对应的服务。以S开头的软链文件,表示要启动对应的服务。
lsmod
可以实现把某些功能代码封装成模块动态地装载到内核中,当内核需要用到这个功能时再读取使用。
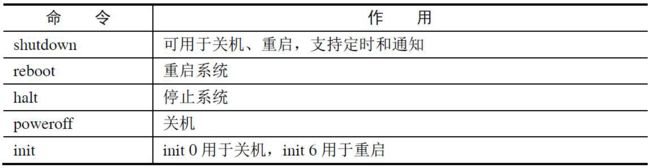
关机和重启
第1章 Linux简介
- 什么是交换分区?交换分区是一个特殊的分区,它的作用相当于Windows下的虚拟内存,这个分区的大小一般设置为物理内存的两倍,但是不管物理内存有多大,交换分区建议不要超过8GB,因为大于8GB的交换分区其实并没有多大实际意义。
- 使用
man cmdinfo cmd来查询cmd命令的说明文档 - 计算机的启动过程
- 通过后计算机会加载BIOS(主板制造商开发适合自己主板的BIOS), BIOS对自身的硬件做一次健康检查,只有硬件没有问题,才能运行软件.
- BIOS默认会从硬盘上的第0柱面、第0磁道、第一个扇区中读取被称为MBR的512字节大小的数据,即主引导记录。其中引导程序部分占用446字节,另外64字节是磁盘分区表DPT,最后两字节是MBR的结束位。这512字节的空间内容是由专门的分区程序产生的,比如说Windows下的fdisk.exe,或者Linux下的fdisk命令,所以它不依赖于任何操作系统,所以可以利用这个特性实现多操作系统共存。
- 常见的方式是在MBR中写入Grub的地址,这样系统实际会载入Grub作为操作系统的引导程序。
- Grub最重要的功能就是根据其配置文件加载kernel镜像,并运行内核加载后的第一个程序/sbin/init,这个程序会根据/etc/inittab来进行初始化的工作。
- Linux将根据/etc/inittab中定义的系统初始化配置
- 根据runlevel值来启动对应的服务,运行/etc/rcN.d/下的所有脚本
- 运行/etc/rc.local
- 生成终端或X Window来等待用户登录
- login shell会执行/etc/profile. 所以/etc/profile是影响所有用户的. 然后依次~/.bash_profile, ~/.bash_login , ~/.profile
第2章 Linux用户管理
- 超级用户 root UID=0;系统用户(apache、mysql),UID 1~499 ;普通用户 UID>500
- /etc/passwd 存放用户信息,所有人都可读;/etc/shadow 存放用户密码,只有root可读。
- 创建用户
useradd USERNAME,可以通过-g指定所属的用户组useradd -g GROUPNAME USERNAME,-d 指定该用户的根目录- 分配UID,将用户信息记录在/etc/passwd中,密码保存在/etc/shadow
- 为该用户自动创建家目录 /home/USERNAME
- /etc/skel下所有的文件至/home/USERNAME/ , /etc/skel下一般存放创建新用户时默认的“配置文件”
- 新建一个与该用户名一样的用户组
- 修改密码
passwd - 删除用户
userdel - 增加用户组
groupadd - 删除用户组
groupdel - 查看用户
users:查看当前系统有哪些用户;who、w:查询详细信息 su:切换到其它用户,默认切换到root,切换成其他用户的前提是需要知道对方的密码。sudo:用其他用户的身份执行命令- 系统首先检查/etc/sudoers,判断该用户是否有执行sudo的权限,在确定有执行权限后,系统要求用户输自己的密码
- sudoers文件格式
USER ALL=(ALL)ALL: USER这个用户(第一列)可以从任何地方登录后(第二列的ALL)执行任何人(第三列的ALL)的任何命令(第四列的ALL)。 - 想要实现不需要输入密码就可以执行命令,可以在最后一个ALL前添加“NOPASSWD:”
USER ALL=(ALL) NOPASSWD:/sbin/shutdown, /usr/bin/reboot
at: 在某一个特定的时间执行一次任务cron: 周期性执行任务
第三章 Linux文件管理
pwd:当前所在的目录; 在每个目录下,都会固定存在两个特殊目录,分别是一个点(.)和两个点(..)的目录。一个点(.)代表的是当前目录,两个点(..)代表的是当前目录的上层目录。touch: 创建文件,如果已经存在了这个文件,并不会修改文件的内容,但是会更新文件的创建时间属性。rm删除文件、目录; -r 递归删除子目录 -f 强制删除,不需要确认提示mv移动或重命名文件cat查看文件;head查看文件头;tail查看文件尾dos2unix把DOS格式的文本文件转变成UNIX下的文本文件mkdir创建目录,-p参数一次性创建所有目录cp文件和目录复制- 查看文件或目录的权限:ls-al
[root@localhost ~]# ls -al
total 112
drwxr-x--- 3 root root 4096 Oct 1 10:43 .
drwxr-xr-x 24 root root 4096 Oct 1 07:42 ..
-rw------- 1 root root 1017 Jan 2 2009 anaconda-ks.cfg
第一列是文件类别和权限,这列由10个字符组成,第一个字符表明该文件的类型。(d:目录 -:普通文件 l:链接文件 b:快文件 c:字符文件 s:socket文件 p:管道文件)
接下来的属性中,每3个字符为一组,第2~4个字符代表该文件所有者(user)的权限,第5~7个字符代表给文件所有组(group)的权限,第8~10个字符代表其他用户(others)拥有的权限。
第二列代表“连接数”,除了目录文件之外,其他所有文件的连接数都是1,目录文件的连接数是该目录中包含其他目录的总个数+2
第三列代表该文件的所有人,第四列代表该文件的所有组,第五列是该文件的大小,第六列是该文件的创建时间或最近的修改时间,第七列是文件名。-
lsattr 查看文件的隐藏属性,chattr设置文件的隐藏属性
- a属性。拥有这种属性的文件只能在尾部增加数据而不能被删除。
chattr +a anaconda-ks.cfg设置了a属性的文件,即便是root用户也不能删除它,但是实际上可以以尾部新增(append)的方式继续向该文件中写入内容。 - i属性 设置了这种属性的文件将无法写入、改名、删除,即便是root用户也不行。
- a属性。拥有这种属性的文件只能在尾部增加数据而不能被删除。
-
chmod: 改变文件权限,u、g、o来分别代表拥有者、拥有组、其他人,而对应的具体权限则使用rwx的组合来定义,增加权限使用+号,删除权限使用-号,详细权限使用=号
- chown:改变文件的拥有者
- chgrp:改变文件的拥有组
- SUID: 如果某个二进制文件的用户权限被设置了s权限,则其它用户也能以该文件的用户身份去运行这个命令。
chmod u+s somefile - Sticky权限只能用于设置在目录上,设置了这种权限的目录,任何用户都可以在该目录中创建或修改文件,但是只有该文件的创建者和root可以删除自己的文件。
chmod o+t somedir - umask:默认权限。
- file:查看文件类型
- find: 查找文件; locate:数据库查找,比find更快,依赖于一个数据库文件,Linux系统默认每天会检索一下系统中的所有文件,然后将检索到的文件记录到数据库中。updatedb可以立即更新数据库
- which/whereis 查找执行文件
- tar 压缩解压文件
第四章 Linux文件系统
文件系统
ext2文件系统:ext2文件系统也是采取将文件数据存放到数据块中的方式来存储数据的,这些数据块的大小可以在创建文件系统的时候指定,对于存放的每个文件和目录,都会有一个inode指定,文件系统中所有的inode都是使用inode表来进行记录的,一定数量的块就会组成一个块组。在ext2文件系统中,整个分区的文件系统信息都被存放在超级块中,考虑到超级块所具有的重要性,因此在每个块组的开头中都有相同的备份。ext2文件系统的弱点也是很明显的:它不支持日志功能。这很容易造成在一些情况下丢失数据,这个天然的弱点让ext2文件系统无法用于关键应用中,目前已经很少有企业使用ext2文件系统了。
ext3文件系统: 从ext2文件系统发展而来,所以完全兼容ext2文件系统,拥有日志功能- mount: 磁盘挂载
- fdisk:创建文件系统
- 硬链接:是指通过索引节点来进行链接。在Linux文件系统中,所有的文件都会有一个编号,称为inode,多个文件名指向同一索引节点是被允许的,这种链接就是硬链接。硬链接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬链接指向同一文件,删除一个链接并不会影响索引节点本身和其他的链接,只有当最后一个链接被删除时,文件的数据块及目录的链接才会被释放。但是 1. 不允许给目录创建硬链接; 2. 只有在同一文件系统中的文件之间才能创建链接
- ln src hard_link; -s 创建软连接
- 软链接(soft link)又称符号链接(symbolic link),是一个包含了另一个文件路径名的文件,可以指向任意文件或目录,也可以跨不同的文件系统。
第五章 字符处理
- 管道是一个固定大小的缓冲区,该缓冲区的大小为1页,即4K字节。
-
grep:搜索文本 grep [-ivnc] ‘需要匹配的字符’ 文件名 #-i 不区分大小写 #-c 统计包含匹配的行数 #-n 输出行号 #-v 反向匹配 sort排序 sort [-ntkr] 文件名 #-n 采取数字排序 #-t 指定分隔符 #-k 指定第几列 #-r 反向排序 uniq删除重复内容 uniq [-ic] #-i 忽略大小写 #-c 计算重复行数 uniq命令只会对比相邻的行,如果有连续相同的若干行则删除重复内容,仅输出一行。如果相同的行非连续,则uniq命令不具备删除效果。uniq一般都需要和sort命令一起使用。 cut 截取文本 cut -f指定的列 -d’分隔符’; 系统中的所有用户及用户的家目录 cat /etc/passwd | cut -f1,6 -d’:’ cut还可以打印指定的字符; cat /etc/passwd | cut -c1-5,7-10 打印出每行第1~5个字符,以及第7~10个字符的内容 tr 做文本转换或删除 cat /etc/passwd | tr ‘[a-z]’ ‘[A-Z]’ //把所有a转换为A b转换为B cat /etc/passwd | tr -d ‘:’ //删除所有的: paste 做文本合并; paste a.txt b.txt ;-d 指定在合并文件时行间的分隔符 split 分割大文件
第六章 网络管理
- ifconfig: 检查和配置网卡
- ifconfig eth0 192.168.159.130 netmask 255.255.255.0 //手工指定eth0的IP地址
- ifconfig eth0 down/up 手工断开/启用网卡
ifoconfig
eth0 Link encap:Ethernet HWaddr 00:16:3E:1A:C7:24
inet addr:172.19.9.191 Bcast:172.19.15.255 Mask:255.255.240.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:14073006 errors:0 dropped:0 overruns:0 frame:0
TX packets:10588780 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:7100709998 (6.6 GiB) TX bytes:8880189731 (8.2 GiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:11804717 errors:0 dropped:0 overruns:0 frame:0
TX packets:11804717 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1845532026 (1.7 GiB) TX bytes:1845532026 (1.7 GiB)
eth0表示的是以太网的第一块网卡。其中eth是Ethernet的前三个字母,代表以太网,0代表是第一块网卡,第二块以太网网卡则是eth1,以此类推。Link encap是指封装方式为以太网;HWaddr是指网卡的硬件地址(MAC地址);inet addr是指该网卡当前的IP地址;Broadcast是广播地址(这部分是由系统根据IP和掩码算出来的,一般不需要手工设置);Mask是指掩码;UP说明了该网卡目前处于活动状态;MTU代表最大存储单元,即此网卡一次所能传输的最大分包;RX和TX分别代表接收和发送的包;collision代表发生的冲突数,如果发现值不为0则很可能网络存在故障;txqueuelen代表传输缓冲区长度大小;第二个设备是lo,表示主机的环回地址,这个地址是用于本地通信的。- RedHat和CentOS系统的网络配置文件所处的目录为/etc/sysconfig/network-scripts/,eth0的配置文件为ifcfg-eth0
DEVICE=eth0 //DEVICE变量定义了设备的名称
BOOTPROTO=dhcp //BOOTPROTO变量定义了获取IP的方式
ONBOOT=yes // ONBOOT变量定义了启动时是否激活使用该设备
// BOOTPROTO=static
//IPADDR=192.168.159.129
//NETMASK=255.255.255.0- route命令添加默认网关
route add default gw 192.168.159.2route–n查看系统当前的路由表 - /etc/hosts 1. 加快域名解析,当访问网站时,系统会首先查看hosts文件中是否有记录,如果记录存在则直接解析出对应的IP,这时则不需要请求DNS服务器。 2. 方便小型局域网用户使用的内部设备,不必为此专门设置DNS服务器
- /etc/resolv.conf: hosts文件毕竟只能做有限的主机记录,无法将所有已知的主机名记录到hosts文件中,当今几乎所有的主机都在使用DNS来解析地址.设置主机为DNS客户端的配置文件就是/etc/resolv.conf
- ping ping程序的目的在于测试另一台主机是否可达
- host、Nslookup、dig 用来查询DNS记录的。
- traceroute 检测数据包是如何经由路由器的工具.
第7章 进程管理
- ps 查询当前运行进程的状态信息
- top 实时的系统状态监控
- kill、killall 终止一个进程
- lsof 查询进程打开的文件(普通文件、目录、网络文件系统中的文件、字符设备、管道、socket等)
lsof [options] filename
lsof filename 显示打开指定文件的所有进程
lsof -c COMMAND 显示COMMAND列中包含指定字符的进程所有打开的文件
lsof -u username 显示所属于user进程打开的文件
lsof -g gid 显示归属于gid的进程情况
lsof +d /DIR/ 显示目录下被进程打开的文件
lsof +D /DIR/ 同上,但是会搜索目录下的所有目录,时间相对较长
lsof -d FD 显示指定文件描述符的进程
lsof -n 不将IP转换为hostname,默认是不加-n
lsof -p<进程号> 列出指定进程号所打开的文件
lsof -i[46] [protocol][@hostname|hostaddr][:service|port]
#46指IPv4或IPv6
#protocol指TCP或UDP
#hostname指主机名
#hostaddr是IPv4地址
#service是/etc/service中的service name
#port是端口号nice、renice:调整进程优先级
第8章 Linux下的软件安装
- yum yum的全称为Yellow dog Updater,Modified,是一个基于RPM的shell前端包管理器,能够从指定的服务器上(一个或多个)自动下载并安装或更新软件、删除软件。其最大的好处是可以自动解决依赖关系。
第9章 vi和vim编辑器
没什么好记录的。。。
第10章 正则表达式
-
.(一个点)符号:用于匹配除换行符之外的任意一个字符。 * 符号:符号用于匹配前一个字符0次或任意多次 {n,m}: 控制字符的重复次数 ^ 符号: 用于匹配开头的字符 $ 符号:“$”用于匹配尾部 [] 符号: 用于匹配方括号内出现的任一字符,^这个符号出现在[]中,则代表取反. \ 转义字符 \d : 匹配一个数字,等价于[0-9] \b : 匹配单词的边界 \B:匹配非单词的边界 \w: 匹配字母、数字和下划线,等价于[A-Za-z0-9]。 \W:匹配非字母、非数字、非下划线,等价于[^A-Za-z0-9]。 \n 匹配换行符 \r匹配回车符 \t 匹配制表符 \s:匹配任何空白字符,\S:匹配非空白字符
扩展正则表达式
+ ?: 用于匹配前一个字符0次或1次
+ +: 用于匹配前一个字符1次以上
+ | “|”符号是“或”的意思,即多种可能的罗列,彼此间是一种分支关系。
grep
基于正则的文本查找命令sed
+ 默认情况下,sed并不会改变原文件本身,而只是对流经sed命令的文本进行修改,并将修改后的结果打印到标准输出中,要想保存修改后的文件,必须使用重定向生成新的文件。如果想直接修改源文件本身则需要使用“-i”参数。
+ sed处理文本时是以行为单位的,每处理完一行就立即打印出来,然后再处理下一行
+ sed [options] 'command' file,是sed可以接受的参数;#command是sed的命令集(一共有25个)
+ -e 参数和分号可以连接多个命令sed 应用实例:
1. 删除:d命令可删除指定的行。删除第一行 `sed '1d' Sed.txt`; 删除从N到M行 `sed 'N,Md' Sed.txt`;删除第一行到最后行 `sed '1,$d' Sed.txt`;删除最后一行 `sed '$d' Sed.txt`; 删除所有包含Empty的行 `sed '/Empty/d' Sed.txt`;删除空行 ` sed '/^$/d' Sed.txt`
2. 查找替换: 使用s命令可将查找到的匹配文本内容替换为新的文本。 sed 's/line/LINE/' Sed.txt 使用LINE替换line,请注意每一行只有第一个line被替换了,默认情况下只替换第一次匹配到的内容。`s/line/LINE/g` 可以完成所有匹配值的替换
3. 字符转换: 使用y命令可进行字符转换,其作用为将一系列字符逐个地变换为另外一系列字符。该命令会将file中的O转换为N、L换为E、D转换为W#注意转换字符和被转换字符的长度要相等,否则sed无法执行 `sed 'y/OLD/NEW/' file`
4. 插入文本:使用i或a命令插入文本,其中i代表在匹配行之前插入,而a代表在匹配行之后插入。 在匹配行的上一行插入,sed '/Pattern/i\Insert' Sed.txt
5. 读取文本,使用r命令可从其他文件中读取文本,并插入匹配行之后。 `sed '/^$/r /etc/passwd' Sed.txt `
6. 打印: 使用p命令可进行打印,这里使用sed命令时一定要加-n参数,表示不打印没关系的行. 打印出文件中指定的行 `sed -n '1p' Sed.txt`
7. 写文件: 想要保存文件除了使用重定向或-i参数外,还可以使用w命令将结果保存到外部指定文件。 `sed -n '1,2 w output' Sed.txt`
8. 替换匹配行的下一行: n命令,该命令的作用在于读取匹配行的下一行,然后再用n命令后的编辑指令来处理该行。
9. 每一行最前面加点东西,`sed 's/^/#/g' pets.txt`
10. 在每一行最后面加点东西 `sed 's/$/ --- /g' pets.txt`
11. 对匹配内容执行多条命令,对1,3行做替换操作,然后打印出替换后的内容 `sed -n '1,3{s/old/new/g;p;}' file`awk
awk则是基于列的文本处理工具,它的工作方式是按行读取文本并视为一条记录,每条记录以字段分割成若干字段,然后输出各字段的值,1、1、2分别用于表示域,$0则表示全部域。
- -F 参数指定分隔符,来区分不同的域
- 内部变量NF表示文件的列数
- BEGIN 初始化变量 END处理结束时输出
第11章 Shell编程概述
- Shell是指一种命令行解释器,是为用户和操作系统之间通信提供的一种接口,它接受来自用户输入的命令,并将其转换为一系列的系统调用送到内核执行,并将结果输出给用户。
- Shell是一门非常容易入门的语言,语法结构简单,Shell具备一定的跨平台性,使用POSIX所定义的规范,可以做到脚本无须修改就能在不同的系统中运行。
- 脚本中的第一行“#!/bin/bash” 是在告诉系统执行这个文件需要使用某个解释器,后面的/bin/bash就是指明了解释器的具体位置。
- “#”后面的内容为注释
- 执行脚本时指定 -x 参数来观察脚本的运行情况,也可以借助第三方工具(bashdb)来调试脚本程序
- Shell内建命令:
-
type:判断一个命令是不是内建命令 执行程序:“.”(点号),点号或者source命令用于执行某个脚本,甚至脚本没有可执行权限也可以运行。 alias:用于创建命令的别名,alias ll='ls -l --color=tty',可以将别名条目写到用户家目录中的.bashrc文件中 unalias: 删除别名 任务前后台切换:bg、fg、jobs cd 改变目录 declare、typeset 用来声明变量 echo 打印字符,默认加上换行符,使用-n参数可以不打印换行符 eval: 将所跟的参数作为Shell的输入,并执行产生的命令 exec:内建命令exec并不启动新的Shell,而是用要被执行的命令替换当前的Shell进程,并且将老进程的环境清理掉。exec典型的用法是与find联合使用,用find找出符合匹配的文件,然后交给exec处理 find / -name "*.conf" -exec ls -l {} \; exit: 退出Shell kill: 发送信号给指定PID或进程 let: Shell内建的整数运算命令 pwd:显示当前目录, PWDPWDOLDPWD local:该命令用于在脚本中声明局部变量 read: 从标准输入读取一行到变量 return 定义函数返回值 ulimit: 显示并设置进程资源限度
-
第12章 Bash Shell的安装
/etc/shells文件中存放系统已安装的shell。- chsh命令(change shell的简写)修改登录Shell,chsh命令做的工作就是修改了/etc/passwd文件中登录Shell的路径
第13章 Shell编程基础
- Shell变量是一种弱类型的变量,也就是说在声明变量时并不需要指定其变量类型
- BASH:Bash Shell的全路径。 BASH_VERSION:Bash Shell的版本。CDPATH:用于快速进入某个目录。EUID:记录当前用户的UID。
- FUNCNAME:在用户函数体内部,记录当前函数体的函数名。
- HISTCMD:记录下一条命令在history命令中的编号。HISTFILE:记录history命令记录文件的位置。HISTFILESIZE:设置HISTFILE文件记录命令的行数。HISTSIZE:缓冲区的大小,Linux并不会每次运行一个命令后立即将该命令记录到HISTFILE文件中,而是先放到命令缓存区中,在缓冲区满或退出Shell时才将缓冲区的记录写到HISTFILE文件中。
- HOSTNAME:展示主机名。HOSTTYPE:展示主机的架构。MACHTYPE:主机类型的GNU标识。LANG:设置当前系统的语言环境。
- PS1:命令提示符,默认值是[\u@\h\W]$,其中\u是用户名、\h是主机名、\W是当前工作目录的basename、$是用户UID的替换字符:如果UID是0则替换成“#”,否则替换成“$”,所以此处具体显示出来就是“[root@localhost~]#”
- 变量命名:必须以字母或者下划线开头,后面可以跟数字、字母和下划线,变量长度没有限制,Shell的变量是区分大小写的
- 变量赋值:name=john 变量名和变量值之间用等号紧紧相连,之间没有任何空格,如果不注意,等号任何一边出现空格就会出错,当变量中有空格时必须用引号括起,否则会出现错误
- 变量取值:只需要在变量名前加上符号既可,严谨一点的写法是符号既可,严谨一点的写法是{}
- 取消变量:unset
-
特殊变量
- 位置参数:脚本本身为0,第一个参数为0,第一个参数为1,第二个参数为2,第三个为2,第三个为3。。。$#表示脚本参数的个数总和,$@或$*表示脚本的所有参数。
- $?: 脚本或命令返回值,Linux中规定正常退出的命令和脚本应该以0作为其返回值,任何非0的返回值都表示命令未正确退出或未正常执行。
-
数组:
定义: declare -a Array #定义名为Array的索引数组 declare -a Name=(‘john’ ‘sue’) # 数组还可以在创建的同时赋值
数组取值: ${数组名[索引]}。${Array[@]} ${Array[*]} 可以一次性取出所有值
数组长度: 利用“@”或“*”字符,可以将数组扩展成列表,然后使用“#”来获取数组元素的个数 echo ${#Array[@]}。echo ${#Array[2]} 如果某个元素是字符串,还可以通过指定索引的方式获得该元素的长度。
数组截取: 可以截取某个元素的一部分,对象可以是整个数组或某个元素。echo ${Array[@]:1:2}
连接数组:将若干个数组进行拼接操作 Conn=(${Array[@]} ${Name[@]})
替换元素:将数组内某个元素的值替换成其他值。Array=(${Array[@]/HelloWorld/HelloJohn}) - 只读变量: 只读变量又称常量,是通过readonly内建命令创建的变量,在声明时就要求赋值,并且之后无法修改。使用declare-r也可以声明只读变量。
readonly RO=100 - 变量的作用域:在Linux系统中,不同进程ID的Shell默认为一个不同的命名空间,同名变量在两个不同命名空间中是互不影响的.Shell变量的作用域是在本Shell内,在函数内部声明的临时变量需要用local指定其为只在函数内生效的“局部变量”,这样这些变量将只存在于局部的命名空间内,从而不会对全局变量有影响。
- 转义和引用:Shell中的转义符是反斜线“\”,在双引号中的$符、反引号、转义符还是会被解析成其特殊含义,而在单引号中所有的字符都只是字面意思。
- 命令替换:命令替换是指将命令的标准输出作为值赋给某个变量。Shell中有两种方式可以完成命令替换,一种是反引号(`),一种是$()。DATE_01=`date` DATE_02=$(date)
- 运算符:常见的算术运算大多需要结合Shell的内建命令let来使用,Shell只支持整数计算,也就,是所有可能产生小数的运算都会舍去小数部分。
- expr: expr命令也可用于整数运算,expr要求操作数和操作符之间使用空格隔开,expr支持的算术运算符有加、减、乘、除、余等
- $[]和$(())类似,可用于简单的算术运算
- $((算术表达式)),其中的算术表达式由变量和运算符组成,常见的用法是显示输出和变量赋值。 echo $((2*i+1)) 变量i前并没有$符.
- 通配符:*代表任意长度的字符串,问号(?)可用于匹配任一单个字符.
第14章 测试和判断
- 测试
- 测试的第一种使用方式是直接使用test命令,test expression,然后根据$?是否返回0来判断是否成功。
- 第二种测试方式是使用“[”启动一个测试,再写expression,再以“]”结束测试,左边的括号“[”后有个空格,右括号“]”前面也有个空格,如果任意一边少了空格都会造成Shell报错。
-
文件测试 : -e FILE :文件或者目录存在时返回真。 -d FILE: 文件存在并且是个目录时返回真。 -f FILE: 文件存在并且为普通文件。 -x FILE: 文件存在并且可以执行。 -r FILE: 文件存在并且可读。 -w FILE: 文件存在并且可写。 字符串测试: -z “STR”: STR为空时返回真 -n “STR”: STR非空时返回真 “string1”=”string2” “string1”!=”string2” 整数比较: ”num1” -eq “num2” “num1” -gt “num2” “num1” -lt “num2” “num1” -ge “num2” “num1” -le “num2” “num1” -ne “num2” 逻辑测试: 用于连接多个测试条件,并返回整个表达式的值。 ! expression expression1 -a expression2 :同时为真 ===> 等同 && expression1 -0 expression2 :有一个为真 ====> 等同 ||
-
判断
-
if判断
if expression; then command fi if expression; then command else command fi if expression1; then command1 else if expression2; then command2 else command3 fi fi -
case判断
case VAR in var1) command1 ;; var2) command2 ;; var3) command3 ;; ... *) command ;; esac //case判断结构中的var1、var2、var3等这些值只能是常量或正则表达式。
-
第15章 循环
-
for循环
-
带列表的for循环
for VARIABLE in (list) do command done 将列表定义到一个变量中,以后有任何修改只需要修改该变量即可 fruits="apple orange banana pear" for FRUIT in ${fruits} do echo "$FRUIT is John's favorite" done echo "No more fruits" for VAR in {1..5} do echo "Loop $VAR times" done 可以使用seq命令结合命令替换的方式生成列表 sum=0 for VAR in `seq 1 100` #for VAR in $(seq 1 100) do let "sum+=VAR" done echo "Total: $sum" //$(seq 1 2 100) -
类C的for循环
for ((expression1; expression2; expression3)) do command done for ((i=1; i<=10; i++)) do echo -n "$i " done -
-
while循环
-
和for循环一样,while循环也是一种运行前测试语句
while expression do command done -
使用while按行读取文件
-
while read LINE
do
NAME=`echo $LINE | awk '{print $1}'`
AGE=`echo $LINE | awk '{print $2}'`
Sex=`echo $LINE | awk '{print $3}'`
echo "My name is $NAME, I'm $AGE years old, I'm a $Sex"
done- until循环
until expression
do
command
done- select循环
select MENU in (list)
do
command
done
当程序运行到select语句时,会自动将列表中的所有元素生成为可用1、2、3等数选择的列表,并等待用户输入。用户输入并回车后,select可判断输入并执行后续命令。- 循环控制
- break用于终止当前整个循环体。一般情况下,break都是和if判断语句一起使用的,当if条件满足时使用break终止循环。
- continue语句 continue语句用于结束当前循环转而进入下一次循环
第16章 函数
#省略关键字function效果一致
function FUNCTION_NAME(){
command1 #函数体中可以有多个语句,不允许有空语句
command2
...
}
# 函数调用 FUNCTION_NAME不需要加小括号
FUNCTION_NAME #调用函数第17章 重定向
文件标识符是重定向中很重要的一个概念,Linux使用0到9的整数指明了与特定进程相关的数据流,系统在启动一个进程的同时会为该进程打开三个文件:标准输入(stdin)、标准输出(stdout)、标准错误输出(stderr),分别用文件标识符0、1、2来标识。如果要为进程打开其他的输入输出,则需要从整数3开始标识。默认情况下,标准输入为键盘,标准输出和错误输出为显示器。
- 标准输出覆盖重定向:>,如果指定的重定向文件不存在,则命令会先创建这个文件,如果文件存在且内容不为空,则原文件内容将被全部清空。
- 标准输出覆盖重定向其实是默认将文件标识符为1的内容重定向到指定文件中 ls -l /usr/ > ls_usr.txt ==> ls -l /usr/ 1> ls_usr.txt
- 命令由于各种原因出错时所产生的错误输出,其文件标识符为2,而标准错误的输出默认也是显示器。所以我们可以通过指定将文件标识符为2的内容重定向到指定文件,这样错误输出就不会出现在显示器上了。
2.标准输出追加重定向:>> 如果指定的重定向文件存在且内容不为空,重定向并不会清空原文件内容,而是将命令的输出新增到原文件的尾部。
- 标识输出重定向:>& 标识输出重定向的作用是将一个标识的输出重定向到另一个标识的输入。
- 标准输入重定向:<
5.管道:| 管道也是一种重要的I/O重定向方法,简单地说管道就是将一个命令的输出作为另一个命令的输入 - Here Document 用于在命令或脚本中按行输入文本。 Here Document的格式为
<
参考: 《Linux系统命令及Shell脚本实践指南》