1、重写TextView的onDraw方法
Android重写系统TextView
Git源码地址:
https://github.com/AndroidAppWidgetDemo/Android_Widget_CustomTextView
一、目的
重写Android系统TextView,是为了解决系统TextView中文换行所带来的参差不齐的锯齿效果。如图1.1为系统TextView的绘制结果,图1.2为期望中的TextView绘制结果。

图1.1 系统TextView的绘制结果

图1.2 期望TextView的绘制结果(重写后的效果)
系统TextView中文换行的大致原理为:
文本绘制绘制到某一行的行尾,并且剩余空间不足一个字符的空间时,将当前要绘制的字符放在下一行进行绘制(因此上一行结尾与该行的右边界有一小段空白)。
文本绘制到某一行的行尾,并且最后一个字符为标点符号时,那么将标点符号连同标点符号的上一个字符放在下一行进行绘制(因此上一行结尾与该行的右边界有稍微大的一段空白)。
所以这种绘制方式,会使TextView右侧的显示文本参差不齐。
二、重写TextView算法的原理
(1)、如何绘制:
对此TextView中的所有字符串使用“canvas.drawText(str, x,y,mPaint)”方法进行一个字、一个字的绘制。
(2)、目标:
主要的目标是解决标点带来的换行参差不齐的问题。
(3)、标点的说明:
这里要说明自己命名的几种标点名称:
单独出现的标点:“,” “。” “.”等
左侧标点:“《”“<”“{”等
右侧标点:“》”“>”“}”等
(4)、最初思考要处理的情况和解决方式:
对一行结尾的字符或者下一行开始的字符进行判断。根据标点的不同,分别进行字体间距的拉伸和压缩。
字间距压缩的情况:
正常绘制时(没有字间距的变化),如果一行绘制结束,但是在下一行的开始时,“单独出现的标点符号”被绘制到了该行的开头。即,“,”或者“。”出现在了行首的位置。
这种情况下,将上一行每两个字符之间的字间距进行压缩,使其刚好可以将本行首的标点放在上一行的行首。如图2.1所示。
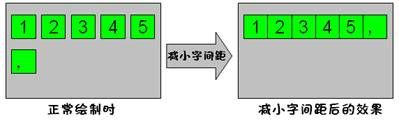
图2.1 字间距进行压缩
字间距的拉伸的情况:
这种情况下即,“《”、“<”等标点符号出现在一行的行尾位置。那么将该行字符的字间距进行拉伸,使这些标点出现在下一行的行首。如图2.2所示。

图2.2 字间距进行拉伸
(5)、最终的解决方案:
后来发现,只是简单的对“行尾字符”、“下一行的开始字符”进行标点的判断还不够。有的时候,几个标点会连续同时出现。下面举例,如图2.3所示。
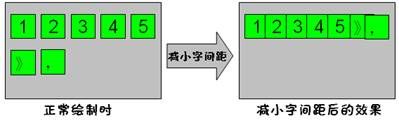
图2.3 字间距进行拉伸
因此在进行标点判断时,要对结尾的三个字符进行判断。即,一行的结尾字符、下一行的开始字符、下一行的第二个字符。如图2.4所示。
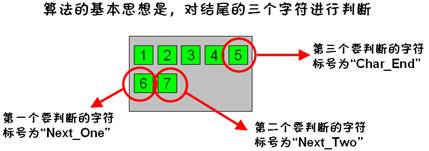
图2.4 要进行标点判断的三个字符位置
(6)、实现:
整个算法的实现,就是判断(5)中所介绍的三个字符与标点的对应情况。这种判断方式的实现,如图2.5所示。

图2.5标点判断的算法实现
三、简单代码的讲解
因为要解决的问题为文本的绘制问题,所以这里只重写了onDraw方法。onDraw方法中:
首先,通过this.getText().toString()方法,获取要绘制的文本字符串;
其次,对字符串进行第一次循环判断,第一次判断是将字符串分行(即获取整个文本中,每一行文本开始的Index和结束Index、该行字体间距拉伸了多少和压缩了多少);
再次,对字符串进行第二次循环,这次循环要做的工作就是根据第一次循环获取的信息进行一个字符一个字符的绘制了。
四、引入的问题
由于自定义TextView中的文本全部都是由“canvas.drawText(str, x,y,mPaint)”方法,一个字符一个字符的进行绘制的。所以当文本数量较大时,对与系统资源的占用较为严重,会造成界面中其他事件的反映较慢。
五、编码是否有影响??
(1)、代码中对于中文标点的判断:
/*
* Chinese punctuation
*/
public static boolean isPunctuation(char c) {
Character.UnicodeBlock ub = Character.UnicodeBlock.of(c);
if (ub == Character.UnicodeBlock.GENERAL_PUNCTUATION
|| ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION
|| ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS) {
return true;
}
return false;
}
对于中文标点的判断来自于网络
(2)、其他英文标点的判断:
/*
* English punctuation
*/
public static boolean isHalfPunctuation(char c) {
int count = (int) c;
if (count >= 33 && count <= 47) {
// !~/
return true;
} else if (count >= 58 && count <= 64) {
// :~@
return true;
} else if (count >= 91 && count <= 96) {
// [~
return true;
} else if (count >= 123 && count <= 126) {
// {~~
return true;
}
return false;
}
这里全部的英文标点是根据“ASCII编码表” 确定的,在不同的编码环境下,这些标点所对应的十进制数值是不变的。
(3)、成对出现标点的判断:
/*
* the left half of the punctuation . For example:" ( < [ { "
*/
public static boolean isLeftPunctuation(char c) {
int count = (int) c;
if (count == 8220 || count == 12298 || count == 65288 || count == 12304
|| count == 40 || count == 60 || count == 91 || count == 123) {
return true;
}
return false;
}
/*
* the right half of the punctuation . For example:" ) > ] } "
*/
public static boolean isRightPunctuation(char c) {
int count = (int) c;
if (count == 8221 || count == 12299 || count == 65289 || count == 12305
|| count == 41 || count == 62 || count == 93 || count == 125) {
return true;
}
return false;
}
这些成对出现的标点中,编码在0~255之间的是根据“ASCII编码表” 确定;其他的则为相应标点,转化为相应的十进制数值来确定。
当编码发生变化时,对于这些“相应标点,转化为相应十进制数值来确定的标点”是否会有影响?????????