12月13-14日,由云栖社区与阿里巴巴技术协会共同主办的《2017阿里巴巴双11技术十二讲》顺利结束,集中为大家分享了2017双11背后的黑科技。本文是《双11万亿流量下的分布式缓存》演讲整理,本文主要从Tair发展和应用开始谈起,接着谈及双11面临的挑战,重点分享了性能优化方面的实践,最后对缓存难题给出了解决方案。内容如下。
分享嘉宾:

宗岱:阿里巴巴资深技术专家,2008年加入淘宝,阿里分布式缓存、NoSQL数据库Tair和Tengine负责人。
Tair概览
Tair发展历程
Tair在阿里巴巴被广泛使用,无论是淘宝天猫浏览下单,还是打开优酷浏览播放时,背后都有Tair的身影默默支撑巨大的流量。Tair的发展历程如下:
2010.04 Tair v1.0正式推出@淘宝核心系统;
2012.06 Tair v2.0推出LDB持久化产品,满足持久化存储需求;
2012.10 推出RDB缓存产品,引入类Redis接口,满足复杂数据结构的存储需求;
2013.03 在LDB的基础上针对全量导入场景上线Fastdump产品,大幅度降低导入时间和访问延时;
2014.07 Tair v3.0 正式上线,性能X倍提升;
2016.11 泰斗智能运维平台上线,助力2016双11迈入千亿时代;
2017.11 性能飞跃,热点散列,资源调度,支持万亿流量。
Tair是一个高性能、分布式、可扩展、高可靠的key/value结构存储系统!Tair特性主要体现在以下几个方面:
高性能:在高吞吐下保证低延迟,是阿里集团内调用量最大系统之一,双11达到每秒5亿次峰值的调用量,平均访问延迟在1毫秒以下;
高可用:自动failover 单元化机房内以及机房间容灾,确保系统在任何情况下都能正常运行;
规模化:分布全球各个数据中心,阿里集团各个BU都在使用;
业务覆盖:电商、蚂蚁、合一、阿里妈妈、高德、阿里健康等。
Tair除了普通Key/Value系统提供的功能,比如get、put、delete以及批量接口外,还有一些附加的实用功能,使得其有更广的适用场景。Tair应用场景包括以下四种:
1.MDB 典型应用场景:用于缓存,降低对后端数据库的访问压力,比如淘宝中的商品都是缓存在Tair中;用于临时数据存储,部分数据丢失不会对业务产生较大影响;读多写少,读qps达到万级别以上。
2.LDB 典型应用场景:通用kv存储、交易快照、安全风控等;存储黑白单数据,读qps很高;计数器功能,更新非常频繁,且数据不可丢失。
3.RDB 典型应用场景:复杂的数据结构的缓存与存储,如播放列表,直播间等。
4.FastDump 典型应用场景:周期性地将离线数据快速地导入到Tair集群中,快速使用到新的数据,对在线读取要求非常高;读取低延迟,不能有毛刺。
双11挑战怎么办?
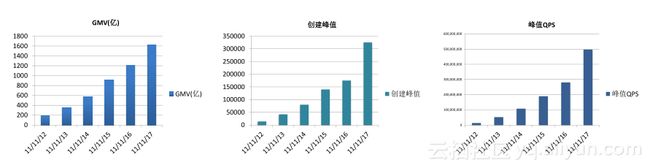
2012-2017年数据如图,可以看到,2012年GMV小于200亿,2017年GMV达到1682亿,交易创建峰值从1.4万达到32.5万,峰值QPS从1300万达到近5亿。我们可以得出,Tair访问峰值增速:Tair峰值 > 交易峰值 > 总GMV,如何确保成本不超过交易峰值增速?对于带数据的分布式系统来说,缓存问题都是比较难解决的,缓存流量特别大,2017年双11后,我们彻底解决掉了缓存问题。我们现在的交易系统和导入系统都是多地域多单元多机房部署的,如何快速部署业务系统呢?
多地域多单元
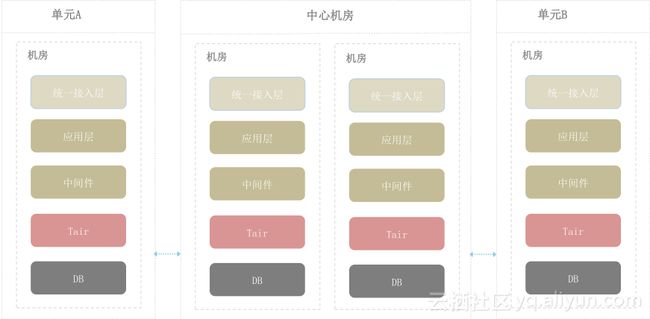
多地域多单元首先是中心机房,我们做了双机房容灾,两侧还有若干个单元。机房内系统图如图,从流量接入进统一接入层-应用层-中间件-Tair-DB,在数据层我们会做多地域的数据同步。
弹性建站
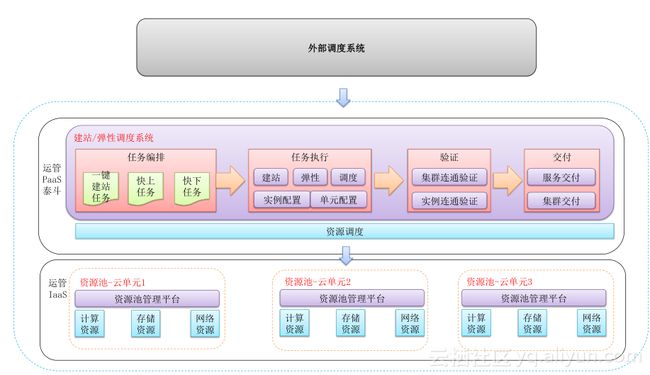
我们需要系统具备弹性建站的能力。Tair是一个复杂的分布式存储系统,我们为之建立了一整套运营管控系统泰斗,在泰斗里建设弹性建站系统,它会经过一系列工作步骤将Tair系统建设起来,我们还会从系统层面、集群层面和实例连通层面进行验证,以确保系统功能、稳定性万无一失。
Tair的每一个业务集群水位其实是不一样的,双11前的每一次全链路压测下,由于业务模型的变化,所用Tair资源会发生变化,造成水位出现变化。在此情况下,我们需要每一次压测完在多个集群间调度Tair资源,如果水位低,就会把某些机器服务器资源往水位高挪,达到所有集群水位值接近。
数据同步
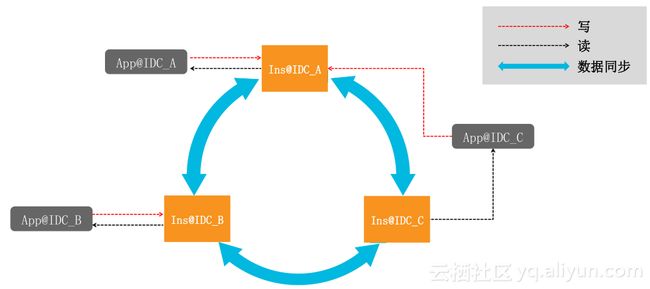
对于单元化业务,我们提供了本单元访问本地Tair的能力,对于有些非单元化业务,我们也提供了更灵活的访问模型。同步延迟是我们一直在做的事情,2017年双11每秒同步数据已经达到了千万级别,那么,如何更好地解决非单元化业务在多单元写入数据冲突问题?这也是我们一直考虑的。
性能优化降成本
服务器成本并不是随着访问量线性增长,每年以百分之三四十成本在下降,我们主要通过服务器性能优化、客户端性能优化和不同的业务解决方案三方面达到此目的。
内存数据结构

图为MDB内存数据结构示意图,我们在进程启动之后会申请一大块内存,在内存中将格式组织起来。主要有slab分配器、hashmap和内存池,内存写满后会经过LRU链进行数据淘汰。随着服务器CPU核数不断增加,如果不能很好处理锁竞争,很难提升整体性能。
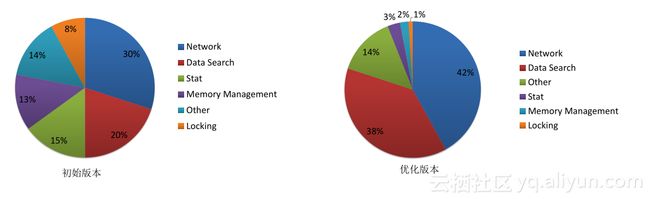
参考了各种文献和操作系统的设计,我们使用了细粒度锁、无锁数据结构、CPU本地数据结构和读拷贝更新(读链表时不需要加锁)。左图为未经过优化时锁竞争各个功能模块消耗图,可以看到网络部分和数据查找部分消耗最多,优化后(右图)有80%的处理都是在网络和数据查找,这是符合我们期望的。
用户态协议栈

锁优化后,我们发现很多CPU消耗在内核态上,这时我们采用DPDK+Alisocket来替换掉原有内核态协议栈,Alisocket采用DPDK在用户态进行网卡收包,并利用自身协议栈提供socket API,对其进行集成。我们与业内类似系统进行了对比,如图。
内存合并
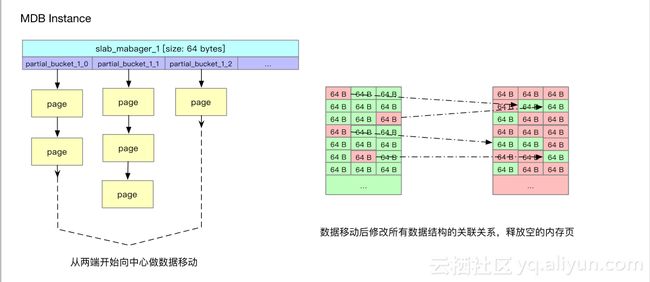
单机性能提升足够高后,带来问题是单位qps对应内存量变少了,怎么解决呢?我们发现公用集群整体看内存还是有的,某些slab没有办法写入, 比如64字节slab没有被写满,但是72字节slab全部写满了,内存池都被申请完了,我们把64字节slab空闲页相互合并,这样可以释放大量空闲页。其中不可避免加入模式锁,在触发合并阈值情况下,切换成加锁状态,合并都是在访问量低峰期做的,对于业务峰值来说没有问题。
客户端优化
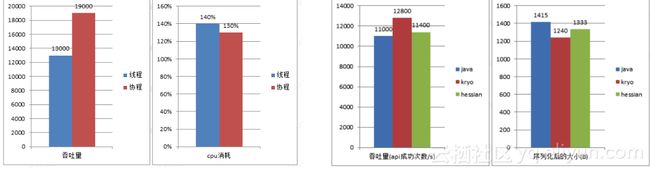
客户端我们做了两方面优化:网络框架替换,适配协程,从原有的mina替换成netty,吞吐量提升40%;序列化优化,集成 kryo和hessian,吞吐量提升16%+。
内存网格
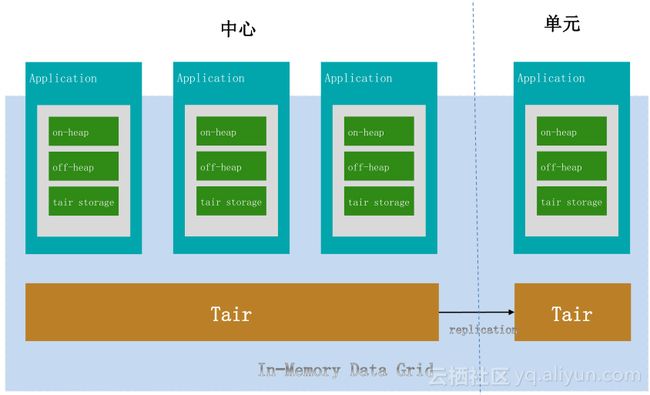
如何与业务结合来降低整体Tair与业务成本?Tair提供了多级存储一体化解决业务问题,比如安全风控场景,读写量超大、有大量本地计算,我们可以在业务机器本地存下该业务机器所要访问的数据,大量读会命中在本地,而且写在一段时间内是可合并的,在一定周期后,合并写到远端Tair集群上作为最终存储。我们提供读写穿透,包括合并写和原有Tair本身具有多单元复制的能力,双11时业务对Tair读取降至27.68%,对Tair写入降至55.75%。
热点难题已解决
缓存击穿
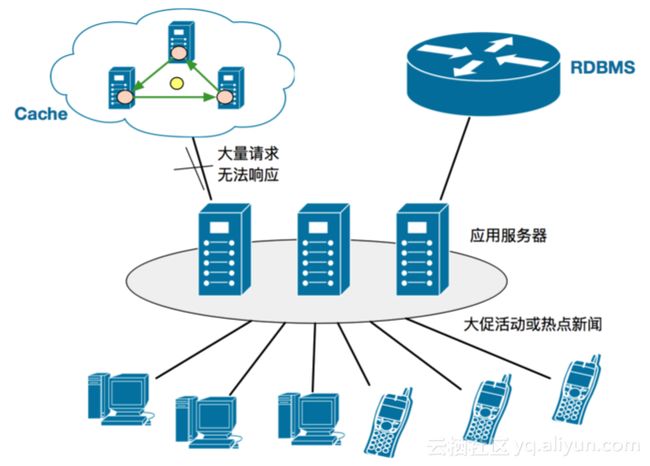
缓存从开始的单点发展到分布式系统,通过数据分片方式组织,但对每一个数据分片来说,还是作为单点存在的。当有大促活动或热点新闻时,数据往往是在某一个分片上的,这就会造成单点访问,进而缓存中某个节点就会无法承受这么大压力,致使大量请求没有办法响应。即便是限流也是有损操作,可能也会造成全系统崩溃。我们发现,问题根源是访问热点,需要彻底解决该问题。
热点散列
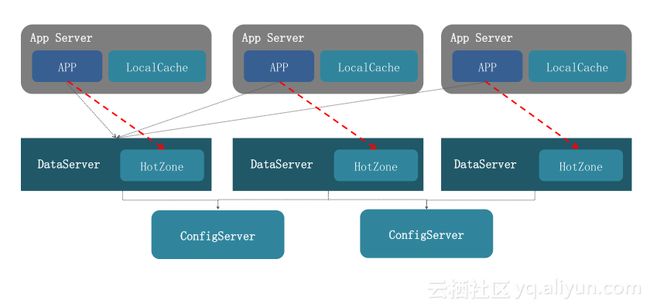
经过多种方案的探索,采用了热点散列方案。我们评估过客户端本地cache方案和二级缓存方案,它们可以在一定程度上解决热点问题,但各有弊端。而热点散列直接在数据节点上加hotzone区域,让hotzone承担热点数据存储。对于整个方案来说,最关键有以下几步:
智能识别。热点数据总是在变化的,或是频率热点,或是流量热点。
实时反馈。采用多级LRU的数据结构,设定不同权值放到不同层级的LRU上,一旦LRU数据写满后,会从低级LRU链开始淘汰,确保权值高的得到保留。
动态散列。当访问到热点时,Appserver和服务端就会联动起来,根据预先设定好的访问模型动态散列到其它数据节点hotzone上去访问,集群中所有节点都会承担这个功能。
通过这种方式,我们将原来单点访问承担的流量通过集群中部分机器来承担。

可以看到,双11零点的刹那,我们吸收了800多万次的热点访问。如果没有做热点散列,散列前的指数都会超过死亡水位线。
写热点
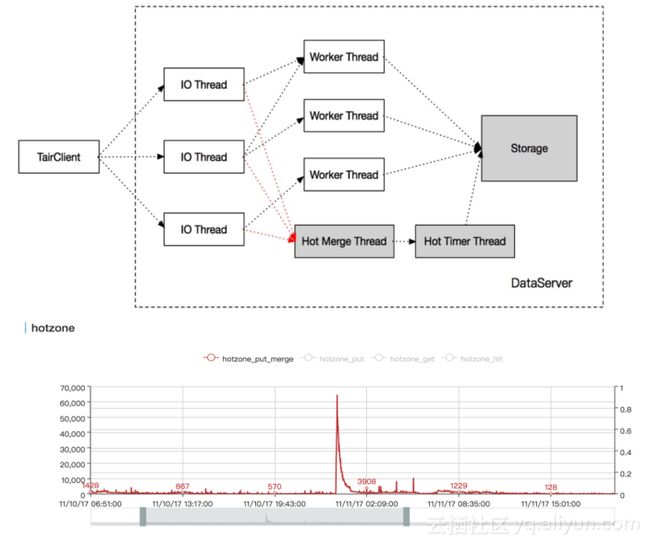
写热点与读热点有类似的地方,也需要把热点实时识别出来,然后通过IO线程把有热点key的请求放给合并线程去处理,会有定时处理线程提交给存储层。
经过双11考验对读写热点的处理,我们现在可以放心的说,我们将缓存包括kv存储部分的读写热点彻底解决了。