MGR单主到底做不做冲突检测?
和同事探讨一个问题, MGR单主做不做冲突检测.
我理解是不需要做的, 因为已经明确只有主节点才能写入数据了, 那么必然不会有数据冲突的可能, 没必要再做冲突检测浪费性能了.
看了下官方文档
In single-primary mode, Group Replication enforces that only a single server writes to the group, so compared to multi-primary mode, consistency checking can be less strict and DDL statements do not need to be handled with any extra care
这里less strict让人很迷惑, 意思是还有冲突检测呗, 但是和多主区别是啥没说
之前看MGR的时候看过网易温正湖的文章, 路上搜了下, 发现两个文章:
MySQL MGR事务认证机制优化

MySQL事务在MGR中的漫游记 - 事务认证

其实他文章哪些源码我也看不懂. 我是不想别人说啥我就信啥, 所以想找到知识源头
到家我搜了下conflict_detection_enable
搜到这个网站https://s0dev0mysql0com.icopy.site/doc/dev/mysql-server/latest/classCertifier.html

那么这个网站源头又是啥呢, 又搜了下
https://dev.mysql.com/doc/dev/mysql-server/latest/classCertifier.html
这里面说的就很清楚了
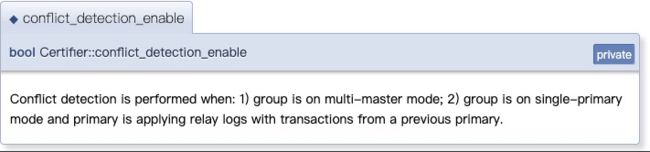
就是说单主, 主库挂了, 新主库应用原主库事务的时候才做冲突检测
想起以前做过实验压测2 5.7MGR是否要应用完所有binlog才会选举出新主
实际上5.7官方文档有描述
单主模式下:
当选择一个新的主数据库时,它只有在处理完所有来自旧主数据库的事务后才可写。 这样可以避免旧的主事务中的旧事务与在该成员上执行的新事务之间可能发生的并发问题。 在新的主数据库重新路由客户端应用程序之前,最好等待新的主数据库应用其复制相关的中继日志。
When a new primary is elected, it is only writable once it has processed all of the transactions that came from the old primary. This avoids possible concurrency issues between old transactions from the old primary and the new ones being executed on this member. It is a good practice to wait for the new primary to apply its replication related relay-log before re-routing client applications to it.
https://dev.mysql.com/doc/refman/5.7/en/group-replication-single-primary-mode.html
在8.0文档中是这样写的
选举或任命新的主库时,可能会积压已应用于旧的主库但尚未在此服务器上应用的更改。 在这种情况下,直到新的主数据库赶上旧的主数据库,读写事务可能会导致冲突并回滚,而只读事务可能会导致陈旧的读取。
When a new primary is elected or appointed, it might have a backlog of changes that had been applied on the old primary but have not yet been applied on this server. In this situation, until the new primary catches up with the old primary, read-write transactions might result in conflicts and be rolled back, and read-only transactions might result in stale reads.
https://dev.mysql.com/doc/refman/8.0/en/group-replication-single-primary-mode.html
这其实很合理, 假设一个单主模式MGR集群 三个节点A, B, C
A是主库, app向T1表插入三条数据, 主键值分别为 1,2,3
B,C收到binlog event, 但还未应用, 此时A宕机, B当选为新主库, 那么B需要应用在A产生的三个插入1,2,3. 如果没有冲突检测, 在B应用1,2,3前,业务有插入了新数据1,2,3, 那么就明显有问题, 所以此阶段一定要做冲突检测.
仔细看感觉5.7和8.0的描述有了"很大区别" 5.7说
When a new primary is elected, it is only writable once it has processed all of the transactions that came from the old primary. 新主必须应用完原主所有事物才可写
8.0说In this situation, until the new primary catches up with the old primary, read-write transactions might result in conflicts and be rolled back, and read-only transactions might result in stale reads.
在新主应用完原主所有事物前, 写可能会冲突回滚, 而读可能会读到旧数据
我猜测这是说5.7单主是彻底关闭了冲突检测, 新主应用原主完原主事务前是不可写的, 通过不可写避免了冲突, 还需要继续做实验测试, 新主应用原主完原主事务前, 是否可以执行不冲突的事务(比如我们像T1表写大量数据制造transactions_behind, 新主当选后, 我们想T2表写数据, 这明显是不冲突的.)
那么看来8.0比5.7有了改进, 在新主应用原主完原主事务期间开启冲突检测, 那么按照上面的实验例子, 业务就可以执行"不冲突的事务了"
但是是否这样对业务来说是可接受的呢? 也许业务希望新主应用原主完原主事务后才可写是合理的, 所以有了下面的参数
8.0.14后增加了参数group_replication_consistency, 从根本上解决了读旧数据的问题(写操作无需设置参数也会等待应用完所有backlog才可以执行)
BEFORE_ON_PRIMARY_FAILOVER
New RO or RW transactions with a newly elected primary that is applying backlog from the old primary are held (not applied) until any backlog has been applied. This ensures that when a primary failover happens, intentionally or not, clients always see the latest value on the primary. This guarantees consistency, but means that clients must be able to handle the delay in the event that a backlog is being applied. Usually this delay should be minimal, but does depend on the size of the backlog.
在发生切换时,连到新主的事务会被阻塞,等待先序提交的事务回放完成;这样确保在故障切换时客户端都能读取到主服务器上的最新数据,保证了一致性
上面的描述不严谨, 出自知数堂田鹏的文章MySQL MGR"一致性读写"特性解读. 事实上只读事务也会等待, 除了以下只读事务(参考此译文https://cloud.tencent.com/developer/article/1478455)
- SHOW commands
- SET option
- DO
- EMPTY
- USE
- SELECTing from performance_schema database
- SELECTing from table PROCESSLIST on database infoschema
- SELECTing from sys database
- SELECT command that don’t use tables
- SELECT command that don’t execute user defined functions
- STOP GROUP_REPLICATION command
- SHUTDOWN command
- RESET PERSIST
个人理解如果设置BEFORE_ON_PRIMARY_FAILOVER虽然会保证一致性, 如果节点新主与原主延迟过大, 新主应用差异日志时间过长, 那么会导致大量连接进来处于等待状态, 导致Threads_running暴涨, 甚至连接数打满新主崩溃
至8.0.18MGR选主算法是
1.选版本最小的
2.选权重最大的
3.选uuid排序最小的
所以并没有判断哪个节点延迟最小
https://dev.mysql.com/doc/refman/8.0/en/group-replication-single-primary-mode.html
那么多主如何处理?
从参数说明上来看BEFORE_ON_PRIMARY_FAILOVER应该只是针对单主, 所以除非应用显示指定了group_replication_consistency, 否则多主还是会读到旧数据.
对于写入, 因为多主是要做冲突检测的, 所以我们假设一个场景
多主MGR, N1,N2,N3, 单写N1, T1(id int primary key, sname varchar(10))表插入
1,fan GTID: GROUP_UUID:1
2,bo GTID: GROUP_UUID:2
3,shi GTID: GROUP_UUID:3
目前GTID: GROUP_UUID:1-3
N1宕机, N2应用到1, 未执行2,3. 此时client像N2插入(2,hehe) 那么此时N2这个插入版本是GROUP_UUID:1
而冲突检测数据库中id=2这一行的版本是GROUP_UUID:1-2, 所以这条插入会冲突检测失败回滚掉
以上是我的理解, 目前没有测试