大数据进阶必修课!Spark实战决策树算法
目录
- 5.SparkMLlib决策树算法
- 5.1决策树算法
- 5.2 算法源码分析
- 5.3应用实战
- 5.3.1 数据说明
- 5.3.2 代码详解
5.SparkMLlib决策树算法
5.1决策树算法
决策树DecisionTree的结构是树型的,由节点和有向边组成。节点由内部节点和叶子节点组成,内部节点表示一个特征的度量,叶子节点表示一个具体的分类,每个分支表示度量的输出结果。决策树算法采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一颗熵值减少最快的树,当到达叶子节点出时熵为零,这事就可以判定每个叶子节点中的样本都属于同一类别。
决策树算法进行学习的过程其实是采用启发式的方法从训练数据集上归纳一组分类规则,求出局部最优即可。每次在内部节点进行度量时都选择最优的那个特征作为划分依据。通常分为三个步骤:特征选择,决策树生成和剪枝。下图就是一个决策树的例子: 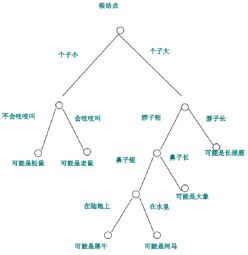
(1)特征选择
特征选择的目的是找出局部最优特征,依据这个特征对样本数据进行分类达到最好的效果。这个分类的好坏取决于分类后的节点数据集合有序程度是否更好。分类后数据越有序,这个氟利昂就越好。在使用决策树进行分类的时候,通常选择信息熵作为节点数据有序性的度量。信息熵就是描述信息量的混乱程度,熵越小,信息越有序,我们使用信息增益来表示信息熵的改变。
(2)生成决策树
决策树的生成算法有ID3和C4.5。ID3算法是基于信息熵来构建决策树,是一种贪心算法。在每个节点选择还没被用来作为划分依据的、有最高信息增益的特征来作为划分标准,也就是以信息熵下降最快作为选取度量特征的标准,然后迭代重复这个过程,指导最后的叶子节点。其核心就是信息增益的计算,也就是一个事件中前后发生的不同信息之间的差值。C4.5算法使用了信息增益比作为度量标准,克服了ID3划分过于充分的缺点。
(3)剪枝
与其他的机器学习算法类似,决策树也存在过拟合的问题,可以通过剪枝来提高泛化能力,就是在决策树模型对训练数据的预测误差和树的复杂度之间寻找一个最优的解决方法。提出了一个由预测误差和树复杂度组成的损失函数,剪枝算法从叶子节点往上寻找,比较剪掉该叶子节点前后损失函数的变化,如果剪掉后损失函数更小,就进行剪枝。
5.2 算法源码分析
MLlib中的决策树分类模型可以完成二元及多元分类任务。Split为分裂点,bin为划分数。一个split把数据集分为两部分,最后统计产生多少个划分数。在使用剪枝方面,MLlib采用前向剪枝,即提前设定参数,当满足一定条件时候就停止构建树,主要是树的最大深度:maxDepth,每个字节点最少的训练样本数:minInstancePerNode,最小的信息增益:minInfoGain。
MLlib中决策树模型的构建有以下几个部分:
(1)DecisionTree:决策树伴生对象,包括了train,trainClassifier方法,设置决策树参数,新建决策树类,执行run方法训练,train方法参数如下:
- input:训练数据集,格式为RDD(label,features);
- algo:回归或分类算法;
- impurity:有序度计算方法,也就是信息增益的计算;
- numClasses:分类数量,默认2;
- maxBins:分裂特征的最大划分数量。
本教程使用train方法或trainClassifier方法均可进行分类器的训练。
(2)DecisionTree类:包含run方法;
(3)RandomForest类:一棵树的随机森林就是决策树;
(4)决策树训练准备:
建立原数据——buildMeatdata,包括特征数量、样本数量、分类数量、划分数、分类特征信息、无序特征信息等;
查找特征的分裂与划分——使用findSplitsBins找出每个特征可能出现的split和bin;
转换样本为TreePoint格式即把样本点按分裂点条件分到所属的bin中;
(5)训练决策树模型
取得决策树分裂所需的节点;
查找最优的分裂顺序;
(6)决策树模型:DecisionTreeModel类,包含predict方法。
5.3应用实战
5.3.1 数据说明
本次实战所用数据是iris数据集,以鸢尾花的特征作为数据来源,包含了150个数据样本,分为3类,每个类别50个数据样本,每条数据样本有4个维度的特征和1个分类标签,决策树可以用来做分类和回归,这个实例将依据这个数据集做出分类和回归两个模型。数据示例如下:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.3.2 代码详解
首先进行数据的处理,对标签和特征进行处理并分组:
//导入需要的机器学习包
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.linalg.{Vector,Vectors}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
//读取数据
//导入spark.implicits._,将RDD数据转换为DataFrame
import spark.implicits._
//定义一个schema:Iris
case class Iris(features: org.apache.spark.ml.linalg.Vector, label: String)
//从文件中读取数据,第一个map用“,”把每行数据分开,前四部分是特征,
//最后是花的分类。
//把这些特征存储在Vector中,创建为Iris(RDD),再转化为DataFrame
val data = spark.sparkContext.textFile("file:///mnt/hgfs/thunder-
download/MLlib_rep/data/iris.txt").map(_.split(",")).map(p => Iris(Vectors.dense(p(0).toDouble,p(1).toDouble,p(2).toDouble, p(3).toDouble),p(4).toString())).toDF()
输出结果如下:
data: org.apache.spark.sql.DataFrame = [features: vector, label: string]
//将之前得到的数据注册成表iris
data.createOrReplaceTempView("iris")
//使用sql查询语句查询数据
val df = spark.sql("select * from iris")
//打印出查询的所有数据
df.map(t => t(1)+":"+t(0)).collect().foreach(println)
输出结果为:
Iris-setosa:[5.1,3.5,1.4,0.2]
Iris-setosa:[4.9,3.0,1.4,0.2]
Iris-setosa:[4.7,3.2,1.3,0.2]
Iris-setosa:[4.6,3.1,1.5,0.2]
Iris-setosa:[5.0,3.6,1.4,0.2]
Iris-setosa:[5.4,3.9,1.7,0.4]
Iris-setosa:[4.6,3.4,1.4,0.3]
Iris-setosa:[5.0,3.4,1.5,0.2]
Iris-setosa:[4.4,2.9,1.4,0.2]
Iris-setosa:[4.9,3.1,1.5,0.1]
Iris-setosa:[5.4,3.7,1.5,0.2]
Iris-setosa:[4.8,3.4,1.6,0.2]
……
//获取标签列和特征列,索引并重命名
val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol(
"indexedLabel").fit(df)
输出结果:
labelIndexer: org.apache.spark.ml.feature.StringIndexerModel =
strIdx_2a3442136787
创建成功
val featureIndexer = new
VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(df)
输出结果:
featureIndexer: org.apache.spark.ml.feature.VectorIndexerModel =
vecIdx_89a5b864820f
//把预测的类别重新转换为字符型
val labelConverter = new
IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.labels)
//数据样本随机划分为训练集和测试集,比例7:3
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
输出结果为:
trainingData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [features: vector, label: string]
testData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [features: vector, label: string]
//构建决策树分类模型
//导入构建模型所需要的包
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
//使用setter方法设置决策树模型的参数
val dtClassifier = new
DecisionTreeClassifier().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures")
输出结果:
dtClassifier: org.apache.spark.ml.classification.DecisionTreeClassifier =
dtc_bf350ce09979
构建模型成功
//在pipline也就是机器学习工作流中设置参数
val pipelinedClassifier = new Pipeline().setStages(Array(labelIndexer, featureIndexer, dtClassifier, labelConverter))
//训练决策树分类模型
val modelClassifier = pipelinedClassifier.fit(trainingData)
输出结果:
modelClassifier: org.apache.spark.ml.PipelineModel = pipeline_c321e4346ddf
//预测
val predictionsClassifier = modelClassifier.transform(testData)
输出结果:
predictionsClassifier: org.apache.spark.sql.DataFrame = [features: vector, label: string ... 6 more fields]
//选择预测结果的前十个显示
predictionsClassifier.select("predictedLabel", "label", "features").show(10)
输出结果:
+--------------+---------------+-----------------+
|predictedLabel| label| features|
+--------------+---------------+-----------------+
| Iris-setosa| Iris-setosa|[4.6,3.1,1.5,0.2]|
| Iris-virginica| Iris-versicolor|[4.9,2.4,3.3,1.0]|
| Iris-setosa| Iris-setosa|[4.9,3.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[4.9,3.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[5.0,3.0,1.6,0.2]|
| Iris-setosa| Iris-setosa|[5.0,3.4,1.5,0.2]|
| Iris-setosa| Iris-setosa|[5.0,3.4,1.6,0.4]|
| Iris-setosa| Iris-setosa|[5.0,3.5,1.3,0.3]|
| Iris-setosa| Iris-setosa|[5.0,3.5,1.6,0.6]|
| Iris-setosa| Iris-setosa|[5.1,3.5,1.4,0.3]|
+--------------+---------------+-----------------+
only showing top 10 rows
//对决策树分类模型的预测结果进行评估
val evaluatorClassifier = new
MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("accuracy")
//计算精确度和测试误差
val accuracy = evaluatorClassifier.evaluate(predictionsClassifier)
输出结果:
准确率accuracy: Double = 0.9333333333333333
Test Error = 0.06666666666666665
//输出决策树模型的结构
val treeModelClassifier =
modelClassifier.stages(2).asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model:\n" + treeModelClassifier.toDebugString)
输出结果:
Learned classification tree model:
DecisionTreeClassificationModel (uid=dtc_bf350ce09979) of depth 4 with 13 nodes
If (feature 2 <= 1.9)
Predict: 2.0
Else (feature 2 > 1.9)
If (feature 3 <= 1.7)
If (feature 2 <= 5.1)
If (feature 0 <= 4.9)
Predict: 1.0
Else (feature 0 > 4.9)
Predict: 0.0
Else (feature 2 > 5.1)
Predict: 1.0
Else (feature 3 > 1.7)
If (feature 2 <= 4.8)
If (feature 0 <= 5.9)
Predict: 0.0
Else (feature 0 > 5.9)
Predict: 1.0
Else (feature 2 > 4.8)
Predict: 1.0