华为开发者大会HDC.Cloud技术探秘:云搜索服务技术实践

搜索是一个古老的技术,从互联网发展的第一天开始,搜索技术就绽放出了惊人的社会和经济价值。随着信息社会快速发展,数据呈爆炸式增长,搜索技术通过数据收集与处理,满足信息共享与快速检索的需求。基于搜索技术,更是缔造了谷歌、百度、雅虎等一批知名企业。
搜索也是一个蓬勃发展技术,它串联起了问答、地图、小程序等各式各样新的应用形态。最近十几年间,也应用到了更早前并无直接关联的IT运维等领域。更是通过技术融合推动了AI、NoSQL、OLAP等相关技术的发展。
日前,华为开发者大会HDC.Cloud DevRunLive开发者技术沙龙上,华为云专家做了关于“云搜索服务技术实践”的技术演讲。本文为大家介绍业界流行的搜索应用场景,开源Elasticsearch的应用,以及华为云搜索服务在此基础上的一些增强。
一、什么是搜索?
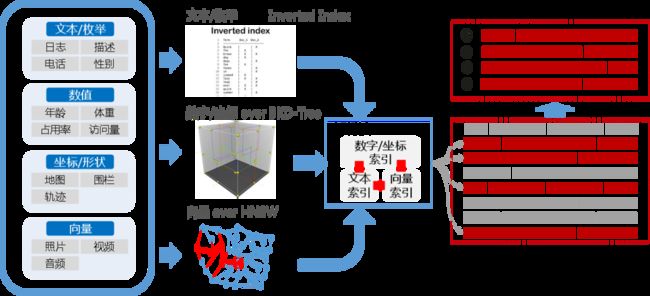
搜索行为的基本流程
从技术上来看,搜索指的是:依据不同类型数据的条件组合,筛选出符合条件的记录(或称文档),并依照某种排序规则进行TopN的选择,最后进行呈现。
具体的过程,如上图所示。我们在生活中遇到的各种类型数据,像新闻文档、电话号码、年龄、体重、地图坐标等,在搜索系统各种会映射成不同类型的索引,比如文本一类的数据被映射成倒排表索引,数字一类的数据被映射成KD-Tree索引。还有一类特殊的数据,像图片、视频等多媒体信息,他们不能直接被表达为索引,而是通过机器学习表达为一个个向量数据,然后存储为搜索系统中的向量索引。
各种数据转换为索引后,我们就可以通过不同的条件描述组合来进行搜索了。通过索引来搜索相比一条条数据的过滤,通常速度会快好几个数量级,从而快速筛选出符合条件的数据条目。
最后,当筛选出来的数据条目非常多的时候,人难以一次阅读过来,还有有一个排序的过程,比如按照是否最新、猜测是否最符合搜索目的等方法挑选出其中的Top N条,最后进行呈现。
上述是从技术角度来阐述什么是搜索,从实际应用来看,更加容易体会搜索的形态以及价值。
搜索的部分应用
从业务上来讲,搜索是一种灵活提取/组织企业知识的手段,面向客户或企业自身都有很强的应用价值。在泛互联网/泛政府/大中小企业都有广泛的应用。
二、企业如何构筑自己的搜索系统?
如果从头开始构筑自己的搜索系统,会是一个非常耗费时间与资源的事情,因为搜索技术确实比较复杂。就比如前面说过的表达文本索引的倒排表,就会有FST、PForDelta、Skip List等等很多底层数据结构以及工程实践要实现。再加上行列存储、数值索引、向量索引、分布式等其他方面的内容,投入的时间和资源会是一个惊人的数字。对于不是以提供搜索引擎为主业的企业来说,最好的选择是从一个优秀的开源软件开始,比如Elasticsearch。

Elasticsearch,简称ES
Elasticsearch拥有着强大的功能,从它开始搭建搜索系统能够节省大量的时间与资源。
当然使用开源软件也不是一个一劳永逸的事情。如果是一个单机的Demo,很容易。但是一旦上到生产系统,事情就变得不那么简单了。
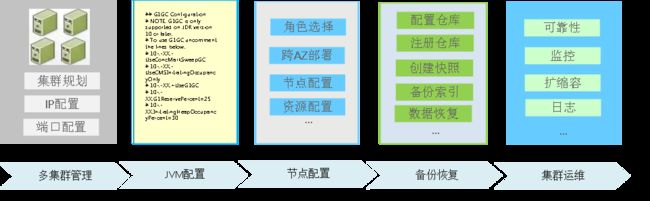
生产环境下,事情变得复杂
在生产环境中,要考虑集群化以应对大量的数据与请求,还要考虑业务连续性所要求的可靠性以及极端情况下可恢复性,防止恶意操作或者误操作的安全准备,以及业务的扩张带来的对应资源添加等等。这些问题都需要大量的经验来支撑操作,这使得企业不得不投入额外的精力来操作这些不属于主业务的事务。
为了帮助企业更好的完成上述任务,华为云推出了云搜索业务,能够大幅简化生产环境下Elasticsearch的维护工作量,并且在部分ES原本处理较薄弱的地方,进行了增强。

华为云搜索,为生产环境充分考虑
华为云为了让企业在生产环境上的搜索系统更易于构筑,做了如下几个方面的工作:
√兼容性:100% 兼容Elasticsearch APIs,支持5.x到7.x多个版本
√易用性:分钟级集群创建、扩容,一键式备份与恢复,7*24看护
√安全性:支持优秀的分权分域,底层磁盘加密
√高可用:扩容节点、磁盘业务不中断,更新词库业务不中断
√可靠性:支持跨AZ冗余配置,自动化的增量备份
√高性能:慢报表自动加速,费时降低百倍,集成向量索引,多媒体检索时延低至ms级
√低成本:存算分离的架构,长时间数据存留成本降至20%
前面的5条,可以笼统的归结为生产环境上的必要条件。这里重点聊一下最后两条中的内容:向量索引、存算分离、报表加速。
三、向量索引
向量搜索主要是为了多媒体内容检索准备的。一个搜索请求假设带上一张图片,这个图片会被事先转换为一个特征向量(比如人脸图片典型特征就是一个256维的Float向量),这个向量会被送入搜索系统与其他存档的向量进行比对,如果两个向量的距离越近(欧式距离、余弦距离等),那么就意味着原始的图片约相似,从而有可能被搜索出来。由于可以对多媒体进行搜索,向量的搜索技术被大量用于拍照选商品、人脸匹配、高速路口车辆寻迹等场景。
Elasticsearch也有向量搜索的能力,叫做DenseVector,但是这个方式有一定的缺陷。
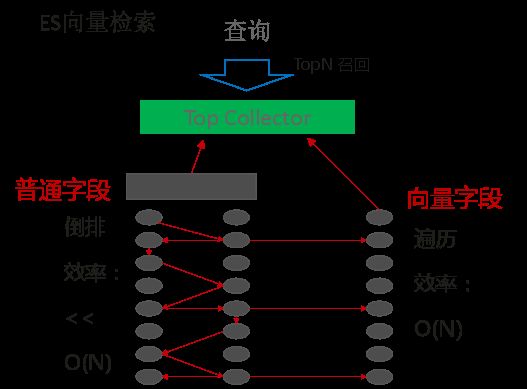
ES的向量处理方式
如上图所示,进行一个联合条件检索,比如“梅观路口”AND <某汽车照片向量>这样的条件来检索出现在梅观路口某车辆历史经过的记录时, 开源ES的做法是先通过倒排索引快速找到符合“梅观路口”的记录,再一条条和查询的小汽车向量进行比较,找出TopN比如前20条向量距离最近的。这样一来,如果符合“梅观路口”的记录有一亿条,就要比较一亿次,效率很低。
华为云搜索采用向量索引来解决这个问题。
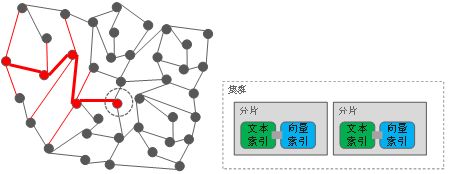
华为云搜索的向量处理方式
如上图所示,主要有两个突破点,第一个突破点是如何对向量采用一种合理的索引编码方式,能够带来远小于O(N)的时间复杂度。我们的方式是采用HNSW的编码方式,带来近似O(Log)的时间复杂度。第二个突破点,是如何与其他类型的索引协同工作,我们通过改写Lucene和ES的代码,在底层新增了一种数据结构,支持与其他索引进行互通,通过向量索引快速锁定搜索范围从而减小其他条件的索引范围。最后的总体效果就是,哪怕是上亿的数据,得出结果也只要数十毫秒。
四、存算分离
如文章开头所讲,近十几年来,搜索因为优良的灵活度,被逐步用于企业的日志定位,指标运营运维任务中,替换了原始的Log文件Ctrl+F和Excel表格运维的操作方式。ES有很大一部分的实际应用都是针对这个场景。对于重度依赖IT系统的企业来讲,日志与指标的产生是源源不断的。但是这些数据的价值随着时间的推移,会逐步降低,但价值却不会完全消失。对于企业来讲,这很两难,如果长时间保留这些数据,使用开源ES的成本相当高昂,如果仅仅保留最近几天的数据,那么万一需要回溯一个疑难杂症或者复盘一个运营事件,需要用到上周甚至是上月的数据怎么办呢?
华为云给出的方案是存算分离。
通过四个方法解决了其中的四个关键点:
依照时序数据不会修改的特征,数据分类为热数据与冷数据,热数据可写可搜,冷数据可搜不可写。这样解决了时序数据特征到数据处理模型的映射。
热转冷时,将数据转移到对象存储,由于对象存储使用的是纠删码存储,冗余与有效载荷的比值远小于1,大幅节约了原先由于多副本带来的存储成本。
计算节点内还是保留多副本概念,用于维护可靠性,但是都仅仅是指向同一份对象存储,不会重复存储。
对于冷数据,不会长时间维持全部的元数据以及Cache,而是自建内存管理机制,尽可能的少用内存,实现小马拉大车,少量节点带动大量数据。
通过上述方式,实现了日志数据保留成本下降至20%,同时数据容量相比优化前提升12倍。
五、报表加速
为了统计PV/UV曲线或者请求的平均时延曲线等运营运维的数据用于企业业务或者IT管理的决策参考,通常IT部门会引入ES来根据原始的指标数据来制作报表。但是这个方式在统计跨度稍大的范围时,就很容易出现报表很慢或者OOM的情况。
华为云采用了报表加速技术解决。
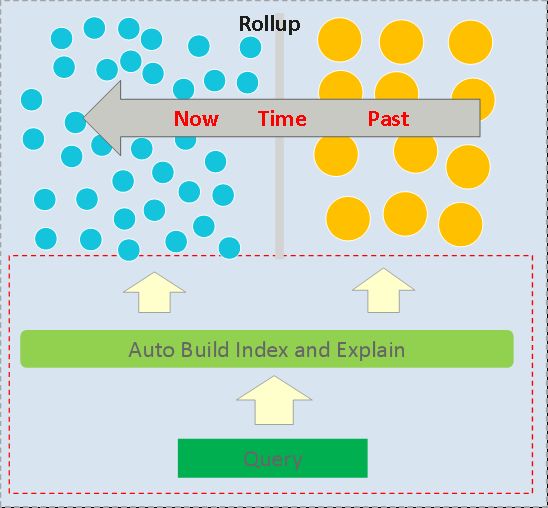
华为云搜索报表加速方式
如上图,这个方案分为两个部分,上面一部分是Rollup。Rollup的原理并不复杂,把时间按照一定的粒度比如5分钟进行分割,将里面的数据按照配置好的聚合语句预先进行一遍聚合计算。那么后续再来报表请求的时候,直接基于预先聚合好的粗粒度数据计算,可以大幅提升计算效能。这个方案ES的非开源包XPack中有实现,华为云搜索也采用了自己的实现。
更贴近客户也是更独特的部分是图中的下半部分。由于ES中Rollup是一套独立的API,用户需要自己进行预聚合的操作与任务维护。华为云搜索则是通过判断用户的慢日志,来自动化的协助用户决策,是否需要进行加速,并生成中间数据辅助计算。优化前后,用户的业务不需要进行任何修改,在已有的接口之上便可获得加速能力。
最后得到的效果是,基本所有加速的报表提速都在100倍以上。

欢迎扫码试用华为云搜索服务
点击阅读原文,回看华为开发者大会HDC.Cloud DevRunLive开发者技术沙龙演讲直播。