误差分析(Error Analysis)
假设你正在通过神经网络构建一个猫分类器,在经过训练数据集训练后,使用调整集进行调整的时候发现算法的出错率是 10%,其中有很多狗的照片被错误的分类成猫。此时,你是否应该集中精力攻克算法对于狗照片的误识别问题?更极端的,是否干脆直接用接下来的几个月去做一个狗的分类器?
得出这个问题的答案不应该仅仅依靠直觉或是他人的建议,而是应该试着分析 100 张调整数据集中被错误分类的图片,统计其中由于错误的将狗的照片分类导致的误差的概率:
如果这 100 张照片中只有 5 张来源于此,那么就说明即便你 100% 的解决了狗的照片误分类问题,也最多能够让算法的出错率从 10% 降到 9.5%,这个 0.5% 被称为改进上限(ceiling),而很明显这个结果是不能令人满意的,此时应该集中精力分析和解决其他可能的影响因素
如果这 100 张照片中有 50 张来源于此,那么就说明如果你 100% 的解决了狗的照片误判问题,可能能够让算法的出错率从 10% 降到 5%,即改进的上限是 5%,那么此时解决狗的照片误判问题有可能是一个值得努力的方向
同样地,如果你已经找到了多个可能导致调整样本集中照片被错误分类的原因,那么分析哪一个方向的改进可以提供更多可能性的时候可以仿照 Andrew 做下面这张表格:
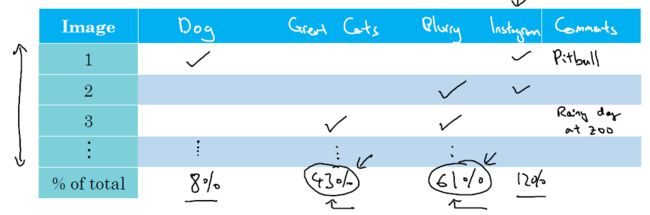
表格的行是待分析的照片,表格的列则列明可能导致错误分类的原因,最后一列可以添加一个备注列,便于更详细的描述相应行的照片的特点。在此基础上统计每一个原因出现的概率,最终找到那个可能提供更高的改进上限的因素。
处理被错误标记的数据
有时候你会在调整数据集中发现有些数据的标签其实是被错误的标记了,此时如果你的训练数据集很大,那么如果这些标签错误的原因是随机和偶发的(random errors),考虑到神经网络的稳健性和重新检查全部标签所耗费的时间,其实可以不必去校对训练数据集中的数据并重新训练。此时在调整数据集的调试过程中,可以在上述表格的基础上添加一列 Incorrect Labled 来统计有多少误分类的照片是由于错误标记造成的,然后统计出这个因素造成的错误比例,进而分析是否需要手动修改调整数据集中被误标记的数据。
如果经过一系列调整使得算法中最终由于误标记造成的错误分类所占的比例上升到一定程度,则此时才应该考虑手动修改调整集中的错误标签,同时需要注意的是:
如果对于调整集进行了修改,那么测试集也要进行修改以保证二者的分布情况相同
在修改的时候,不仅要检查算法错误判定的样本,同样也要考虑检查算法正确分类的样本的标签是否正确
考虑到训练集的数据量,这些修改不一定要在训练集中同样进行
快速搭建你的第一个系统
在神经网络系统的构思过程中,通过对问题的分析可以发现诸多需要考虑的因素和方向,但在这个阶段过多的停留会耽误很多的时间。所以 Andrew 建议大家在打造一个全新的系统时不要对于问题反复的 “overthink", 尽快建立数据集及衡量指标,并随即着手构建系统原型,在此基础上再通过偏差分析、方差分析和误差分析来确认下一步的工作方向。这会大大缩短整个项目的时间,并且分析的结果会自动指明那些可能的方向中真正值得去花时间改进的地方。
采用分布情况不同的训练集和调整集
假设需要打造一个用于移动客户端的手机应用,其功能是通过用户上传的手机图片进行猫的识别,如果手头上有 100,000 张网络下载的高清猫图和另外 10,000 张用户手机拍摄的相对低质的猫图,那么数据集该如何进行划分?
方案 A:将所有图片混合在一起,随机打乱后按照一定比例划分训练数据集,调整数据集和测试数据集
方案 B:在训练数据集全部使用网络获取的图片,或者添加部分手机获取的图片,而在调整数据集和测试数据集中全部使用手机图片
这两个方案哪一个更好?
很多人可能都会选择 A,包括我自己,而在 Andrew 看来 B 才是更加合理的选择,因为这使得系统在使用调整数据集进行调整时得到的参数更加接近其真实的工作环境,进而后期在实际应用中准确率会更高,用户也会更加满意。
但这种做法也产生了一个问题:如果测试数据集和调整数据集的分布情况相同,那么如果系统在测试数据集和调整数据集上分别的误差值为 1% 和 10%,那么此时可以放心的下结论说系统的方差值较高,即此时应该纳入更多的数据或者正则化来改进系统。而当测试数据集和调整数据集不再具有相同的分布,那么这个结论将无法确定的得出。比如对应前面的猫分类器的例子,很可能训练集上表现更好是因为采用的是高清的网络图片,而调整集中的相对较差的表现主要可以归因于较差的图片质量。
得出更确切的结论的办法就是在训练数据集中再单独分出一个小的数据集,在此称为 training-dev set。将系统用剩余的训练数据集重新进行训练并得到误差值之后,再测试系统在这个 training-dev set 和调整数据集上的误差值:
如果系统在三个数据集上的误差值分别为 1%, 9.5%, 10% ,那么此时可以判断系统具有较高的方差值,因为其在前两个数据集上具有较大差异的表现
如果系统在三个数据集上的误差值分别为 1%,1.5% ,10%,那么此时我们可以判定差别主要来源于数据的不匹配(mismatch)
当然前面这个例子的判断基于假设人类在类似问题的错误率为 0% 或接近 0%,如果人类的表现不是这个数值,那么这些数值的相对大小则需要另行判断。
再一次地,不同误差之间的相对值大小对应模型的问题如下:
人类水平表现 VS 训练集误差值间的差异衡量的是可避免偏差大小
训练集与 training-dev set 之间的误差相对大小反映系统的方差情况
而 training-dev set 与验证数据集之间的误差相对大小反映数据不匹配对于误差的贡献情况
验证数据集和测试数据集间的误差相对大小反映系统对于验证数据集是否存在过拟合情况
数据不匹配的处理
对于数据不匹配问题目前并没有系统性的解决方案,Andrew 在这里建议应该首先分析训练数据集和验证数据集的差异主要来源于哪里,在找到这些差异之后可以通过收集更多接近于验证数据集的数据,或者通过人工数据合成向测试数据集添加相应的差异因素等方式来使其更加接近于验证集。需要注意的是如果通过合成的方式进行数据修饰,那么要防止引入的修饰成分过于单一而使得算法对于这一修饰做出过拟合,即应该尽量多样化。
迁移学习(Transfer learning)
这是一个我之前一直没有花时间理解的概念,一直以为迁移学习是和深度学习、机器学习等并列的一项技术,但实际上迁移学习是指把之前在一项任务上学习得到的知识/模型稍作修改应用在另一个任务上去,也就是对于学习到的知识的迁移,所以我个人觉得更直观的翻译是学习的迁移。
例如假设我们已经有一个通过足够动物数据训练后的动物图像识别模型,如果此时需要一个医疗影像识别模型,那么可能可以通过修改最后一层的输出,并用新任务的数据来重新训练网络。由于在之前的训练中,网络已经对于如何识别物体建立了相当程度的基础,因此可以假设其对于如医学影像中的肿瘤识别等问题也具有一定的解决能力。此时动物图像识别的训练就称为基础训练或者叫预训练,在预训练的基础上采用新任务的数据进行训练的过程叫做微调(fine-tuning)。
迁移学习常见的应用场景是预训练任务的数据量远高于被迁移到的新领域的数据量,否则就没有必要做这个迁移,应该一开始就采用新任务的数据进行训练。在后面 Andrew 会讲到迁移学习中取决于新任务的数据量,一般会对预训练得到的参数全部或部分的进行冻结,即不通过微调改变这些参数,使得网络对于之前的知识得以保留。当新任务的数据量足够多的时候也可以选择将预训练的参数作为初始化的值,而不是随机初始化,在此基础上对网络进行微调。由于计算机视觉相关应用训练所需数据量通常要更大,所以训练一个网络需要很长的时间,所以这个领域的研究者更多的会采用迁移学习来加速自己的工作。
多任务学习(Multi-task learning)
与每一次只执行一个任务,例如单个物体的识别不同的是可以通过神经网络一次性执行多个任务,例如在自动驾驶中,需要自动驾驶车辆同时识别行人、其他车辆、路标、交通指示灯等等。
多任务对应的网络的输出层有多个输出值,此时的成本函数的定义为:
J = ∑∑L(ŷj(i), yj(i)) / m = ∑∑(-yj(i)logŷj(i) - (1 - yj(i))log(1 - ŷj(i))) / m,其中最外层的 ∑ 是加总所有 m 个训练样本,即 i = 1, 2, 3,..., m,而内层的 ∑ 则是加总输出特征的数量 n,j = 1, 2, 3,..., n
注意多任务与 softmax 不同的是后者会给每一个样本提供一个标签,而多任务可以对于同一个样本提供多个标签。同时,如果输入数据的标签不完整,即只标记了部分的标签值,输入的矩阵中未标记标签部分会被设置为 “?”,此时在加总计算时忽略掉这部分即可。
已经有研究证明,当神经网络足够大的时候,多任务的表现要优于将这些任务分拆为多个子任务并独立训练的结果。例如对于前面的自动驾驶的例子,由于对于各个对象的识别所需要的网络的基础架构是相通的,或者说基础能力是相同的,假设对于上述四个特征做过标记的独立数据各自有 100,000 个,那么此时采用 400,000 数据来训练一个多任务系统,其表现通常会优于分别用 100,000 输入来训练 4 个独立的网络。
所以总结起来多任务的应用前提是:
这些多个任务之间共享相当多的底层特征
对于执行各个子任务来说都有几乎相同数量的数据
神经网络要足够大
端对端的深度学习
端到端的深度学习之所以如此得名是因为相比将一项复杂的任务分成多个阶段来执行的方式,端对端学习方式通过构建一个庞大的神经网络,直接从输入(一端)构建与输出(另一端)间的关系,省去了中间的任务切割和逐个击破的步骤。听起来似乎端对端的深度学习可以直接解决所有的问题,但其实端对端的深度学习只有在具备海量的数据和使用庞大的神经网络的时候才能达到或超越分阶段执行的效果。具体到在应用中如何选择,Andrew 总结端对端深度学习的优势和缺点如下:
优点:
让数据自己说话:不人为的要求系统按照人类的思维去解释现象,而是让系统自己寻找规律
需要更少的手工设计算法的过程和时间
缺点:
- 收集海量数据和构建庞大的神经网络所需的资源、成本和技术能力限制
尽管神经网络领域里的很多研究者对于在系统中实施手工设计比较抵触,但在 Andrew 看来神经网络学习的知识来源于两个方面:
数据本身
算法设计者手工在算法中添加的促进算法学习的设计,如特定特征的引导识别,网络架构设计等
因此当数据量本身非常大的时候,当然可以尽量减少人工干预,让数据自己说话。但当你所有具备的数据量非常小的时候,系统中的人工干预部分可以使得人类将已有的知识传递给系统,并在很大程度上决定最终系统表现的优劣。
所以对于是否采用端对端的深度学习,总结一句话就是:
Do you have sufficient data to learn a function of the complexity needed to map x to y?
你是否具备足够多的数据来使得系统能够构建出具备直接从 x 映射到 y 所需的复杂度要求的函数?再翻译一下就是:如果数据数量和技术能力不达标,分阶段执行!