Kintinuous 解析
写在前面
先讲下 KinectFusion 算法的不足,KinectFusion 算法使用固定体积的网格模型表示重建的三维场景,这就造成重建的时候只能重建固定大小的场景,而且 KinectFusion 中使用的 TSDF 模型将整个待重建的空间划分成等大小的网格,当重建体积较大,或者网格的空间分辨率较高时很消耗显存。而且 KinectFusion 算法没有回环检测和回环优化,这也造成当相机移动距离大时,不可避免的会有累积误差(虽然 KinectFusion 算法使用 frame-to-model 的形式配准会减小累积误差,但是当移动距离大时,重建的三维场景也会飘起来),累积误差造成重建场景的漂移。
这篇文章的作者做了几年工作,才有了当前的 Kintinuous 算法,这个算法是个比较完备的三维重建系统,位姿估计结合了 ICP 和直接法,用 GPU 实现,位姿估计的精度鲁棒性都相对其它算法如 InfiniTAM 也较好,而且 Kintinuous 融合了回环检测和回环优化,并且史无前例的在实时三维刚体重建中用 deformation graph 做非刚体变换,根据回环优化的结果,更新点的坐标,使得回环的地方两次重建的可以对齐。
Kintinuous 适合做大场景的三维重建,这篇文章的作者的另一个工作 Elasticfusion 适合做小场景的三维重建。
阅读这篇博客前,建议先熟练掌握 KinectFusion 算法,KinectFusion 博客地址:
http://blog.csdn.net/fuxingyin/article/details/51417822
Kintinuous 是对 KinectFusion 的改进,2011 年发表的 KinectFusion 论文只能做固定小场景的三维重建,PCL 里实现的 kinfu_large_scale 可以重建大场景,但是没有做回环检测和回环优化,并且重建实际效果也不好。这篇文章介绍的 kintinuous 算法,加入了回环检测,回环优化和三维点的更正,是重建大场景比较完备的系统。
实测作者发布的代码效果虽然不如作者发的 demo 视频那么惊艳,但是效果也确实好。
在实测过程中,发现代码回环地方处理的并不理想,有些地方回环检测到了,但是两次重建的并没有对齐上,造成同一个地方重建的错开。作者发布的 demo 视频里,回环处理的比较赞,论文的第二作者也是 iSAM 的作者说把代码的基本框架开源,可能作者写的比较好的没开源的版本,能把回环处理好。
Kintinuous 代码地址:
https://github.com/mp3guy/Kintinuous
扩展体模型融合
网格模型表示
同 KinectFusion 重建也用 TSDF 模型,TSDF 模型参见 KinectFusion 博客。
TSDF 模型,每个网格中存储的值如下:
signed distance value ( S(s)τ truncated float16)
unsigned weight value unsigned ( S(s)W unsigned int8)
A byte for each color component R, G and B ( S(s)R , S(s)G , S(s)B )
每个网格占 6字节。
网格模型, x , y 和 z 三个维度每个维度用 vs=512 维网格表示,在 GPU 中存储消耗的显存为 768M。
三个维度每个维度的物理长度为 ( vd metres)表示
相机在 TSDF 坐标系下的位姿表示为 Pτi ,由旋转矩阵 Rτi 和 tτi 组成,开始时初始化为 Rτi=I , tτi=(0,0,0)τ ,
TSDF volume 在全局坐标系下坐标初始化 g0=(0,0,0)τ
Volume Shifting
重建时当相机移动的距离比较大,超过当前设定的阈值时,算法移动 volume(volume 表示 TSDF 模型立方体),让相机的光心近似在 volume 的中心。移动 volume 实际是改变 volume 中心坐标,volume 在 GPU 中的表示并没有变化。 volume 移动的示意图如下:
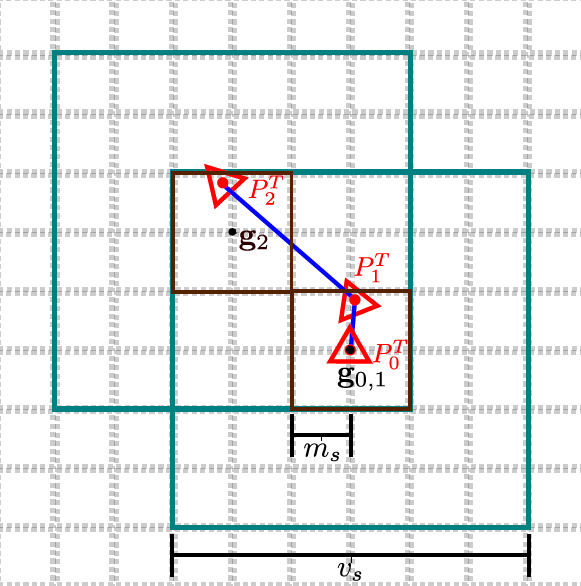
相机移动触发 volume 移动的示意图如下,相机光心第一次从 pT0 移动到 pT1 ,由于相机移动的距离小,没有触发 volume 的移动,相机第二次从 pT1 移动到 pT2 ,这时触发了 volume 移动。volume 移动时,改变 volume 中心坐标值,让 volume 的中心和相机的光心的重合。如上图 volume 移动到 g2 后,volume 在 g0,1 位置处的绿框和在 g2 处的绿框不相交部分网格的三维点会从 volume 中提取出来,并且网格的值被清空。
算法用循环利用显存的方式解决大场景重建 voxel 模型显存不足的问题。算法使用下述方式改变 volume 中心的位置。
定义 ms 为 volume shift 的阈值(以 voxels 为单位),当相机在 volume 中心 gu 移动的单元格数大于 ms 时,触发一次 shift,触发是在 x , y , z 三个维度上单独计算,相机移动的单元个数为:
u=⌊vstτi+1vd⌋
这里 u 表示的是网格的数目。
⌊⌋ 表示取下整,因为 volume 中心坐标改变了,在volume 移动时还需要同时更新相机相对于 volume 的位置信息,相机位置更新方式如下:
tτ′i+1=tτi+1−vduvs
相机相当于 volume 的坐标和 volume 相对于 global voxel 坐标变动的方式相反。volume 中心在 global voxel 位置变动如下:
gi+1=gi+u
如上图虚线表示的是 global voxel 坐标,volume 相对于虚线的坐标为 gi (voxel 为单位),相机相当于 volume 的坐标为 ti (物理值)。
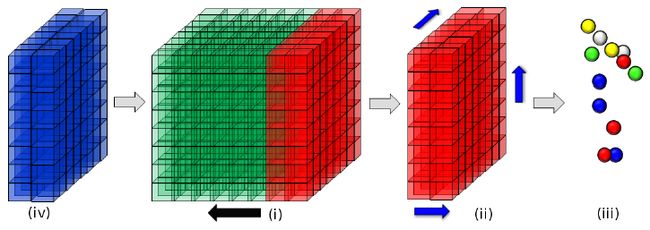
上图解释如下:
(1) 相机移动的距离超过了设定的阈值 ms
(2) 离开 volume 的红色区域在三个坐标轴方向上提取点,并且红色区域在显存中释放掉
(3) 提取的表面点用 GPT 算法计算 mesh
(4) 蓝色区域表示移出之后重复使用的空闲区域
三维的 voxel 点在显存中的索引关系为:
a=(x+yvs+zv2s)
volume 中心移动后,TSDF integration 和 raycasting 在显存中索引的方式为:
x′=(x+gix) mode vs
y′=(y+giy) mode vs
z′=(x+giz) mode vs
a′=(x′+y′vs+z′v2s)
表面点提取
volume 每次移动的适合会在 volume 中将不在相机光心附近网格处三维点从 volume 中提取出来,提取算法是在和坐标轴相同的三个方向上检测在 volume 中网格从正到负或者从负到正的穿越点,并且将这些穿越点在网格模型中提取出来,也就是重建好的场景点。

每次提取的场景点,组成一个 cloud slice ,算法通过 incremental 的方式根据提取的 cloud slice 用 GPT 算法构建 mesh,每个 cloud slice 和提取的时候相机的位姿相对应,相对应的相机的位姿是在全局坐标物理坐标系下的位姿,位姿计算公式如下:
Ri=Rτi
ti=tτi+vdgivs
变换前 Ri 和 ti 是相机相对于 volume 的位姿,这里将相机相对于volume的位姿转换为相机相对于全局物理坐标系的位姿。
Dynamic cube positioning
前面说到把相机放在 volume 的中心,但是如果把相机放到 volume 的中心,相机的视场和 volume 交叠的很少,如下图:

定义 βi 为相机相对于 volume 在 y 轴上的旋转,重新计算 TSDF 的中心相对于相机的位姿为:
rτ=(vd2⋅cos(βi+π2),0,vd2⋅sin(βi−π2))
Color estimation

和深度融合类似,网格颜色值融合也是按照加权的方式融合,不一样的地方是通过光线投影算法得到的颜色图像不会参与相机的位姿估计,而是通过前后帧的 RGBD 图像结合深度图像使用直接法估计相机位姿。
由于 RGB 相机的深度图像校准问题和 light diffraction 的影响,closed object 边缘估计的颜色值通常不准,在深度通道处这些边缘通常有 stark discontimuities,作者拒绝在深度图像处 strong boundaries 这些测量到的颜色值,边缘通过 7x7 邻域的深度图像计算得到,上图红色的部分显示的是拒绝的地方,在颜色值融合的时候,按照surface normal 和相机光心的夹角进行加权融合,目标的表面和相平面越是平行,加权的时候权值越大。
相机位姿估计
相机位姿估计结合了 ICP 算法和直接法。
ICP 算法原理讲解:
http://blog.csdn.net/fuxingyin/article/details/51505854
ICP 算法 GPU 实现讲解:
http://blog.csdn.net/fuxingyin/article/details/51425721
直接法以后再讲。
回环检测
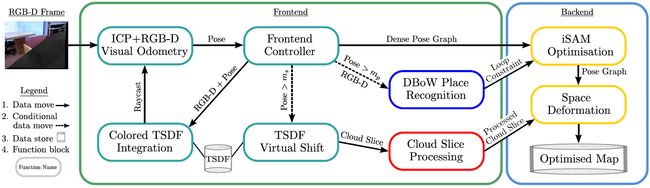
系统总的流程图如上所示,整个系统分为前端和后端,其中前端包括 相机位姿估计、场景点提取。后端包括回环检测、iSAM 算法位姿优化, deformation graph 优化和场景点更新。
作者使用 iSAM 算法优化前端位姿求解建立的位姿约束和回环检测建立的位姿约束优化相机的轨迹,然后通过优化根据优化前的轨迹和优化后的轨迹建立的约束,和回环检测时匹配的特征点建立的约束优化得到 deformation graph 控制点的参数,作者使用 deformation graph 的物理意义是用 deformation graph 这个工具,将 iSAM 优化的结果作用于相机的 Map,iSAM 让回环的地方轨迹对齐好,deformation graph 根据 iSAM 优化的结果让回环的地方重建的场景点对齐好。
Pose graph
pose graph 实际是从计算的相机位姿抽样得到的,这里的 pose graph 也是 deformation graph,Kintinuous 算法的 deformation graph 是从相机位姿的抽样点,而不是 ElasticFusion 中重建点的抽样点,这可能也解释了为什么在回环处 Elasticfusion 算法要比 Kintinuous 算法对齐的好。相机移动距离大时 volume 每次移动提取的三维点都会和 pose graph 中距离相近的点建立连接,示意图如下:

上图中 v 表示相机移动距离大时从 volume 中提取出来的三维点,紫色线表示三维点和 pose graph 也就是和 deformation graph 中四个点相连接,pose graph 中的点会和也会和相邻的点连接。点 v 实际是在 volume 移动 Pγ 处从 volume 中提取出来的,带你 v 寻找 pose graph 中连接点的算法是根据 Pγ 找到相邻 pose graph 中的点,再找 pose graph 相邻的点中找距离最相近的点,然后和距离最相近的点建立连接。
回环检测
作者用 DBoW SURF 描述子进行回环检测,DBoW 介绍:
http://blog.csdn.net/fuxingyin/article/details/51489160
当相机旋转或者移动的距离超过一定阈值的时候,将当前帧加入做关键帧并且进行回环检测,综合角度和平移移动计算公式为:
mab=||r(R−1aRb)||2+||ta−tb||2r(R):SO(3)→R3
当前帧为 [rgbi,di] ,相机移动的距离超过阈值时,首先计算关键点和对应的描述子 Ui∈Ω×R64 ,这些描述子存储在内存中,深度图像 di 在压缩后也存储在内存中。
回环检测首先通过 DBoW 寻找匹配的关键帧,如果存在匹配的图像,将在内存中存储的匹配图像的 SURF 描述子 Um 和深度图像 dm 重新索引出来。
surf 特征点匹配
给定两帧图像的 SURF 描述子 Ui 和 Um ,用 FLANN 来建立 SURF 的匹配关系,如果能够匹配上的 SURF 点数量不超过 35 个,则认为这不是一个有效的匹配,通过匹配建立 SURF 的匹配关系: G∈Ω×Ω 。
RANSAC 估计初始位姿变换
通过上一步建立的 SURF 间的匹配,用 RANSAC 算法估计两帧之间的位姿,得到位姿后再用 LM 算法优化重投影误差优化相机位姿。
ICP 算法计算精确位姿变换
用 ICP 再优化上述算法计算得到的位姿,如果匹配点之间的误差小于设定阈值,则认为这是一个有效的回环。
增量的方式建立抽取点和 deformation graph 点连接
构建 pose graph 时先按照空间关系抽样,如下所示,当节点和节点之间距离大于阈值时将当前帧加入 pose graph,加入 pose graph 的节点和节点之间建立连接,连接的方式是每一个节点和前后两个节点之间建立连接。

对于每一个触发 volume 移动的 pose graph 点都会对应一个 cloud slice,对于 cloud slice 中的 vertex 用 deformation graph 中优化好的参数做更新,更新的方式和 ElasticFusion 中相同。
每个volume 中抽取点在 pose graph 中找连接点时,首先根据抽取点对应的 pose graph 点找到相邻的点,在找到的相邻点后,再和最近的 k 个相邻点建立连接,算法如下:

具体算法如下:pose graph 中的 node 本来就是按照时间关系存储的,所以可以用二分法进行查找时间上最相近的 node,找到时间上最相近的node之后,再向后查找空间上相近的 node。
每个抽取点和 pose graph 点之间的连接是按照 incrementally online 的方式计算的,作者也说使用增量的方式建立抽取点和 pose graph 点之间的连接是 Kintinuous 算法提升效率的关键。
优化
当检测到存在回环时,优化分为两步,第一步用 iSAM 算法根据回环约束优化相机轨迹,第二步根据优化前后的轨迹和回环处特征点的对应优化 deformation graph 中控制点的参数。
轨迹优化
在前端位姿求解的时候前后帧计算位姿变换可以建立前后帧的位姿约束,回环检测可以建立回环处的位姿约束,iSAM 算法通过优化这两种约束优化相机轨迹。
deformation graph 优化
Kintinuous 优化 deformation graph 的方式和 ElasticFusion 优化 deformation graph 的方式有些类似。
ElasticFusion 算法介绍:
http://blog.csdn.net/fuxingyin/article/details/51433793
Kintinuous 优化 deformation graph 和 Elasticfusion 优化 deformation graph 的约束项不一样,Elasticfusion 在回环的地方抽样深度图像点建立约束,Kintinuous 通过优化前后的轨迹和回环处匹配的 surf 点建立约束。
优化目标函数具体如下:
同 Elasticfusion 中的约束项,第一项保持 R 的单位正交性,第二项保持 deformation graph 参数的连续性。
不同的是,第三项用 iSAM 优化前后的轨迹和回环处匹配的特征点作为约束,表达形式如下:
Econp=∑i||ϕ(ti)−t′i||22
上式中, ti 是 iSAM 优化前相机的位置坐标, t′i 是 iSAM 优化后相机的位置坐标, ϕ(ti) 是根据 deformation graph 参数 deform 后相机的位置坐标,这里待优化的参数是 deformation graph 中每个点处的仿射变换,这部分在 Elasticfusion 博客有讲。
作者说只使用上述约束 at some points the surface orientation may not be well optimized,为了克服它又加了优化前后投影出来的 SURF 三维点坐标的约束。
Esurf=∑q||ϕ((RiGq)+ti)−((R′iGq)+t′i)||22
Ri 和 R′i 是优化前后的旋转矩阵, ti 和 t′i 是优化前后的平移向量。
参考文献:
“Real-time large scale dense RGB-D SLAM with volumetric fusion”