malloclab 实验详解(动态分配器如何设计)
本文主要针对CSAPP中的动态内存分配器做一个讲解,在讲解书上的各种分配器如何设计的同时,用实验的实际代码来实现这些算法。
首先,先贴上书本配套实验的地址:http://csapp.cs.cmu.edu/public/labs.html
备注:这个实验地址并没有给出实际的traces里面的测试,
相关的测试以及最终的答案可以从我的github上下载:https://github.com/HBKO/malloclab
首先,要理解动态分配器是个什么东西?简单来说,动态分配器就是我们平时在C语言上用的malloc和free,realloc,通过分配堆上的内存给程序,我们通过向堆申请一块连续的内存,然后将堆中连续的内存按malloc所需要的块来分配,不够了,就继续向堆申请新的内存,也就是扩展堆,这里设定,堆顶指针想上伸展(堆的大小变大),不能向下增长(虽然,sbrk函数也可以让指针想下伸展),以下是堆的一些说明:
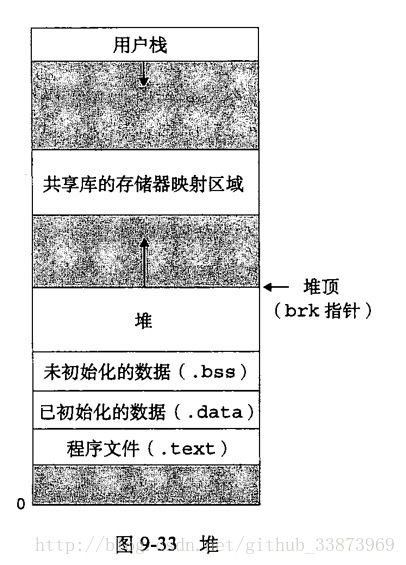
那么,对于如何管理这个堆,主要有这么几步操作:
一.find_fit:找到一个合适的块,分配出去,这里寻找块的方法也有以下几种(这里指申请需要的空间为needsize):
(1).首次适配:就是在搜索整个堆或者空闲链表的时候,只要找到一个比needsize就直接申请出去。(优点:速度快。缺点:不一定找到空间最合适的块,空间利用率降低(但是利用分离适配的方法可以让首次适配的空间利用率也提升))
(2).最佳适配:在搜索的时候,找到一个
needsize<=size && min(size-needsize)的块。(优点:能找到最合适的块,空间利用率高。缺点:对于大的空闲块搜索效率低(因为经常都是把小的空闲块安插在链表前))
(3).下一次适配:下一次适配和首次适配很类似,首次适配是从空闲链表头开始寻找,下一次适配是从上一次分配的地方开始搜索。但有些研究表明,下一次适配比首次适配的效率更快,但空间利用率更低。所以我们的实验中一般采用首次适配和最佳适配。
二.分割块(放置块):在申请一个块的时候,如果这个块的大小远大于我们的需求,我们就要分割块(这个分割块的界线在于最小块的大小是多少),分割出来的块标为空闲的,放入空闲链表中(但是在针对realloc优化的时候发现,很多时候在realloc不分割的时候空间利用率更好,可能是针对特定的case才有这种情况)。
三.合并块:我们想要降低空间利用率,就要降低假碎片的出现,这里就要介绍一下什么是内存分配产生的碎片了。
(1)内部碎片:内部碎片的产生是在一个已分配块比有效载荷大的时候,就如同如下结构:
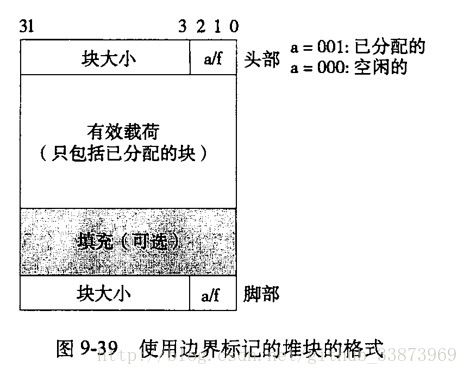
一个空闲块必须得要有空间存放头部和脚部,这里头部和脚部就是内部碎片,减少内部碎片的办法就要减少这样每个堆块必须分配的内存。
(2)外部碎片:外部碎片就是当空闲存储器合计起来足够满足一个malloc请求,但是却无法申请的时候。如下图所示:
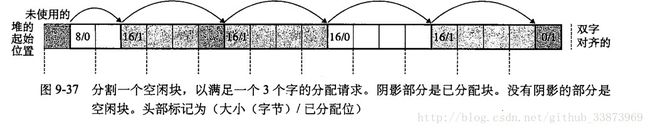
在图片这个情况,如果我申请的块大小为20,那么就没法申请,即使现在空闲块的总和是8+16=24,但还是伸展堆的大小,伸展出新的块出来。所以,外部碎片也可以说是最棘手的一种碎片,因为无法预估后来申请块是大还是小块,如果一大一小的申请。并且,只释放小块,这样就很容易产生外部碎片。
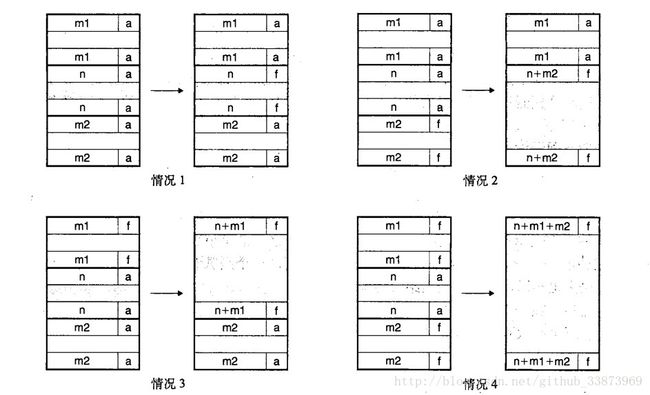
为了降少这些外部碎片,我们就需要进行空闲块的合并。但是,如果我们采用单向链表的形式,在每次合并的时候,就要遍历整个链表进行合并。当然啦,我们采用延迟合并的策略,即得到我们每次malloc需要新的空间的时候再进行合并,在需要的时候再进行合并。从根本上减少合并的次数来节约时间。但是,这里Knuth提出了一种标记块的方法(我认为是相当巧妙的一种方法),利用头部和脚部来存储块的大小以及是否被申请的信息,头部和尾部的信息都一样,就如图9-39的结果,可以就可通过一个块,访问前一个块和后一个块,使得合并达到常数时间,具体获取前后块的代码如下图所示:
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char *)(bp)+ GET_SIZE(HDRP(bp))-DSIZE)
#define NEXT_BLKP(bp) ((char *)(bp)+GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))合并的四种情况无非就是:1.前后都忙碌。2.前忙碌,后空闲。3.前空闲,后忙碌。4.前后都空闲,如下图所示:
好了,我们要对这个内存分配器所做的操作都说完了,就是说我们的基本零件有了。
但是,我们如果想衡量一下我们所做的这个内存分配器需要那些指标呢?
1. 空间利用率:
举例来说,如果我的前k个请求连续使用十个malloc(100),那么我的前k个请求总申请的空间就是10*100=1000(当然我如果free过,空间就减,取最大值),这时我们的堆的大小如果是1000,那么空间利用率就是100%(当然这种情况基本不可能出现),这时我们的堆的大小如果是2000,那么空间利用率就是50%。那么显然可知,空间利用率就取决于碎片多不多,如果内部和外部碎片越少,我们的空间利用率就越高。
2. 效率:
这个很好理解,就是我们执行这些操作的时间复杂度,我们的目标就是让上面提到的每一步操作都能达到常数时间。
但其实很多时候,空间利用率和效率是相互矛盾的,我们只能通过我们的设计取到最优解。
接下来就是我们的设计部分啦。
一. 隐式空闲链表+首次适配+普通的realloc
这部分的代码CSAPP的书上都提供了,我就不赘述,要注意的是,我们下面所有的优化设计都基于这个最基本的设计。所以,你只有将这个最简单的设计理解下了,才能继续下去。这个方法的缺点很明显:find_fit是整个堆的常数时间,这是相当慢的。但是好处就是,这个算法的空间利用率挺理想的。
二.显式空闲链表+首次适配 OR 按地址进行放置空闲链表
针对于显式空闲链表,一个空闲块中就多了前继和后继结点,构成双向链表,如下图所示:
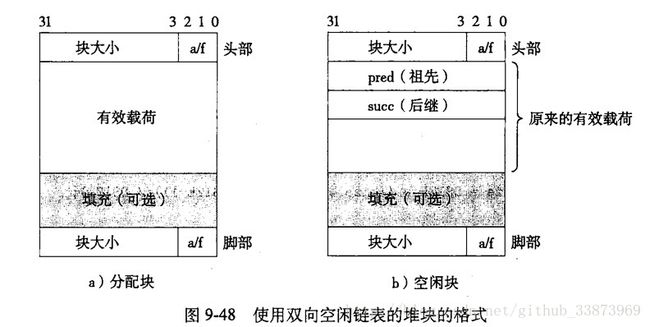
那么这个时候,咱们的堆变成了什么样了呢?
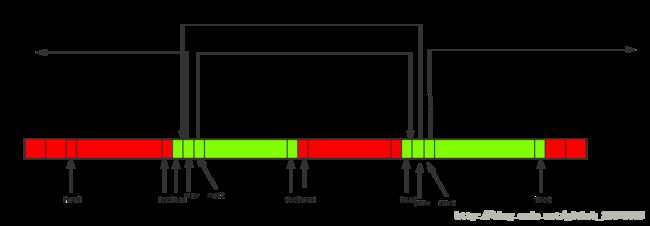
图画的有点丑。。。别介意,利用双向链表将所有空闲链表串连起来,这样就可以使搜索的速度降低到空闲块的线形时间了。
那么,每次free块的时候,将块插入到链表里面,可以直接采取两种策略:
1.直接暴力插入到链表头,每次刚释放出来的块都放在链表头,这样尽可能使得释放的时候维持在常数时间,但这样做的空间利用率降低。
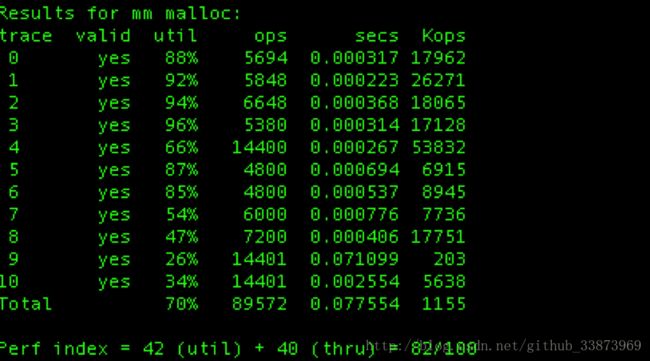
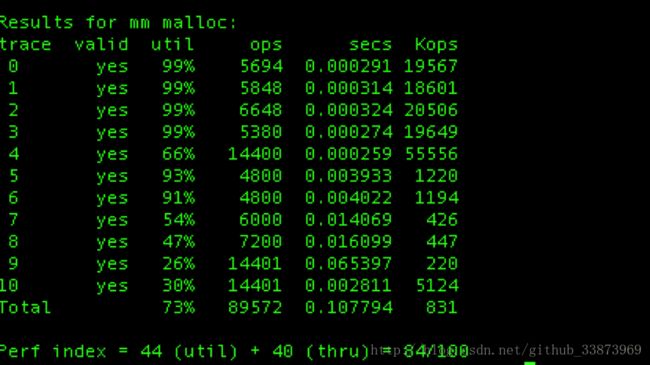
2. 在释放块的时候,按照地址的大小顺序排列所有的block,这样牺牲一点释放时间,提升了空间利用率。两种方法的利用率和效率的最终得分如下图所示:
图一:空闲链表+直接插入头部
图二:空闲链表+按地址排序
这里讲一些最简单的realloc实现,malloc一块新空间,将旧空间的数据拷贝过去,将原来的块free掉。
这里的代码的地址在这https://github.com/HBKO/malloclab/blob/master/mymallocVersion2.zip
但似乎这种显式结构,搜索时间还是所有的空闲块,搜索时间还是太长,还能不能使得搜索时间再短一点了。
3.分离适配+改进的realloc:
分离适配的基本思想就是将所有空闲块分成大小类,分别分成0~8,9~16,17~32,33~64,65~128…… 2049~4096,4097~正无穷,这么几个大小类的空闲链表,然后我们想要进行malloc的时候,就将空闲块进行筛选,将其分到对应的大小块中进行搜索,这样就可以将malloc搜索块的时间从所有空的空闲块降低到局部链表的空闲块中,提高了效率。并且事实证明,当分到对应的大小类链表的时候,它的空间也会在大小类链表的范围里面,这样使得即使是首次适配也可以是空间利用率接近最佳适配。那么,他的free也是相同,在合并的时候,将前后空闲块从链表中删除,然后合并,合并后再加入对应的空闲链表,分割的时候,也是分割后将分割块插入适当的空闲链表中。
我们的最终答案也是采用这种设计。
改进的realloc,就是要重新分配的块的内存大于本身块的大小,先寻找一下前后能不能合并,能合并并且空间大小符合,就直接合并后放置。但这里的realloc本来要进行分割。但是,在分割后得到的空间利用率并不好,可能是特定case原因,所以我就没进行分割,要注意的是对自己的extend_heap的格式进行修改,不能申请4096个空间,否则第4个case的空间利用率会很差
完整代码在这里:https://github.com/HBKO/malloclab
下面是我的mm.c和mm.h的内容:
#include /*
* mm-naive.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include NULL;
PUT(head_listp,0); /* Alignment padding */
PUT(head_listp+(1*WSIZE),PACK(DSIZE,1)); /* Prologue header */
PUT(head_listp+(2*WSIZE),PACK(DSIZE,1)); /* Prologue footer */
PUT(head_listp+(3*WSIZE),PACK(0,1)); /* Epilogue header */
head_listp+=(2*WSIZE);
#ifdef DEBUG
// printf("the size of head_listp :%x\n",GET_SIZE(HDRP(head_listp)));
// printf("the alloc of head_listp: %x\n",GET_ALLOC(FTRP(head_listp)));
#endif
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if(extend_heap(CHUNKSIZE/WSIZE)==NULL)
{
return -1;
}
#ifdef DEBUG
printf("the size of freelist_head=%d\n",GET_SIZE(HDRP(freelist_head)));
#endif
return 0;
}
//扩展堆的大小
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size=(words %2)? (words+1)*WSIZE: words*WSIZE;
if((long)(bp=mem_sbrk(size))==-1)
return NULL;
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp),PACK(size,0)); /* Free block header */
PUT(FTRP(bp),PACK(size,0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); /* New epilogue header */
// placefree(bp);
#ifdef DEBUG
// printf("the freelist_head size is :%d\n",GET_SIZE(HDRP(freelist_head)));
// if(GET_ADDRESS(PRED(freelist_head))==NULL && GET_ADDRESS(SUCC(freelist_head))==NULL)
// printf("the double link of freelist_head is NULL");
#endif
/* Coalesce if the previous block was free */
return coalesce(bp);
}
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
void *mm_malloc(size_t size)
{
#ifdef DEBUG
// printf("the size of alloc=%zu\n",size);
#endif
size_t asize; /* Adjusted block size */
size_t extendsize; /* Amount to extend heap if no fit */
char *bp;
/* Ignore spurious requests */
if(size==0)
{
return NULL;
}
/* Adjust block size to include overhead and alignment reqs. */
//要加上头尾两个指针
if(size<=DSIZE)
asize=2*DSIZE;
else
asize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE);
/* Search the free list for a fit */
if((bp=find_fit(asize))!=NULL)
{
place(bp,asize);
// printf("the payload of bp is:%u\n",GET_PAYLOAD(bp));
return bp;
}
/* No fit found. Get more memory and place the block */
// extendsize=MAX(asize,CHUNKSIZE);
extendsize=asize;
if(extendsize<=DSIZE)
extendsize=2*DSIZE;
else
extendsize=DSIZE*((extendsize+(DSIZE)+(DSIZE-1))/DSIZE);
//不够申请
if((bp=extend_heap(extendsize/WSIZE))==NULL)
{
return NULL;
}
place(bp,asize);
return bp;
}
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *ptr)
{
#ifdef DEBUG
printf("the point of free=%x\n",(unsigned int)ptr);
#endif
size_t size=GET_SIZE(HDRP(ptr));
//头尾归为free的block
PUT(HDRP(ptr),PACK(size,0));
PUT(FTRP(ptr),PACK(size,0));
coalesce(ptr);
}
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
void *mm_realloc(void *ptr, size_t size)
{
if(ptr==NULL) return mm_malloc(size);
if(size==0)
{
mm_free(ptr);
return ptr;
}
size_t asize=0;
//计算要分配这么size内存所需要的总体size
if(size<=DSIZE)
asize=2*DSIZE;
else
asize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE);
if(ptr!=NULL)
{
size_t oldsize=GET_PAYLOAD(ptr);
if(oldsizevoid* newptr=recoalesce(ptr,asize);
if(newptr==NULL)
{
newptr=mm_malloc(asize);
memcpy(newptr,ptr,oldsize);
mm_free(ptr);
return newptr;
}
else
{
return newptr;
}
}
else if(oldsize==size)
{
return ptr;
}
//申请的块比原来的块小
else
{
// place(ptr,asize);
return ptr;
}
/*
memcpy(newptr,ptr,finalsize);
mm_free(ptr);
return newptr;
*/
}
return NULL;
}
//找不到合适的块直接返回NULL,其它情况返回已经memcpy过的块的头指针
static void *recoalesce(void *bp,size_t needsize)
{
size_t prev_alloc=GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc=GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size=GET_SIZE(HDRP(bp));
//情况一,前后都没有空闲块
if(prev_alloc && next_alloc)
{
return NULL;
}
//情况二,后一块是空闲的
else if(prev_alloc && !next_alloc)
{
size+=GET_SIZE(HDRP(NEXT_BLKP(bp)));
//即使加上去内存也不够
if(sizereturn NULL;
else
{
deletefree(NEXT_BLKP(bp));
//合并
PUT(HDRP(bp),PACK(size,1));
PUT(FTRP(bp),PACK(size,1));
// place(bp,needsize);
return bp;
}
}
//情况三,前一块是空闲的
else if(!prev_alloc && next_alloc)
{
size+=GET_SIZE(HDRP(PREV_BLKP(bp)));
if(sizereturn NULL;
else
{
size_t thissize=GET_PAYLOAD(bp);
void* prev_point=PREV_BLKP(bp);
deletefree(prev_point);
//合并
PUT(FTRP(bp),PACK(size,1));
PUT(HDRP(prev_point),PACK(size,1));
//拷贝
memcpy(prev_point,bp,thissize);
// place(prev_point,needsize);
return prev_point;
}
}
//情况四,前后都是空闲的
else
{
size+=(GET_SIZE(HDRP(NEXT_BLKP(bp)))+GET_SIZE(FTRP(PREV_BLKP(bp))));
if(sizereturn NULL;
else
{
size_t thissize=GET_PAYLOAD(bp);
void* prev_point=PREV_BLKP(bp);
deletefree(prev_point);
deletefree(NEXT_BLKP(bp));
PUT(FTRP(NEXT_BLKP(bp)),PACK(size,1));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,1));
memcpy(prev_point,bp,thissize);
// place(prev_point,needsize);
return prev_point;
}
}
}
static void *coalesce(void *bp)
{
//关于这一块的改free操作已经在free函数的过程中执行了
size_t prev_alloc=GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc=GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size=GET_SIZE(HDRP(bp));
//情况一,前一块和后一块都被申请了
if(prev_alloc && next_alloc)
{
placefree(bp);
return bp;
}
//情况二,后一块是空闲的
else if(prev_alloc && !next_alloc)
{
deletefree(NEXT_BLKP(bp));
size+=GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp),PACK(size,0));
//改完头部大小就变了,只能直接访问尾部,对尾部进行改大小的操作
PUT(FTRP(bp),PACK(size,0));
placefree(bp);
return bp;
}
//情况三,前一块是空闲的
else if(!prev_alloc && next_alloc)
{
deletefree(PREV_BLKP(bp));
size+=GET_SIZE(FTRP(PREV_BLKP(bp)));
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
placefree(PREV_BLKP(bp));
return PREV_BLKP(bp);
}
//情况四,前后都是空的
else
{
deletefree(PREV_BLKP(bp));
deletefree(NEXT_BLKP(bp));
size+=(GET_SIZE(HDRP(NEXT_BLKP(bp)))+GET_SIZE(FTRP(PREV_BLKP(bp))));
PUT(FTRP(NEXT_BLKP(bp)),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
placefree(PREV_BLKP(bp));
return PREV_BLKP(bp);
}
}
//寻找合适的块
static void *find_fit(size_t size)
{
/* Version1: First fit search */
/* Version2: Best fit search */
// maxfreesize=0;
for(int index=findlink(size);indexvoid* bp=linkhead[index];
while(bp!=NULL)
{
// maxfreesize=GET_SIZE(HDRP(bp));
if(GET_SIZE(HDRP(bp))>=size) return bp;
bp=GET_ADDRESS(SUCC(bp));
}
}
return NULL;
}
static void place(void* bp,size_t asize)
{
size_t left=GET_SIZE(HDRP(bp))-asize;
int alloc=GET_ALLOC(HDRP(bp));
if(alloc==0)
deletefree(bp);
//大于双字要把头尾都考虑进行说明,可以进行分割,由于输入的asize肯定是双字结构,这样就保证了分割出来的内容也都是双字结构
//前继和后继结点都要考虑进行
if(left>=(DSIZE*2))
{
//申请的块为忙碌
PUT(HDRP(bp),PACK(asize,1));
PUT(FTRP(bp),PACK(asize,1));
//分割出来的块为空闲
PUT(HDRP(NEXT_BLKP(bp)),PACK(left,0));
PUT(FTRP(NEXT_BLKP(bp)),PACK(left,0));
//把该结点从空闲链表中删除,并把下一个结点加入空闲链表,产生了一个空闲链表,所以执行一次合并操作
coalesce(NEXT_BLKP(bp));
// placefree(NEXT_BLKP(bp));
}
//无法进行分割
else
{
size_t allsize=GET_SIZE(HDRP(bp));
//全部设定为忙碌
PUT(HDRP(bp),PACK(allsize,1));
PUT(FTRP(bp),PACK(allsize,1));
}
}
//1.使用直接添加到链表头,减少时间消耗,但是空间利用率被牺牲
//2.利用地址顺序来处理
static void placefree(void* bp)
{
//按顺序放置
int index=findlink(GET_SIZE(HDRP(bp)));
void* head=linkhead[index];
if(head==NULL)
{
linkhead[index]=bp;
//指向的是它的地址,地址里面存的都是是上一个或者下一个块的地址,所以每解一次引用得到的都是对应的下一个块的地址
GET_ADDRESS(PRED(bp))=NULL;
GET_ADDRESS(SUCC(bp))=NULL;
}
else
{
size_t bpsize=GET_SIZE(HDRP(bp));
void* temp=NULL;
while(head!=NULL)
{
temp=head;
if(GET_SIZE(HDRP(head))>=bpsize) break;
head=GET_ADDRESS(SUCC(head));
}
if(head==NULL)
{
//插入尾部
GET_ADDRESS(SUCC(temp))=bp;
GET_ADDRESS(PRED(bp))=temp;
GET_ADDRESS(SUCC(bp))=NULL;
}
//插入前面
else
{
if(head==linkhead[index])
{
GET_ADDRESS(PRED(head))=bp;
GET_ADDRESS(SUCC(bp))=head;
GET_ADDRESS(PRED(bp))=NULL;
linkhead[index]=bp;
}
//插入中间
else
{
GET_ADDRESS(SUCC(GET_ADDRESS(PRED(head))))=bp;
GET_ADDRESS(PRED(bp))=GET_ADDRESS(PRED(head));
GET_ADDRESS(SUCC(bp))=head;
GET_ADDRESS(PRED(head))=bp;
}
}
}
}
static void deletefree(void* bp)
{
int index=findlink(GET_SIZE(HDRP(bp)));
if(linkhead[index]==NULL)
printf("freelist is empty. Something must be wrong!!!!!");
//链表中只有一个空闲块的时候
if(GET_ADDRESS(PRED(bp))==NULL && GET_ADDRESS(SUCC(bp))==NULL)
{
linkhead[index]=NULL;
}
else if(GET_ADDRESS(PRED(bp))==NULL && GET_ADDRESS(SUCC(bp))!=NULL) //链表头,并且不只有一个结点
{
GET_ADDRESS(PRED(GET_ADDRESS(SUCC(bp))))=NULL;
linkhead[index]=GET_ADDRESS(SUCC(bp));
GET_ADDRESS(SUCC(bp))=NULL;
}
else if(GET_ADDRESS(PRED(bp))!=NULL && GET_ADDRESS(SUCC(bp))==NULL) //链表尾,并且不只有一个结点
{
GET_ADDRESS(SUCC(GET_ADDRESS(PRED(bp))))=NULL;
GET_ADDRESS(PRED(bp))=NULL;
}
else //中间结点
{
GET_ADDRESS(SUCC(GET_ADDRESS(PRED(bp))))=GET_ADDRESS(SUCC(bp));
GET_ADDRESS(PRED(GET_ADDRESS(SUCC(bp))))=GET_ADDRESS(PRED(bp));
GET_ADDRESS(PRED(bp))=GET_ADDRESS(SUCC(bp))=NULL;
}
}
//寻找对应的下标
static int findlink(size_t size)
{
if(size<=8)
return 0;
else if(size<=16)
return 1;
else if(size<=32)
return 2;
else if(size<=64)
return 3;
else if(size<=128)
return 4;
else if(size<=256)
return 5;
else if(size<=512)
return 6;
else if(size<=2048)
return 7;
else if(size<=4096)
return 8;
else
return 9;
}
int mm_checkheap(void)
{
// char* start=head_listp;
// char* next;
// char* hi=mem_heap_hi();
return 1;
}
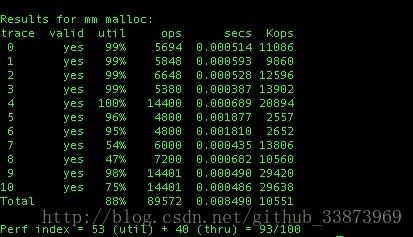
最终的优化得分是93分,有两个case会产生大量的无法合并的外部碎片,我没想到合适的优化方法:
参考资料:CSAPP
http://blog.csdn.net/u012336567/article/details/52004250