【阅读笔记】Interpreting the Latent Space of GANs for Semantic Face Editing
论文名称:Interpreting the Latent Space of GANs for Semantic Face Editing
论文作者:Yujun Shen, Jinjin Gu, Xiaoou Tang, Bolei Zhou
发行时间:Submitted on 15 Dec 2019, last revised 31 Mar 2020
论文地址:https://arxiv.org/abs/1907.10786
代码开源:https://github.com/genforce/interfacegan
- 一. 概要
- 二. 模型框架
- 2.1. 潜在空间的语义信息
- 2.1.1. 单个语义
- 2.1.2. 多个语义
- 2.2. 操作潜在空间
- 2.2.1. 仅操作单个语义
- 2.2.2. 条件性操作
- 2.2.3. 操作真实图像
- 2.1. 潜在空间的语义信息
- 三. 实验
- 3.1.潜在空间的可分性
- 3.2. 潜在空间的可操控性
- 3.2.1. 操控单一属性
- 3.2.2. 语义子空间的距离效应
- 3.2.3. 伪影修正
- 3.3. 条件操作
- 3.3.1. 各属性之间相关性
- 3.3.2. 条件操作
- 3.4. StyleGAN结果
- 3.5. 真实图像操控
- 四. 实现细节
一. 概要
本文提出了一个新颖的框架 InterFaceGAN ,即通过对 GAN 学习到的潜在语义信息进行解释来实现对人脸的语义信息编辑。本文研究了不同的语义如何编码到用于人脸合成的 GANs 潜在空间中,探究了各种语义之间的解耦及利用子空间投影来对已经耦合的一些语义进行解耦,实现了对面部属性更加精准的操控来实现人脸编辑。本文的人脸编辑不但可以操控性别、年龄、表情、眼镜外,还可以对原图的面部姿势进行修改,甚至能修复 GAN 模型中意外产生的伪影。将文中提出的方法同 GAN 反编码算法或引入编码器模型相结合,可对真实图像进行可控且解耦的属性表征。
InterFaceGAN 全称是:Interpreting Face GANs , 用来识别训练良好的脸部合成模型在潜在空间的语义,并利用其来进行语义人脸编辑。本文的主要贡献如下:
- 使用
InterFaceGAN来探究如何在GAN的潜在空间中对单个或多个语义进行编码。 - 证明了
InterFaceGAN可使用任何预训练好的固定GAN来进行脸部语义编辑。(效果图如下图所示) - 利用 对真实图像也进行了语义编辑。
二. 模型框架
- 分析了
latent code的语义属性。 - 构造使用
latent code语义编辑面部的操作过程。
2.1. 潜在空间的语义信息
对于任一训练完毕的 GAN 模型,其生成器的函数表示为 g : Z → X g:~\mathcal{Z} \to \mathcal{X} g: Z→X ,其中 Z ⊆ R d \mathcal{Z} \subseteq \mathbb{R}^d Z⊆Rd 代表 d d d 维的潜在空间,该空间遵循多元正态分布 N ( 0 , I d ) \mathcal{N}(0,{\rm I}_d) N(0,Id);而 X \mathcal{X} X 表示图像空间,其中的每个样本 x x x 都具有一定的语义信息。定义一语义得分函数 f s : X → S f_s:~\mathcal{X}\to \mathcal{S} fs: X→S ,其中 S ⊆ R m \mathcal{S} \subseteq \mathbb{R}^m S⊆Rm 代表 m m m 维的语义空间。于是便从潜在空间 Z \mathcal{Z} Z 变换到了语义空间 S \mathcal{S} S :
s = f S ( g ( z ) ) s=f_{\mathcal{S}}(g(z)) s=fS(g(z))
其中, s s s 表示语义分数, z z z 表示采样得到的潜在代码。
属性 1: 给定 n ∈ R d n \in \mathbb{R}^d n∈Rd 且 n ≠ 0 n \neq 0 n=0,使用集合 { z ∈ R d : n T z = 0 } \left \{ z \in \mathbb{R}^d:~n^Tz=0 \right \} {z∈Rd: nTz=0} 定义了在 R d \mathbb{R}^d Rd 的一个超平面,其中 n n n 称为法向量。这里所有的向量 z ∈ R d z \in \mathbb{R}^d z∈Rd 都满足在超平面的同一侧内 n T z > 0 n^Tz > 0 nTz>0 必成立。
属性 2: 给定 n ∈ R d n \in \mathbb{R}^d n∈Rd 且 n T n = 1 n^Tn=1 nTn=1,其定义了一个超平面。一个遵循多元正态分布的随机变量 z ∼ N ( 0 , I d ) z \sim \mathcal{N}(0,{\rm I}_d) z∼N(0,Id)。对于任何满足 α ≥ 1 \alpha \geq 1 α≥1 和 d ≥ 4 d\geq 4 d≥4,有 P ( ∣ n T z ∣ ≤ 2 α d d − 2 ) ≥ ( 1 − 3 e − c d ) ( 1 − 2 α e − α 2 / 2 ) P(|n^Tz| \leq 2\alpha\sqrt{\frac{d}{d-2}}) \geq(1-3e^{-cd})(1-\frac{2}{\alpha}e^{-\alpha^2/2}) P(∣nTz∣≤2αd−2d)≥(1−3e−cd)(1−α2e−α2/2) 。其中, P ( ⋅ ) P(\cdot) P(⋅) 表示概念, c c c 是一个固定的正常数。
具体证明可见原论文,在此不做过多阐述。
2.1.1. 单个语义
诸多实验证明对两个潜码 z 1 z_1 z1 和 z 2 z_2 z2 进行线性变换(如: z = λ z 1 + ( 1 − λ ) z 2 z=\lambda z_1 + (1-\lambda)z_2 z=λz1+(1−λ)z2)时,相应产生的合成结果是连续变化的。它隐含地意味着图像中包含的语义也在逐渐变化。根据 属性 1, 对两个潜码 z 1 z_1 z1 和 z 2 z_2 z2 进行线性变换会在 Z \mathcal{Z} Z 上形成一个方向,这进一步定义了超平面。
文中作出了一个设想,**对于任何的二元语义,其在潜在空间汇总都存在一个边界。但潜码在边界的一侧内移动(不穿过边界)时,其语义保持不变;而一旦潜码的变换越过边界进行移动时,语义就会变得相反。**移动情况如下图所示:
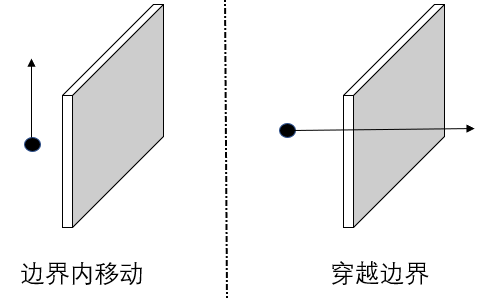
给定一带有单位法向量 n ∈ R d n \in \mathbb{R}^d n∈Rd 的超平面,定义样本 z z z 到超平面的距离为
d ( n , z ) = n T z d(n,z)=n^Tz d(n,z)=nTz
此处的 d ( ⋅ , ⋅ ) d(\cdot,\cdot) d(⋅,⋅) 并非严格定义的距离,它可以是负数表示语义被反转。当 z z z 位于边界附近且在超平面上移动时,距离和语义得分都会对应发生改变。一旦距离变成了负数,就表示语义属性发生了逆转。我们期望距离和语义信息是呈现线性相关的:
f ( g ( z ) ) = λ d ( n , z ) f(g(z))=\lambda d(n,z) f(g(z))=λd(n,z)
其中 f ( ⋅ ) f(\cdot) f(⋅) 是参与的语义的得分, λ > 0 \lambda > 0 λ>0 是用来用来测量语义随距离变化的快慢的标量。根据 属性 2,从 N ( 0 , I d ) \mathcal{N}(0,{\rm I}_d) N(0,Id) 中随机采样的样本很大概率会定位到离给定超平面足够近的位置。因此,对应的语义可以用 n n n 所定义的线性子空间来建模。
2.1.2. 多个语义
假设有 m m m 个不同语义,则有
s ≡ f S ( g ( z ) ) = Λ N T z s\equiv f_{\mathcal{S}}(g(z))= \Lambda N^Tz s≡fS(g(z))=ΛNTz
其中, s = [ s 1 , ⋯ , s m ] T s=[s_1,\cdots,s_m]^T s=[s1,⋯,sm]T 表示语义得分, Λ = d i a g ( λ 1 , ⋯ , λ m ) \Lambda = {\rm diag}(\lambda_1,\cdots,\lambda_m) Λ=diag(λ1,⋯,λm) 是一个包含线性系数的对角矩阵, N = [ n 1 , ⋯ , n m ] N=[n_1,\cdots,n_m] N=[n1,⋯,nm] 表示分离边界。 z z z 是从 N ( 0 , I d ) \mathcal{N}(0,{\rm I}_d) N(0,Id) 中随机采样的样本,那么 s s s 的均值和协方差矩阵的计算为:
μ s = E ( Λ N T z ) = Λ N T E ( z ) = 0 ∑ s = E ( Λ N T z z T N Λ T ) = Λ N T E ( z z T ) N Λ T = Λ N T N Λ \mu_s=\mathbb{E}(\Lambda N^T z)=\Lambda N^T \mathbb{E}(z)=0 \\ \sum_s=\mathbb{E}(\Lambda N^T z z^T N \Lambda^T)= \Lambda N^T \mathbb{E}(zz^T)N \Lambda^T=\Lambda N^TN\Lambda μs=E(ΛNTz)=ΛNTE(z)=0s∑=E(ΛNTzzTNΛT)=ΛNTE(zzT)NΛT=ΛNTNΛ
因此,得到遵循多元正态分布的 s ∼ N ( 0 , ∑ s ) s\sim \mathcal{N}(0,\sum_s) s∼N(0,∑s)。要想在 s s s 中各个不同的项之间都是项目解耦的,必须满足 ∑ s \sum_s ∑s 为对角矩阵,即在 N = [ n 1 , ⋯ , n m ] N=[n_1,\cdots,n_m] N=[n1,⋯,nm] 中的两两之间彼此正交。一旦不能满足这一条件,则在 s s s 中一定会存在一些会产生纠缠的语义。因此,我们可用 n i T n j n_i^Tn_j niTnj 来衡量第 i i i 个语义和第 j j j 个语义之间的纠缠度。
2.2. 操作潜在空间
2.2.1. 仅操作单个语义
根据单个语义中语义得分和距离存在的线性关系,可编辑原始的潜在编码 z z z : z e d i t = z + α n z_{edit}=z+\alpha n zedit=z+αn。 即当 α > 0 \alpha>0 α>0 时,其编辑的语义会使得合成的图像看起来更加积极,因为语义得分变成了 f ( g ( z e d i t ) ) = f ( g ( z ) ) + λ α f(g(z_{edit}))=f(g(z))+\lambda\alpha f(g(zedit))=f(g(z))+λα。同理,当 α < 0 \alpha<0 α<0 时,其合成的会看起来更加消极。
2.2.2. 条件性操作

存在多个属性时,可能会有一些耦合的语义,一旦修改其中一个会产生连锁反应影响其他语义,会影响精准编辑面部。为了避免之,文中提出手动将 N T N N^TN NTN 强制为对角矩阵。实现该条件的方法是利用投影来使得不同的向量正交化。如上图所示,我们给定两个超平面和对应的法向量 n 1 n_1 n1 和 n 2 n_2 n2,我们找到了一个新的投影方向 n 1 − ( n 1 T n 2 ) n 2 n_1-(n_1^Tn_2)n_2 n1−(n1Tn2)n2,只要沿着这个方向移动的样本就可以仅对 “属性 1” 进行编辑而不影响 “属性 2”。因为从图中可看出新方向正交于 n 2 n_2 n2 ,移动往该方向不会影响到 n 2 n_2 n2。我们把这个操作就叫做条件性操作。若有一个以上的属性需要被限制,我们只需让原始方向减去所有限定方向所构成的平面上的投影。
2.2.3. 操作真实图像
首先使用对潜在编码进行梯度回传或额外引入一个编码器来将真实图像映射成潜在编码,然后再对其潜在编码 z z z 进行操控以实现编辑真实图像的目的。
三. 实验
在本章中,作者分别对以下三个方面进行了实验:
- 3.1,3.2,3.3 从
PGGAN出发,对传统生成器中的潜在空间进行了解释 - 3.4 从
StyleGAN出发,对基于style的生成器中的潜在空间进行了解释 - 3.5 从真实图像入手,说明了
GAN如何将学到的语义用于人脸编辑
3.1.潜在空间的可分性
文中使用了 SVM 对在 2.1 中二元语义的可分性 进行了验证,证明了假设的正确性。

我们对一些样本到边界的距离进行了排序,得到上图可视化结果。如上图所示,第一行和最后一行的两类极端情况是无法通过直接采样获取到的,只能通过尽可能"无限"地将潜在代码移向法线方向得到。图中显示了正负样本的可区分性。
3.2. 潜在空间的可操控性
3.2.1. 操控单一属性
上图是对5个属性的语义操控,可见在所有属性上都表现良好。特别是姿态属性,观察到即使通过解决双分类问题来搜索边界,移动潜在代码也会产生连续的变化。此外,尽管在训练集中缺乏足够的极端姿势的数据,GAN能够想象侧面脸应该是什么样子。同样的情况也发生在眼镜属性上。虽然训练集的数据不充分,但是可以手动创建很多戴着眼镜的面孔。这两个观察结果有力地证明了GAN并不是随机生成图像的,而是从潜在空间中学习了一些可解释的语义。
3.2.2. 语义子空间的距离效应

距离效应指当样本离边界过远时( − inf -\inf −inf 或 inf \inf inf ),其产生的图像外表会验证地变形,这从 Figure 3 中上下两端的图像可看出。如上图所示,当我们仅对性别属性操控于边界处附近对人脸部信息,人脸的结构保存的很好,而一旦超过一定的区域时,人脸结构就会发生变形。但这种效应并不影响我们对潜空间中解纠缠语义的理解,这是因为这种极端样本不太可能直接从标准正态分布中提取,相反,它们是通过沿着一定的方向不断移动采样得到的潜在代码来手工构造的。这样可以更好地解释GANs的潜在语义。
3.2.3. 伪影修正

文中通过实验发现 GAN 同样将伪影信息编码到了潜在空间中。基于此,文中将伪影视为一个可操控的属性,将其潜码往该属性的积极方向移动,成功消除了伪影。消除结果如上图所示,效果还不错。
3.3. 条件操作
本小结进行了如下两点:
- 不同属性之间的解耦
- 评估了条件操作方法
3.3.1. 各属性之间相关性
本文的关注点是不同隐藏语义之间的关系,并研究它们是如何相互耦合的。因此,本文使用了两种不同的指标来衡量两种属性的相关度:
- 余弦相似度: cos ( n 1 , n 2 ) = n 1 T n 2 \cos(n_1,n_2)=n_1^Tn_2 cos(n1,n2)=n1Tn2,其中 n 1 n_1 n1 和 n 2 n_2 n2 都表示两种属性对应的单位法向量。
- 相关系数:将每个属性的得分作为一个随机变量,将所有50万个综合数据所观测到的属性分布来计算相关系数 ρ \rho ρ。那么有 ρ A 1 A 2 = C o v ( A 1 , A 2 ) σ A 1 σ A 2 \rho_{A_1A_2}=\frac{Cov(A_1,A_2)}{\sigma_{A_1}\sigma{A_2}} ρA1A2=σA1σA2Cov(A1,A2),其中 A 1 A_1 A1 和 A 2 A_2 A2 表示对应于两个属性得分, C o v ( ⋅ , ⋅ ) Cov(\cdot,\cdot) Cov(⋅,⋅) 表示协方差, σ \sigma σ 表示标准差。
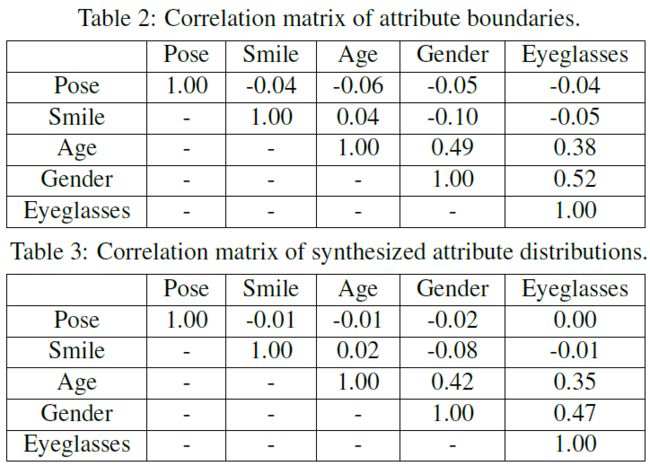
上面这个表格便是使用这两种指标的结果,可见属性在这两个度量下的行为是相似的,这表明提出的 InterFaceGAN 能够准确地识别隐藏在潜在空间中的语义。此外,从表中可看出性别、年龄和眼镜这三个属性是高度相关的,这个观察结果反映了训练数据集中的属性相关性。例如,该数据集中的男性老年人更有可能戴眼镜。GAN在学习产生真实观察时也捕捉到了这一特点。
3.3.2. 条件操作
上图显示了将一个属性固定作为条件而对另一个属性进行操作的结果,以左侧结果为例,文中将性别方向固定为条件,然后对年龄进行编辑,其通过让年龄方向减去性别方向的投影来得到一个新方向,这样可确保当样本沿着投影的新方向移动时,性别成分不会发生改变,而年龄却会改变。
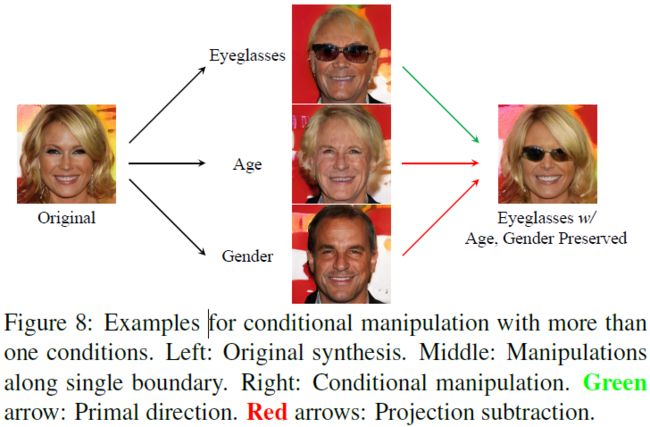
上图则是在将多个属性固定作为条件而对另一个属性操作的结果,这里则是将年龄和性别固定,往人脸上增加眼镜。最开始时,增加眼镜与改变年龄和性别是纠缠在一起的。但通过投影操作后,在不影响年龄和性别的情况下,成功地增加了眼镜。这两个实验表明,我们提出的条件操纵有助于实现独立和精确的属性控制。
3.4. StyleGAN结果
StyleGAN 中的生成器是基于样式的生成器,其首先将 潜在编码从 Z \mathcal{Z} Z 映射到了更高维的空间 W \mathcal{W} W 中,然后将 W \mathcal{W} W 输入到生成器中,StyleGAN 证明了 W \mathcal{W} W 能更好地模拟真实数据的底层特征。
如上图所示, W \mathcal{W} W 空间确实比 Z \mathcal{Z} Z 空间要晚出现眼镜;条件操控于 Z \mathcal{Z} Z 空间的解耦能力要优于单独的使用 W \mathcal{W} W 空间。虽然 StyleGAN 中 W \mathcal{W} W 的解耦能力确实比 Z \mathcal{Z} Z 要好,但却不能用我们提出的投影方法用于 W \mathcal{W} W 空间。因为文中发现 W \mathcal{W} W 空间有时捕获了训练集中数据之间存在的属性相关性,并将其编码成了耦合的样式。以上图为例, W \mathcal{W} W 空间学到了一种包含了眼镜语义的年龄语义投影,但这个方向在某种程度上又和眼镜语义方向是垂直的,我们所描述的减去眼镜投影相当于减去了一个零向量,几乎不会对结果又任何影响。
3.5. 真实图像操控
首先需要将真实图像转换成潜在编码,这里有两种转换机制:
- 基于优化的方法,利用固定生成器直接优化潜在代码,使像素级重构误差最小化
- 基于编码器的方法,其中额外的编码器网络被训练来学习逆映射(图像转潜在编码)
本小结对这两种方法在 PGGAN 和 StyleGAN 上进行了实验。实验结果如下图。

如上图所示,在 PGGAN 中的两种转换机制生成的效果图都较差,可见传统生成器架构的 GAN 对训练数据和测试数据之间的差异性过于敏感。虽然生成的效果图很差,但仍可以用我们的 InterFaceGAN 方法对面部属性进行编辑。
如上图所示,在 StyleGAN 中的基于优化方法的效果要好得多。值得注意的是,这里的优化目标是每层的样式(所有层里的 w w w)。在编辑实例的过程中,将所有的样式编码都推向同一个方向。无需再训练StyleGAN,仅仅利用了潜在空间的解释语义,便成功地更改了真实人脸图像的属性。

此外还测试了 InterFaceGAN 在编码器-解码器生成模型(让编码器与生成器和判别器同时参与训练)里的效果。即一旦模型收敛,便直接使用编码器进行推理将给定图像映射到潜在空间。文中将 InterFaceGAN 方法来解释最近的编解码器模型 LIA 的潜在空间。实验结果如上图所示,可见其也支持语义编辑。此外,同上述由 PGGAN 中模型准备好后再单独学习编码器相比,编码器和生成器一起训练的模型明显有更好的重构和操作结果。
四. 实现细节
本文选择了五个关键的面部特征进行分析,包括姿势、微笑、年龄、性别和眼镜。相应的“正方向”被定义为向右转、大笑、变老、男性化和戴眼镜。注意,只要属性检测器可用,我们总是可以轻松插入更多属性。
使用自CelebA数据集的注释和ResNet50网络训练了一个辅助属性预测模型。这个模型接受了多任务损失训练,以同时预测微笑、年龄、性别、眼镜以及5点面部标志(确定面部框架)。这里,人脸标示将被用来计算姿势的偏移,在进一步的分析中也被当作二元属性(左或右)来处理。**除面部标志外,所有的属性都用 softmax 交叉损失的双分类问题,面部标志用 l 2 l_2 l2 回归损失进行优化。**由于 PGGAN 和 StyleGAN 的图像分辨率为 1024 × 1024 1024\times 1024 1024×1024,我们在将其输入属性模型之前将其大小调整为 224 × 224 224\times224 224×224。
在预先训练好的 GAN 模型的基础上,对潜在空间进行随机采样,生成了 500 500 500 K 幅图像。之所以要准备这样大规模的数据,主要有两个原因:
- 消除抽样带来的随机性,通过大规模数据来确保潜在编码的分布符合预期分布。
- 通过大规模数据来确保训练集中有足够多的戴眼镜样本,因为
PGGAN模型中很少生成这一类样本。
为了找到潜在空间中的语义边界,我们使用预先训练好的属性预测模型对 500 500 500 K 个合成的图像进行属性评分。对于每个属性,我们对相应的得分进行排序,选择得分最高的10K个样本和得分最低的10K个样本作为候选。这样做的原因是,预测模型不是绝对准确的,可能会对模糊的样本产生错误的预测,例如对年龄属性的预测是中年人。然后从候选样本中随机抽取 70 % 70 \% 70% 的样本作为训练集学习线性支持向量机,得到一个决策边界。其中,所有边界的法向量都归一化为单位向量。剩下的30%用于验证线性分类器的分类效果。在SVM训练中,输入为 512 512 512 维的潜码,二值标签由辅助属性预测模型分配。