【阅读笔记】SinGAN:Learning a Generative Model from a Single Natural Image
论文名称:SinGAN: Learning a Generative Model from a Single Natural Image
论文作者:Tamar Rott Shaham, Tali Dekel, Tomer Michaeli
发行时间:Submitted on 15 Dec 2019, last revised 31 Mar 2020
论文地址:https://arxiv.org/abs/1905.01164
代码开源:https://github.com/tamarott/SinGAN
- 一. 概要
- 二. SinGAN 模型
- 2.1. 多尺度架构
- 2.2. Patch的精巧处理
- 2.3. 训练阶段
一. 概要
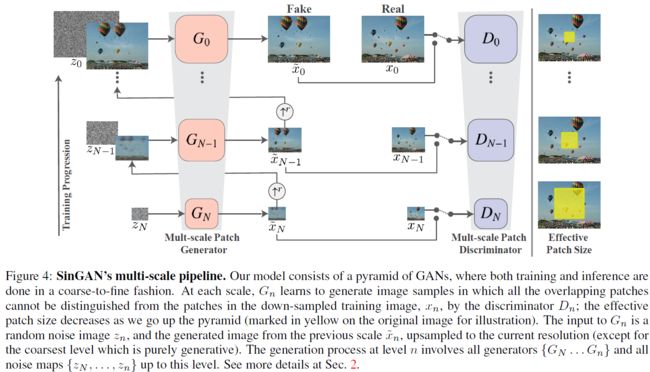
本文提出了 SinGAN 模型,其是一个非条件生成器模型中对单张自然图像进行训练的模型。 SinGAN 由金字塔型的一系列全卷积 GAN 组成,其中的每个 GAN 都用来学习图像在不同尺寸下的 patches 数据分布。该模型被训练来捕获图像中 patches 之间数据分布,然后可生成一系列尺寸的高质量图像,这些图像同训练图像在语义结构上相似,但包含了新的对象配置和结构。如下图所示。
具体来说,SinGAN 仅对一张图像进行训练,训练完毕后又在这张图像上进行测试。即只能对训练的图像进行测试,一旦想换一张图测试效果,需要重新对这张图像进行训练。
对于从原图中分割出来的 pathch ,实际上是在对应的尺寸上的图像分割出来的 patch ,其中原文中的感受野和 patch 大小都设置为 11 × 11 11 \times 11 11×11 的大小。对于最粗糙的图中,其分割出来的多个重叠 patches ,忽略了图像的细节信息,较好的保留了图像整体的布局信息。然后随着训练的不断推进,图像的尺寸不断增大,随之而来的是分割出来的 patch 逐渐开始注重细节,同时由于模型的残差设计,会逐渐往之间的模糊图像中引入更多的细节,最终得到有效的图像。SinGAN使用多个GAN结构分别学习了不同尺度下分辨率 11 × 11 11 \times 11 11×11 的图像块的分布,并从粗糙到细致、从低分辨率到高分辨率逐步生成真实图像。

二. SinGAN 模型
第 n n n 层的 G n G_n Gn 的具体实现:
2.1. 多尺度架构
如上图所示,模型由 N + 1 N+1 N+1 个 GAN 组成,包含金字塔型生成器 { G 0 , ⋯ , G N } \left \{ G_0,\cdots, G_N \right \} {G0,⋯,GN},金字塔型判别器 { D 0 , ⋯ , D N } \left \{ D_0,\cdots,D_N \right \} {D0,⋯,DN}。 { x 0 , ⋯ , x N } \left \{ x_0,\cdots,x_N \right \} {x0,⋯,xN} 是一系列尺寸金字塔型图像,其中 x n x_n xn 是训练图 x 0 x_0 x0 按照系数 r r r 进行下采样图, r > 1 r>1 r>1 (原文说 r r r 应该尽量接近于 4 3 \frac{4}{3} 34)。 { z 0 , ⋯ , z N } \left \{ z_0,\cdots,z_N \right \} {z0,⋯,zN} 是一系列对应尺寸的随机噪声图。
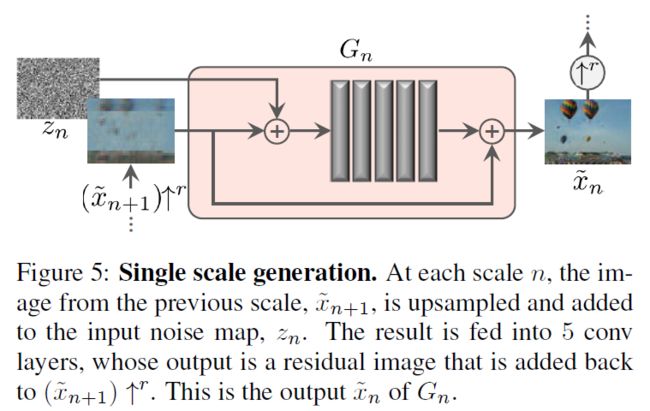
**模型是从粗糙到精细( N → 0 N \to 0 N→0)逐渐进行训练的,且每个尺寸训练上都注入了噪声,并使用了残差学习的思想。**首先看生成器:
- 对于模型的第 N N N 层,作为最粗糙的生成器 G N G_N GN 直接接受 z N z_N zN 来生成 x ~ N \tilde{x}_N x~N 。
- 对于模型的第 n n n 层( n < N n < N n<N),首先将该层的噪声图 z n z_n zn 加上前一层生成器 G n + 1 G_{n+1} Gn+1 生成的图 x ~ n + 1 \tilde{x}_{n+1} x~n+1 的上采样图 ( x ~ n + 1 ) ↑ r (\tilde{x}_{n+1})\uparrow^r (x~n+1)↑r,然后将该图输入到当前层的生成器 G n G_n Gn 中, 然后再将生成器的图加上上采样图 ( x ~ n + 1 ) ↑ r (\tilde{x}_{n+1})\uparrow^r (x~n+1)↑r,得到最终的输出图 x ~ n \tilde{x}_n x~n。
- 用表达式表示第 i i i 层生成器 G i G_i Gi 的结果如下所示:
x ~ i = { G i ( z i ) , i = N G i ( z i , ( x ~ i + 1 ) ↑ r ) , i < N \tilde{x}_i=\left\{\begin{matrix}G_i(z_i) & ,~~i=N\\ G_i(z_i,(\tilde{x}_{i+1})\uparrow^r) & ,~~i
更具体的说,由于生成器实际上是由 5 5 5 个由 Conv(3×3)-BatchNorm-LeakyRelu 的卷积块组成的全卷积网络 ψ \psi ψ 。所以可以更详细的写出第 i i i 层生成器 G i G_i Gi 的表达式:
x ~ i = { ψ i ( z i ) , i = N ( x ~ i + 1 ) ↑ r + ψ i ( z i + ( x ~ i + 1 ) ↑ r ) , i < N \tilde{x}_i=\left\{\begin{matrix} \psi_i(z_i) & ,~~i=N\\ (\tilde{x}_{i+1})\uparrow^r + \psi_i(z_i+(\tilde{x}_{i+1})\uparrow^r)& ,~~i
再看判别器,这里的判别器的网络结构和生成器一样都是5个由 Conv(3×3)-BatchNorm-LeakyRelu 的卷积块组成的全卷积网络 ψ \psi ψ ,不同的是这里采用的是马尔科夫判别器,即在全连接网络的最后一层卷积结果经过 Sigmoid 处理并输出,得到一个概率判别图,其大小和当前层的的 x ~ n \tilde{x}_n x~n 大小一样(不包含通道),其中每个位置的值都表示了 x ~ n \tilde{x}_n x~n 以该位置为中心的 11 × 11 11 \times 11 11×11 的 Patch 和对应位置处的 x n x_n xn 的 Patch 一致的概率。最终 D n D_n Dn 的输出是这个概率判别图的平均值。
- 对于模型的第 0 0 0 层,判别器接受的原始图像 x 0 x_0 x0 和对应层生成器生成的图像 x ~ 0 \tilde{x}_0 x~0。
- 对于模型的第 n n n 层( n > 0 n>0 n>0), 判别器接受的是原始图像下采样到对应尺寸的图 x n x_n xn 和对应层生成器生成的图像 x ~ n \tilde{x}_n x~n。
总的来说,对于其中第 n n n 层, G n G_n Gn 学到了该尺度下 11 × 11 11\times 11 11×11 图像 patches 的分布,并能够结合上一尺寸的输出来生成当前尺寸下的图像。 D n D_n Dn 则能够判别一个 11 × 11 11\times 11 11×11 的图像的 patches 是否是该尺寸下的真实图像的 patches 。
2.2. Patch的精巧处理
本小结引用自 QbitAl的博客
虽然在网络的输入端都是完整图像,但实际上,作者通过一个巧妙的设计使得其等价于将图像分割成 11 × 11 11\times11 11×11 的 Patch 分别输入:
- 由于所有的生成器 G G G 和判别器 D D D 都拥有相同的网络结构,都由 5 5 5 个 3 × 3 3\times3 3×3 的卷积块组成,对应的感受野都是 11 × 11 11\times 11 11×11 。将一张图像输入一个拥有 11 × 11 11\times 11 11×11 感受野的网络,网络会输出的每个位置的值,等价于原图以该位置为中心,大小为11x11的
patch输入网络后的输出值。(并不严谨,可意会一下)
2.3. 训练阶段
模型从从粗糙( 25 p x 25 px 25px)到精细( 250 p x 250 px 250px)尺寸逐渐进行训练,且一旦某个阶段的 GAN 训练完毕,就将其权重固定住。本文第 n n n 层的训练损失由对抗性损失和重构性损失这两部分组成:
min G n max D n L a d v ( G n , D n ) + α L r e c ( G n ) \mathop{\min}\limits_{G_n} \mathop{\max}\limits_{D_n}\mathcal{L}_{adv}(G_n,D_n)+\alpha\mathcal{L}_{rec}(G_n) GnminDnmaxLadv(Gn,Dn)+αLrec(Gn)
其中
-
L a d v \mathcal{L_{adv}} Ladv 对 x n x_n xn 与 x ~ n \tilde{x}_n x~n 中的
patches分布间的距离进行惩罚。对于对抗性损失 L a d v \mathcal{L_{adv}} Ladv,实际上就是使用WGAN-UP loss,可有效地增加训练的稳定性。 -
L r e c \mathcal{L}_{rec} Lrec 用来确保存在一个噪声集合 { z 0 , ⋯ , z N } \left \{ z_0,\cdots,z_N \right \} {z0,⋯,zN} 能够生成当前尺寸下的原图 x n x_n xn。为此,作者特意选取了一组随机噪声,即仅在生成最粗糙的图像时用到 z ⋆ z^{\star} z⋆ ,之后的阶段都取消噪声输入:
{ z N r e c , z N − 1 r e c , ⋯ , z 0 r e c } = { z ⋆ , 0 , ⋯ , 0 } \left \{ z_N^{rec},z_{N-1}^{rec},\cdots,z_0^{rec} \right \}=\left \{ z^{\star},0,\cdots,0 \right \} {zNrec,zN−1rec,⋯,z0rec}={z⋆,0,⋯,0}
这里的 z ⋆ z^{\star} z⋆ 是训练前随机选取的固定噪声图,于是重构性损失表示如下:
L r e c = { ∣ ∣ G N ( z ⋆ ) − x N ∣ ∣ , n = N ∣ ∣ G n ( 0 , ( x ~ n + 1 r e c ) ↑ r ) − x n ∣ ∣ 2 2 , n < N \mathcal{L}_{rec}= \left\{\begin{matrix} ||G_N(z^{\star})-x_N|| & ,~~n=N \\ ||G_n(0,(\tilde{x}^{rec}_{n+1})\uparrow^r)-x_n||_2^2 & ,~~nLrec={∣∣GN(z⋆)−xN∣∣∣∣Gn(0,(x~n+1rec)↑r)−xn∣∣22, n=N, n<N
即我们希望尽可能最小化该层的 x n x_n xn 与 x ~ n \tilde{x}_n x~n 之间的差异的二范数。