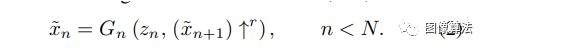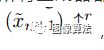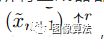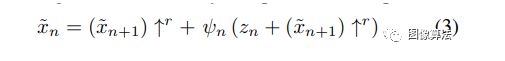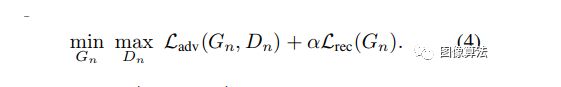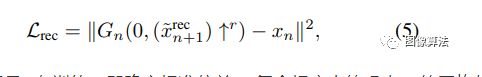SinGAN从单个自然图像中学习生成模型ICCV 2019最佳论文
该篇Paper的作者来自谷歌研究院,文章中主要提及图像生成是从单个训练图像中学到的。
作者建议SinGAN –一种新的无条件生成在单个自然图像上训练的模型。对模型使用专门的多尺度对抗训练计划;然后可以将其用于生成新的逼真的图像样本,以保留创建新的对象配置和结构时使用原始补丁程序分发。
概述
SinGAN是一种无条件的生成模型,可以从单个自然图像中学习。 模型经过训练后,可以捕获图像内斑块的内部分布,然后能够生成高质量,多样的样本,并承载与图像相同的视觉内容。SinGAN包含一个完全卷积的GAN金字塔,每个GAN负责学习图像不同比例的面片分布。这样就可以生成具有任意大小和纵横比的新样本,这些样本具有明显的可变性,同时又可以保持训练图像的整体结构和精细纹理。与以前的单图像GAN方案相比,我们的方法不仅限于纹理图像,而且不是有条件的(即它从噪声中生成样本)。用户研究证实,生成的样本通常被混淆为真实图像。我们将说明SinGAN在各种图像处理任务中的实用性。
相关背景
生成对抗网(GAN)在建模高维分布方面的巨大飞跃视觉数据。特别是,无条件GAN具有在针对特定班级的数据集进行训练后,在生成逼真的高质量样本方面显示出了巨大的进展(例如,人脸,卧室等)。但是,捕获具有多个对象类的高度多样化的数据集的分布(例如ImageNet ),仍然被认为是一项重大挑战并经常需要以另一代为条件输入信号或为特定任务训练模型(例如超分辨率,修复,重新定位)。
在这里,我们将GAN的使用带入了一个新领域-从单个自然图像中学到的无条件生成。具体来说,我们显示了补丁的内部统计信息单个自然图像中的图像通常携带足够的信息以学习强大的生成模型。我们新的单一图像生成模型,使我们能够应对包含复杂结构的一般自然图像和纹理,而无需依赖存在来自同一类别的图像数据库。这是通过实现完全卷积的轻型GAN的金字塔,每个
负责捕获补丁的分布不同的规模。经过培训,SinGAN可以生成各种高质量的图像样本(任意尺寸),在语义上类似于训练图像,但包含新的对象配置和结构。

建模内部补丁的内部分布长期以来,人们一直认为单一自然图像是许多计算机视觉任务中的有力先验[。
经典示例包括去噪,去模糊,超分辨率,除雾和图像编辑。
与Closley最相关的工作,其中定义并优化了双向补丁相似性度量以确保图像经过处理后的色块与原始的。作者在这里展示如何在简单的统一学习中使用SinGAN解决各种图像处理任务的框架,包括从单个图像进行图像绘制,编辑,协调,超分辨率和动画。
在所有这些情况下,我们的模型会产生高质量的结果,训练图像的内部补丁统计信息(见图和我们的项目网页)。所有任务都可以通过相同的生成网络,无需任何其他信息或超出原始训练图像的进一步训练。

相关工作
- 一单图像深度模型。
最近的一些工作提出在单个样本上训练“过拟合”深度模型,所有这些都是为特定任务设计的,如超分辨率重建、纹理扩展等。由Shocher等人提出的Ingan。是第一个基于内部gan的单一自然图像训练模型。生成的样本依赖于输入图像(即图像被映射到图像),并且无法绘制随机样本。
本文的框架是纯生成的(即将噪声映射到图像样本),因此适用于许多不同的图像处理任务。目前,无条件单像gan模型只研究纹理图像。在对这些模型进行无背景图像训练时,不会生成有意义的样本。本文提出的方法不仅限于纹理,而且可以处理一般的自然图像。
- 图像处理的生成模型。
在许多不同的图像处理任务中,基于gan的方法已经被证明具有很大的不利于学习的优势,包括交互式图像编辑、草图合成图像和其他图像到图像的翻译任务。
然而,所有这些方法都是在一组特定的数据集上训练的,通常需要生成额外的输入信号调整。本文不关注如何在同一类型的图像之间获得共同特征,而是考虑使用不同的训练数据源——在单个自然图像的多个尺度上的所有重叠图像块。
作者指出,强大的生成模型可以从这些数据中学习并用于许多图像处理任务。
方法
本文的目标是学习一个无条件生成模型,该模型捕获单个训练图像x的内部统计信息。该任务在概念上与传统的gan设置类似,只是这里的训练样本是在单个图像的不同尺度上采样的图像,而不是数据集中的整个图像样本。
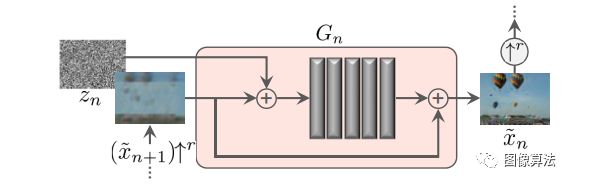
模型选择处理更一般的自然图像,使模型具有纹理生成以外的其他功能。为了捕捉图像中目标的形状和排列位置(如顶部的天空、底部的地面)等全局特性,以及精细的细节和纹理信息,singan包含了一个分块gans(markov discriminator)的层次结构,其中每个discriminator负责捕捉x不同的刻度,如图所示。
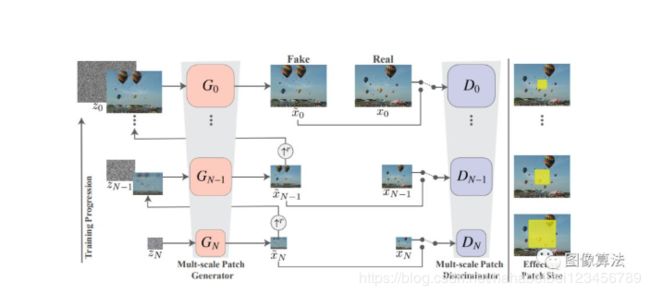
SinGAN的多尺度管道。我们的模型由GAN金字塔组成,在该金字塔中训练和推理都是从粗到细的方式完成。在每个尺度上,Gn都会学习生成图像样本,其中所有重叠的色块鉴别符Dn无法将其与下采样训练图像xn中的色块区分开;有效的补丁尺寸随着我们上金字塔而减小(为便于说明,在原始图像上以黄色标记)。Gn的输入是随机噪声图像zn和从先前比例x〜n生成的图像被上采样到当前分辨率(除了纯粹是生成的最粗糙的级别)。级别n的生成过程涉及所有生成器{GN。。。Gn}和所有噪声图{zN,。。。}直到达到此级别。
尽管在gan中已经探索了类似的多尺度结构,但本文是第一个探索从单个图像进行内部学习的网络架构。
多尺度结构
我们的模型由金字塔组成,{G0,。。。,GN},针对x的图像金字塔进行训练:{x0,。。。,xN},其中xn是x的下采样版本,因子rn,对于r>1。每个生成器Gn负责生成逼真图像样本。相应图像xn中的色块分布。实现了
通过对抗训练,Gn学会愚弄相关的歧视者Dn,后者试图区分xn中补丁生成的样本中的补丁。
图像样本的生成从最粗糙的位置开始缩放并依次通过所有生成器,直到最好的音阶,在每个音阶上都会注入噪声。所有生成器和鉴别器具有相同的接收场并因此捕获随着我们上升而尺寸减小的结构生成过程。在最粗略的范围内是纯粹生成的,即GN映射空间白色高斯噪声zN到图像样本x〜N,
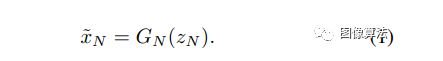
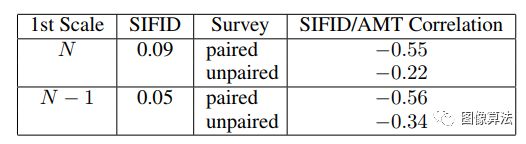
在此水平上的有效接收场通常约为1/2图像的高度,因此GN会生成图像的总体布局以及对象的全局结构。每一个生成器Gn在较小的比例下(n 所有生成器都具有相似的架构,如下所示在图中。具体地,噪声zn被添加到图像。,然后再馈入一系列卷积层。这确保了GAN不会忽略 噪声,就像在涉及随机性的条件方案中经常发生的那样[62,36,63]。积液的作用层将生成中的缺失细节[R(残余学习)。即Gn执行操作 ψn是具有5个conv块的全卷积网络形式为Conv(3×3)-BatchNorm-LeakyReLU 。我们首先以最粗糙的比例从每个块32个内核开始,然后每4个比例将该数字增加2倍。因为生成器是完全卷积的,我们可以在测试时生成任意大小和宽高比的图像(通过更改噪声图的尺寸)。 单尺度生成。 在每个比例n处,对前一个比例x〜n + 1的图像进行上采样并相加输入噪声图zn 结果送入5转换层,其输出是添加回去的残像 训练过程 我们从从最粗到最细的比例。每个GAN一次受过训练,会保持固定。我们第n个GAN的训练损失是由对抗词和重构词组成, 拉德夫的对抗损失惩罚了双方之间的距离。xn中补丁的分布和生成的样本xn中的补丁。重建损失Lrec确保存在一组特定的噪声图可以产生xn,这是图像处理的重要功能。接下来,我们将详细描述Ladv,Lrec。看到有关优化细节的补充材料(SM)。 每产生Gn耦合使用马尔可夫鉴别器Dn对每个分类器进行分类 其输入的重叠补丁是真实的还是伪造的。作者使用WGAN-GP损失,发现这会增加训练的稳定性,最终的得分是补丁识别图上的平均值。与用于纹理的单图像GAN相比,这里我们定义整个图像的损失,而不是随机的。这使网能够学习边界条件(请参阅SM),这很重要功能设置。Dn的架构相同作为Gn内的净ψn,因此其补丁大小是11×11。 我们要确保存在一组特定的输入噪声图,该图会生成原始图像x。我们专门选择{z记录reN−1。。。,zrec0} = {z∗,0,。。。,0},其中z∗是一些 固定的噪声图(绘制一次并在训练过程中保持固定)。用x〜表示记录ñ生成的第n个比例的图像使用这些噪声图时。然后对于n 重建图像x〜记录n在训练,即确定标准偏差σn每个标度中的噪声zn的平均值。具体来说,我们将σn取为与(〜x之间的均方根误差(RMSE)成正比记录和xn表示需要按该比例添加的详细信息数量。 实验结果 作者在一个图像场景跨度较大的数据集上对信号进行了定性和定量测试。定性生成的图像如图1和图4所示。singan很好地保留了目标的全局结构和更好的纹理信息,如图1中的山脉、图4中的热气球或金字塔。此外,该模型是反射和阴影的真实合成。 随机生成的图像样本 当训练中使用较少的尺度时,最粗尺度的有效场会更小,因此只能捕捉到精细的纹理。随着缩放比例的增加,会出现更大的支撑结构,并且全局目标的对齐(位置关系)会得到更好的保留。 该测试可以选择开始生成标度,而singan的多标度结构可以控制样本之间的差异总量。从最粗的尺度生成会导致整体结构的巨大变化,在某些情况下,如果目标显著性较大,则可能会生成不真实的样本。 当从更精细的尺度开始时,整体结构可以保持完整,同时只改变更精细的图像特征。 为了量化生成的图像的真实性以及它们捕获训练图像内部统计信息的程度,作者使用了两种度量:amt真假用户研究和fid的单一图像版本。 amt测试结果表明,singan能够生成非常逼真的样本,且人的识别混淆率较高。利用单图像fid量化singan捕获x内部统计信息的能力的结果如表1所示。 n-1量表的sfid评价值低于n量表的sfid评价值,这与用户研究结果一致。作者还报告了sifid和假图像混叠率之间的相关性,并且二者之间存在显著的负相关性,这意味着较小的sifid通常表示较大的混淆率。 高分辨率图像生成。 从不同尺度生成 两种模式的SIFD值 结论 作者介绍了SinGAN,一种新的无条件生成从单个自然图像中学到的方案。证明了其超越纹理的能力并能够为自然复杂的图像生成各种逼真的样本。 内部学习在语义上固有地受到限制与受过外部训练的生成方法相比更具多样性。例如,如果训练图像包含单个狗,我们的模型不会生成其他狗的样本品种。不过,正如我们的实验所证明的,SinGAN可以为广泛的应用提供强大的工具图像处理任务。 相关论文源码下载地址:关注“图像算法”微信公众号 回复“SinGAN”