词典
import nltk
def unusual_words(text):
text_vocab = set(w.lower() for w in text if w.isalpha())
english_vocab = set(w.lower() for w in nltk.corpus.words.words())
unusual = text_vocab.difference(english_vocab)
return sorted(unusual)
print(unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt')))
from nltk.corpus import stopwords
import nltk
stopwords.words('english')
def content_fraction(text):
stopwords = nltk.corpus.stopwords.words('english')
content = [w for w in text if w.lower() not in stopwords]
print(content)
return len(content) / len(text)
print(content_fraction(nltk.corpus.reuters.words()))
- 一个游戏,从字典中找出一些词语,这些词语长度大于设定值6, 并且每个字母只能出现一次,并且必须包含一个已经设定好的字母r
import nltk
puzzle_letters = nltk.FreqDist('egivrvonl')
obligatory = 'r'
wordlist = nltk.corpus.words.words()
print([w for w in wordlist if len(w) >= 6
and obligatory in w
and nltk.FreqDist(w) <= puzzle_letters])
import nltk
names = nltk.corpus.names
names.fileids()
male_names = names.words('male.txt')
female_names = names.words('female.txt')
print([w for w in male_names if w in female_names])
- 输出姓名末尾的字母在男女中的比例(即男女中以26个字母为姓名末尾的频数分布)
import nltk
names = nltk.corpus.names
cfd = nltk.ConditionalFreqDist(
(fileid, name[-1])
for fileid in names.fileids()
for name in names.words(fileid))
cfd.plot()

1.发音词典(并没有完全整理完整,当涉及到时在看)
import nltk
entries = nltk.corpus.cmudict.entries()
print(len(entries))
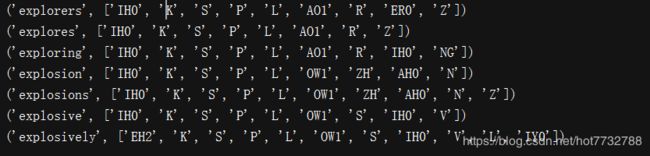
for entry in entries[39943:39951]:
print(entry)
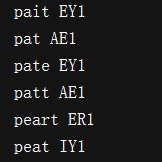
- 找出三音节,并且第一个音节是P,第三个音节是T,的发音词典中的词
import nltk
entries = nltk.corpus.cmudict.entries()
for word, pron in entries:
if len(pron) == 3:
ph1, ph2, ph3 = pron
if ph1 == 'P' and ph3 == 'T':
print(word, ph2)
- 输出以设定好音节为发音结尾的词(可用于其他部分,如果以单词为结尾的中文句子,稳)
import nltk
entries = nltk.corpus.cmudict.entries()
syllable = ['N', 'IH0', 'K', 'S']
print([word for word, pron in entries if pron[-4:] == syllable])
2.比较词典(相同单词在不同语言中的意思转换,未细看,请自行整理,此处仅作提醒)
from nltk.corpus import swadesh
print(swadesh.fileids())
3.词汇工具toolbox
from nltk.corpus import toolbox
print(toolbox.entries('rotokas.dic')[0])

4.woednet(同义词)
from nltk.corpus import wordnet as wn
print(wn.synsets('motorcar'))
print(wn.synset('car.n.01').lemma_names())
print(wn.synset('car.n.01').definition())
print(wn.synset('car.n.01').examples())
from nltk.corpus import wordnet as wn
print(wn.synset('car.n.01').lemmas())
print(wn.lemma('car.n.01.automobile'))
print(wn.lemma('car.n.01.automobile').synset())
print(wn.lemma('car.n.01.automobile').name())
for synset in wn.synsets('car'):
print(synset.lemma_names())
motorcar = wn.synset('car.n.01')
types_of_motorcar = motorcar.hyponyms()
sorted([lemma.name() for synset in types_of_motorcar for lemma in synset.lemmas()])
motorcar.hypernyms()