利用python进行数据分析学习笔记1(NumPy)
常用模块的命名惯例
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels as sm
numpy基础
NumPy的ndarray是一种多维数组对象,创建一个ndarray实例
import numpy as np
data = np.random.randn(3,5)
调用numpy库中的random模块的randn函数,这个函数根据标准正态分布随机产生一个数,生成了一个二维数组,每个列表中有五个元素,可以直接对数组进行数学运算,计算会应用在每个元素上。
data * 10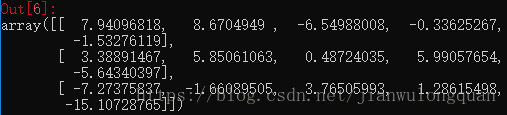
每个数组都有shape和dtype属性,前者表示各维度大小,后者说明数组中的数据类型的对象

创建ndarray
array是数组创建函数,它将输入数据(列表、元祖、数组或其它序列类型)转换为ndarray。
新建一个列表,将列表作为参数传到array中。
data1 = [1,2,3,4,5]
arr1 = np.array(data1)![]()
如果是嵌套序列,则生成多维数组
data2 = [[10, 9, 8, 7], [6, 5, 4, 3]]
arr2 = np.array(data2)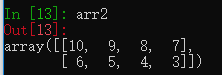
数组的ndim属性返回数组的维度,如上面的data是个二维数组。
![]()
zeros和ones函数创建全0和全1的数组。
test1 = np.zeros(10) #表示创建一个10个元素的一维数组![]()
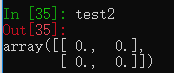
test2 = np.zeros((2,2)) #表示创建一个二维数组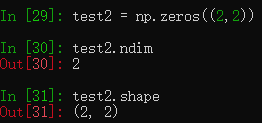
test3 = np.zeros((2,2,2)) #表示创建一个三维数组
zeros_like和ones_like函数,以另一个数组为参数,根据其形状创建一个全0或全1的数组。
比如上面的test4是一个内含15个元素的一维数组。
test5 = np.zeros(test4) #表示创建一个和test4一样的一维数组,由15个0组成![]()
numpy中的arange函数是python内置函数range的数组版。
test4 = np.arange(15) #表示创建一个一维数组,由0~14组成

full函数有两个参数,参数一是数组形状,参数二是指定填充的数据。
test6 = np.full((2,2),3) #表示创建一个两行两列的数组,用3填充
eye函数生成对角数组,第一个参数和第二个参数表示数组规模,如eye(2,4)表示创建两行四列的数组,如果只输入第一个参数则默认第二个参数和第一个参数相同。第三个参数默认是0,表示从左上到右下的对角线用1填充,其余都是0,如果是k=2,表示左上第二条对角线(从0开始)用1填充,如果是负数,则从右下角算。
test7 = np.eye(2) #创建一个2*2的数组,左上到右下对角线用1填充
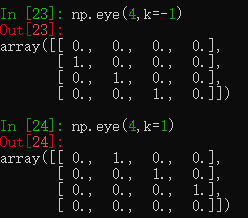
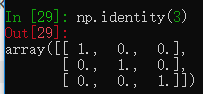
还有一个identity函数和eye相近,不过只能创建正方形数组
数组的数据类型
通过array创建数组时,通过dtype可以将数据设置为指定类型。
test = np.array([1,2,3,4,5,6]) #默认是int64![]()
通过astype可以进行修改
test2 = test.astype(np.float64)![]()
如果将浮点数的数据转化成整数类型,那么小数部分会被删除。
如果字符串数组中都是数字,也可以转换为数字类型。
astype还可以传入一个数组作为参数,将数据类型转为和该数组参数一致的数据类型。
另外,使用astype不会在原对象上进行修改。
数组的运算
arr = np.array([[1,2,3],[4,5,6]]) #创建一个二维数组可以直接对数组进行运算。

数组和数组间也可以进行运算,前提是数组的形状一样。

两个形状相同的数组可以进行逻辑比较,返回一个布尔值数组
arr2 = np.array([[9,8,7],[6,5,4]]) #再创建一个和arr形状相同的二维数组
不同大小的数组之间的运算叫广播。
基本索引和切片
arr = np.arange(10) #创建一个一维数组![]()
通过索引取数组中某个元素(序号从0开始)
![]()
通过切片取数组中某区间元素(区间左开右闭)
![]()
通过切片可以将指定区间的数据改为其他数据,修改会原地进行。

通过切片将数组的某个区间的数据赋值给一个新变量,如果该变量发生变化,原数组的数据也会变化。

![]()
因为numpy是处理大数据的,如果赋值给一个新变量就复制一个数组,可能会导致内存不够用,所以使用这种映射的方式。
如果明确想要一份副本,则应如下书写
test = arr[2:5].copy()对二维数组及三位以上数组的索引和切片方式和普通list相近
arr2d = np.array([[1,2,3],[4,5,6]]) #创建一个二维数组
arr2d[0][1] #取元素索引为(0,1)的元素

arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) #创建一个二维数组
arr2d[:2, 1:] #通过切片取前两行数据,再取第一列及以后的数据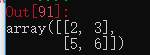
arr2d[:2,2] #取前两行的第二列数据arr2d[:1, :] = 0 #通过切片表达式对数组的指定区域赋值
布尔型索引
name = np.array(['A', 'B', 'C', 'A', 'D', 'E', 'F']) #创建一个字符串数组
name == 'A' #找出字符串为A的元素,返回的是一个布尔型数组
这个布尔型数组可以作为索引。
test = np.random.randn(7,4) #创建一个七行四列的随机数组
test1 = test[name == 'A'] #将布尔型数组作为索引代入,返回布尔值为True的对应数据索引位置0、4的布尔值为True,故返回test数据对应位置的数据。


test2 = test[~(name == 'A')] #返回字符串不为A的,符号~用于反转条件
运算符&表示和,|表示或
test3 = test[(name == 'A') | (name == 'B')] #返回字符串为A或B的对应数据
常通过布尔型数组设置值。
test[test < 0] = 0 #通过布尔型数组,将test数组中小于0的数值全部设置为0
花式索引
简单举个例子,先创建一个八行四列的数组
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
传入整数列表作为参数,可以返回指定的行。
arr[[4,3,0,6]]返回第四行,第一行,第零行,第六行。

如果传入两个索引列表,第一个列表表示行,第二个列表表示列
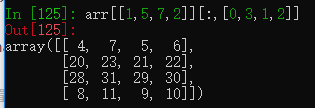
arr = np.arange(32).reshape((8, 4)) #创建一个八行四列的数组
arr[[1, 5, 7, 2], [0, 3, 1, 2]]取行1,5,7,2,列0,3,1,2的数据
![]()
选中数据后可以改变列的次序
arr[[1,5,7,2]][:,[0,3,1,2]]选中行1,5,7,2的所有数据,并将列的顺序调整为0,3,1,2。
数组转置和轴对换
array有一个T属性,可以对数组进行转置,即行和列互换。
arr = np.arange(15).reshape((3,5)) #创建一个三行五列的数组
arr.T #使用T属性对行列转置
矩阵计算经常用到转置,如np.dot计算矩阵内积(前矮胖,后瘦高)
np.dot(arr,arr.T)
对高维数组,transpose函数需要传入一个由轴编号组成的元组才能进行转置。
arr = np.arange(16).reshape((2,2,4)) #创建一个三维数组,数组形状为2,2,4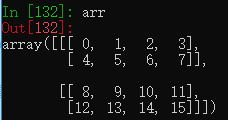
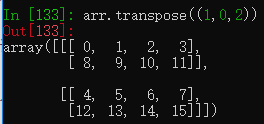
arr.transpose((1,0,2)) #将每个元素的0和1位交换如8的位置原来是(1,0,0),经过转置后变为了(0,1,0)
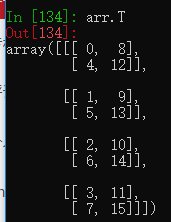
使用T属性则是将元素的位置整个倒过来,如8的位置原来是(1,0,0),使用T转置后变成(0,0,1)
还有一个swapaxes方法,传入两个轴参数,返回的结果是将这两个轴互换的转置结果。
arr.swapaxes(1,2) #将1和2转置如4原来的的位置参数为(0,1,0),将参数1和2转置后变成了(0,0,1)

通用函数
一元通用函数,只接受一个数组,对每个元素进行计算。
arr = np.arange(10) #创建一个0-9的一维数组
np.sqrt(arr) #对arr数组中的每个元素开方
np.exp(arr) 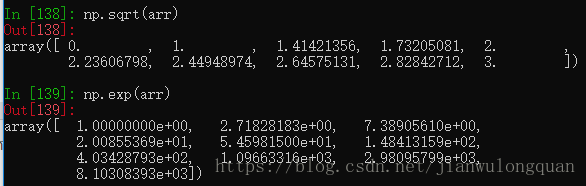
接受两个数组的叫二元函数,如add或者maximum。
x = np.random.randn(5)
y = np.random.randn(5) #创建两个随机数组
np.maximum(x,y) #使用maximum函数比较大小
![]()
有些计算函数可以返回多个数组,如modf,会返回传入数组的整数部分和小数部分。
arr = np.random.randn(5)
int_,float_ = np.modf(arr)
通用函数可以接受一个out可选参数,实现原地修改

其他一元通用函数
abs和fabs都是计算绝对值,fabs不能用于复数。
sqrt计算元素的平方根。
square用于计算元素的平方。
exp计算元素的指数e^x。
sign计算元素的正负号,1表整数,0表示零,-1表示负数。
ceil计算大于等于元素的最小整数。

floor计算小于等于元素的最大整数。
rint将元素四舍五入到最接近的整数,保留原数据类型。
modf,将元素的整数部分和小数部分分割开,一独立数组形式返回。
isnan,判断元素是不是NaN,是则True。返回一个逻辑数组。
isfinite,isinf,分别判断元素是有穷,无穷,返回一个逻辑数组。
二元通用函数
add,将两个数组中对应元素相加。
subtract,第一个数组减第二个数组。
multiply,数组元素相乘。
divide函数,参数1除参数2,floor_divide函数,结果取整。
power,第一个数组中的元素A,第二个数组中的元素B,计算A^B。
maximum,返回最大元素数组。
minimum,返回最小元素数组。
mod,返回数组1除数组2的余数的数组。
copysign,将第二个数组中的值的符号赋值给第一个数组中的值。
![]()
greater、greater_equal、less、less_equal、equal、not_equal,相当于大于,大于等于,小于,小于等于,等于,不等于。
利用数组进行数据处理
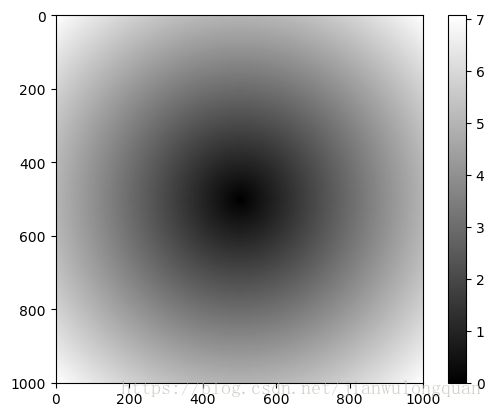
points = np.arange(-5,5,0.01) #创建一个数组
xs,ys = np.meshgrid(points,points) #通过meshgrid函数返回了两个二维矩阵

z = np.sqrt(xs ** 2 + ys **2) #使用xs和ys进行计算。
使用matplotlib创建这个二维数组的可视化

将条件逻辑表述为数组运算
创建两个普通数组和一个布尔型数组
xarr = np.array([1.1,1.2,1.3,1.4,1.5])
yarr = np.array([2.1,2.2,2.3,2.4,2.5])
cond = np.array([True,False,True,True,False])根据布尔型数组中的值来选取xarr和yarr的值。
result = [(x if c else y) for x,y,c in zip(xarr,yarr,cond)]
上面的代码对大数组的处理速度不快,且无法用于多维数组,一般用np.where来代替。
result = np.where(cond,xarr,yarr)
![]()
第一个参数是布尔型数组,如果元素是True则选择参数二中的元素,False则选择参数三中的元素。
参数二和参数三可以是常数,如果参数一中的元素是True,就将对应的数组元素替换为参数二。
arr = np.random.randn(4,4) #创建一个四行四列的随即数组
np.where(arr > 0,2,-2) #如果元素大于0,则用2替换,否则用-2替换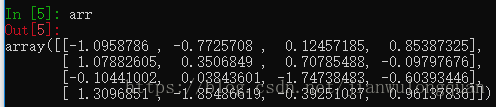

np.where(arr>0,2,arr) #将数组中大于0的元素用2替换,其他值不变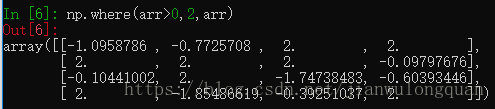
数学和统计方法
通过sum、mean、std(标准差)函数做聚合计算。
arr = np.random.randn(5,4) #创建一个五行四列的随即数组

可以接受一个axis选项参数,计算该轴向上的统计值。
arr.mean(axis=0) #计算列的均值
arr.mean(axis=1) #计算行的均值
cumsum函数是累积求和
arr = np.arange(10)
arr.cumsum()cumsum函数也可以传入axis参数,0表示列累积求和,1表示行累积求和。
arr = np.arange(20).reshape(5,4) #创建一个五行四列的二维数组
arr.cumsum(axis=0) #列累积求和
arr.cumsum(axis=1) #行累积求和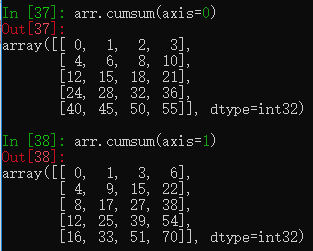
基本数组统计方法
sum,求和函数,可以对整个数组求和或者传入axis参数,对某个轴向求和。
mean,算术平均数函数。
std、var,标准差和方差函数,自由度可调。
min和max,求最大值和最小值。
argmin、argmax,最小值和最大值的索引。
cumsum、cumprod,累积和、累积积函数。
用于布尔型数组的方法
建立一个含100个随机数的数组,对其中大于0的数进行求和。
arr = np.random.randn(100)
(arr > 0).sum()![]()
any函数测试数组中是否存在一个或多个True,all函数测试数组中是否全都是True。
(arr > 0).any() #测试arr中是否存在大于0的数据
(arr > 0).all() #测试arr中是否全都是大于0的数据any和all也能用于非布尔型数组,所有非0元素都被视为True。
排序
通过sort函数可以进行就地排序
arr = np.random.randn(5)
arr.sort()![]()
多维数组通过传入axis对指定轴向数据进行排序,如二维数组,arr.sort(axis=1),表示按行排序。
如果不想就地修改,可以使用np.sort()方法,不要直接用数组的sort()方法。
唯一化以及其它的集合逻辑
unique函数可以筛选出数组中的唯一数据。
test = np.array(['a','a','b','b','c','c']) #创建带重复元素的数组
np.unique(test) #返回只含唯一值的数组
函数np.in1d用于测试一个数组中的元素是否在另一个数组中存在,返回一个布尔型数组。
values = np.array([6,0,0,3,2,5,6])
np.in1d(values,[2,3,6])![]()
![]()
集合函数补充
intersect1d(x,y),返回x和y的交集,并排序。
union1d(x,y),返回x和y的并集,并排序。
setdiff1d(x,y),返回y数组中没有,x数组中有的元素。
setxor1d(x,y),返回x和y非共同拥有的元素。
用于数组的文件输入输出
通过save函数,可以将数组保存在工作目录下,以后可以通过load函数进行调用。
arr = np.arange(10)
np.save('test',arr)
np.load('test.npy')![]()
savez可以将多个数组保存到一个文件中,数组要以关键字形式存入,调用时直接用变量
arr1 = np.arange(5)
arr2 = np.arange(6)
np.savez('test2',a=arr1,b=arr2)
arch = np.load('test2.npz')
arch['b']![]()
线性代数
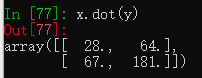
dot函数是矩阵乘法,设数组A结构为2X3的,数组B结构为3X4,那么np.dot(A,B)的结果是一个2X4的数组,np.dot(B,A)的结果是一个3X3的数组。
x = np.array([[1., 2., 3.], [4., 5., 6.]])
y = np.array([[6., 23.], [-1, 7], [8, 9]])
x.dot(y) #等价于np.dot(x,y)
如果dot处理的是两个一维数组,会得到两个数组的内积
a = np.arange(5)
np.dot(a,a)![]()
即0*0+1*1+2*2+3*3+4*4=30
如果np.dot(a,b),a是一个二维数组,b是一个一维数组,结果还是一维数组。
常用的numpy.linalg函数

伪随机数生成
使用numpy库中的random模块中的normal函数可以创建数据来自标准正态分布的数组。
samples = np.random.normal(size=(4,4))
这些随机数是通过算法获取的,基于随机数生成器种子,可以通过seed方法更改随机数生成种子。
np.random.seed(1234)以下是random模块中常用的函数


随机漫步
用random模块模拟随机产生1000个掷硬币结果,正面为+1,反面为-1
nsteps = 1000
draws = np.random.randint(0,2,size=nsteps) #在0和1之间随机取一个,取1000次,组成数组
steps = np.where(draws > 0,1,-1) #将数组中的0全部改为-1
walk = steps.cumsum() #对数组进行累积求和想知道第一次达到距离原点10步远时投掷了多少次
(np.abs(walk) >= 10).argmax()![]()
一次模拟多个随机漫步
nwalks = 5000
nsteps = 1000
draws = np.random.randint(0,2,size=(nwalks,nsteps)) #建立一个5000行,1000列的二维数组
steps = np.where(draws > 0,1,-1)
walks = steps.cumsum(1) #对每行进行累积求和想知道5000行中,最快到达距离原点30步的投掷次数,先看看5000次漫步中有多少次是到达了距离原点30的地方。
hits30 = (np.abs(walks) >= 30).any(1)![]()
有3380次漫步到达了30。
crossing_times = (np.abs(walks[hits30])>=30).argmax(1)![]()
第一次到达30需要投掷次数的数组。
![]()
通过min函数可以求出,最快的只需要投掷47次就能到达距离原点30的位置了。
此学习笔记主要内容出自:https://www.jianshu.com/p/a380222a3292