大数据与云计算 | Hadoop分布式集群搭建与HDFS、Hadoop、MapReduce常见操作
一、实验目的
- 熟悉Hadoop分布式集群的搭建过程
- 学习Hadoop分布式集群的使用示例
二、实验内容
- 搭建Hadoop分布式集群环境
- 掌握HDFS常见操作,自行编写一个英文文本文件,上传至HDFS中
- 使用Hadoop提供的example程序实现统计该文件的wordcount
- *自行编写实现wordcount功能的MapReduce程序
三、实验过程
3.1 虚拟机环境配置

3.1.1 从https://www.virtualbox.org下载并安装安装Oracle VM VirtualBox,新建一台Linux虚拟机,分配1024MB内存(master分配2048MB)、50GB虚拟硬盘(使用VDI映像,动态分配空间)
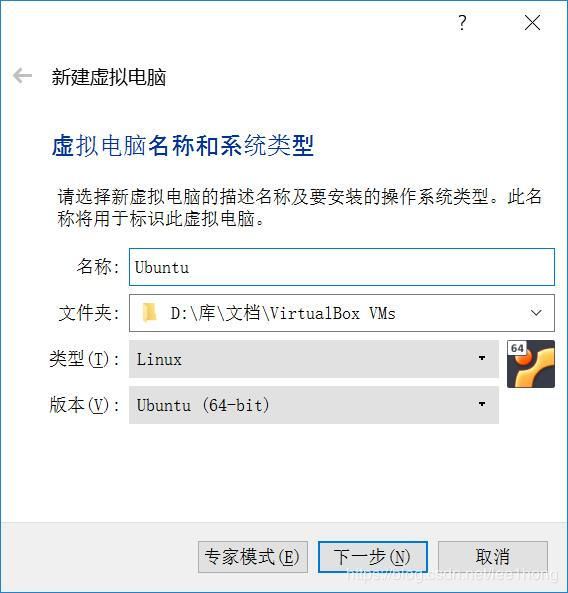
3.1.2 刚新建完成的虚拟机没有操作系统,为了兼顾稳定性和主机负载,我选用了桌面版Ubuntu 16.04(https://ubuntu.com/download/desktop),下载镜像后,在存储区挂载Ubuntu安装镜像的虚拟光盘后开机

3.1.3 根据安装程序的提示,在虚拟机中安装Ubuntu,按照默认设置安装即可,静等安装完成,安装完成后卸载ISO虚拟光驱

3.1.4为了便于后续的IP与MAC绑定操作,设置虚拟机的网络连接方式为“桥接网卡”,至此,虚拟机的配置大体完成

3.2 前置配置操作(上)
(为减轻重复配置的工作量,先配置一台虚拟机,配置完成后克隆出三台虚拟机,然后配置虚拟机之间不同部分)
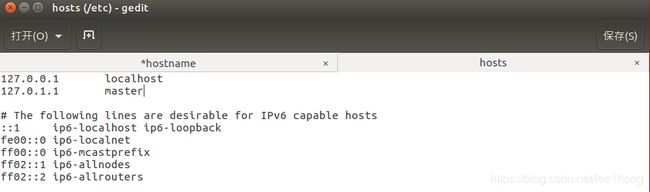
3.2.1 编辑hostname文件,将第一台虚拟机命名为master,保存

3.2.2 编辑hosts文件,修改127.0.1.1的名称为master,保存
3.2.3 安装ssh并配置SSH免密登录
- 打开终端,运行sudo apt-get install openssh-server,安装ssh
- 运行sudo ufw disable,关闭防火墙
- 运行ssh-keygen –t rsa,一直回车,设置密码为空,直至出现RSA密钥
- 运行cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys,将公钥追加到“authorized_keys”文件
- 设定文件权限:chmod 600 .ssh/authorized_keys
- 运行ssh localhost,如出现下图界面,说明配置成功

3.2.4 安装JDK和Hadoop
- 运行sudo apt-get install openjdk-8-jdk,完成JDK的安装
- 从https://hadoop.apache.org/下载Hadoop 2.10.0,下载完成后解压,移动到“/usr/local”目录下,重命名文件夹名为hadoop

jdk安装界面
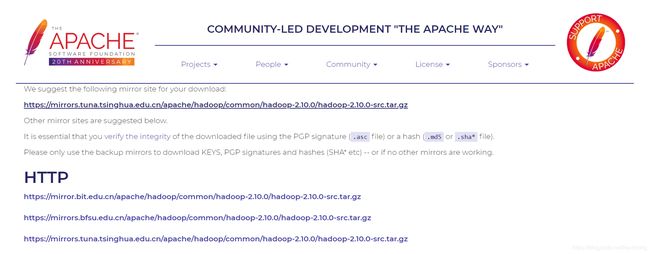
Hadoop下载页面

Hadoop安装目录
3.2.5 配置JDK与Hadoop的系统环境变量
需要修改配置文件/etc/profile,添加Java和Hadoop的环境变量
- export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
- export PATH=$JAVA_HOME/bin:$PATH
- export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- export HADOOP_HOME=/usr/local/hadoop
- export PATH=$PATH:$HADOOP_HOME/bin
保存后运行“source /etc/profile”指令使刚刚的配置立即生效

3.2.6 配置Hadoop相关配置文件
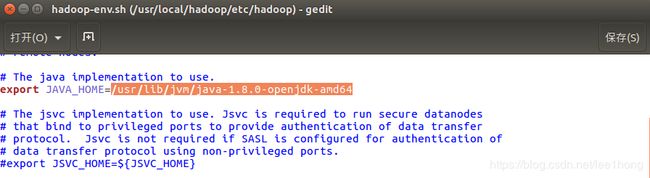
3.2.6.1 修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh,配置JDK路径为:
“/usr/lib/jvm/java-1.8.0-openjdk-amd64”
3.2.6.2 修改/usr/local/hadoop/etc/hadoop/core-site.xml —— HDFS默认地址和Web UI配置
-
-
hadoop.tmp.dir -
file:/usr/local/hadoop/tmp -
Abase for other temporary directories. -
-
fs.defaultFS -
hdfs://master:9000

3.2.6.3 修改/usr/local/hadoop/etc/hadoop/hdfs-site.xml —— HDFS副本
-
-
dfs.replication -
3 -
-
dfs.name.dir -
/usr/local/hadoop/hdfs/name -
-
dfs.data.dir -
/usr/local/hadoop/hdfs/data -
-
yarn.nodemanager.aux-services -
mapreduce_shuffle -
-
yarn.resourcemanager.hostname -
master

3.2.6.6 修改/usr/local/hadoop/etc/hadoop/slaves,添加以下内容(即hostname文件中要设置的主机名):
- data1
- data2
- data3
3.3 克隆虚拟机
将虚拟机复制3份,重新生成MAC地址,使用“完全复制”,作为从机

VM VirtualBox中的四台虚拟机,全部启动

虚拟机全部启动后,系统资源使用情况
3.4 前置配置操作(下)
3.4.1 使用ifconfig命令查询每一台虚拟机的IP地址
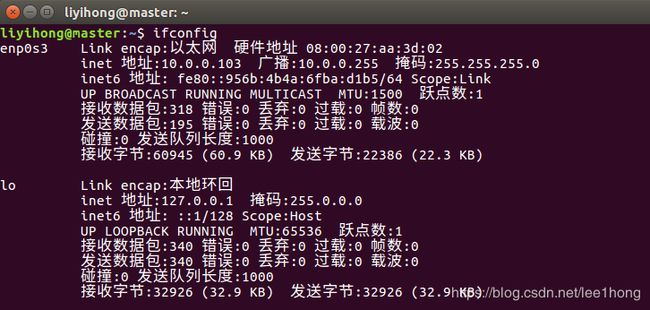
经查询,master的IP地址为10.0.0.103,三台从机的IP地址为10.0.0.104、10.0.105、10.0.107
3.4.2 编辑hostname文件,将三台从机分别命名为data1、data2、data3,保存

3.4.3 编辑hosts文件,修改127.0.1.1的名称为本机的hostname,加入四个IP地址对应虚拟机的host,保存

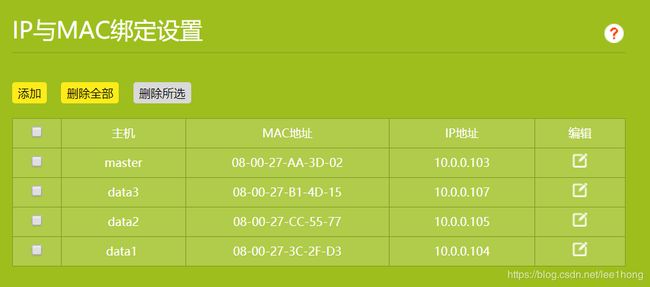
3.4.4 为了避免各虚拟机的内网IP地址发生变化,在路由器设置界面将IP与MAC地址绑定,或将DHCP地址租期设置为最大值,以免反复调整hosts文件

3.4.5 ssh免密登录配置
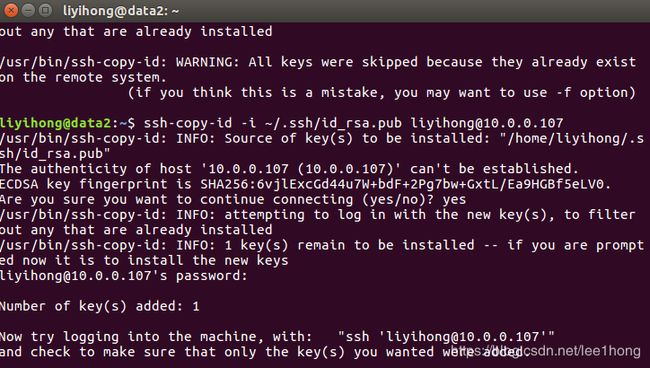
把自己的密钥拷贝到需要免密的机器上,对每台虚拟机执行以下命令:
ssh-copy-id -i ~/.ssh/id_rsa.pub 用户名@IP地址【注意是用户名,不是主机名!】
3.5 启动Hadoop
3.5.1 启动HDFS
3.5.1.1 格式化文件系统:在master的/usr/local/hadoop目录运行以下命令:
- bin/hdfs namenode –format

3.5.1.2 开启HDFS
在master的/usr/local/hadoop目录运行以下命令:
sbin/start-all.sh
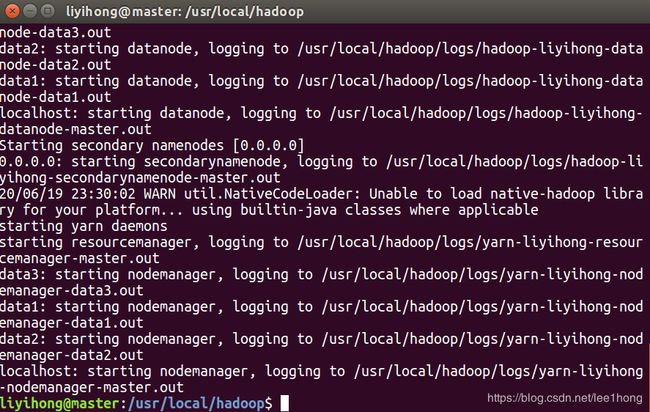
出现上图所示界面,Hadoop启动成功
3.6 上传一个文件至HDFS
- 在hadoop目录下新建一个文本文件,填充英文文本,命名为U201717126.txt,执行以下命令:hadoop fs -copyFromLocal U201717126.txt /dest
- 执行命令hadoop fs -ls /dest,显示相应的文件,表明上传成功

3.7 使用example程序统计文件wordcount
- 输入命令: hadoop jar usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /dest /out
- 在虚拟机中打开http://master:8088,可以看到wordcount正在运行

静等其运行完成:

从localhost:50070/explorer.html打开hadoop的文件浏览器,在out文件夹下有_SUCCESS和part-r-00000两个文件
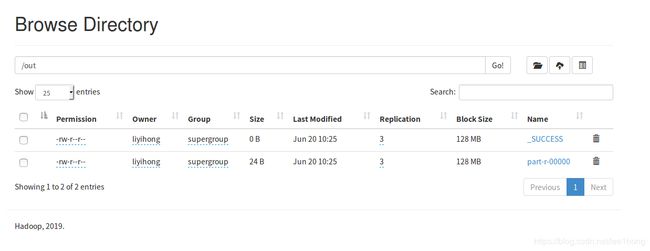
下载part-r-00000文件并打开,词频统计与文档U201717126.txt内容一致

3.8 编写实现wordcount功能的MapReduce程序(选做)
3.8.1 编写WordMain.java:
- package wordcount;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class WordMain {
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- // Configuration类:读取配置文件内容-core-site.xml
- Configuration conf = new Configuration();
- // 读取命令行参数,并设置到conf
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- // 添加内容
- conf.set("fs.defaultFS", "hdfs://10.13.7.72:9000");
- conf.set("hadoop.job.user", "hadoop");
- conf.set("mapreduce.framework.name", "yarn");
- conf.set("mapreduce.jobtracker.address", "10.13.7.72:9001");
- conf.set("yarn.resourcemanager.hostname", "10.13.7.72");
- conf.set("yarn.resourcemanager.admin.adress", "10.13.7.72:8033");
- conf.set("yarn.resourcemanager.adress", "10.13.7.72:8032");
- conf.set("yarn.resourcemanager.resource-tracker.address", "10.13.7.72:8036");
- conf.set("yarn.resourcemanager.scheduler.address", "10.13.7.72:8030");
- if (otherArgs.length != 2) { // 输入目录 输出目录
- System.err.println("Usage: wordcount
" - System.exit(2);
- }
- Job job = new Job(conf, "word count"); // 新建一个job
- job.setJar("wordcount.jar");
- job.setJarByClass(WordMain.class); // 设置主类
- job.setMapperClass(WordMapper.class); // 设置Mapper类
- job.setCombinerClass(WordReducer.class); // 设置作业合成类
- job.setReducerClass(WordReducer.class); // 设置Reducer类
- job.setOutputKeyClass(Text.class); // 设置输出数据的关键类
- job.setOutputValueClass(IntWritable.class); // 设置输出值类
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
3.8.2 编写WordMapper.java:
- package wordcount;
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Mapper;
- public class WordMapper extends Mapper
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- // Mapper类的核心方法
- /**
- * key 首字符偏移量
- * value 文件的一行内容
- * context Mapper端的上下文
- * @throws InterruptedException
- * @throws IOException
- */
- public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
3.8.3 编写WordReducer.java:
- package wordcount;
- import java.io.IOException;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Reducer;
- public class WordReducer extends Reducer
- private IntWritable result = new IntWritable(); // 记录词的频数
- // Reducer抽象类的核心方法
- public void reduce (Text key, Iterable
values, Context context) throws IOException, InterruptedException { - int sum = 0;
- // 遍历values 将 list
- for (IntWritable value : values) {
- sum += value.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
3.8.4 将Java程序打包为my_wordcount.jar,置于hadoop目录,运行:
hadoop my_wordcount.jar wordcount.WordMain /U201717126.txt /out2

出现上图界面,顺利运行完成

在hadoop中的out2文件夹生成了两个文件

下载part-r-00000文件并打开,词频统计与文档U201717126.txt内容一致

(U201717126.txt的文件内容)
四、实验结果
- 完成Hadoop分布式集群环境搭建
- 完成编写一个英文文本文件,上传至HDFS中
- 完成用Hadoop提供的example程序实现统计该文件的wordcount
- 自行编写实现wordcount功能的MapReduce程序并运行成功
五、体会
通过本次实验,我对Hadoop分布式集群、HDFS分布式存储、MapReduce分布式计算、Yarn资源调度有了更深刻的理解,掌握了Hadoop分布式集群环境搭建、HDFS文件的操作与MapReduce分布式计算程序的编译运行,对大数据与云计算的功能与原理有了进一步的了解。