克鲁斯卡尔算法
克鲁斯卡尔算法
问题引入
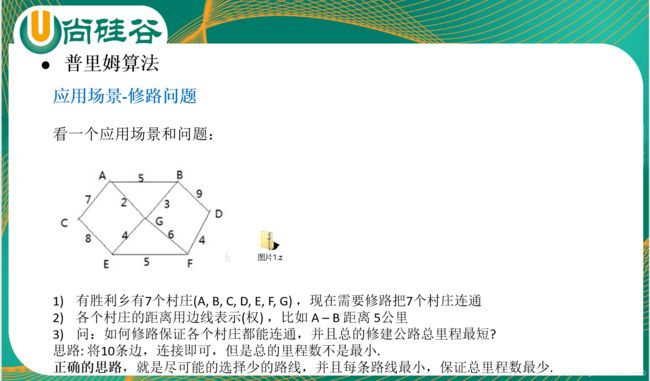
可以看出,普利姆算法和克鲁斯卡尔算法要解决的问题是同一类的的问题。
- 有几个顶点。
- 顶点之间通过有向边或者无向边连接
- 顶点之间的权重不同。
求,如何修路保证各个村庄都能连通,并且总的修建公路里程最短。
核心的想法,就是尽可能选择少的路线,并且每条路线最小,保证总里程数最少。
简介
克鲁斯卡尔Kruskal算法是求最小支撑树问题的另外一种常用算法。在实践过程中,普利姆算法适用于求稀疏网络的最小支撑树。算法思想如下:
设连通图为N=(V,E C), T为N的最小支撑树,。初始时,T = {V, ∅},即T 中没有边,只有n个顶点,显然,这n个顶点就是n个连通分量。克鲁斯卡尔算法的基本步骤如下:
- 在E中选择权值最小的两个边,并将此边从E中删除
- 如果此边的两个顶点在T的不同的连通分量中,则将此边加入到T中,从而导致T中减少一个连通分量。
- 重复执行前两个步骤,直至T中仅剩下一个连通分量。
在学习中,也可以通过如下的通俗的说法来理解克鲁斯卡尔算法

最小支撑树的概念如下图:


图解过程

代码实现
关键点阐述
从上面的行文中,可以看到,在克鲁斯卡尔的实现过程中,有两个比较重要的关键点
- 对图中的所有边进行排序,并选择最小的n-1条边。
- 每次选择的边要在新生成的最小生成树中不构成回路,即两个顶点在T中不同的连通分量。
连通分量的概念如下:
设G是图,若存在一条从顶点vi到到vj的路径,则称vi与vj可连通。若G为无向图,且V(G)中任意两顶点都可及,则称G为连通图。
边排序
首先,排序的实现较为简单。我们可以通过以下任何的排序算法实现:
- 交换排序
- 冒泡排序
- 堆排序
- 选择排序
- 插入排序
- 直接插入排序
- 希尔排序
等排序算法实现。
不构成回路
即选择的边两个顶点不在T中的相同的联通分量中

思路1:
- 由于构建的最小支撑树T在不断的增加边,生成的T也是一个图。这样在新加的边的两个顶点,假如说是a和b两个顶点,那么我们可以对于T这个图对两个顶点进行判断,通过深度优先判断两个点是否可以通过一个点访问另外一个点,如果可以访问,那么就说明两个顶点在在同一个连通分量,即构成了回路
- 记录顶点在“最小生成树”中的终点,顶点的终点是在“最小生成树中与它连通的最大顶点”。然后每次需要将一条边添加到最小生成树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。
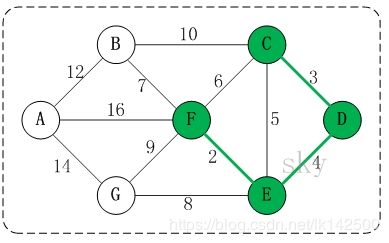
在将
(01) C的终点是F。
(02) D的终点是F。
(03) E的终点是F。
(04) F的终点是F。
关于终点的说明:
- 就是将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是"与它连通的最大顶点"。
- 因此,接下来,虽然
这个方式较为简单。实现起来也容易。
代码实现
完整代码实现
下述类型EdgeData抽象的是图中存在的边。包含起点,终点和权重。
package com.atguigu.graph.graph;
/**
* 边实例, 该元素的对象保存了一条边,包括权重,起点,终点
*
* @author songquanheng
* 2020/7/2-21:31
*/
public class EdgeData implements Comparable<EdgeData> {
private int start;
private int end;
private int cost;
EdgeData(int start, int end, int cost) {
this.start = start;
this.end = end;
this.cost = cost;
}
int getStart() {
return start;
}
int getEnd() {
return end;
}
int getCost() {
return cost;
}
@Override
public int compareTo(EdgeData o) {
return this.cost - o.cost;
}
@Override
public String toString() {
return "EdgeData{" +
"start=" + start +
", end=" + end +
", cost=" + cost +
'}';
}
}
主干程序如下:
package com.atguigu.graph.graph;
import java.util.*;
/**
* 使用邻接矩阵实现图类
*
* @author songquanheng
* @Time: 2020/6/20-11:32
*/
public class Graph {
/**
* 顶点数组
*/
private String[] vertexs;
private int numberOfVertex;
/**
* 边数
*/
private int numberOfEdges;
/**
* 边集合,采用二维数组表示
*/
private int[][] edges;
public static void main(String[] args) {
String[] vertices = "A B C D E F G".split(" ");
Graph graph = new Graph(vertices);
graph.show();
graph.insertEdge(0, 1, 5);
graph.insertEdge(0, 2, 7);
graph.insertEdge(0, 6, 2);
graph.insertEdge(1, 6, 3);
graph.insertEdge(1, 3, 9);
graph.insertEdge(2, 4, 8);
graph.insertEdge(3, 5, 4);
graph.insertEdge(4, 5, 5);
graph.insertEdge(4, 6, 4);
graph.insertEdge(5, 6, 6);
graph.show();
MinTree minTree = graph.prim(0);
minTree.show();
System.out.println("minTree.getMinWeight() = " + minTree.getMinWeight());
MinTree minTree2 = graph.prim2(0);
minTree.show();
System.out.println("minTree2.getMinWeight() = " + minTree2.getMinWeight());
List<EdgeData> kruskal = graph.kruscal();
System.out.println(kruskal);
System.out.println("kruskal.stream().mapToInt(EdgeData::getCost).sum() = " + kruskal.stream().mapToInt(EdgeData::getCost).sum());
}
public List<EdgeData> kruscal() {
// 排序
List<EdgeData> edgeDataCollection = getEdges();
Collections.sort(edgeDataCollection);
System.out.println("edgeDataCollection.size() = " + edgeDataCollection.size());
System.out.println(edgeDataCollection);
// 用来保存每个顶点的终点, 初始化均为0
int[] destinations = new int[getNumberOfVertex()];
List<EdgeData> result = new ArrayList<>();
// 当结果中的边数小于顶点数-1,继续循环
while (result.size() < getNumberOfVertex() - 1) {
EdgeData leastCostEdge = edgeDataCollection.remove(0);
// 如果未构成回环,则该边应该加入最小支撑树
int m = getEnd(leastCostEdge.getStart(), destinations);
int n = getEnd(leastCostEdge.getEnd(), destinations);
if (m != n) {
result.add(leastCostEdge);
destinations[m] = n;
}
}
return result;
}
/**
* 返回尝试假如的边是否构成回环
* @param destinations 辅助数组
* @param leastCostEdge 新尝试加入的最小权重的边
* @return 返回尝试假如的最小边是否构成回环
*/
private boolean isLoop(int[] destinations, EdgeData leastCostEdge) {
int startDestination = getEnd(leastCostEdge.getStart(), destinations);
int endDestination = getEnd(leastCostEdge.getEnd(), destinations);
return startDestination == endDestination;
}
/**
* @param vertexIndex 顶点索引
* @param destinations 保存每个顶点的终点
* @return 返回顶点vertexIndex的终点的索引
*/
private int getEnd(int vertexIndex, int[] destinations) {
int i = vertexIndex;
while (destinations[i] != 0) {
i = destinations[i];
}
return i;
}
/**
* @return 返回图形中的所有边
*/
List<EdgeData> getEdges() {
List<EdgeData> result = new ArrayList<EdgeData>();
for (int i = 0; i < numberOfVertex; i++) {
for (int j = i + 1; j < numberOfVertex; j++) {
if (edges[i][j] == Integer.MAX_VALUE) {
continue;
}
EdgeData edgeData = new EdgeData(i, j, edges[i][j]);
result.add(edgeData);
}
}
return result;
}
/**
* @param vertex 通过普利姆算法获取最小支撑树的开始顶点
* @return 获取最小支撑树
*/
public MinTree prim(int vertex) {
MinTree minTree = new MinTree(numberOfVertex);
// 1. 初始化邻接矩阵 ,当图已经得到良好的初始化了之后,邻接矩阵未初始化的边默认未0
for (int i = 0; i < numberOfVertex; i++) {
for (int j = 0; j < numberOfVertex; j++) {
if (edges[i][j] == 0) {
edges[i][j] = Integer.MAX_VALUE;
}
}
}
show();
// 2. 初始化closedge数组, 以顶点vertex未初始顶点,初始化数组closedge
MinEdge[] closedge = new MinEdge[numberOfVertex];
for (int i = 0; i < numberOfVertex; i++) {
// 设置了每个顶点到已访问顶点vertex的距离
closedge[i] = new MinEdge(vertex, edges[i][vertex]);
}
closedge[vertex].setVertex(-1);
closedge[vertex].setLowcost(0);
// 3. 构造图的最小支撑树
// 循环n-1次,获取n-1条最小的边
for (int i = 0; i < numberOfVertex - 1; i++) {
int minCost = Integer.MAX_VALUE;
// 未访问的目标顶点索引,其与lowcost[unAccessedTargetVertexIndex].getVertex()构成了未访问顶点集合到已访问顶点集合的最短边
int unAccessedTargetVertexIndex = -1;
for (int j = 0; j < numberOfVertex; j++) {
// 采用选择排序获取未访问顶点到已访问顶点的最小值。第一次循环是找出各个顶点到vertex顶点的距离的最小值
if (closedge[j].getVertex() != -1 && closedge[j].getLowcost() < minCost) {
minCost = closedge[j].getLowcost();
// 寻找最短边的位置序号,不断更新直到找到一个最小的。
unAccessedTargetVertexIndex = j;
}
}
// 如果在执行了通过选择排序查找未访问顶点集合到已访问顶点集合的最短边和顶点信息之后,查找的unAccessedTargetVertexIndex为-1表示未查找到有效的顶点
assert unAccessedTargetVertexIndex != -1;
MSTEdge edge = new MSTEdge(unAccessedTargetVertexIndex, closedge[unAccessedTargetVertexIndex].getVertex(), minCost);
minTree.addMstEdge(edge);
// 把找到的未访问顶点标记为已经访问
closedge[unAccessedTargetVertexIndex].setVertex(-1);
closedge[unAccessedTargetVertexIndex].setLowcost(0);
for (int j = 0; j < numberOfVertex; j++) {
// j代表未访问顶点, unAccessedTargetVertexIndex代表已经访问的新的顶点。
// 主要是为了更新,最新的顶点加入到已经访问的集合对未访问的顶点集合的影响。
// 采用选择排序获取未访问顶点到已访问顶点的最小值。第一次循环是找出各个顶点到vertex顶点的距离的最小值
if (closedge[j].getVertex() != -1 && edges[j][unAccessedTargetVertexIndex] < closedge[j].getLowcost()) {
closedge[j].setLowcost(edges[j][unAccessedTargetVertexIndex]);
closedge[j].setVertex(unAccessedTargetVertexIndex);
}
}
}
return minTree;
}
/**
* 通过普利姆算法获取图形的最小支撑树
*
* @param vertex 普利姆算法的起始顶点
* @return 返回当前图形的最小支撑树,注意:这要求当前图形是连通图
*/
public MinTree prim2(int vertex) {
boolean[] visited = new boolean[numberOfVertex];
Arrays.fill(visited, false);
// 表示vertex结点已经加入最小支撑树
visited[vertex] = true;
MinTree minTree = new MinTree(numberOfVertex);
// 感觉这个过程还是不太好理解。
// 注意选择排序的运用
while (minTree.numberOfMstEdge() < numberOfVertex - 1) {
MSTEdge edge = getShortestEdge(visited);
minTree.addMstEdge(edge);
visited[edge.getEnd()] = true;
}
return minTree;
}
/**
* 获取已访问顶点和未访问顶点之间相连的最短边
*
* @param visited 辅助遍历数组
* @return 获取最短边,一端是已经访问的点,一端是未访问的顶点。通过遍历求出最短的边
*/
private MSTEdge getShortestEdge(boolean[] visited) {
int minWeight = Integer.MAX_VALUE;
int minStart = Integer.MAX_VALUE;
int minEnd = Integer.MAX_VALUE;
// i 表示已经访问过的集合中的顶点
for (int i = 0; i < numberOfVertex; i++) {
// 表示未访问的顶点集合中的顶点
for (int j = 0; j < numberOfVertex; j++) {
if (visited[i] && !visited[j] && edges[i][j] < minWeight) {
minWeight = edges[i][j];
minStart = i;
minEnd = j;
}
}
}
return new MSTEdge(minStart, minEnd, minWeight);
}
public Graph(String[] vertexs) {
numberOfVertex = vertexs.length;
this.vertexs = new String[numberOfVertex];
int i = 0;
for (String item : vertexs) {
this.vertexs[i++] = item;
}
// 初始化邻接矩阵
this.edges = new int[numberOfVertex][numberOfVertex];
}
public void show() {
System.out.println("Graph.show");
System.out.println(Arrays.toString(vertexs));
System.out.println();
for (int[] row : edges) {
System.out.println(Arrays.toString(row));
}
System.out.println("graph.getNumberOfEdges() = " + getNumberOfEdges());
System.out.println("graph.getNumberOfVertex() = " + getNumberOfVertex());
System.out.println();
}
/**
* @param v1 边的起点的序号
* @param v2 边的终点的序号
* @param w 边的权值 无向图赋值为1即可
*/
public void insertEdge(int v1, int v2, int w) {
assert v1 != v2;
edges[v1][v2] = w;
edges[v2][v1] = w;
numberOfEdges++;
}
/**
* 深度优先遍历,此时不考虑起始点,即以0号序列的顶点为起始顶点
*/
public void dfs() {
System.out.println("Graph.dfs");
boolean[] visited = new boolean[numberOfVertex];
Arrays.fill(visited, false);
for (int i = 0; i < numberOfVertex; i++) {
if (!visited[i]) {
dfs(i, visited);
}
}
System.out.println();
}
/**
* 从指定顶点进行深度优先遍历
*
* @param vertex 开始顶点的序号
*/
public void dfs(int vertex) {
boolean[] visited = new boolean[numberOfVertex];
Arrays.fill(visited, false);
dfs(vertex, visited);
System.out.println();
}
/**
* @param vertex 深度优先遍历的开始顶点所在的序号
*/
private void dfs(int vertex, boolean[] visited) {
System.out.print(vertexs[vertex] + "->");
visited[vertex] = true;
int w = getFirstNeighbour(vertex);
while (w != -1) {
if (!visited[w]) {
dfs(w, visited);
} else {
// 如果w已经被访问过,则访问w的下一个邻接顶点
w = getNextNeighbour(vertex, w);
}
}
}
/**
* 广度优先遍历
*/
public void bfs() {
System.out.println("Graph.bfs");
boolean[] visited = new boolean[numberOfVertex];
Arrays.fill(visited, false);
for (int i = 0; i < numberOfVertex; i++) {
if (!visited[i]) {
bfs(i, visited);
}
}
}
/**
* 从指定顶点vertex开始进行广度优先遍历
*
* @param vertex 从vertex顶点开始进行广度优先遍历
*/
public void bfs(int vertex) {
boolean[] visited = new boolean[numberOfVertex];
Arrays.fill(visited, false);
bfs(vertex, visited);
}
/**
* 从顶点vertex开始进行广度优先遍历
*
* @param vertex 顶点序号
* @param visited 辅助遍历数组
*/
private void bfs(int vertex, boolean[] visited) {
System.out.print(vertexs[vertex] + "->");
visited[vertex] = true;
LinkedList<Integer> queue = new LinkedList<>();
queue.addLast(vertex);
while (!queue.isEmpty()) {
// 此时head所在的顶点已经访问过了
int head = queue.remove();
int w = getFirstNeighbour(head);
while (w != -1) {
if (!visited[w]) {
// 深度优先遍历从此处开始递归,但广度优先不进行递归
System.out.print(vertexs[w] + "->");
visited[w] = true;
queue.addLast(w);
}
w = getNextNeighbour(head, w);
}
}
}
/**
* 返回序号为vertex的第一个邻接顶点的序号
*
* @param vertex 顶点的序号,对于A顶点,则传入的vertex为A顶点所在的序号0
* @return 返回该顶点的第一个邻接顶点所在的序号, 如果存在,返回顶点所在的序号,否则返回-1表示不存在
*/
public int getFirstNeighbour(int vertex) {
return neighbour(vertex, 0);
}
/**
* 返回序号为vertex的顶点相对于序号为currentAdjacentVertex的顶点的下一个邻接顶点的序号
*
* @param vertex 顶点序号
* @param currentAdjacentVertex currentAdjacentVertex为vertex序号顶点的邻接点,求相对于这个currentAdjacentVertex的下一个邻接顶点的序号
* @return 返回下一个邻接顶点的序号
*/
public int getNextNeighbour(int vertex, int currentAdjacentVertex) {
return neighbour(vertex, currentAdjacentVertex + 1);
}
/**
* 从firstSearchLocation查找获取顶点vertex序号的顶点的邻接点的序号,
*
* @param vertex 顶点序号
* @param firstSearchIndex 查找位置值的范围为[0, numberOfVertex - 1]
* @return 如果从firstSearchIndex开始查找存在返回邻接顶点,则返回邻接顶点的序号,否则返回1
*/
private int neighbour(int vertex, int firstSearchIndex) {
for (int i = firstSearchIndex; i < numberOfVertex; i++) {
if (edges[vertex][i] > 0) {
return i;
}
}
return -1;
}
public int getNumberOfEdges() {
return numberOfEdges;
}
public int getNumberOfVertex() {
return numberOfVertex;
}
}
class MinTree {
ArrayList<MSTEdge> mstEdges;
public MinTree(int numberOfVertex) {
mstEdges = new ArrayList<>(numberOfVertex - 1);
}
public void show() {
System.out.println("MinTree.show");
System.out.println("最小支撑树如下所示:");
mstEdges.stream()
.forEach(System.out::println);
}
public void addMstEdge(MSTEdge mstEdge) {
mstEdges.add(mstEdge);
}
public int numberOfMstEdge() {
return mstEdges.size();
}
/**
* @return 返回最小支撑树的最小权重
*/
public int getMinWeight() {
return mstEdges.stream()
.mapToInt(edge -> edge.getWeight())
.sum();
}
}
/**
* 最小支撑树的边类
*/
class MSTEdge {
int start;
int end;
int weight;
public MSTEdge(int start, int end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public String toString() {
return "MSTEdge{" +
"start=" + start +
", end=" + end +
", weight=" + weight +
'}';
}
public int getEnd() {
return end;
}
public int getWeight() {
return weight;
}
}
/**
* 刘大有 普利姆算法实现
*/
class MinEdge {
/**
* vertex顶点,含义是已访问的顶点序号
*/
private int vertex;
/**
* 某个未访问顶点到vertex顶点所需要的最短的开销
*/
private int lowcost;
public int getVertex() {
return vertex;
}
public void setVertex(int vertex) {
this.vertex = vertex;
}
public int getLowcost() {
return lowcost;
}
public void setLowcost(int lowcost) {
this.lowcost = lowcost;
}
public MinEdge(int vertex, int lowcost) {
this.vertex = vertex;
this.lowcost = lowcost;
}
}
算法执行结果
Graph.show
[A, B, C, D, E, F, G]
[0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0]
graph.getNumberOfEdges() = 0
graph.getNumberOfVertex() = 7
Graph.show
[A, B, C, D, E, F, G]
[0, 5, 7, 0, 0, 0, 2]
[5, 0, 0, 9, 0, 0, 3]
[7, 0, 0, 0, 8, 0, 0]
[0, 9, 0, 0, 0, 4, 0]
[0, 0, 8, 0, 0, 5, 4]
[0, 0, 0, 4, 5, 0, 6]
[2, 3, 0, 0, 4, 6, 0]
graph.getNumberOfEdges() = 10
graph.getNumberOfVertex() = 7
Graph.show
[A, B, C, D, E, F, G]
[2147483647, 5, 7, 2147483647, 2147483647, 2147483647, 2]
[5, 2147483647, 2147483647, 9, 2147483647, 2147483647, 3]
[7, 2147483647, 2147483647, 2147483647, 8, 2147483647, 2147483647]
[2147483647, 9, 2147483647, 2147483647, 2147483647, 4, 2147483647]
[2147483647, 2147483647, 8, 2147483647, 2147483647, 5, 4]
[2147483647, 2147483647, 2147483647, 4, 5, 2147483647, 6]
[2, 3, 2147483647, 2147483647, 4, 6, 2147483647]
graph.getNumberOfEdges() = 10
graph.getNumberOfVertex() = 7
MinTree.show
最小支撑树如下所示:
MSTEdge{start=6, end=0, weight=2}
MSTEdge{start=1, end=6, weight=3}
MSTEdge{start=4, end=6, weight=4}
MSTEdge{start=5, end=4, weight=5}
MSTEdge{start=3, end=5, weight=4}
MSTEdge{start=2, end=0, weight=7}
minTree.getMinWeight() = 25
MinTree.show
最小支撑树如下所示:
MSTEdge{start=6, end=0, weight=2}
MSTEdge{start=1, end=6, weight=3}
MSTEdge{start=4, end=6, weight=4}
MSTEdge{start=5, end=4, weight=5}
MSTEdge{start=3, end=5, weight=4}
MSTEdge{start=2, end=0, weight=7}
minTree2.getMinWeight() = 25
edgeDataCollection.size() = 10
[EdgeData{start=0, end=6, cost=2}, EdgeData{start=1, end=6, cost=3}, EdgeData{start=3, end=5, cost=4}, EdgeData{start=4, end=6, cost=4}, EdgeData{start=0, end=1, cost=5}, EdgeData{start=4, end=5, cost=5}, EdgeData{start=5, end=6, cost=6}, EdgeData{start=0, end=2, cost=7}, EdgeData{start=2, end=4, cost=8}, EdgeData{start=1, end=3, cost=9}]
[EdgeData{start=0, end=6, cost=2}, EdgeData{start=1, end=6, cost=3}, EdgeData{start=3, end=5, cost=4}, EdgeData{start=4, end=6, cost=4}, EdgeData{start=4, end=5, cost=5}, EdgeData{start=0, end=2, cost=7}]
kruskal.stream().mapToInt(EdgeData::getCost).sum() = 25
代码剖析
主干代码
与克鲁斯卡尔算法实现的主干代码为:
/**
* 返回最小支撑树
*
* @return 最小支撑树的组成的边
*/
public List<EdgeData> kruscal() {
// 排序
List<EdgeData> edgeDataCollection = getEdges();
Collections.sort(edgeDataCollection);
System.out.println("edgeDataCollection.size() = " + edgeDataCollection.size());
System.out.println(edgeDataCollection);
// 用来保存每个顶点的终点, 初始化均为0
int[] destinations = new int[getNumberOfVertex()];
List<EdgeData> result = new ArrayList<>();
// 当结果中的边数小于顶点数-1,继续循环
while (result.size() < getNumberOfVertex() - 1) {
EdgeData leastCostEdge = edgeDataCollection.remove(0);
// 如果未构成回环,则该边应该加入最小支撑树
int m = getEnd(leastCostEdge.getStart(), destinations);
int n = getEnd(leastCostEdge.getEnd(), destinations);
if (m != n) {
result.add(leastCostEdge);
destinations[m] = n;
}
}
return result;
}
获取所有边由函数getEdges()实现
/**
* @return 返回图形中的所有边
*/
List<EdgeData> getEdges() {
List<EdgeData> result = new ArrayList<EdgeData>();
for (int i = 0; i < numberOfVertex; i++) {
for (int j = i + 1; j < numberOfVertex; j++) {
if (edges[i][j] == Integer.MAX_VALUE) {
continue;
}
EdgeData edgeData = new EdgeData(i, j, edges[i][j]);
result.add(edgeData);
}
}
return result;
}
边排序
package com.atguigu.graph.graph;
/**
* 边实例, 该元素的对象保存了一条边,包括权重,起点,终点
*
* @author songquanheng
* @Time: 2020/7/2-21:31
*/
public class EdgeData implements Comparable<EdgeData> {
private int start;
private int end;
private int cost;
public EdgeData(int start, int end, int cost) {
this.start = start;
this.end = end;
this.cost = cost;
}
public int getStart() {
return start;
}
public int getEnd() {
return end;
}
public int getCost() {
return cost;
}
@Override
public int compareTo(EdgeData o) {
return this.cost - o.cost;
}
@Override
public String toString() {
return "EdgeData{" +
"start=" + start +
", end=" + end +
", cost=" + cost +
'}';
}
}
EdgeData实现了Comparable接口,该接口在添加到List中,可以调用sort,自然实现排序。
package java.lang;
import java.util.*;
/**
* This interface imposes a total ordering on the objects of each class that
* implements it. This ordering is referred to as the class's natural
* ordering, and the class's compareTo method is referred to as
* its natural comparison method.
*
* Lists (and arrays) of objects that implement this interface can be sorted
* automatically by {@link Collections#sort(List) Collections.sort} (and
* {@link Arrays#sort(Object[]) Arrays.sort}). Objects that implement this
* interface can be used as keys in a {@linkplain SortedMap sorted map} or as
* elements in a {@linkplain SortedSet sorted set}, without the need to
* specify a {@linkplain Comparator comparator}.
*
* The natural ordering for a class C is said to be consistent
* with equals if and only if e1.compareTo(e2) == 0 has
* the same boolean value as e1.equals(e2) for every
* e1 and e2 of class C. Note that null
* is not an instance of any class, and e.compareTo(null) should
* throw a NullPointerException even though e.equals(null)
* returns false.
*
* It is strongly recommended (though not required) that natural orderings be
* consistent with equals. This is so because sorted sets (and sorted maps)
* without explicit comparators behave "strangely" when they are used with
* elements (or keys) whose natural ordering is inconsistent with equals. In
* particular, such a sorted set (or sorted map) violates the general contract
* for set (or map), which is defined in terms of the equals
* method.
*
* For example, if one adds two keys a and b such that
* {@code (!a.equals(b) && a.compareTo(b) == 0)} to a sorted
* set that does not use an explicit comparator, the second add
* operation returns false (and the size of the sorted set does not increase)
* because a and b are equivalent from the sorted set's
* perspective.
*
* Virtually all Java core classes that implement Comparable have natural
* orderings that are consistent with equals. One exception is
* java.math.BigDecimal, whose natural ordering equates
* BigDecimal objects with equal values and different precisions
* (such as 4.0 and 4.00).
*
* For the mathematically inclined, the relation that defines
* the natural ordering on a given class C is:
* {(x, y) such that x.compareTo(y) <= 0}.
* The quotient for this total order is:
* {(x, y) such that x.compareTo(y) == 0}.
*
*
* It follows immediately from the contract for compareTo that the
* quotient is an equivalence relation on C, and that the
* natural ordering is a total order on C. When we say that a
* class's natural ordering is consistent with equals, we mean that the
* quotient for the natural ordering is the equivalence relation defined by
* the class's {@link Object#equals(Object) equals(Object)} method:
* {(x, y) such that x.equals(y)}.
*
* This interface is a member of the
*
* Java Collections Framework.
*
* @param the type of objects that this object may be compared to
*
* @author Josh Bloch
* @see java.util.Comparator
* @since 1.2
*/
public interface Comparable<T> {
/**
* Compares this object with the specified object for order. Returns a
* negative integer, zero, or a positive integer as this object is less
* than, equal to, or greater than the specified object.
*
* The implementor must ensure sgn(x.compareTo(y)) ==
* -sgn(y.compareTo(x)) for all x and y. (This
* implies that x.compareTo(y) must throw an exception iff
* y.compareTo(x) throws an exception.)
*
*
The implementor must also ensure that the relation is transitive:
* (x.compareTo(y)>0 && y.compareTo(z)>0) implies
* x.compareTo(z)>0.
*
*
Finally, the implementor must ensure that x.compareTo(y)==0
* implies that sgn(x.compareTo(z)) == sgn(y.compareTo(z)), for
* all z.
*
*
It is strongly recommended, but not strictly required that
* (x.compareTo(y)==0) == (x.equals(y)). Generally speaking, any
* class that implements the Comparable interface and violates
* this condition should clearly indicate this fact. The recommended
* language is "Note: this class has a natural ordering that is
* inconsistent with equals."
*
*
In the foregoing description, the notation
* sgn(expression) designates the mathematical
* signum function, which is defined to return one of -1,
* 0, or 1 according to whether the value of
* expression is negative, zero or positive.
*
* @param o the object to be compared.
* @return a negative integer, zero, or a positive integer as this object
* is less than, equal to, or greater than the specified object.
*
* @throws NullPointerException if the specified object is null
* @throws ClassCastException if the specified object's type prevents it
* from being compared to this object.
*/
public int compareTo(T o);
}
Comparable和Comparator的区别可以参考博客
Comparator和Comparable在排序中的应用
从边集中获取最小支撑树
/**
* 返回最小支撑树
*
* @return 最小支撑树的组成的边
*/
public List<EdgeData> kruscal() {
// 排序
List<EdgeData> edgeDataCollection = getEdges();
Collections.sort(edgeDataCollection);
System.out.println("edgeDataCollection.size() = " + edgeDataCollection.size());
System.out.println(edgeDataCollection);
// 用来保存每个顶点的终点, 初始化均为0
int[] destinations = new int[getNumberOfVertex()];
List<EdgeData> result = new ArrayList<>();
// 当结果中的边数小于顶点数-1,继续循环
while (result.size() < getNumberOfVertex() - 1) {
EdgeData leastCostEdge = edgeDataCollection.remove(0);
// 如果未构成回环,则该边应该加入最小支撑树
int m = getEnd(leastCostEdge.getStart(), destinations);
int n = getEnd(leastCostEdge.getEnd(), destinations);
if (m != n) {
result.add(leastCostEdge);
destinations[m] = n;
}
}
return result;
}
上述函数为克鲁斯卡尔的核心算法,该算法代码的活动图如下所示

上述代码在判断回路时,采用了并查集的思想。并查集的内容,不详细阐述,可以参见下述章节。
主干代码在分析时
// 用来保存每个顶点的终点, 初始化均为0
int[] destinations = new int[getNumberOfVertex()];
List<EdgeData> result = new ArrayList<>();
// 当结果中的边数小于顶点数-1,继续循环
while (result.size() < getNumberOfVertex() - 1) {
EdgeData leastCostEdge = edgeDataCollection.remove(0);
// 如果未构成回环,则该边应该加入最小支撑树
int m = getEnd(leastCostEdge.getStart(), destinations);
int n = getEnd(leastCostEdge.getEnd(), destinations);
if (m != n) {
result.add(leastCostEdge);
destinations[m] = n;
}
}
return result;
首先获取一个与顶点数相同的destinations数组,该数组用来辅助判断一条边的两端是否构成回环。开始的时候,把数组中所有元素都置位0,表示每个顶点自成一个集合。然后在不断插入边到最小支撑树的过程中,更新该集合。
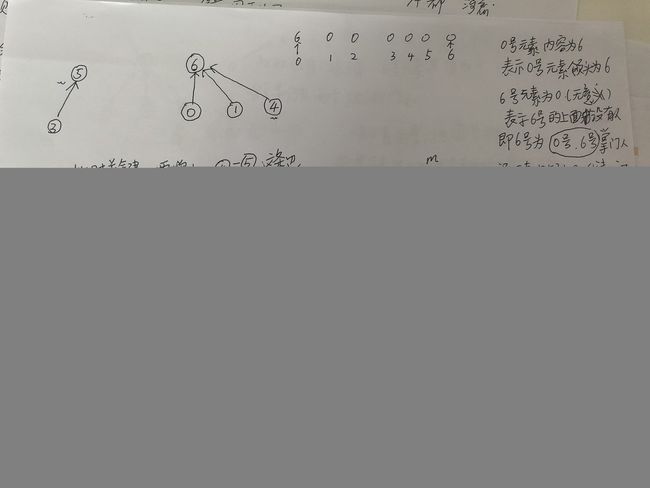
更新完destinations之后,新尝试插入的边为0-1,由于0号顶点所属集合为6号顶点,1号顶点所属集合也为6号奠定,两个顶点,同属一个集合,则认为,0号和1号构成回路,无法插入最小支撑树。

下图是要插入0-2号边时的情形。可以看到destinations集合中
{6, 6, 0, 5, 6, 0, 5}
2号元素和5号元素的内容均为0,表示两个顶点分属不同的集合。


最后形成的destinations所代表的树如下所示:

并查集
并查集详解 ——图文解说,简单易懂(转)
学了这么久的数据结构,还不理解并查集?看这篇文章如何实现

与普利姆算法的比较
最小支撑树实现的两种经典算法为普利姆算法和克鲁斯卡尔算法。MST算法在实际生活中也有着经典的使用。
克鲁斯卡尔算法与普利姆算法的不同点如下所示:
- 普利姆算法时间复杂度为O(n2),该算法适用于求边稠密网的最小支撑树
- 克鲁斯卡尔算法的时间复杂度为O(eloge),适用于求稀疏网的最小支撑树
- 克鲁斯卡尔算法在执行过程中,以边为核心,而普利姆算法则是以顶点为核心,在算法执行过程中,则是把顶点集合分为已经访问的顶点集合和未访问的顶点集合,通过不断的寻找两个集合间的最短边实现的。
参考
普利姆算法
数据结构之图:邻接矩阵和邻接表、深度优先遍历和广度优先遍历
下载
克鲁斯卡尔下载
Git Hub源码查看
总结
总算是完成了克鲁斯卡尔算法内容的编写,这也是关于数据结构的第三个文章了。纸上得来终觉浅,觉知此事要躬行。之前在听韩顺平老师讲授克鲁斯卡尔算法的时候,觉得听起来虽然比较累,但整体并非不可理解,直到自己上手敲代码,才发现真懂、似懂非懂、和假懂虽然看起来很像,一说起来头头是道,但实际是半瓶水晃荡。感谢自己能有这样的认识。
图对自己的伤害很大,因为在读书的时候,自己一到这些地方,就整个云里雾里了,感谢自己还能有机会认真的推敲这些代码的原理,感觉自己确实通过数据结构的学习,理解力得到了提升。
最后简要复述本文的主要内容。本文主要阐述了最小支撑树之克鲁斯卡尔算法的思想,并且通过代码实现了克鲁斯卡尔算法。在实践过程中,通过Comparable接口对边进行了排序,并且结合并查集完成了端点不成回环的判定。通过手绘和visio活动图的阐述描述了克鲁斯卡尔算法在执行过程中的主要工作内容。希望通过本文的学习能够增强读者对于图、以及最小支撑树的理解。
2020年7月4日21:21:41于AUX, 天气下雨。