【spark】关于spark的shuffle模式的一些见解
我不想说太多源码层面的东西,然后把详细方法一个个列出来,其实没有多大意义(因为源码里有,再者比我讲的清晰明白的大有人在,我没有必要再重复相同的东西),但是我真的花了好大的精力才把这部分看完,我得记录下,不然会忘掉
一、spark到底有几种shuffleManager(shuffle管理类)可以选择?
首先spark早期的版本(比如1.5.1版本),是有三种shuffle
http://spark.apache.org/docs/1.5.1/configuration.html#shuffle-behavior
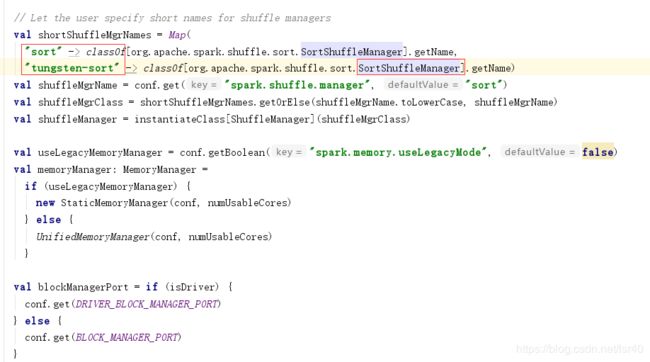
但是后来在1.6的版本又把tungsten-sort取消掉了,最后在2的版本又把hash去掉了
所以现在的版本只有一种了!!!虽然配置里可以写sort或者tungsten-sort,但是指向的是同一个类
sparkEnv类中:
二、shuffle模式有几种?
首先是构建shufflehandle(shuffle处理器),获得write写出数据(这当中还有一些排序,spill磁盘,磁盘上多个文件合并等,我就不具体说了,很多文章都有说明)
1、构建处理器
SortShuffleManager类中:
有一个注册shuffle的方法,这个方法是在DAG构建的时候会触发的(对,就是那个面试的时候很爱问的宽依赖和窄依赖!)
我们可以看到这个方法里会构建3中ShuffleHandle(handle是处理的意思,所以就是有三种shuffle的处理方式)

然后我们先来看看各自的条件
(1)、BypassMergeSortShuffleHandle
(这个类的名字就是绕过聚合和排序,取名很有哲学!)的生成条件如下:
1、依赖中是否有map端的聚合?(必须没有)
2、依赖的分区数是否小于spark.shuffle.sort.bypassMergeThreshold这个值(默认是200)

我多说一句,spark.shuffle.sort.bypassMergeThreshold建议不要随便改动,因为没有聚合,spark会直接往磁盘上写数据,200就要开启200个io流,如果你手动设置调大了,就会开启更多的io流,所以值不能太大,会出问题
(2)、SerializedShuffleHandle
(看的出来,序列化的shuffle)的生成条件如下:
1、序列化支持relocation(这是什么鬼东西,讲实话我没百度到),但是我可以确定的是默认的java序列化是做不了这个事情的,你需要把spark.serializer设置为org.apache.spark.serializer.KryoSerializer,这样就ok了!
2、依赖中没有聚合
3、分区数小于(1 << 24) - 1,也就是16777215

(3)、BaseShuffleHandle
如果上两条都失败,那就构建BaseShuffleHandle
2、构建write
根据上面不同的handle创建不同的write(写类)
SortShuffleManager类中:

好,所以对应关系是
BypassMergeSortShuffleHandle 对应 BypassMergeSortShuffleWriter
SerializedShuffleHandle 对应 UnsafeShuffleWriter 使用 ShuffleExternalSorter 做排序
BaseShuffleHandle 对应 SortShuffleWriter 使用 ExternalSorter 做排序
spark源码分析之ShuffleExternalSorter(作者:weiqing687 ):https://blog.csdn.net/qq_26222859/article/details/81502251
3、区别和使用场景、可修改的参数
(1)、区别
(1)、其实区别在一开始做handle判断的时候,就可见一斑,bypass适用没有聚合,分区少(数据量少)的情况,因此他是最先判断的
(2)、接着是unsafe,unsafe其实是spark的tungsten计划(可以直接操作服务器的内存,以此来避免GC和JVM里面因为对象构建而多占用的资源),但是有三个前提条件,就是使用kryo和没有聚合操作外加分区数要小于16777215(不过说句实在话,分区数要大于1600W的任务。。。我还真没见过,可能我孤陋寡闻了)
(3)、最后这种应该是最通用的了,在以上两条都不满足的时候,只能触发(没有任何强化特性的)基础shuffle,他就没有什么限制条件了,啥都能做,什么聚合啊排序啊,或者不想聚合啊都ok,原因在于
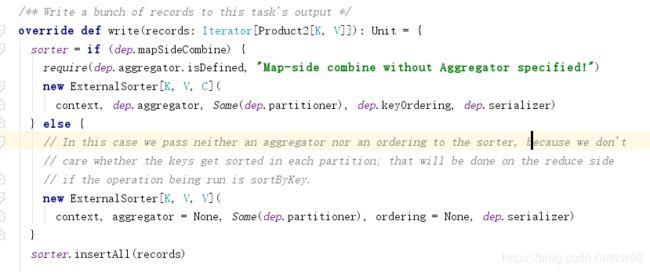
SortShuffleWrite类中的write方法:
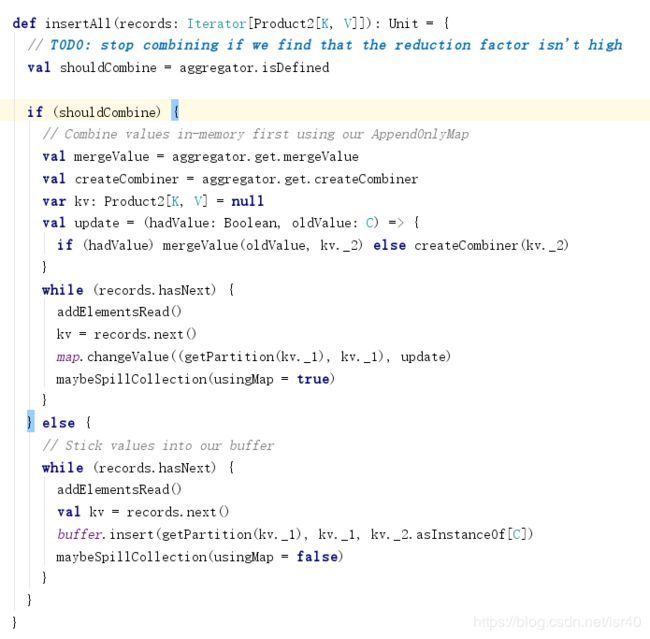
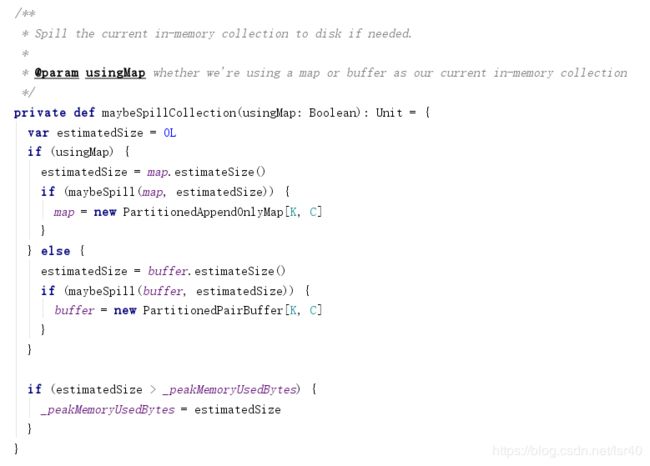
会根据是否有聚合和排序构建ExternalSorter,然后ExternalSorter类的insertAll方法里,又会判断聚合与否,来选择是使用spark自定义的map保存数据还是buffer缓冲数据(map是可用聚合更新数据的,buffer只是缓冲,然后预估这两个对象的大小,来spill磁盘)

(2)、使用场景
相信我,这篇文章你能读到这里,我已经觉得你很棒了!因为我自己都觉得很枯燥,好像对于那些想做shuffle层面优化的小伙伴来说,啥都没得到,接下来我要说说我自己看了这些知识之后的观点。
1、map端的聚合的疑问?
map端的聚合其实是一个优化,他可以减少数据占用的空间,10条(spark,1)这样的数据,我可以用1条(spark,10)来代替,肯定是方便的,但是可以看到如果想使用unsafe的shuffle,那就不能有map端的聚合,那到底有哪些场景适用呢?
我举几个例子:
RDD:groupbyKey

是不是觉得,太少了,之前我一时之间也想不到其他的,不过后来
repartition,sort排序,还有一个非常常见的场景join
2、unsafe和基础的shuffle性能
在完全相同的数据量和处理下,unsafe的性能肯定会比基础的shuffle性能好,不然spark就不用那么大费周折的添加这个功能,但是不少场景下,我们是可以通过map的先行聚合来减少数据量,既然减少了数据量,那么相应内存消耗,io消耗就会减少,因此不能说所有场景下unsafe的性能都比基础的shuffle好
3、bypass基本只使用数据量少的场景
像本地测试,基本上全是走bypass,大家可以自己在注册shuffle的方法打断点跑跑看
4、想使用unsafe优化,是否必须显示设置kryo
我自己试下,rdd编程的话,必须设置,否则就走java的序列化,那就永远都用不到unsafe
但如果你用的是DataSet的DSL编程,我发现不设置kryo,他也会走到unsafe里,不过管他的呢,你直接在配置文件里写死kryo它不香吗?
(3)、可修改的参数
1、bypass方式
可以增加buffer,减少磁盘写入次数,但是这样内存压力就会变大
这个参数不止在这里用到,在基础shuffle中也用到了,具体往下看
spark.shuffle.file.buffer |
32k | Size of the in-memory buffer for each shuffle file output stream, in KiB unless otherwise specified. These buffers reduce the number of disk seeks and system calls made in creating intermediate shuffle files. | 1.4.0 |

2、unsafe
我们说过unsafe的方式不支持聚合,但是支持排序,所以
spark.shuffle.sort.initialBufferSize可以设置这个值来提高sort的buffer,但是其实官网的configuration页面,并没有把这个参数列出来,估计是不想让大家随便改把!!

3、原始的shuffle:SortShuffleWriter
在这个类中,并没有参数可以设置,但是在write的时候,他使用到了ExternalSorter类,这个类里有2个参数
第一个参数和bypass是一样的,第二个参数官网也没有列出,但是注释里说,不要设置太低,否则会导致“在序列化中过度的复制”(我也不知道什么意思)

4、shuffle的下游read数据
可以看到SortShuffleManager类,中有个getReader的方法,里面构建了BlockStoreShuffleReader类
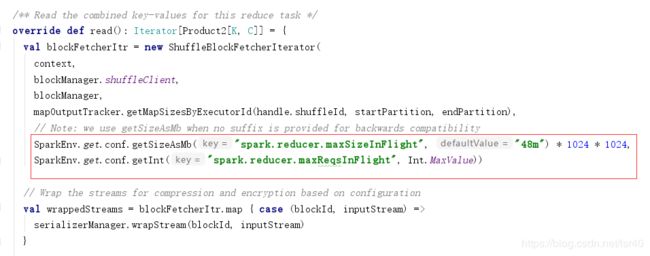
这个类中有个参数,是每个reduce拉取map的结果数据到buffer中,上限48M,如果你有足够的内存,可以增加这个值,减少io压力
spark.reducer.maxSizeInFlight |
48m | Maximum size of map outputs to fetch simultaneously from each reduce task, in MiB unless otherwise specified. Since each output requires us to create a buffer to receive it, this represents a fixed memory overhead per reduce task, so keep it small unless you have a large amount of memory. | 1.4.0 |
5、除此之外,建议看看官网
当然除了上述参数之外,没有什么其他太多的参数了
剩下的没讲到的参数,基本就两种,一种是shuffle的io拉取数据的时候的重试(在大作业运行时,可以调大这些重试,增加程序的稳定),另一种就是外部的shuffle机制,这是跟动态资源申请相关的(但是理论上我是不推荐使用动态资源申请的,一直以来这个模式一直都有或多或少的bug,而且毕竟集群不止是spark在用,很有可能有其他的hive等任务,所以。。。这就好像TDD一样,大家都说好,但是用的人很少)
http://spark.apache.org/docs/3.0.0/configuration.html#shuffle-behavior
http://spark.apache.org/docs/3.0.0/job-scheduling.html#dynamic-resource-allocation
以上就是我对spark的shuffle模式的总结和见解,欢迎大家留言讨论!!
我也看到一些文章还不错,所以留在下面:
Spark中几种ShuffleWriter的区别你都知道吗?(作者:叫我不矜持):https://www.jianshu.com/p/cbab289d51c0
Spark SortShuffleWriter(作者:wangdy12):https://www.jianshu.com/p/541b3648ffd7
spark源码分析系列(作者:JohnnyBai):https://www.cnblogs.com/johnny666888/p/11259944.html
菜鸡一只,一晃今天是2020年上半年的最后一天了,感觉好快啊~
感谢“甘木”大佬的点拨,我才能写出这篇文章!