百度云智学院视频的爬取
文章目录
- 任务1.1 requests与fake_useragent的模块及入门
- 任务1.2 读取json文件
- 任务1.3 字节流文件的读与写
- 任务1.4 使用os库创建目录与文件
- 任务1.5 使用re库进行匹配数字
- 任务1.6 了解m3u8视频格式
- 任务2.1 对视频的来源进行探索
- 任务2.2 探索获取m3u8视频格式文件的请求参数timestamp
- 任务2.3 探索获取m3u8视频格式文件的请求参数courseId
- 任务2.4 探索获取m3u8视频格式文件的请求参数sectionId,videoId,mediaId
- 任务2.5 利用前面找到的几个参数,进行最后获取视频的步骤
- 任务2.6 优化代码
前言
同学们时光荏苒!,你们通过前几个月的艰苦奋斗完成了python基础,高级部分,或多或少,了解了爬虫基础。今天我们一起做一个爬取百度云智慧学院的所有视频的项目吧,通过项目实战夯实基础,强化编程能力与将爬虫技术提升到一个新的境界,同学们将再一次踏上新的征程!
知识技能篇
单元一:爬取之前进行必备技能的学习
学习目标
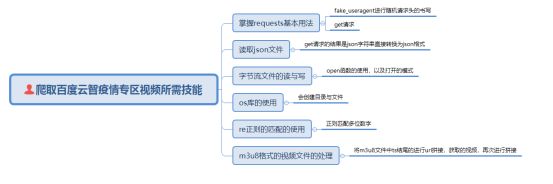
任务1.1 requests与fake_useragent的模块及入门
任务描述
(1)安装requests与fake_useragent库
(2)尝试使用requests进行get或者post请求
知识学习
requests历史
我们可能了解了urllib的基本用法,但是其中确实有很多不方便的地方,比如处理网页验证和Cookies时,需要进行Opener和Handler来处理。为了更加方便实现这些操作,引入更加强大的库,requests库。Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库。它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。
任务实施
1.安装requests与fake_useragent库
我们直接在pycharm中打开命令行下载,如下图
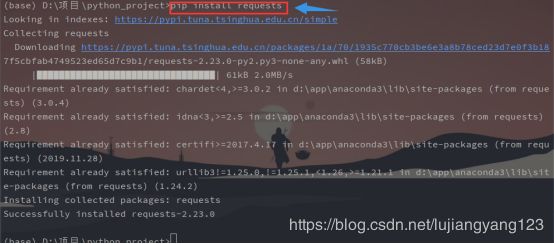
requests的下载:
cmd命令示例:pip install requests
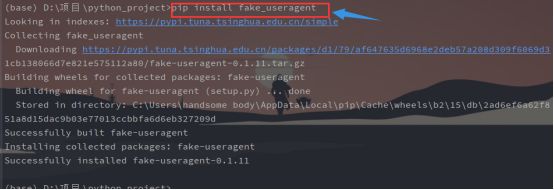
fake_useragent的下载:
cmd命令示例:pip install fake_useragent
2.尝试使用requests模块爬取百度云智学院疫情活动专区的首页
网址地址:请点我
首先新建一个py文件,准备书写代码
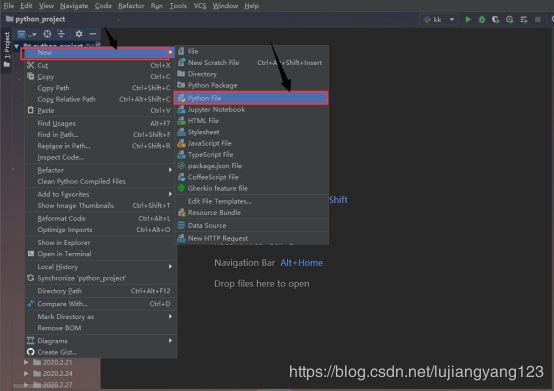
在创建的文件中书写代码,爬取百度云智学院疫情专区的首页
进入疫情专区网页,点击F12进入开发者模式,找到这个第一个文件,就是我们需要爬取的首页源码。
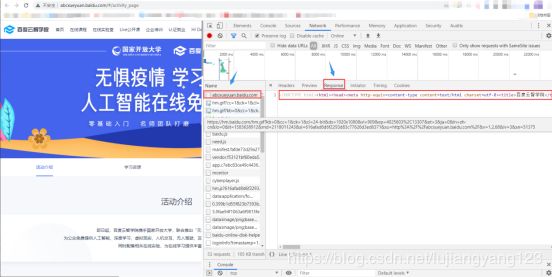
查看文件请求的url与请求头需要什么,以及需不需要请求参数
然后进行requests请求编辑如下代码获取网页源码
import requests
from fake_useragent import UserAgent
# 定义随机请求头
def random_agent():
return UserAgent().random
# 请求头的书写
header = {
'User-Agent': UserAgent().random
}
# 进行get请求
response = requests.get('http://abcxueyuan.baidu.com/#/activity_page', headers=header)
# 获取请求的结果
print(response.content.decode('utf-8'))
运行结果:

任务1.2 读取json文件
任务描述
本任务主要是学会如何读取json字符串
知识学习
python为我们提供了简单易用的json库来实现json文件的读写操作,,我们可以调用json库的loads()方法将json文本字符串转为json对象,可以通过dumps()方法将json对象转为文本字符串。在本项目中get请求后直接调用json()直接使用json进行解析json格式方便取值
任务实施
写一个json字符串,将他转换为json格式,取出里面的电话号码
import json
#进行过书写json字符串
json_str='''
[{
"name":"xiaoming",
"addr":"shanxi",
"ipone":15245623648
},{
"name":"lihua",
"addr":"xian",
"ipone":78958462124
}]
'''
运行结果:

#获取数据类型
print(type(json_str))
#将json字符串转为json格式
json1=json.loads(json_str)
#获取数据类型
print(type(json1))
#获取所有的电话
for i in json1:
print(i["ipone"])
运行结果:

任务1.3 字节流文件的读与写
任务描述
掌握字节流文件读取的方式,以及各种打开文件的模式
知识学习
我们一般抓取一个网页,实际上他返回的是一个HTML文档。如果想要抓取图片、音频、视频、等文件,应该怎么办呢?
图片、音频、视频这些文件本质上都是有二进制码组成的,由于有特定的保存格式和对应的解析方式,我们才可以看到这些形形色色的多媒体。所以,想要抓取他们,就要拿到他们的二进制码。
文件打开的模式:
“a” 以“追加”模式打开
“a+” 以”读写”模式打开
“ab” 以”二进制 追加”模式打开
“ab+” 以”二进制 读写”模式打开
“w” 以”写”的方式打开
“w+” 以“读写”模式打开
“wb” 以“二进制 写”模式打开
“wb+” 以“二进制 读写”模式打开
“r+” 以”读写”模式打开
“rb” 以”二进制 读”模式打开
“rb+” 以”二进制 读写”模式打开
任务实施
获取一个mp4文件的二进制内容,并将内容写入一个新的文件里
#以二进制只读模式打开一个文件
with open("./mp4文件.mp4",mode='rb') as f:
#读取MP4二进制文件
read_binary_system=f.read()
#打印文件内容
print(read_binary_system)
#以二进制只写模式对文件进行写入
with open("./new mp4.mp4",mode='wb') as f1:
#将f中的二进制内容重新写入一个文件
f1.write(read_binary_system)
print("二进制数据写入成功")
运行结果:

任务1.4 使用os库创建目录与文件
任务描述
本任务主要是学会使用os库创建目录与文件
知识学习
os.makedirs()
os.makedirs() 方法用于递归创建目录。像 mkdir(), 但创建的所有intermediate-level文件夹需要包含子目录。
os.path.exists()
os.path.exists()方法用于判断给出的路径是否存在
任务1.5 使用re库进行匹配数字
任务描述
本任务主要是学会使用re库进行匹配数字
代码示例
import re
print(re.findall("courseId=(\d+)", "http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/playVideo?timestamp=1583670623568&courseId=14956§ionId=15226&videoId=2521&mediaId=mda-jdmne9edxxuk1pc3"))
任务1.6 了解m3u8视频格式
任务描述
了解m3u8视频格式
知识学习
m3u8不是一种视频格式,而是一种纯文本文件。
m3u8视频文件格式中存放了视频的基本信息和 分段视频的索引地址 (将一整个视频分成了时长不同的很多小段)。当播放m3u8视频时,就是按顺序下载播放索引列表的视频,从而完成一部完整视频的播放。
技术应用篇
单元二:requests爬取百度云智学院的疫情专区的所有视频
学习目标
实现对百度云智学院的疫情专区的所有视频的爬取
思维导图:
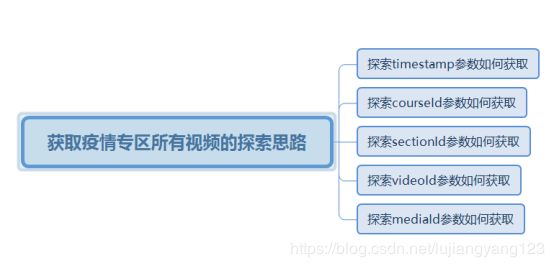
任务2.1 对视频的来源进行探索
任务描述
本任务主要是有下面2个任务:
(1)找出视频是通过哪个接口请求到的
(2)简单模拟一下这个过程
思路探索
首先选择一个专区,再随便选择一个视频,进行学习
点击f12,Network,一般获取的数据很多,会干扰我们的视线,于是我们选择XHR,然后ctrl+r进行刷新,查看异步加载的数据,这样就大大降低我们查找我们想要的数据所耗费的时间。点击播放按钮,观察新请求出来的文件
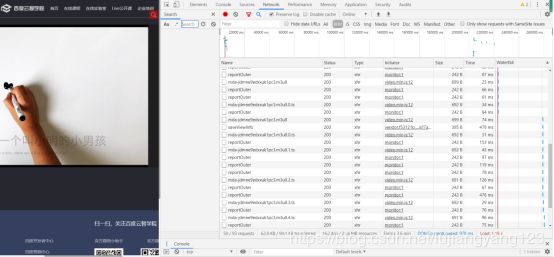
然后仔细观察这几个文件的关系
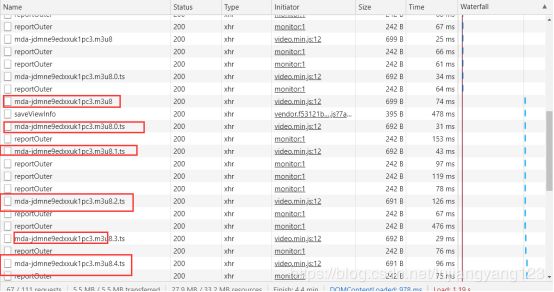
我们发现mda-jdmne9edxxuk1pc3.m3u8了这个文件里面有很多ts结尾的
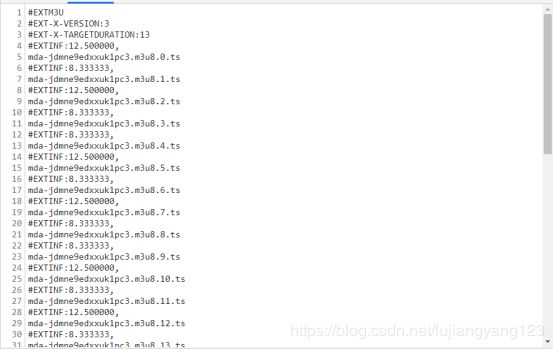
查看mda-jdmne9edxxuk1pc3.m3u8.0.ts文件,我们发现,这个文件请求的url,前面都是相同的,就是最后一个组成部分不同,所以我们可以判定,这些ts文件肯定是通过m3u8文件中的那个ts结尾的,进行了某种请求得到的
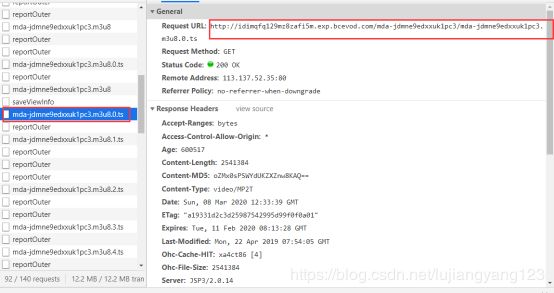
我们将前面两种文件url相同的部分去搜索一下(http://idimqfq129mz8zafi5m.exp.bcevod.com),搜到这个名为playVideo?timestamp=1583670623568&courseId=14956§ionId=15226&videoId=2521&mediaId=mda-jdmne9edxxuk1pc3这个有用的文件
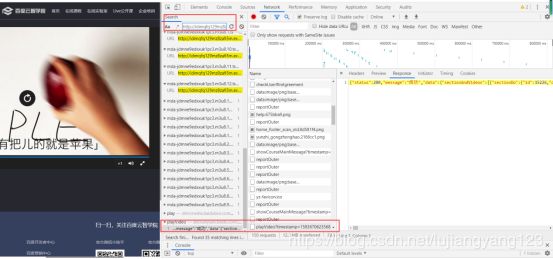
进入这个图中红色框框那个文件,查看他的Preview
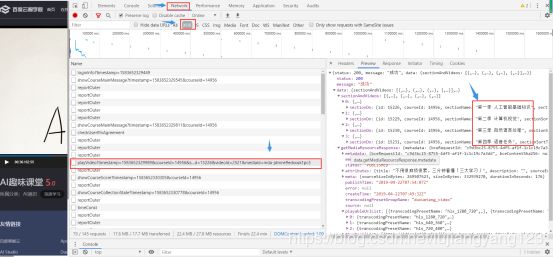
查看这个文件的Preview之后,我们发现那个文件好像有我们要找的视频url,有一丝联系,于是我们将这些数据复制到json格式化工具上进行json格式化,选择在Response下复制数据方便,Json格式化工具网址:https://www.json.cn/。
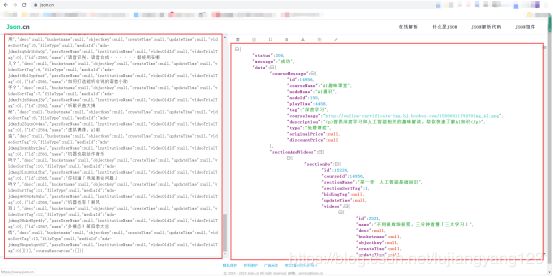
格式化后,我们来找找有没有跟视频有关系的url,如果说对m3u8熟悉的同学,可能已经找到了,如果不熟悉,没听说过,可能不会错过关键线索。最终找到这个m3u8的网址,我们发现有三个url,根据英语意思,我们发现,这三个url分别代表高清,标清,流畅,
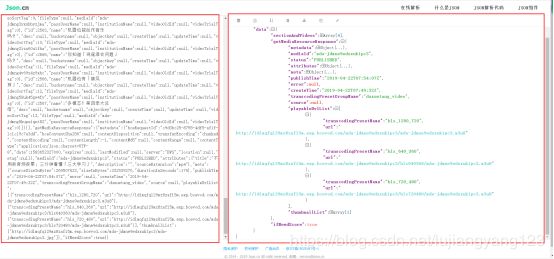
于是我们点击1280_720的这个网址会下载一个m3u8的文件,在网页上打开他,会发现里面的文件是这样的
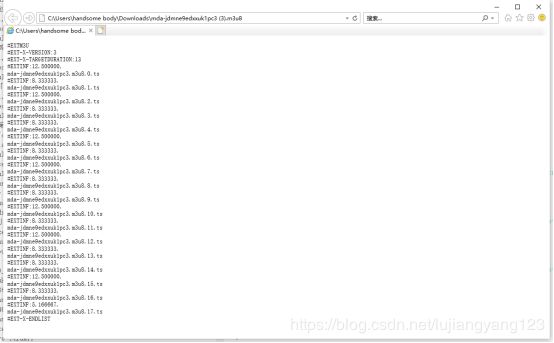
于是我们将http://idimqfq129mz8zafi5m.exp.bcevod.com/mda-jdmne9edxxuk1pc3/与文件中的所有ts格式的第一个进行url拼接,再放到输入到游览器地址栏中
![]()
会自动下载这个音频文件,于是我们打开他,发现只有10秒,那个第一视频一共2分多种,于是我们可以猜想,将这个文件所有的ts格式的那一行进行url拼接,再将获取的所有视频拼接再一起,就会是一个完整的视频

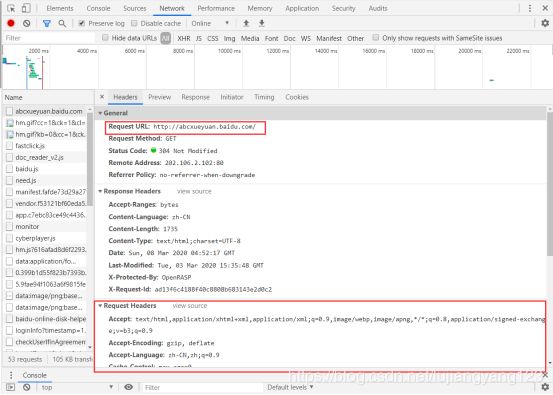
于是我们查看这个文件的url,以及请求头,和请求参数,get请求还是post请求
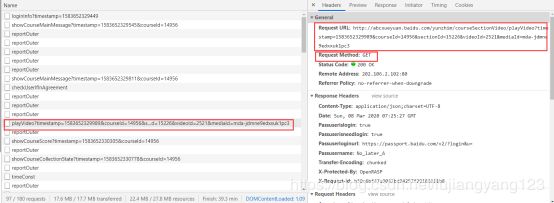
请求的url与请求的方式

请求头
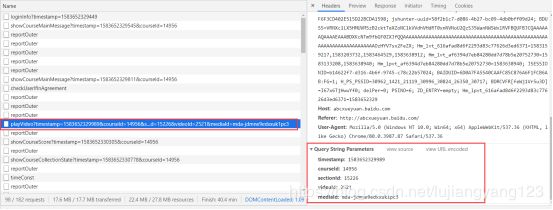
请求参数
任务实施
通过pycharm中的正则进行添加双引号与逗号,避免繁重的操作
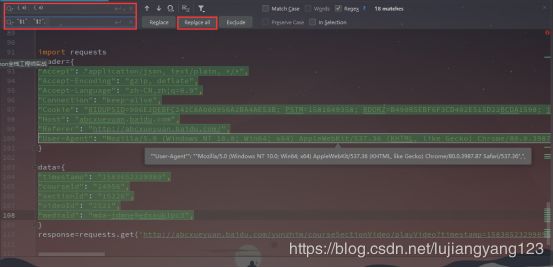
代码示例:
import requests
# 定义随机请求头
def random_agent():
return UserAgent().random
# 选择清晰度
def select_definition():
# 0是分辨率为1280_720,1是分辨率为640_360,2是分辨率为720_480
return 0 # 默认为最高画质,可手动修改
# 对应的画质,为了起名字
def vision_name(number):
# 高清,流畅,标清
return ["高清", "流畅", "标清"][number]
# 定义请求头
header = {
"Cookie": "BIDUPSID=906E2DEBFC241C8A000956A2BA4AE53B; PSTM=1581049358; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; jshunter-uuid=58f2b1c7-d086-4b27-bc09-4db0bff09d24; BDUSS=VRNXc1LX5HMUVMSzB2cktTeXZoNC1kVVdhVHdRT0xnNVNoU2QzS35WanNWSWxlRVFBQUFBJCQAAAAAAQAAAAEAAABDXKcNTm9fbGF0ZXJfQQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOzHYV7sx2FeZX; Hm_lvt_616afad8d6f2293d83c77626d3ed6371=1583159217,1583203732,1583464529,1583638912; Hm_lvt_af6394d7eb84280dd7d78b5e20752730=1583133208,1583638940; Hm_lpvt_af6394d7eb84280dd7d78b5e20752730=1583638940; JSESSIONID=b14622f7-d316-4b6f-9745-c78c22b57024; BAIDUID=6D0A7FA5540CAAFC85C876A6F1FCB6AB:FG=1; H_PS_PSSID=30962_1421_21119_30996_30824_26350_30717; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=6; ZD_ENTRY=empty; Hm_lpvt_616afad8d6f2293d83c77626d3ed6371=1583652329",
"Referer": "http://abcxueyuan.baidu.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36",
}
# 定义传参字典
data = {
"timestamp": "1583652329989",
"courseId": "14956",
"sectionId": "15226",
"videoId": "2521",
"mediaId": "mda-jdmne9edxxuk1pc3",
}
# 进行requests请求
response = requests.get(
'http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/playVideo?timestamp=1583652329989&courseId=14956§ionId=15226&videoId=2521&mediaId=mda-jdmne9edxxuk1pc3',
headers=header, data=data)
# 获取json数据格式
response_json = response.json()
# 取出m3u8视频格式的所有url,使用ts格式的那一行拼接url,拿到所有视频,再次进行拼接
m3u8 = [i for i in response_json["data"]["getMediaResourceResponse"]["playableUrlList"]][select_definition()]
# 获取所有的url
m3u8_url_all = m3u8["url"]
print("打印m3u8url", m3u8_url_all)
# 拿到m3u8格式的url进行请求
response1_text = requests.get(m3u8_url_all).text
# 截取前面的从右向左第一个斜杠到最前面的url
m3u8_url_ts_url = m3u8_url_all[:m3u8_url_all.rfind("/")]
for y in str(response1_text).split("\n"):
if y[-3:] == ".ts":
# 拼接获取视频的url
url = "{}/{}".format(m3u8_url_ts_url, y)
print("正在存储", url)
# 进行get请求
response_ts_text = requests.get(url)
# 以二进制追加的方式打开文件,如果没有则创建,如果有则追加
with open("{}大片.mp4".format(vision_name(select_definition())), mode="ab+") as f:
# 将字节流写入文件中
f.write(response_ts_text.content)
print("视频拼接存储成功")
运行结果:

通过查看我们获取的视频,我们发现我们的思路是对的,成功拼接成功视频,在网站中第一个视频中正是2分55秒,我们获取第一个视频就这样成功了
任务2.2 探索获取m3u8视频格式文件的请求参数timestamp
任务描述
本任务主要找出请求m3u8视频格式文件的请求参数timestamp的来源
任务实施
熟眼的人一看就会发现这是个时间戳,那么我们来证明一下,将这个参数复制到时间戳网站上去
时间戳网址:请点我
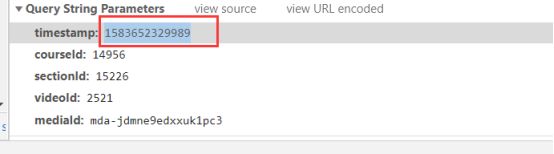
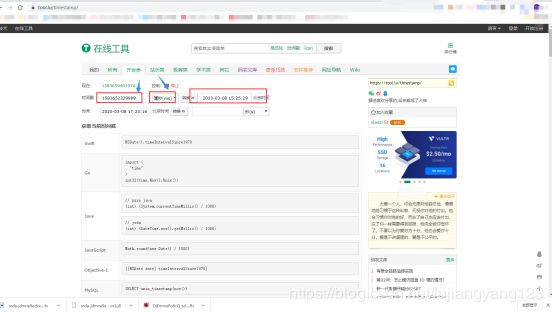
通过时间戳的转换于是我们发现,这个timestamp就是时间戳,于是我们来模拟一下
代码示例:
import time
# 定义时间戳函数
def timestamp():
return str(int(time.time() * 1000))
print("时间戳",timestamp())
任务2.3 探索获取m3u8视频格式文件的请求参数courseId
任务描述
本任务主要找出请求m3u8视频格式文件的请求参数courseId的来源
任务实施
通过查看本网页上面的url,我们发现这个参数的值,应该是上个网页传进来的
![]()
跳转到上一个网页我们发现上面的url还是有直接有这个值,于是我们判断还在上一层
点击F12搜索这个值14956,于是我们发现含有这个数据的文件的有三个,两个js文件肯定不是我们要找的,于是就剩下另一个叫getActivityForm?timestamp=1583660020228的文件
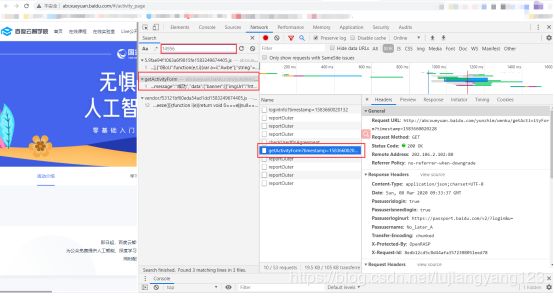
通过查看这个文件的内容发现,好像就是我们要找的文件
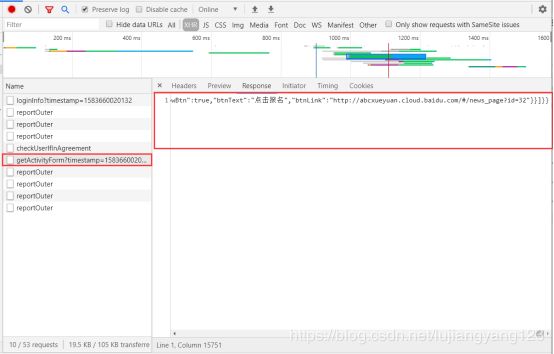
同样我们将Response下的数据复制到json格式化工具中去,使用ctrl+f搜索courseId,
我们发现每门课都有这个参数,所以我们算是成功解决这个courseId参数了
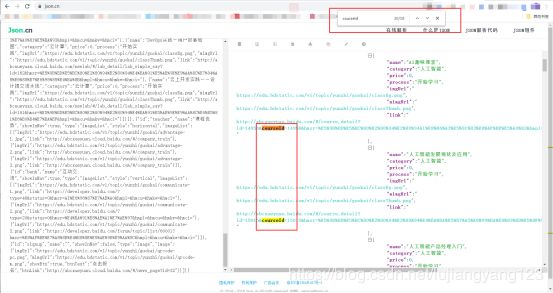
查看请求该文件接口需要的url,请求方式,请求头,请求参数
代码示例
将所有的course参数取出来
import requests
import time
import re
# 定义随机请求头
def random_agent():
return UserAgent().random
# 定义时间戳函数
def timestamp():
return str(int(time.time() * 1000))
#定义请求头
header={
"Cookie": "BIDUPSID=906E2DEBFC241C8A000956A2BA4AE53B; PSTM=1581049358; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; jshunter-uuid=58f2b1c7-d086-4b27-bc09-4db0bff09d24; BDUSS=VRNXc1LX5HMUVMSzB2cktTeXZoNC1kVVdhVHdRT0xnNVNoU2QzS35WanNWSWxlRVFBQUFBJCQAAAAAAQAAAAEAAABDXKcNTm9fbGF0ZXJfQQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOzHYV7sx2FeZX; Hm_lvt_616afad8d6f2293d83c77626d3ed6371=1583159217,1583203732,1583464529,1583638912; Hm_lvt_af6394d7eb84280dd7d78b5e20752730=1583133208,1583638940; Hm_lpvt_af6394d7eb84280dd7d78b5e20752730=1583638940; JSESSIONID=b14622f7-d316-4b6f-9745-c78c22b57024; BAIDUID=6D0A7FA5540CAAFC85C876A6F1FCB6AB:FG=1; H_PS_PSSID=30962_1421_21119_30996_30824_26350_30717; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=6; ZD_ENTRY=empty; Hm_lpvt_616afad8d6f2293d83c77626d3ed6371=1583660020",
"Referer": "http://abcxueyuan.baidu.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
#定义传参字典
data={
timestamp:timestamp()
}
#进行get请求
response=requests.get('http://abcxueyuan.baidu.com/yunzhim/wenku/getActivityForm?timestamp=1583660020228',headers=header,data=data)
#使用json解析
response_json=response.json()
for i in response_json["data"]["modules"][1]["classList"]:
#获取专区名称
print(i["title"])
for j in i["classes"]:
#获取课程名称
class_name=j["name"]
print("课程名称",class_name)
# 获取courseId参数
courseId = re.findall("courseId=(\d+)", j['link'])
运行结果:

我们分析一下结果发现几个问题
有两个链接里面都有两个这个参数,但是后面那个跟前面某个重复,所以我们使用这个参数列表,都使用第一个元素,因为后面的都是重复的
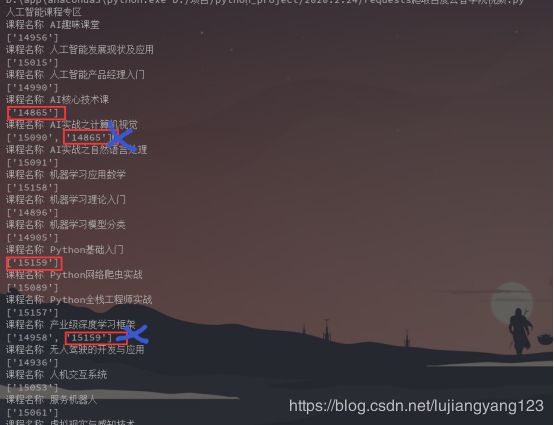
我们还发现最后一个专区的所有的都没有获取到courseId这个参数,是因为最后一个专区是模拟实验室,所以是没有视频的,再最后写代码的时候过滤掉即可

任务2.4 探索获取m3u8视频格式文件的请求参数sectionId,videoId,mediaId
任务描述
本任务主要找出请求m3u8视频格式文件的请求参数sectionId,videoId,mediaId的来源
任务实施
首先再中间网站搜索sectionId这个值,发现有个叫showCourseMainMessage?timestamp=1583662857382&courseId=14956文件的内容有这个参数
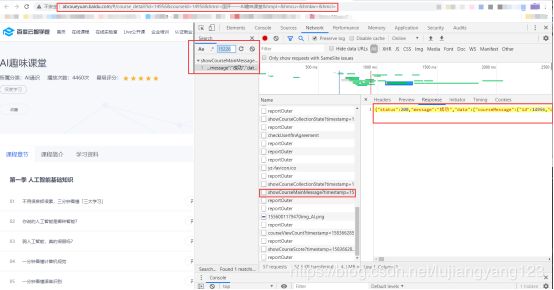
于是我们依然将Response下面的代码粘贴到json格式化网站中去,于是如果我们细心的话,会一下收获三个参数,分别是sectionId对应着父id,videoId对应着子id,以及mediaId这个参数(注意:不要以为在获取视频url接口是sectionId,videold,在别的网页变量名就不会发生变化。
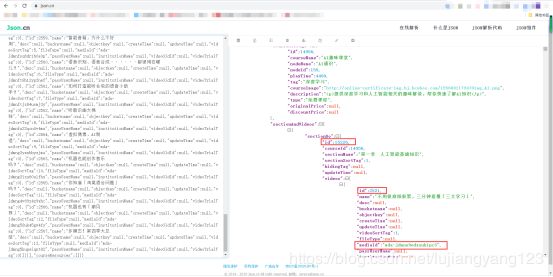
我们再看一下这个文件,请求所需要的url,请求头,请求参数
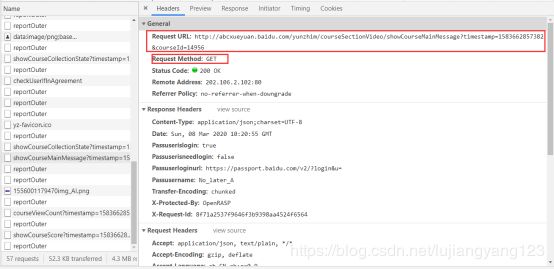
请求所需要的请求url,请求方式
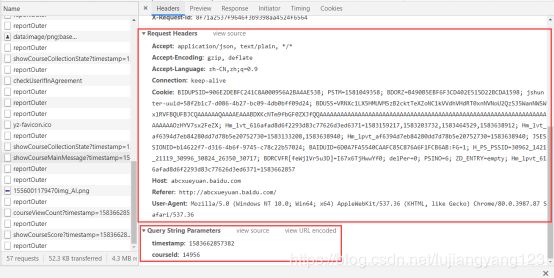
请求所需要的请求头,请求参数
我们发现,之前获取的参数courseId可以用上了,于是进行代码的书写,获取这三个参数
代码示例
import requests
import time
import re
# 定义随机请求头
def random_agent():
return UserAgent().random
# 定义时间戳函数
def timestamp():
return str(int(time.time() * 1000))
# 定义请求头
header = {
"Cookie": "BIDUPSID=906E2DEBFC241C8A000956A2BA4AE53B; PSTM=1581049358; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; jshunter-uuid=58f2b1c7-d086-4b27-bc09-4db0bff09d24; BDUSS=VRNXc1LX5HMUVMSzB2cktTeXZoNC1kVVdhVHdRT0xnNVNoU2QzS35WanNWSWxlRVFBQUFBJCQAAAAAAQAAAAEAAABDXKcNTm9fbGF0ZXJfQQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOzHYV7sx2FeZX; Hm_lvt_616afad8d6f2293d83c77626d3ed6371=1583159217,1583203732,1583464529,1583638912; Hm_lvt_af6394d7eb84280dd7d78b5e20752730=1583133208,1583638940; Hm_lpvt_af6394d7eb84280dd7d78b5e20752730=1583638940; JSESSIONID=b14622f7-d316-4b6f-9745-c78c22b57024; BAIDUID=6D0A7FA5540CAAFC85C876A6F1FCB6AB:FG=1; H_PS_PSSID=30962_1421_21119_30996_30824_26350_30717; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=6; ZD_ENTRY=empty; Hm_lpvt_616afad8d6f2293d83c77626d3ed6371=1583660020",
"Referer": "http://abcxueyuan.baidu.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
# 定义传参字典
data = {
timestamp: timestamp()
}
# 定义初始的时间戳
time1 = timestamp()
# 进行get请求
response = requests.get('http://abcxueyuan.baidu.com/yunzhim/wenku/getActivityForm?timestamp={}'.format(time1),
headers=header, data=data)
# 使用json解析
response_json = response.json()
for i in response_json["data"]["modules"][1]["classList"]:
# 获取专区名称
print(i["title"])
for j in i["classes"]:
# 获取课程名称
class_name = j["name"]
print("课程名称", class_name)
# 获取courseId参数
courseId = re.findall("courseId=(\d+)", j['link'])[0]
# 第二次定义时间戳
time2 = timestamp()
# 进行第二次请求所需要的请求参数字典的书写
data1 = {
"timestamp": time2,
"courseId": courseId,
}
# 进行第二次请求获取三个关键参数
response1 = requests.get(
"http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/showCourseMainMessage?timestamp={}&courseId={}".format(
time1, courseId), headers=header, data=data1)
# 使用json进行解析
response1_json = response1.json()
for z in response1_json["data"]["sectionAndVideos"]:
# 获取参数sectionId
sectionId = z["sectionDo"]["id"]
for k in z["sectionDo"]["videos"]:
# 获取参数videoId
videoId = k["id"]
# 获取参数mediaId
mediaId = k["mediaId"]
print(courseId, sectionId, videoId, mediaId)
运行结果:

任务2.5 利用前面找到的几个参数,进行最后获取视频的步骤
任务描述
通过前面的努力我们已经找到了获取所有视频url的接口的必备参数,我们来请求所有的高清,标清,流畅视频把。
任务实施
代码示例
import requests
import json
import time
import re
import os
from fake_useragent import UserAgent
# 定义随机请求头
def random_agent():
return UserAgent().random
# 定义时间戳函数
def timestamp():
return str(int(time.time() * 1000))
# 选择清晰度
def select_definition():
# 0是分辨率为1280_720,1是分辨率为640_360,2是分辨率为720_480
return 0 # 默认为最高画质,可手动修改
# 对应的画质,为了起名字
def vision_name(number):
# 高清,流畅,标清
return ["高清", "流畅", "标清"][number]
# 选择专区
def select_course():
# 0为人工智能专区,1为大数据课程专区,2为云计算课程专区,3为物联网,区块链课程专区,4为k12科普课程专区,5为实验室实践课程专区
return 0 # 默认人工智能专区,可手动更改
def main():
# 定义最初请求的时间戳
time1 = timestamp()
data1 = {
'timestamp': time1
}
header = {
"Cookie": "BIDUPSID=906E2DEBFC241C8A000956A2BA4AE53B; PSTM=1581049358; BAIDUID=906E2DEBFC241C8ADC25849A4A3C310E:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; jshunter-uuid=58f2b1c7-d086-4b27-bc09-4db0bff09d24; Hm_lvt_616afad8d6f2293d83c77626d3ed6371=1582515071,1582555226,1582559448,1582595860; H_PS_PSSID=30746_1455_21113_30840_30823; BDUSS=NpLXZCbENFOTUybzBTOFdkNk5Ufm55fnVjcS1PTmgyREVSdVZwSFhEfnlMWHhlRUFBQUFBJCQAAAAAAQAAAAEAAABDXKcNTm9fbGF0ZXJfQQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPKgVF7yoFReNW; delPer=0; PSINO=6; BCLID=8548900187112280009; BDSFRCVID=gstOJeC6293Zm-cuoWpGEM2zwFm9-UjTH6aoI8vBB_1C22a5Bm2REG0PeM8g0KAb-FL1ogKKy2OTH9KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tJIjVC05tK83qb8kK4oj5JK_-U702t_XKKOLVMQ1Jp7keq8CD6u5Wl0N5loyLM5P3mDHXt3jyqTFfD52y5jHhnF7yt8OBtoUJe5z_loEK4TpsIJMbfFWbT8ULfKL0fADaKvia-I-BMb1bqvDBT5h2M4qMxtOLR3pWDTm_q5TtUJMeCnTDMFhe6j0Dauft5tef5R2stoHK-5-HJOdMtTHq4tehHRMbb39WDTm_D_XtMcVKJOGhpJ2QULIDl6f0tu8HGTB-pPKKR7zb-QtLlPaLTjX-HoG26jN3mkjbn5zfn02OpjPqfjdDt4syPR8JfRnWn5iKfA-b4ncjRcTehoM3xI8LNj405OTbIFO0KJzJCcjqR8Zj6LbejOP; ZD_ENTRY=baidu; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; Hm_lpvt_616afad8d6f2293d83c77626d3ed6371=1582621363",
"Referer": "http://abcxueyuan.baidu.com/",
'User-Agent': random_agent()
}
# 通过一系列操作获取最终需要的请求的视频url的接口的必备参数
response1 = requests.get('http://abcxueyuan.baidu.com/yunzhim/wenku/getActivityForm?timestamp=1582614705092',
headers=header, data=data1)
response1_json = response1.json()
# 获取人工智能课程的link
# classlist获取所有系列的资源
# 可更改下载的专区select_course()函数
for i in [i for i in response1_json["data"]["modules"][1]["classList"]][select_course()]["classes"]:
# print(i)
# 获取所有文章的资源
main_name = i["name"]
# print(main_name)
# # 获取courseId参数
courseId = re.findall("courseId=(\d+)", i['link'])[0]
# print(courseId)
data2 = {
'timestamp': time1,
'courseId': courseId
}
# 创建课程视频目录
if not os.path.exists("./video"):
os.makedirs("./video")
# 创建课程专区
if not os.path.exists("./video/{}".format(i["category"])):
os.mkdir("./video/{}".format(i["category"]))
# 创建课程名字
if not os.path.exists("./video/{}/{}".format(i["category"], main_name)):
os.makedirs("./video/{}/{}".format(i["category"], main_name))
response2 = requests.get(
"http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/showCourseMainMessage?timestamp={}&courseId={}".format(
time1, courseId), data=data2, headers=header)
response2_json = response2.json()
for j in response2_json["data"]["sectionAndVideos"]:
# 获取参数sectionId
sectionId = j["sectionDo"]["id"]
for k in j["sectionDo"]["videos"]:
# 获取参数videoId
videoId = k["id"]
# 获取参数mediaId
mediaId = k["mediaId"]
# 获取name
name = k["name"]
# print(sectionId,videoId,mediaId,name)
data3 = {
"timestamp": time1,
"courseId": courseId,
"sectionId": sectionId,
"videoId": videoId,
"mediaId": mediaId
}
response3 = requests.get(
'http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/playVideo?timestamp={}&courseId={}§ionId={}&videoId={}&mediaId={}'.format(
timestamp(), courseId, sectionId, videoId, mediaId), data=data3, headers=header)
response3_json = response3.json()
# print(response3.text)
print("查看返回的数据", response3_json)
#进行异常处理,防止cookie过期,报错
try:
# 画质的选择
vision = [u for u in response3_json["data"]["getMediaResourceResponse"]["playableUrlList"]][
select_definition()]
# 获取url
m3u8_url = vision["url"]
# 音频文件
print("搜索到音频文件,准备下载")
print(m3u8_url)
response4 = requests.get(m3u8_url)
# 获取文本
response4_html = response4.text
# 截取前面的从右向左第一个斜杠到最前面的url
m3u8_url_ts_url = m3u8_url[:m3u8_url.rfind("/")]
# print(m3u8_url_ts_url)
# 将我们要找的ts拿出来
for y in response4_html.split("\n"):
if y[-3:] == ".ts":
response5 = requests.get("{}/{}".format(m3u8_url_ts_url, y))
# 请求完毕,等待一秒
time.sleep(1)
print("正在存储{}请稍等".format(y))
# 将字节流存储到文件中,并且将一个文件种的ts,进行拼接视频
with open('./video/{}/{}/{}{}{}'.format(i["category"], main_name, name,
vision_name(select_definition()), ".mp4"),
'ab+') as f:
f.write(response5.content)
else:
continue
except:
print("出错原因可能是cookie过期,或者使用了没有购买部分资源的cookie")
if __name__ == '__main__':
main()
运行结果:
任务2.6 优化代码
任务实施
优化思路:局部使用类来优化代码与业务的优化(可以下载任意想下载的视频)
代码实例:
import requests
import json
import time
import re
import os
from fake_useragent import UserAgent
import random
#定义当一次下载的时候,判断是否因为名字输入错误下载失败
download_succed=False
# 定义随机请求头
def random_agent():
return UserAgent().random
# 定义时间戳函数
def timestamp():
return str(int(time.time() * 1000))
# 选择清晰度
def select_definition():
# 0是分辨率为1280_720,1是分辨率为640_360,2是分辨率为720_480
return 0 # 默认为最高画质,可手动修改
# 对应的画质,为了起名字
def vision_name(number):
# 高清,流畅,标清
return ["高清", "流畅", "标清"][number]
#让用户输入想要下载的课程名称
def select_course():
return input("请复制粘贴上面的任意一门课程,进行下载")
#定义查询课程与下载课程重复的部分作为类,减少代码
class parent(object):
# 定义最初请求的时间戳
time1 = timestamp()
data1 = {
'timestamp': time1
}
header = {
"Cookie": "BIDUPSID=906E2DEBFC241C8A000956A2BA4AE53B; PSTM=1581049358; BAIDUID=906E2DEBFC241C8ADC25849A4A3C310E:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; jshunter-uuid=58f2b1c7-d086-4b27-bc09-4db0bff09d24; Hm_lvt_616afad8d6f2293d83c77626d3ed6371=1582559448,1582595860,1582637225,1582681971; H_PS_PSSID=30746_1455_21113_30840_30823; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=6; BDUSS=n5pVXJDN1RXdkVvOWoxYUtDdTBhVy11TXFCWDR2OHlseHF0Z1NJaS03SFlhWDFlRUFBQUFBJCQAAAAAAQAAAAEAAABDXKcNTm9fbGF0ZXJfQQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANjcVV7Y3FVea; Hm_lpvt_616afad8d6f2293d83c77626d3ed6371=1582685409",
'Referer': 'http://abcxueyuan.baidu.com/',
'User-Agent': random_agent(),
}
# 通过一系列操作获取最终需要的请求的视频url的接口的必备参数
response1 = requests.get('http://abcxueyuan.baidu.com/yunzhim/wenku/getActivityForm?timestamp=1582614705092',
headers=header, data=data1)
response1_json = response1.json()
#定义返回所有课程的方法
@classmethod
def return_all_course(cls):
for j in [i for i in parent.response1_json["data"]["modules"][1]["classList"]]:
for z in [k["name"] for k in j["classes"]]:
yield z
#定义返回所有专区,过滤掉实践专区,因为不是视频
@classmethod
def return_json(cls):
return [i for i in parent.response1_json["data"]["modules"][1]["classList"]][:-1]
#定义下载方法
def down_course(course):
global download_succed
#遍历专区列表
for i in range(len(parent.return_json())):
# 获取专区的资源
single_parent=parent.return_json()[i]["classes"]
# print(single_parent)
#遍历某个专区的课程
for value in single_parent:
#判断是不是用户想要的课程
if value["name"] == course:
#获取系列名称
series_name = value["category"]
# print(main_name)
# 获取courseId参数
courseId = re.findall("courseId=(\d+)", value['link'])[0]
# print(courseId)
data2 = {
'timestamp': parent.time1,
'courseId': courseId
}
# 创建课程视频目录
if not os.path.exists("./video"):
os.makedirs("./video")
# 创建系列名字
if not os.path.exists("./video/{}".format(series_name)):
os.makedirs("./video/{}".format(series_name))
#创建课程名称
if not os.path.exists("./video/{}/{}".format(series_name,value["name"])):
os.makedirs("./video/{}/{}".format(series_name,value["name"]))
response2 = requests.get(
"http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/showCourseMainMessage?timestamp={}&courseId={}".format(
parent.time1, courseId), data=data2, headers=parent.header)
response2_json = response2.json()
for j in response2_json["data"]["sectionAndVideos"]:
# 获取参数sectionId
sectionId = j["sectionDo"]["id"]
for k in j["sectionDo"]["videos"]:
# 获取参数videoId
videoId = k["id"]
# 获取参数mediaId
mediaId = k["mediaId"]
# 获取name
name = k["name"]
# print(sectionId,videoId,mediaId,courseId)
data3 = {
"timestamp": parent.time1,
"courseId": courseId,
"sectionId": sectionId,
"videoId": videoId,
"mediaId": mediaId
}
response3 = requests.get(
'http://abcxueyuan.baidu.com/yunzhim/courseSectionVideo/playVideo?timestamp={}&courseId={}§ionId={}&videoId={}&mediaId={}'.format(
timestamp(), courseId, sectionId, videoId, mediaId), data=data3, headers=parent.header)
response3_json = response3.json()
# print(response3.text)
print("查看返回的数据", response3_json)
# 进行异常处理,收费视频无法下载,避免报错
try:
# 画质的选择
vision = [u for u in response3_json["data"]["getMediaResourceResponse"]["playableUrlList"]][
select_definition()]
# 获取url
m3u8_url = vision["url"]
# 音频文件
print("搜索到音频文件,准备下载")
print(m3u8_url)
response4 = requests.get(m3u8_url)
# 获取文本
response4_html = response4.text
# 截取前面的从右向左第一个斜杠到最前面的url
m3u8_url_ts_url = m3u8_url[:m3u8_url.rfind("/")]
# print(m3u8_url_ts_url)
# 将我们要找的ts拿出来
for y in response4_html.split("\n"):
if y[-3:] == ".ts":
response5 = requests.get("{}/{}".format(m3u8_url_ts_url, y))
# 请求完毕,进行随机等待
time.sleep(random.random())
print("正在存储{}请稍等".format(y))
# 将字节流存储到文件中,并且将一个文件种的ts,进行拼接视频
with open('./video/{}/{}/{}{}{}'.format(series_name,value["name"],name,
vision_name(select_definition()), ".mp4"),
'ab+') as f:
f.write(response5.content)
else:
continue
print("已成功")
#下载成功
download_succed = True
except:
print("出错原因可能是cookie过期,或者使用了没有购买部分资源的cookie")
def main():
global download_succed
print("所有的课程如下:")
for i in parent.return_all_course():
print(i)
down_course(select_course())
if download_succed:
print("下载完成,期待你的下次使用")
else:
print("你好,你的课程名字输入错误,下载失败")
if __name__ == '__main__':
main()
运行结果:
