用YOLOV4实现街景字符编码识别
目录
- 赛题理解
- 方法选择
- Ubuntu下darknet的安装
- 数据处理
- 模型训练
- voc.names
- number.data
- yolo.cfg
- 正式训练
- 结果验证
- 小结
赛题理解
这次参加的是阿里天池和datawhale发起的街景字符编码识别赛事,赛事的网址为https://tianchi.aliyun.com/competition/entrance/531795/introduction
几天提交下来,现在最高的正确率在0.89左右,下面是我每次提交的正确率:
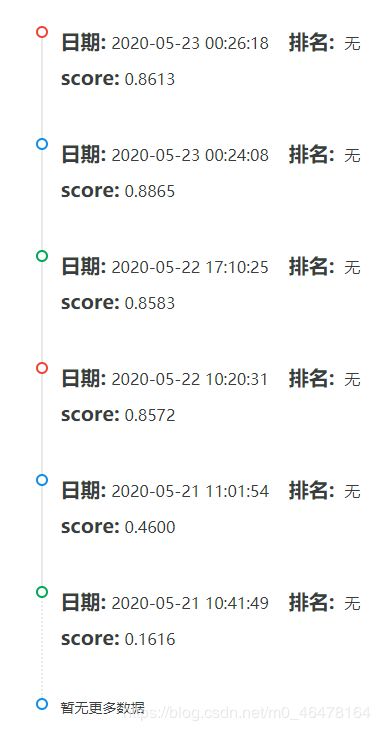 之后我会详细叙述每次提交的过程和之后改进的措施。
之后我会详细叙述每次提交的过程和之后改进的措施。
方法选择
这次的题目是很典型的字符识别问题,一张图片里有多个字符,将它们全部识别出来就算对,识别错误、识别多了和识别少了都算错。那么首先很快就有两个思路:
一是把问题转换为定长字符识别,用简单的卷积神经网络训练模型,0~9识别为0~9,空白字符用其它方式表示。
第二种就是我采用的方法,将问题转化为目标识别问题,用yolo或者fastrcnn来训练模型。虽然最终结果只要将字符识别出来就行了,不用额外进行定位,但用目标检测模型可以很好的简化问题,所以就采用了第二种方法。而在fastrcnn和yolo之间,我比较常用yolo,但是理论上fastrcnn在准确率上表现是优于yolo模型的,yolo的优势在于识别速度快,而在这个题目中对速度并没有要求,所以追求更高准确率可以去尝试用fastrcnn解决这个问题。
Ubuntu下darknet的安装
安装darknet的资料网上有很多,这里就不再过多赘述了,主要是简要介绍一下流程。首先CUDA、cuDNN以及OpenCV是肯定需要的,如果没有这些,对于比赛中3W张图片的训练集,训练时间肯定是会大大拉长的。在安装好这些后,在github上访问https://github.com/AlexeyAB/darknet,然后git clone就行了。
最终文件夹里有这些文件:
(这里我是截的windows下的图,但是实际上我是在Ubuntu下操作的,因为Ubuntu用的不是很多,而且在Ubuntu下打开后面数据集3W张图片的文件夹会很卡,所以除了训练模型,其他操作我都是在windows下进行的。)
在实际运行前,还要下载yolov4的权重文件,yolov4.weights
然后打开Makefile,
GPU=0
CUDNN=0
CUDNN_HALF=0
OPENCV=0
AVX=0
OPENMP=0
LIBSO=0
ZED_CAMERA=0 # ZED SDK 3.0 and above
ZED_CAMERA_v2_8=0 # ZED SDK 2.X
这个时候我是习惯先什么都不改,确保GPU/CUDNN/OPENCV都等于0。然后在终端运行
make -j12 #多核电脑可以在-j后加上核数乘2的数字,可以加快编译的速度
命令,之后就会生成一个darknet的可执行文件,然后运行
./darknet detect cfg/yolov4.cfg yolov4.weights data/person.jpg
程序运行一段时间后,返回
horse: 100%
person: 100%
dog: 99%
证明darknet框架成功下载,没有下错、少下文件等情况,之后解决GPU的问题,将Makefile改为
GPU=1
CUDNN=1
CUDNN_HALF=0
OPENCV=1
重复上述步骤。
再编译,那么你的yolo现在就会基于GPU进行运算了,速度会比之前快很多。
数据处理
在安装好darknet后,接下来就是要处理数据了。因为官方给的数据集和yolo训练需要的数据还是有很大不同的,就拿训练集为例,官方给名为mchar_train.json,用Jupyter notebook读取:
import json
import pprint
f = open(
"mchar_train.json",
encoding='utf-8')
data = json.load(f)
pprint.pprint(data)
结果为
{'000000.png': {'height': [219, 219],
'label': [1, 9],
'left': [246, 323],
'top': [77, 81],
'width': [81, 96]},
'000001.png': {'height': [32, 32],
'label': [2, 3],
'left': [77, 98],
'top': [29, 25],
'width': [23, 26]},
'000002.png': {'height': [15, 15],
'label': [2, 5],
'left': [17, 25],
'top': [5, 5],
'width': [8, 9]},
'000003.png': {'height': [34, 34],
...
以000000.png为例,代表该图有1和9两个数字,每个数字各有height、left、top和width 4个属性
| top | height | left | width |
|---|---|---|---|
| 左上角坐标X | 字符高度 | 左上角坐标Y | 字符宽度 |
也就是

但是yolo训练需要的数据集格式不一样,yolo需要两个文件表示训练集,分别是1个文件表示所有训练集图片的位置和名字:
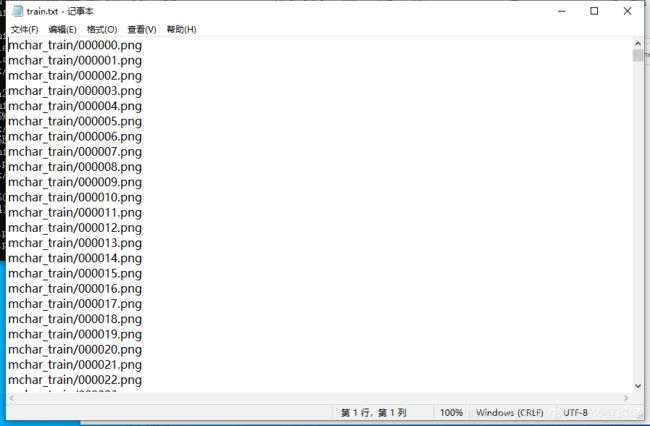
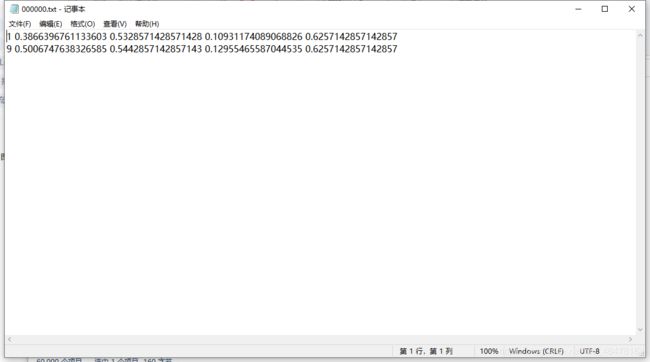
另一个个文件表示每张图片标注框的位置:

就是说对于3W张图片的训练集,我们需要1个train.txt文件,3W张图片,3W个和图片名字对应的标注框文件。
train.txt的生成方法很简单:
import os
f = open('train.txt','w')
for i in os.listdir(r'input\mchar_train'):
f.write(r'mchar_train/'+i)
f.write('\n')
f.close()
对于与图片名字对应的标注框文件,我们要生成的格式为:
1 0.3866396761133603 0.5328571428571428 0.10931174089068826 0.6257142857142857
标签
| 标签 | 中心点x | 中心点y | 标注框宽度 | 标准框高度 |
|---|---|---|---|---|
| 1 | 0.38 | 0.53 | 0.10 | 0.62 |
其中中心点x 、中心点y、标注框宽度、标准框高度都是比例,生成这个文件的方法如下:
import os
import cv2
import json
def process(dict1,shape):
l=''
for i in range(len(dict1['left'])):
l += str(dict1['label'][i])+' '+\
str((dict1['left'][i]+dict1['width'][i]/2)/shape[1])+' '+\
str((dict1['top'][i]+dict1['height'][i]/2)/shape[0])+' '+\
str(dict1['width'][i]/shape[1])+' '+\
str(dict1['height'][i]/shape[0])\
+'\n'
return l
f = open(
"mchar_train.json",
encoding='utf-8')
data = json.load(f)
for i in data:
img = cv2.imread(r'mchar_train'+'\\'+i)
shape = img.shape
f = open(r'input\mchar_train'+i[0:6]+'.txt','w')
f.write(process(data[i],shape))
f.close()
这样训练集数据就处理完毕了,同样之后对验证集也做相同的处理。
模型训练
在darknet-master目录下新建一个文件夹,命名为project_yolov4,我们的模型文件就放在这里面,方便区分和后续改变模型。就比如说我总共用了3个模型,分别命名为project_yolotiny,project_yolov3,project_yolov4,后面如果有什么想法,就直接找到相应模型做更改就行了。
文件夹结构如下:
其中backup存放训练过程中的模型,cfg存放number.data和yolov3-tiny.cfg,data里存放voc.names文件。
backup开始时是空文件夹,
yolov3-tiny.cfg从darknet-master\cfg中复制而来,number.data从darknet-master\cfg复制coco.data重命名而来,
voc.names来自darknet-master\data。
voc.names
将voc.names改成以下内容:
0
1
2
3
4
5
6
7
8
9
这个就是你显示在图片上的标签。
number.data
将number.data改成以下内容:
classes= 10 #总共有10个类别
train = train.txt #train.txt指向训练文件所在地
valid = val.txt #val.txt指向验证文件所在地
names = project_yolov4/data/voc.names #标签名文件所在地
backup = project_yolov4/backup/ #训练中weights存放的地点
yolo.cfg
然后就是修改你的.cfg文件了。cfg文件就是你yolo的网络结构,这对于最后分类器的效果有很大影响,这里主要说一些比较重要的需要修改的地方:
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=2
width=320
height=320
channels=3
这是文件的开头,batch是你随机梯度下降所用图片数量的大小,但是并不是一次就计算一个batch,二是一次计算batch/subdivisions张图片,然后计算完一个batch的图片后加起来进行一次随机梯度下降。也就是说你需要调节的只有subdivisions参数。这个跟你的显存和图片大小有关,如果显存大、图片小,subdivisions就小,如果显存小,图片大,subdivisions就大。图中subdivisions为2,就是一次计算32张图片。这里有几个我使用的参数,在显卡为2060s的情况下,用yolov3tiny,subdivisions为2,yolov3为16~32,yolov4为32~64。
然后是20行左右
max_batches = 10000
policy=steps
steps= 8000,9000
这里要改的参数是max_batches和steps。max_batches是迭代多少个batches,作者建议是2000*classes数,但实际上还是看训练的过程,主要是什么时候loss不再下降,我的yolov3-tiny就训练了10000步,yolov4训练了30000步。
steps改为max_batches的0.8和0.9。
之后在文件末尾会看到3个conv-yolo结构,tiny中只有2个。如下:
[convolutional]
size=1
stride=1
pad=1
filters=45
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=10
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
将classes改为训练类别数10,filters改为3*(anchor数+classes),也就是45。这样就大功告成,可以开始训练模型了。
正式训练
在Ubuntu下,darknet-master文件夹中运行终端,输入命令
./darknet detector train project-yolotiny/cfg/number.data project-yolotiny/cfg/yolov3-tiny.cfg yolov3-tiny.conv.11
其中yolov3-tiny.conv.11是预训练模型,yolov3是darknet53.conv.74,yolov4是yolov4.conv.137。这个可以根据你的cfg文件进行更改。(其实也不是一定要用这些预训练模型,其中我在运行yolov4时,用官方的预训练模型200步左右loss出现nan的情况,最后还是用自己之前训练的模型做的替代)
然后就是等待了。
这之后就是不停调参的过程,训练yolov3-tiny的过程图如下:
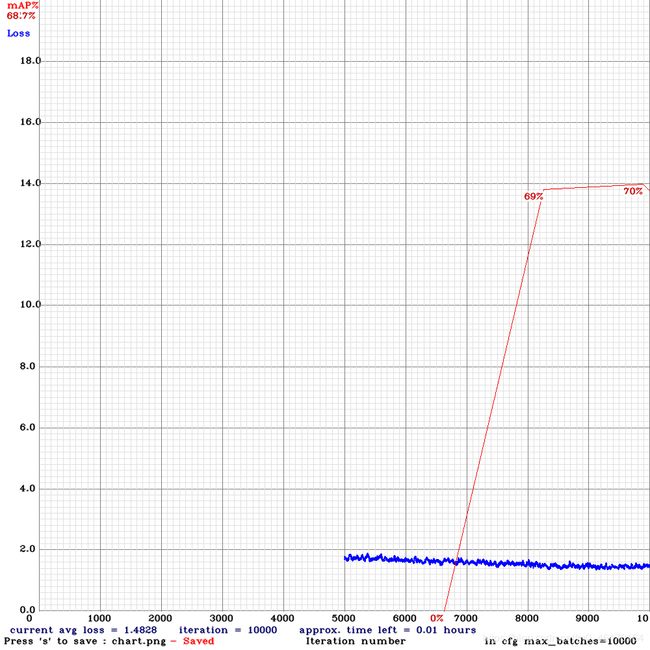
训练过程中,每100步会储存一个yolov3-tiny_last.weights,每100步会储存一个yolov3-tiny_x000.weights,之后可以用这些权重做验证。
结果验证
模型训练完成后,将测试图片传入,生成json文件,读取过程如下:
import json
import pprint
from collections import defaultdict
f = open(
"E:/result.json",
encoding='utf-8')
data = json.load(f)
pprint.pprint(data)
结果如下:
[{'filename': '/home/chronicle/darknet-master/mchar_test_a/000000.png',
'frame_id': 1,
'objects': [{'class_id': 9,
'confidence': 0.854373,
'name': '9',
'relative_coordinates': {'center_x': 0.542882,
'center_y': 0.46038,
'height': 0.670167,
'width': 0.178935}},
{'class_id': 6,
'confidence': 0.644879,
'name': '6',
'relative_coordinates': {'center_x': 0.362152,
'center_y': 0.459418,
'height': 0.585337,
'width': 0.185117}},
{'class_id': 1,
'confidence': 0.297224,
'name': '1',
'relative_coordinates': {'center_x': 0.286442,
'center_y': 0.517485,
'height': 0.631283,
'width': 0.168805}}]},
{'filename': '/home/chronicle/darknet-master/mchar_test_a/000001.png',
'frame_id': 2,
'objects': [{'class_id': 9,
'confidence': 0.941694,
'name': '9',
'relative_coordinates': {'center_x': 0.453235,
'center_y': 0.45478,
'height': 0.515545,
'width': 0.187647}},
{'class_id': 2,
'confidence': 0.903534,
'name': '2',
'relative_coordinates': {'center_x': 0.274208,
'center_y': 0.601338,
'height': 0.539937,
'width': 0.213464}},
{'class_id': 0,
'confidence': 0.930464,
'name': '0',
'relative_coordinates': {'center_x': 0.643067,
'center_y': 0.33342,
'height': 0.545984,
'width': 0.205608}}]},
{'filename': '/home/chronicle/darknet-master/mchar_test_a/000002.png',
'frame_id': 3,
'objects': [{'class_id': 4,
'confidence': 0.509182,
'name': '4',
'relative_coordinates': {'center_x': 0.278375,
'center_y': 0.46035,
'height': 0.485015,
'width': 0.190665}},
{'class_id': 3,
'confidence': 0.711077,
'name': '3',
'relative_coordinates': {'center_x': 0.615338,
'center_y': 0.569178,
'height': 0.49089,
'width': 0.184246}},
{'class_id': 1,
'confidence': 0.880182,
'name': '1',
'relative_coordinates': {'center_x': 0.451903,
'center_y': 0.533386,
'height': 0.500637,
'width': 0.152359}},
{'class_id': 1,
'confidence': 0.811803,
'name': '1',
'relative_coordinates': {'center_x': 0.285075,
'center_y': 0.460338,
'height': 0.519091,
'width': 0.197285}}]},
这就是检测的结果,然后将结果进行一定的处理,就可以上传查看成绩了。
处理的方法以及每次提交准确率是如何提升的后续再更。
小结
后续忙完毕业的事情,再更一下对模型结构进行的修改以及后续数据的处理方法,顺便讲一下第一次提交丢人的0.16怎么来的。过段时间再调一下看得分能不能突破0.9的大关,不行的话就只能换方法了。