零基础Python(三)
Python之文件操作
python的文件操作主要方法是open,help(open)或者dir(open)看看open以及相关的方法吧:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Open file and return a stream. Raise OSError upon failure.
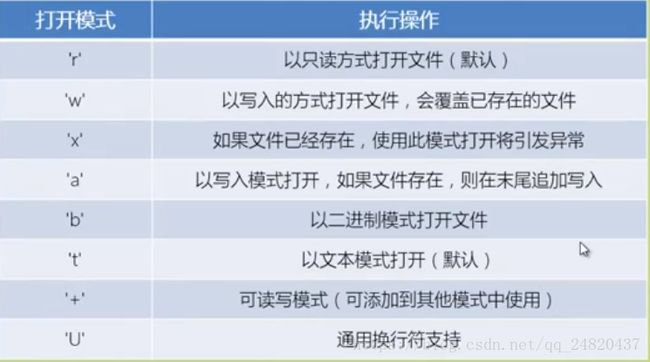
可以看出这个方法就是用来打开文件并返回流的。open只有一个必须传的参数就是file,也就是file的路径,其他的都有默认值,不过一般还会用到mode这个参数,以什么方式打开file,取值有如下几个:
`file1=open('D:\\6.txt')`
file1
--》
<_io.TextIOWrapper name='D:\\6.txt' mode='r' encoding='cp936'>
路径中用两个斜杠,是因为需要转义,没毛病
文件对象方法:
1:f.close() : 关闭文件
2:f.read(size=-1) :从文件中读取size个字符,当未给定size或给定负值的时候,读取剩余的所有字符, 然后作为字符串返回
3:f.readline():以写入模式打开,如果文件存在,则在末尾追加写入
4:f.writeline(seq):向文件写入字符串序列seq,seq应该是一个返回字符串的可迭代对象
5:f.seek(offset,from):在文件中移动文件指针,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节
6:f.tell():返回当前在文件中的位置
7:with:关键字with在不需要访问文件后将其关闭。
ex:
temp=file1.read(100)
temp
--》"adb server version (32) doesn't match this client (39); killing...\n* daemon started successfully *\ni"
temp2=file1.tell()
temp2
--》102
file1.seek(0,0)
--》0(定位到文件初始位置,然后调用readline读第一行)
file1.readline()
-->"adb server version (32) doesn't match this client (39); killing...\n"
这时候直接list(file1),就可以把文件放进list中并输出出来,但是有可能文件格式有问题,比如我的txt是gbk就会报错,解决方法就是打开文件的时候指定格式:
file2= open('order.log','r', encoding='UTF-8')
有可能文件太大导致有些卡。
可以直接用一下代码,将文件一行一行输出出来:
for each_line in file1:
print(each_line)
关于文件写入,write、writeline方法,如果没有指定是w或者其他可编辑的模式,写入会报io异常,我们可以新建一个txt文件指定模式:
file2=open('D:\\test.txt','w')
file2.write('人活着究竟有什么意思呢?')
到这一步只是将内容放入了缓冲区了,还没有写入到文件里面,不信可以看看新建的文件里面有没有内容,最后需要调用:
file2.close()方法,将缓冲区内容写入到文件中去。
打开文件常用结构
close()语句较容易导致错误,可以使用以下格式来打开文本文件:
with open('D:\\pyTest.txt') as fileContent:
contents=fileContent.read()
print(contents)
***********************************文件内容********************************
人生若只如初见,何事秋风悲画扇。
这种结构是:只管打开文件,并在需要时使用它,python自会在核实的时候自动将其关闭。
文件路径
windows下文件路径是用的反斜杠‘\’,但因为反斜杠在python中是转义字符,所以我们需要用两个反斜杠来表示一个反斜杠,所以上面路径里是两个反斜杠。
创建一个包含文件各行内容的列表
使用with关键字时,open()返回的文件对象只在with代码块内可用。如果想在with代码块外访问文件的内容,可以在with代码块内将文件内容的各行存储在一个列表中。这样外部就可以使用了,ex:
>>> with open("D:\\pyTest.txt") as fileContent:
list1=fileContent.readlines()
>>> for item in list1:
print(item)
***********************************文件内容********************************
人生若只如初见,何事秋风悲画扇。
>>>
使用文件的内容
在使用文件内容的时候,我们有时候需要去除换行符、空格,这时候我们就可以使用list的strip()方法去去除空格;ex:
我们修改一下文件内容,加几个空格:

然后,我们再读:
>>> with open("D:\\pyTest.txt") as fileContent:
list1=fileContent.readlines()
>>> for item in list1:
print(item)
***********************************文件内容********************************
人生若只如初见,何事秋风悲画扇。
>>> for item in list1:
print(item.strip())
***********************************文件内容********************************
人生若只如初见,何事秋风悲画扇。
>>>
当文件存储的是数字时,更能体现strip()的重要性。
写入文件
>>> with open('D:\\'+fileName,'w') as newFile:
newFile.write('I love programming!')
19
返回的是本次添加的字符数,这个是包含空格的。
关键在于,打开文件模式要为’w’,也就是写入文件,可别再用’r’了。
还需要注意一点,write()函数,不会再文本末尾添加换行符,如果要写入多行,别忘了在语句后面加上换行符,也就是**’\n’**.
附加到文件
如果,我们再次写入:
>>> with open('D:\\'+fileName,'w') as newFile:
newFile.write('That\'s good!')
12
这里你就会发现,并不是附加到文件末尾,而是复写了文件,如果我们想附加到文件末尾,那么就可以使用’a’模式打开文件,也就是append的意思。ex:
>>> with open('D:\\'+fileName,'a') as newFile:
newFile.write('\n人生若只如初见!')
9
这时再打开文件,内容就变成了:
That's good!
人生若只如初见!
异常
>>> try:
c=10/0
print (c)
except ZeroDivisionError:
print('hello')
模块
模块是一个包含所有你定义函数和变量的文件,其后缀名是.py,模块是可以被别的程序引入,以使用该模块中的函数等功能。
ex:
>>> import random
>>> scrent=random.randint(1,10)
这里如果不import random ,是会报错的。
1.首先说OS(Operating System 操作系统)模块。
① getcwd() :返回当前工作目录
② chdir(path) :改变工作目录
③ listdir(path='.'):列举指定目录中的文件名(’.‘表示当前目录,’…‘表示上一级目录)
④mkdir(path):创建单层目录,如该目录已存在抛出异常
⑤ remove(path):删除文件
⑥rmdir(path):删除单层目录,如该目录非空则抛出异常
⑦removedirs(path):递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常
⑧rename(old,new):将文件old命名为new
⑨system(command):运行系统的shell命令
以下是支持路径操作常用到的一些定义,支持所有平台(每个平台的路径都有他自己的脾气)
①os.curdir:指代当前目录(’.’)
②os.pardir:指代上一级目录(’…’)
③os.sep:输出操作系统特定的路径分隔符(Win下为’\’,Linux为’/’)
④os.linesep:当前平台使用的行终止符(Win下为’\r\n’,Linux下为’\n’)
⑤os.name:指代当前使用的操作系统(包括:‘posix’,‘nt’,‘mac’,‘os2’,‘ce’,‘java’)
>>> import os
>>> os.getcwd()
'C:\\Program Files\\Python36'
>>> os.listdir(path='.')
['DLLs', 'Doc', 'include', 'Lib', 'libs', 'LICENSE.txt', 'NEWS.txt', 'python.exe', 'python.pdb', 'python3.dll', 'python36.dll', 'python36.pdb', 'python36_d.dll', 'python36_d.pdb', 'python3_d.dll', 'pythonw.exe', 'pythonw.pdb', 'pythonw_d.exe', 'pythonw_d.pdb', 'python_d.exe', 'python_d.pdb', 'Scripts', 'tcl', 'Tools', 'vcruntime140.dll']
>>> os.listdir('.')
['DLLs', 'Doc', 'include', 'Lib', 'libs', 'LICENSE.txt', 'NEWS.txt', 'python.exe', 'python.pdb', 'python3.dll', 'python36.dll', 'python36.pdb', 'python36_d.dll', 'python36_d.pdb', 'python3_d.dll', 'pythonw.exe', 'pythonw.pdb', 'pythonw_d.exe', 'pythonw_d.pdb', 'python_d.exe', 'python_d.pdb', 'Scripts', 'tcl', 'Tools', 'vcruntime140.dll']
>>> os.mkdir('zzgTest')
Traceback (most recent call last):
File "", line 1, in
os.mkdir('zzgTest')
PermissionError: [WinError 5] 拒绝访问。: 'zzgTest'
>>> import os
>>> os.listdir('.')
['DLLs', 'Doc', 'include', 'Lib', 'libs', 'LICENSE.txt', 'NEWS.txt', 'python.exe', 'python3.dll', 'python37.dll', 'pythonw.exe', 'Scripts', 'tcl', 'Tools', 'vcruntime140.dll']
>>> os.curdir()
Traceback (most recent call last):
File "", line 1, in
os.curdir()
TypeError: 'str' object is not callable
>>> os.getcwd()
'C:\\Users\\18041\\AppData\\Local\\Programs\\Python\\Python37'
>>> os.chdir('D:\\Pyws')
>>> os.getcwd()
'D:\\Pyws'
>>> os.listdir('.')
['testDir']
>>> os.mkdir
>>> os.mkdir('.\\test2')
>>> os.listdir()
['test2', 'testDir']
>>> os.remove('.\\test2')
Traceback (most recent call last):
File "", line 1, in
os.remove('.\\test2')
PermissionError: [WinError 5] 拒绝访问。: '.\\test2'
>>> os.rmdir('.\\test2')
>>> os.getcwd()
'D:\\Pyws'
>>> os.listdir()
['testDir']
>>> os.rename
>>> os.rename('.\\testDir','.\\zzgTestDir')
>>> os.listdir('.')
['zzgTestDir']
os.path模块中关于路径常用的函数使用方法:
①basename(path):去掉目录路径,单独返回文件名
②dirname(path):去掉文件名,单独返回目录路径
③join(path1[,path2[,...]]):将path1,path2各部分分组合成一个路径名
④split(path):分割文件名与路径,返回(f_path,f_name)元组。如果完全使用目录,它将会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在
⑤splitext(path):分离文件名与扩展名,返回(f_name,f_extension)元组
⑥getsize(file):返回指定文件的尺寸,单位是字节
⑦getatime(file):返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
⑧getctime(file):返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
⑨getmtime(file):返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
以下为函数返回True或False
exists(path): 判断指定路径(目录或文件)是否存在
isabs(path):判断指定路径是否为绝对路径
isdir(path):判断指定路径是否存在且是一个目录
isfile(path):判断指定路径是否存在且是一个文件
islink(path):判断指定路径是否存在且是一个符号链接
ismount(path):判断指定路径是否存在切实一个挂载点
samefile(path1,path2):判断path1和path2两个路径是否指向同一个文件
>>> os.name
'nt'
>>> os.getcwd()
'D:\\Pyws'
>>> os.path.basename(os.getcwd())
'Pyws'
>>> os.path.dirname(os.getcwd())
'D:\\'
>>> os.path.split(os.getcwd())
('D:\\', 'Pyws')
>>> os.path.splitext('D:\\Pyws\\zzgTestDir\\test.txt')
('D:\\Pyws\\zzgTestDir\\test', '.txt')
>>> os.path.getctime('D:\\Pyws\\zzgTestDir\\test.txt')
1539219852.6340446
>>> os.path.exists('D:\\Pyws\\zzgTestDir\\test.txt')
True
Pickle模块
当存储列表、字典类型、类时,如果保存先转换为String然后保存,那么获取的时候将会十分困难,而Pickl模块就是将这些复杂对象转换为二进制存储,存取十分的方便。
从对象转换为二进制类型的过程叫pickling
从二进制转换为对象的过程叫unpickling
存储实例:
>>> import pickle
>>> my_list=['秦时明月','天行九歌',3.14]
>>> pickle_file=open('D:\\my_list.pkl','wb')
>>> pickle.dump(my_list,pickle_file)
>>> pickle_file.close()
这里解释一下,首先先导入模块,这没问题,至于文件的后缀名可以随意,毕竟后缀名只是为了便于区分,打开模式一定要为’wb’,然后将list存储进文件,调用dump方法即可,最后不要忘记调用close方法,不然文件内容一直在缓冲区~
上面是存储,下面来讲读取:
>>> pickle_file=open('D:\\my_list.pkl','rb')
>>> mylist2=pickle.load(pickle_file)
>>> print(mylist2)
['秦时明月', '天行九歌', 3.14]
解释一下,打开模式为’rb’,然后调用load方法即可。
Tips:因为有可能字典或者类比较大,多个地方使用起来比较繁琐,这时候使用pickle存储起来调用比较方便(感觉就是数据封装成一个方法,方便调用,不过这点比起来还是没有java方便)
Python异常处理
python常见异常:
1.AssertionError :断言语句(assert)失败
2.AttributeError :尝试访问一个位置的对象属性
ex:
>>> my_list=['Fill']
>>> assert len(my_list) > 0
>>> my_list.pop()
'Fill'
>>> assert len(my_list) > 0
Traceback (most recent call last):
File "", line 1, in
assert len(my_list) > 0
AssertionError
>>> my_list.zzg
Traceback (most recent call last):
File "", line 1, in
my_list.zzg
AttributeError: 'list' object has no attribute 'zzg'
>>>
3.IndexError:索引超出序列的范围【确实很常见】
4.KeyError:字典中查找一个不存在的关键字
>>> my_dict={'one':1,'two':2}
>>> my_dict['one']
1
>>> my_dict['fuck']
Traceback (most recent call last):
File "", line 1, in
my_dict['fuck']
KeyError: 'fuck'
>>>
所以,字典可以用get方法,如果没有key,就什么都不返回
>>> my_dict.get('fuck')
>>>
5.OSError:操作系统产生的异常(例如打开一个不存在的文件)
6.SyntaxError:Python的语法错误,ex:
>>> print 'zzg'
SyntaxError: Missing parentheses in call to 'print'. Did you mean print('zzg'
7.TypeError:不同类型对象间的无效操作
>>> 1+'one'
Traceback (most recent call last):
File "", line 1, in
1+'one'
TypeError: unsupported operand type(s) for +: 'int' and 'str'
8.ZeroDivisionError:除数为零
捕获异常
1.try:
检测范围
except Exception[as reason]:
出现异常(Exception)后的处理代码
ex:
try:
f=open('一个不存在的文件.txt')
print(f.read())
f.close()
except OSError as reason:
print('文件出错!出错原因:'+str(reason))
========= RESTART: C:/Users/angel/Desktop/PythonDemo/tryException.py =========
文件出错!出错原因:[Errno 2] No such file or directory: '一个不存在的文件.txt'
可以同时捕获多个异常,ex:
try:
sum=1+'1'
f=open('一个不存在的文件.txt')
print(f.read())
f.close()
except OSError as reason:
print('文件出错!出错原因:'+str(reason))
except TypeError as reason:
print('算术运算出错!出错原因:'+str(reason))
========= RESTART: C:/Users/angel/Desktop/PythonDemo/tryException.py =========
算术运算出错!出错原因:unsupported operand type(s) for +: 'int' and 'str'
>>>
如果异常类型不再捕获的类型中,就会报错,ex:
try:
int('abc')
sum=1+'1'
f=open('一个不存在的文件.txt')
print(f.read())
f.close()
except OSError as reason:
print('文件出错!出错原因:'+str(reason))
except TypeError as reason:
print('算术运算出错!出错原因:'+str(reason))
========= RESTART: C:/Users/angel/Desktop/PythonDemo/tryException.py =========
Traceback (most recent call last):
File "C:/Users/angel/Desktop/PythonDemo/tryException.py", line 2, in
int('abc')
ValueError: invalid literal for int() with base 10: 'abc'
>>>
try语句中,一旦出现异常,剩下的语句将不会执行,这和java一个样,没啥说的,从上面可以看出就捕获了一个异常,因为不会走到第二个异常上。
还有一种姿势:
try:
sum=1+'1'
f=open('一个不存在的文件.txt')
print(f.read())
f.close()
except (OSError,TypeError) as reason:
print('文件出错!出错原因:'+str(reason))
2.try-finally捕获异常:
try:
检测范围
except Exception[as reason]:
出现异常(Exception)后的处理代码
finally:
无论如何都会被执行的代码
简洁的with语句
一般打开文件可能忘了关闭导致一系列异常,with语句能很好的帮我们解决这个问题。先看看,普通的open语句对文件的操作,ex:
try:
f = open('file.txt','w')
for each_line in f:
print(each_line)
except OSError as reason:
print('打开出错!'+str(reason))
finally:
f.close()
打开出错!not readable
这里需要注意,我们打开文件,除了文件不存在的问题,还有可能文件不可读的问题,所以用’w’状态打开,就可以很好的规避这个问题,不然tryexcept了,也会标红的。改为with语句:
try:
with open('file.txt','w') as f:
for each_line in f:
print(each_line)
except OSError as reason:
print('打开出错!'+str(reason))
打开出错!not readable