机器学习 | 特征重要性判断
聊聊feature_importances_
- 1 背景
- 2 原理
- 2.1 文字版
- 2.2 公式版
- 2.3 面试遇到的问题
- 3 Python实现
- 3.1 解决mac下用jupyter绘图不显示中文的问题
- 3.2 一个神奇的函数:np.argsort
- 4 参考
1 背景
在运用树模型建模的时候,常用的一个sklearn的子库就是看特征重要性,也就是feature_importances_,下面将从原理和Python代码实现两个角度来聊一聊!
2 原理
2.1 文字版
基于树的集成模型 特征的重要性是在所有单颗树上该特征重要性的一个平均值,而单颗树上特征重要性计算方法为:根据该特征进行分裂后平方损失的减少量的求和。
2.2 公式版

2.3 面试遇到的问题
问题:单颗决策树,分裂特征会重复出现吗?
答案:分类特征不会,而数值型特征可能会。具体见下方例子:
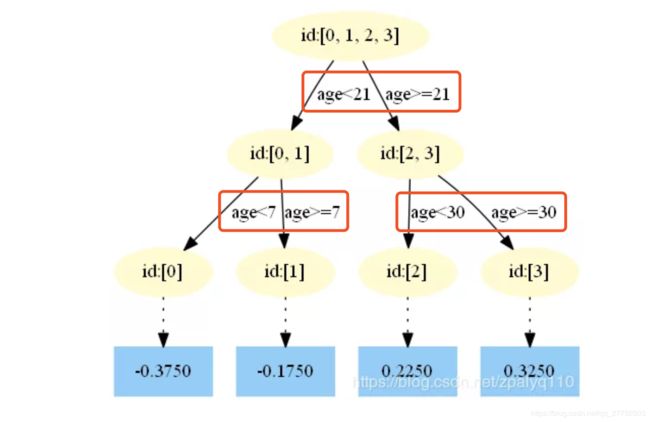
可以看到age这个数值型变量出现了好几次,因为分裂一次之后还可以细分,而分类型变量则不会,因为一旦分裂之后,对应子节点的样本中该类别即为同一类别,非常纯!
3 Python实现
直接封装好了一个函数!Show the code!
def plot_feature_importances(fea_imp, title, fea, pic_name):
# 函数作用:绘制变量重要性柱状图 显示重要性>0的变量
# fea_imp:方法的.feature_importances_
# title:图的标题
# fea:所有变量的名称
# pic_name:要保存的图片的名称
# 设置字体 使中文正常显示
import matplotlib as mpl
font_ch = mpl.font_manager.FontProperties(fname='/System/Library/Fonts/PingFang.ttc')
# 将重要性值标准化
fea_imp = 100.0*(fea_imp/max(fea_imp))
# 将得分从高到低排序
index_sorted = np.argsort(-fea_imp) # 降序排列
plt.figure(figsize=(16,4))
# 统计非0的个数
n = (fea_imp[index_sorted]>0).sum()
print('重要性非0的变量共有 %d 个' % n)
# 让X坐标轴上的标签居中显示 和n保持一致
pos = np.arange(n)+0.5
# 画图只画大于0的特征重要性部分
plt.bar(pos, fea_imp[index_sorted][:n], align='center')
plt.xticks(pos, np.array(fea)[index_sorted][:n], rotation=90, fontproperties = font_ch) # 转90度就可以了!
plt.ylabel('变量重要性得分', fontproperties = font_ch)
plt.title(title, fontproperties = font_ch)
plt.savefig(pic_name + '.png', dpi=100, bbox_inches='tight') # bbox_inches='tight'这个参数可以解决输出图片横轴标签显示不全的问题
plt.show()
其中有些函数还是用的蛮多的,总结一下:
3.1 解决mac下用jupyter绘图不显示中文的问题
两行代码轻松解决!
# 设置字体 使中文正常显示
import matplotlib as mpl
font_ch = mpl.font_manager.FontProperties(fname='/System/Library/Fonts/PingFang.ttc')
然后后面在绘图的时候,加上参数:fontproperties = font_ch 即可,注意要在所有地方都加!特别是有中文的地方!
3.2 一个神奇的函数:np.argsort
函数作用:返回一个numpy数组的按值进行顺序排列的对应的索引!听着是不是很拗口?举个栗子!
a = np.array([1,3,4,6,2,5])
a.argsort()
返回结果是什么呢?
array([0, 4, 1, 2, 5, 3])
这个该如何解释呢?一眼看过去,其实有点懵逼的!就会不自觉的想,诶,1和0对应有啥关系?千万不要陷入这个死胡同,而是自己先去把a这个数组进行升序排列!应该是[1,2,3,4,5,6] 然后这6个数分别对应的索引是多少呢?是不是就是[0, 4, 1, 2, 5, 3] ? 对的!没错!所以说返回的结果就是从小到大排序之后的值的对应的索引!
这样有什么好处呢? 知道了索引我就可以直接按顺序输出从小到大的数值!
那能不能降序排列呢?可以,非常简单!只要加个负号就好了!
np.argsort(-a)
输出为:
array([3, 5, 2, 1, 4, 0])
4 参考
- https://blog.csdn.net/ictcxq/article/details/78754905
- https://mp.weixin.qq.com/s/9SrciKW-nJJMA2BbTs5CLg