编译原理与编译构造 LR文法
本份课堂笔记来源于我院最最高大的七米八同学,不知道他用不用CSDN写博客,但是不管如何向他表示感谢。
LR文法——通用语法分析法,基于规约、FA
对于文法 B→αAβ,A→γ ,我们有自动机,确切地说,是分层的有限自动机(NFA),如下图。

对于每个状态(就是每个圈)的命名,我们不会和以前一样一路 A−Z 命名下来,而是会有特定的命名方式。
状态命名
状态命名: LR项{层的信息——用相应的产生式体现顺序——用点表示
就比如说,第一层的加黄的状态是 B→α⋅Aβ ,第一层加蓝的状态是 B→αAβ⋅ 。
第二层的最左边状态是 A→⋅γ 。
其中, B→αAβ⋅ 这种点在最后的 LR 项,叫做“可归约 LR 项”,否则叫做“移进 LR 项( shift LR item )”
状态的拓展
NFA{ϵ产生式→状态内部的拓展子集构造→状态之间的拓展(移点)
if( B→α⋅Aβ∈Ii ) {
A→⋅γ∈Ii
}
这个证明很简单,我们看一下之前的那张图, A→⋅γ 这个状态是由 B→α⋅Aβ 这个状态由 ϵ 边转换过去的,只需要结合之前的知识加上知道这是状态内部的拓展,就能得到结论了。
公式
B→α⋅βγ∈Ii →β B→αβ⋅γ∈Ij
看了看效果,我决定下面一个公式还是手画一下吧。。
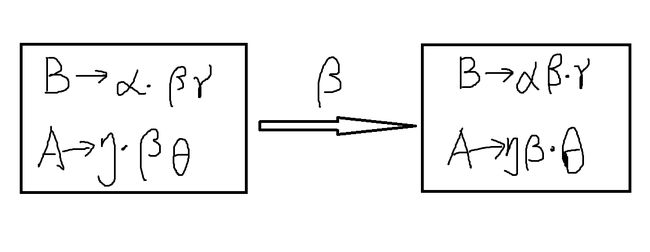
对于上面的两组公式, β 既可以是终结符,也可以是非终结符
转换模型
我们有这样的语法: ①E→E+T②E→T③T→T∗F④T→F⑤F→(E)⑥F→i ,要构造这个语法的转换模型。
首先讲一下LR转换模型,这个跟LL(1)的转换模型结构是差不多的。不过左边的栈变了,有一个状态栈和符号栈。LR分析程序,应该说差不多也是LR转换表,也变了。
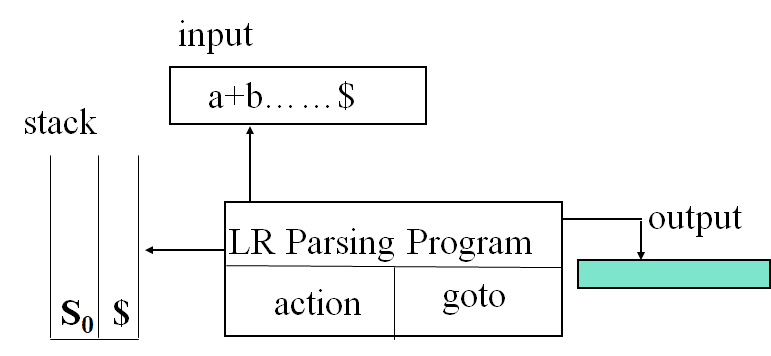
对于刚刚的语法,我们二话不说,先加一个0号产生式: S′→E
为什么要加一个0号产生式?因为这样使得分层状态自动机最上层有且仅有一个自动机,且有且仅有一个初始状态。
转换图
下面看一下分层有限状态自动机,如果看不懂的话可能需要补一补前面的课。
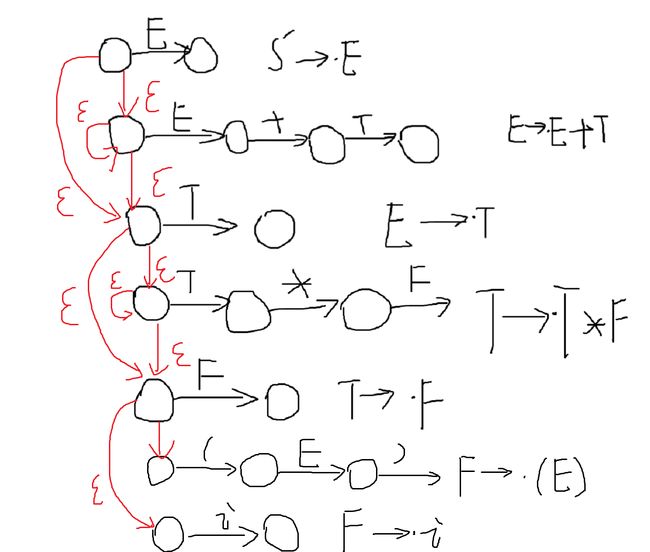
这个图主要是示意一下的 I0 是怎么得到的,跟以前的做法是一样的,通过 ϵ 产生式来得到。此时通过移点来获取别的状态,此处忽略过程,因为挺好懂的,直接看图就能看懂。

注意要结合前面的公式。
转换表
我们由上面的转换图来获取转换表。
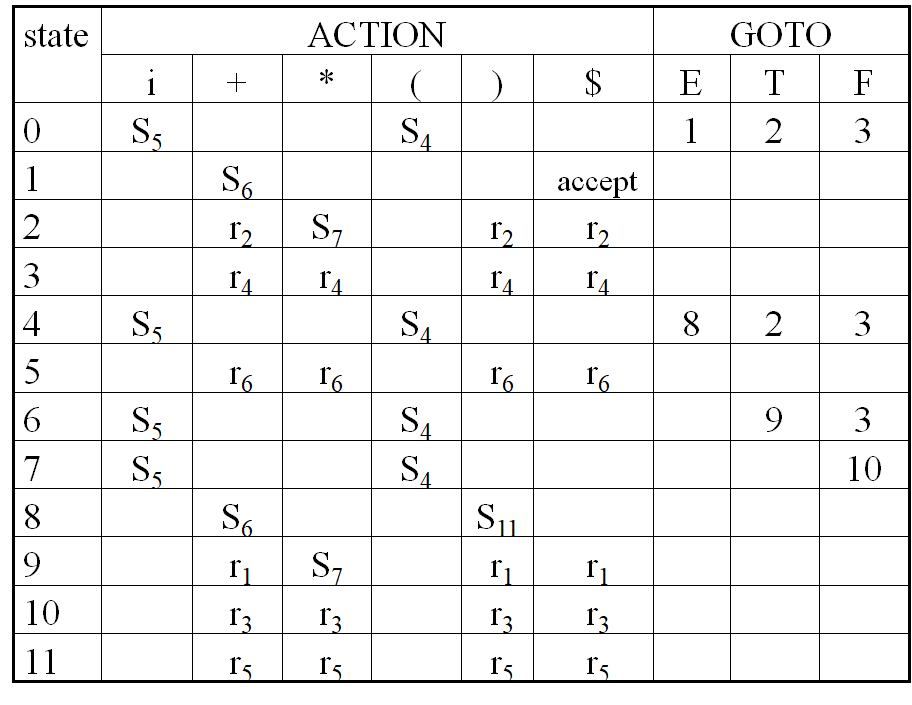
上图就是转换表,符号含义如下:
1) Sj means shift and stack state j, and the top of the stack change into(j,a);
2) rj means reduce by production numbered j;
3)accept means accept
4)blank means error
有以下的主要规则:



如果说这个不是很好理解的话,我们可以这么来看。首先 ACTION 表最上方全填终结符,另外要加一个 $ 符号,然后 GOTO 最上方全填非终结符。显然, GOTO 表相当好填,我们只需要在状态转换的箭头上找到非终结符,然后填就可以了。例如 I0→TI2 ,就显然有 。
。
对于填 Sx 这个也是很简单,我们只需要在状态转移的箭头上找到终结符就好了。例如 I0→iI5 ,我们就有

然后最复杂的显然是 rx 。此时我们把语法再拉过来: 0.S′→E1.E→E+T2.E→T3.T→T∗F4.T→F5.F→(E)6.F→i
我们只要在 Ii 中找最右是 ⋅ 的式子就行了,然后看这个点左边的式子是从上面的语法中哪一步得到的,就填 rx ,其中这个 x 是语法前面的序号。
算法
此时就是对着转换表来填状态栈和符号栈,此处借助一个实例来讲解。
对于刚刚的文法,检验 i∗i+i 是否合法。
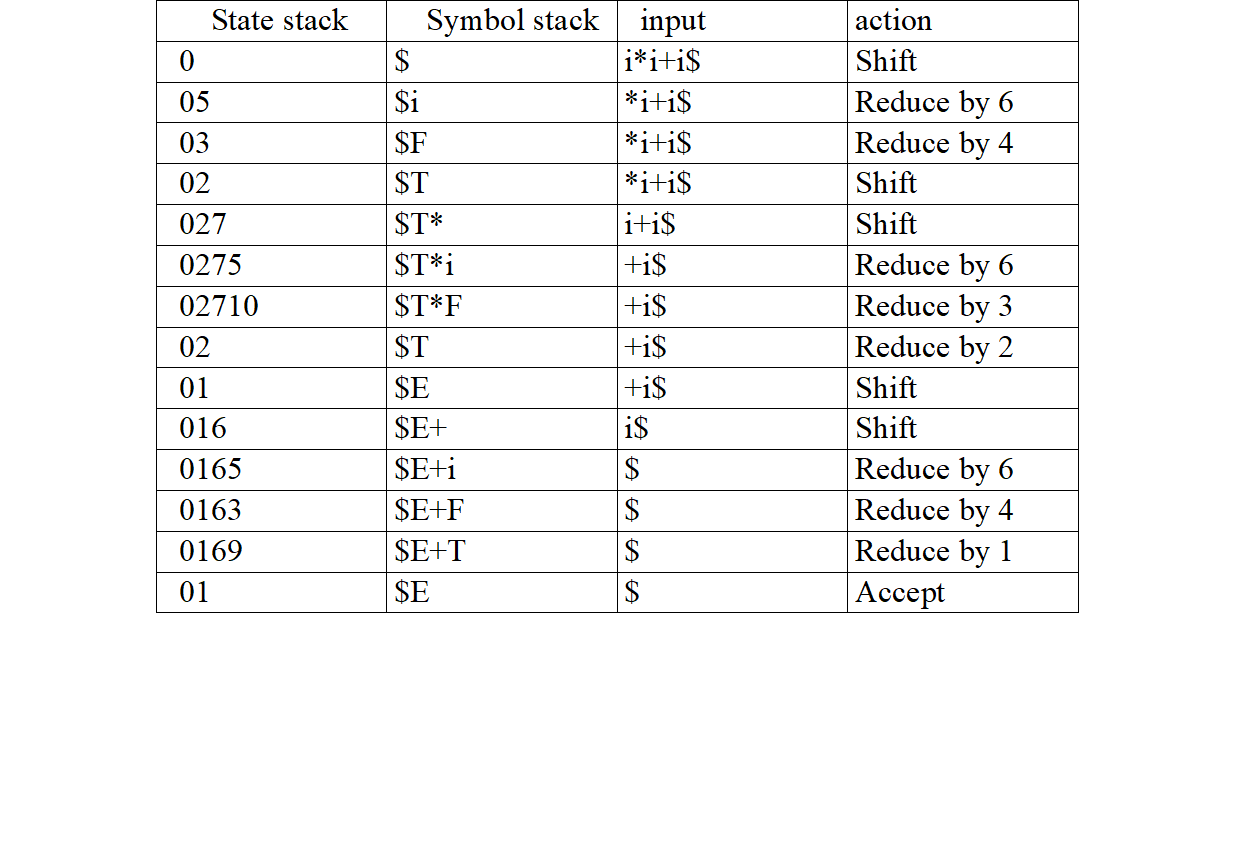
首先,二话不说,在状态栈里写一个0,在符号栈里写一个 $ 。然后输入的部分写要检验的式子和一个 $ , 因为我们可以认为之前省略了一步,即input为 $i∗i+i$ 的一步,因此此处填的是 Shift 操作。
状态栈栈顶是0,输入的最左边是 i ,查表得 S5 ,状态栈压入5,符号栈压入 i ,输入的指针右移。
状态栈栈顶是5,输入的最左边是 ∗ ,查表得 r6 。 r6 就是 rF→i ,所以将符号栈中的 i 弹出,压入 F 。由于 i 的长度是1,因此在状态栈中弹出一个元素。此时栈顶元素为0,查 S0,F ,是3,因此压3入状态栈。
具体算法如下:



构造分析树
构造分析树的方法就是根据刚刚的算法来构造。假设算法执行下来的步骤是 1→n ,那么构造分析树的时候就是从 n→1 ,根据栈上的元素变化来写。
以上讲的大概都是SLR(1)部分的内容。
SLR(1)是说,simple, left-to-right scan, •construct
a rightmost derivation in reverse
the number of input symbols of look ahead is 1
为什么simple?
不能分析所有的非二义文法,但是SLR(1)都是非二义文法。
备注
- 一个状态既存在可规约项目,又存在移进项目,可能导致出现二义性。既出现 S 又出现 r ,称为“移进-规约冲突”
- 有两个可规约项目,称为“规约-规约冲突”
SLR(1) → LR(1)
这一步相当于只加了一个预测符。
| 起点 | 状态内部扩展 | 状态之间扩展 | 可规约项目处理 |
|---|---|---|---|
| SLR(1) | S′→S | if B→α⋅Aβ∈Ii,then A→⋅γ∈Ii | 移点 |
| LR(1) | (S′→⋅S,$R) | if B→(α⋅Aβ,a)∈Ii,then (A→⋅γ,first(βa))∈Ii | 移点,相同预测符 |
对于文法: 1.S′→S2.S→L=R3.S→R4.L→∗R5.L→i6.R→L ,这个例子的详解见《LR1-1.pdf》《LR1-2.pdf》,若是有空我把这两个pdf加进来。
对于文法: 1.S′→S2.S→AaAb|BbBa3.A→ϵ4.B→ϵ ,这个例子的详解见《Lr1-3.pdf》,有空就加。
LR(1) → LALR(1)
这部分不要求掌握,所以就偷懒一点。。。
思路:合并同心状态(same core)
LA: look ahead
状态的心:去掉预测符之后的部分
若LR(1)的DFA出现同心状态,能合并,则LALR(1)状态数和SLR(1)状态数是相同的
由Yack生成语法分析程序为LALR(1)
举个例子来说明不能合并的现象:
I6:B→e⋅,cC→e⋅,d
I9:B→e⋅,dC→e⋅,c
由于在 I6 中,心是 B→e∗C→e∗ ,同理 I9 也是,因此符合合并的要求。但是合并后,此时会出现这么一种情况。
| State | Action | ||
|---|---|---|---|
| c | d | …… | |
| I69 | rB→erC→e | rC→erB→e |
此时出现规约-规约冲突,不行。