编译原理——LL(1)分析
前言:这是我学习编译原理,课程实验的内容,课程早已结束,现整理发表。
一、实验任务
- 存储文法;
- 计算给定文法所有非终结符的
FIRST集合; - 计算给定文法所有非终结符的
FOLLOW集合; - 构造该文法的
LL(1)文法的分析表 - 根据
LL(1)分析表判断文法是否LL(1)文法; - 完成完整的
LL(1)分析过程。
二、实验内容
- 确定文法的文件存储格式,存储文法的非终结符集合、开始符号、终结符集合和产生式规则集合。
要求为3个以上测试文法准备好相应的存储文件。 - 计算给定文法所有非终结符的
FIRST集合。 - 计算给定文法所有非终结符的
FOLLOW集合; - 确定
LL(1)分析表的文件存储格式。
要求为3个以上测试文法准备好相应LL(1)分析表的存储文件。 - 根据
LL(1)分析表判断文法是否LL(1)文法。
看每个表项是否最多只有一条候选式,如是该文法是LL(1)文法。 - 实现
LL(1)分析过程。
当 5. 判断出该文法是LL(1)文法时,要求给出3个以上输入串的LL(1)分析过程,并判断输入串是否该文法的合法句子。 - 完成完整的
LL(1)分析过程。
三、存储格式
- 文法
E->TE`
E`->+TE`|e
T->FT`
T`->*FT`|e
F->(E)|id
- 改变
E`用Y代替
T`用X代替
- 非终结符号
EYTXF
- 终结符号
i+*()$
- 文法改写存储
E,TY
Y,+TY
Y,e
T,FX
X,*FX
X,e
F,(E)
F,i
- 分析表用一个结构体的二维数组存储,会很复杂,看代码理解。
四、程序设计
- 结构体类
struct.h
注意理清里面的结构体嵌套。
#include
#ifndef MAXNUM
#define MAXNUM 100
#endif
#ifndef _STRUCT_H
#define _STRUCT_H
/******数据定义******/
struct rule
{ //一个文法
std::string startSymbol; //开始符号
std::string tuidao; //推导式
};
struct record{ //记录一个终结符号由那些产生式得出的
int num=0; //数量
int gramNum[MAXNUM]; //产生式的编号
};
struct set
{ //集合
char startSymbol; //非终结符
char set[MAXNUM]; //frist or follow集合
record gramNum[MAXNUM]; //记录一个终结符号是由哪些文法推导出的
int num = 0;
bool isExistE = false; //是否存在空串
};
struct tableCell{ //预测分析表的一个单元
int num=0;
rule cell[MAXNUM];
bool error=true;
};
#endif
- 获得
first和follow集文法类getFirFol.h
#include "getFirFol.h"
#include "struct.h"
#ifndef _LL_H
#define _LL_H
class LL{
public:
LL(getFirst_Follow *ff,std::string ts, std::string nts, std::string rl);
/***构造分析表***/
void fillInTheTable();
/***分析字符串***/
void analyzeChars(std::string path);
/***在对应的分析表单元格加入文法***/
bool addInTableCell(int h,int l,int gramNum);
private:
getFirst_Follow *getff;
std::string terSymbol; //终结符号集合
int tsLength=0; //终结符号数量
std::string nonTerSymbol; //非终结符号集合
int ntsLength=0; //非终结符号数量
rule *grammer = NULL; //文法
int gramNum = 0; //文法公式数目
tableCell **analyzeTable; //预测分析表
bool isLLGrammer=true; //判断是为LL(1)文法
};
#endif
- 主函数
main.cpp
#include"getFirFol.h"
#include"LL.h"
#include
#include
#include
#include
using namespace std;
int main(){
string ts="test1\\terminalSymbol.ll";
string nts="test1\\nonTerminalSymbol.ll";
string rl = "test1\\rule.ll";
string path="test1\\input1.ll";
getFirst_Follow gff(ts,nts,rl);
gff.getFirst();
gff.getFollow();
LL ll(&gff,ts,nts,rl);
ll.fillInTheTable();
ll.analyzeChars(path);
system("pause");
return 0;
}
五、实验测试
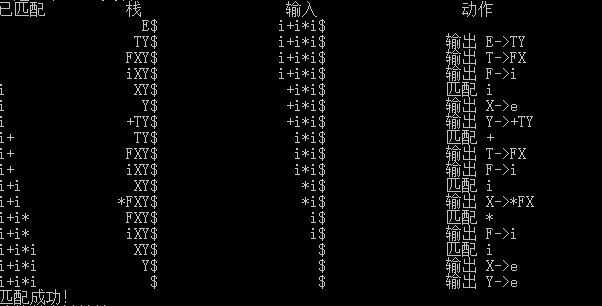
- 文法分析结果

LL(1)分析结果
1)输入串
i+i*i
2) 分析
六、实验总结
哇,东西好少,我也觉得好简单的感觉,这是还是当初我写的觉得放弃的代码么?
还是的,如果你看具体代码就觉得不那么简单了,尤其是入了结构体的坑,觉得用结构体好好用的,然后就不停的用,而上篇的代码和这篇的代码都是这样的产物。。。
总之,这篇是最后一篇编译原理的代码了,总共10个实验,前面4个必写,后面6个任选2个,要写6个实验,然后你会说不对啊,不够6个啊,系列不是只有4篇么?
呃,其实这篇是后面6个实验中的2个实验的,分别是获得first和follow集和用分析表进行LL(1)进行分析两个实验的综合,那还有一个实验呢?第4个实验我没有写出来,或者说放弃写了。
为什么?因为第四个实验要构建完整的语法分析程序!
不想写了,太累了,老实说写这个和前一个实验花了我很多时间和精力的,代码完全是我自己写的,没有参考其他的人的,本来就临近期末了,就放弃了。改tiny的语法分析提交一些实验内容,就没有写后面的自己定义的语法分析器了。太累了。
老实说,当初写完的时候要我分享我辛辛苦苦写的代码给别人我是一百个不愿意的,因为按我的想法,凭什么你就能轻松的获得我的劳动成果,我在辛苦写的时候你轻松玩,然后再来拿我的成果,不可以,不行,不愿意。不过,也没有人来说来拿我的代码,因为有其他人写好的,人也比我更好接触,即使知道我写好能用了验收过了,也没有人来要我的代码,因为我是个不爱分享的人,或者说,自私的人。
那你怎么又拿出来了?因为还是想要自己的成果能让别人知道的,积灰还不如造福下社会,毕竟我也是在网上学到很多东西的人,反补下也是合理的,至于有没有帮助到就不得而知了。
不过,我有个请求,如果你是参考了我的代码的写的,请不要说完全是自己写的,你就说是从网上参考的,那我就很开心的了。
废话完了,代码还是很难看懂的,希望能耐心看一看,会有些帮助。
七、资料下载
代码详见LL(1)。
编译原理——Fin