hadoop安装教程
Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
2.1 HDFS(Hadoop Distributed File System)架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.2 YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
2.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
配置Hadoop环境变量
首先去官网下载hadoop压缩包 点击打开链接
将下载好的hadoop压缩包和jdk压缩包一样上传到Linux系统,用命令解压的到目标文件夹:
tar -xvf hadoop-2.7.3.tar.gz -C ~/training/
解压好之后,进到解压的目录下,使用命令pwd列出文件所在的目录,copy一下:
之后 使用vi命令: vi ~/.bash_profile:
HADOOP_HOME="/root/training/hadoop-2.7.3" export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export PATH使用source ~/.bash_profile 使命令生效
搭建Hadoop本地模式:
Hadoop环境分为三种模式,一种是本地模式,一种是伪分布式,还有一种是全分布式。 伪分布式一般适用于开发,生产环境上是全分布式,伪分布式一台机器就可以了,但是全分布式至少3台机器。
如果想搭建本地模式很简单只需要改一个文件,进入/root/training/hadoop-2.7.3/etc/hadoop 这个个路径下,
vi hadoop-env.sh,修改里面的export JAVA_HOME="" 指向你jdk的路径即可
如下:

顺便介绍一个命令,如果你不记得你的JAVA_HOME的地址,可以用一个命令查看:echo $JAVA_HOME

最后各式一下hadoop, 输入命令: hdfs namenode -format 即可
最后 start-all.sh即可
伪分布式环境搭建
有了上面的本地模式,搭建伪分布式模式就相对简单的多:只需要配置/root/training/hadoop-2.7.3/etc/hadoop这个目录下的的文件即可:
(1) hadoop-env.sh
这个文件中的jdk的安装路径,在上面的本地模式已经配置过。
(2) hdfs-site.xml
dfs.replication
1
这个属性设置的是HDFS文件的副本个数,默认为因为我们是伪分布式,只有一台机器,nameNode 和DataNode都在一台机器上,所以设置为1.
(2)core-site.xml
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/root/training/hadoop-2.7.3/tmp
这两个参数,第一个设置的是HDFS的访问接口,第二个是HDFS的存放目录
(3)mapred-site.xml
这个文件是不存在的,但是有这个文件mapred-site.xml.template这个文件,我们可以复制一个:
cp mapred-site.xml.template mapred-site.xml这样在里面添加: 这个表示的是MapReduce的运行环境
mapreduce.framework.name
yarn
(4)yarn-site.xml
yarn.resourcemanager.hostname
localhost
yarn.nodemanager.aux-servsuoyuices
mapreduce_shuffle
第一个是yarn的主节点,第二个表示MapReduce的运行方式
配置完之后:hdfs namenode -format
start-all.sh即可启动hadoop
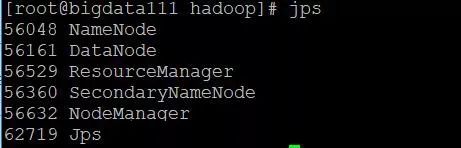
输入命令jps,列出所有的进程如下:
全分布式:
全分布式至少需要3台机器,我们以3台机器为例,一台运行NameNode,另外两台运行DataNode
配置起来跟伪分布式差不多需要更改几处文件
hdfs-site.xml
dfs.replication
2
数据的副本数就不要是1了,改成2
添加另外两台dataNode,需要更改文件slaves:

这个里面原来默认就是你本机,需要将localHost删除,添加你的另外两台机器的ip即可,这台机器作为主机主节点运行NameNode,其他两台机器运行DataNode
三台机器都要这么配置那就太麻烦了,配置好了一个之后可以copy到另外的机器:
scp -r hadoop-xx root@ip:/root/xxx/
这个命令的含义就是将hadoop-xx 这个文件copy到主机ip上,名字是root。:后面是路径

欢迎关注,一起学习大数据!
下周kafka专场,欢迎关注公众号,获得最新信息!