Kotlin进阶-6-重入锁+synchronized+volatile
目录
1、介绍
2、线程的状态
3、创建线程
4、线程同步
4.1、可重入锁
4.2、不可重入锁的实现
4.3、可重入锁的实现
4.4、Java中的可重入锁---ReentrantLock
4.5、同步方法---synchronized
5、volatile
5.1、Java 内存模型
5.1.1、原子性
5.1.2、可见性
5.1.3、有序性
5.2、volatile功能
5.2.1、volatile变量具有可见性
5.2.2、volatile不保证原子性
5.2.3、volatile保证有序性
5.3、正确使用volatile
1、介绍
进程:进程是操作系统结构的基础,是程序在一个数据集合上运行的过程,使系统进行资源分配和调度的基本单位。进程可以被看作程序的实体,同样,它也是线程的容器。
2、线程的状态
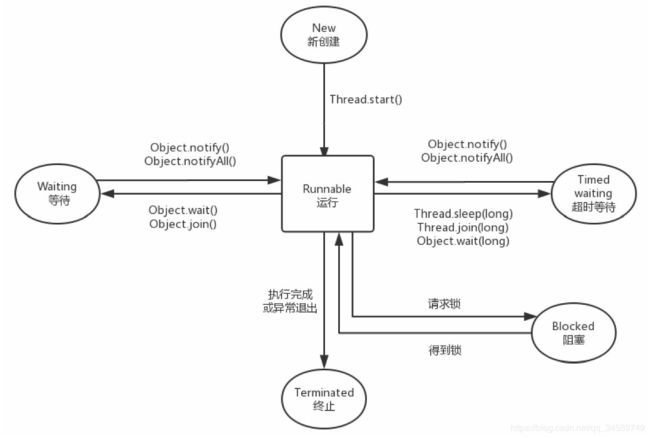
Java线程在运行的声明周期中,可能处于6种不同的状态:
New:新创建状态-----线程被创建,但是还没调用start()方法。
Runnable:可运行状态-----一旦调用了start()方法,该线程就会处于Runnable状态。一个可运行状态的线程可能在运行,也可能不在运行,这取决于操作系统给该线程提供的运行的时间。
Blocked:阻塞状态-----表示该线程被锁阻塞,该线程暂时无法运行。
Waiting:等待状态------线程暂时不活动,并且不运行任何代码,这消耗最小的资源,直到其他线程通知它,它才会返回Runnable状态。
Timed Waiting:超时等待状态-----和Waiting 状态一样都会停止运行,但是和等待状态不同的是,它在指定的时间之后会自行返回Runnable状态。
Terminated:终止状态-----表示该线程已经执行结束。导致该线程终止有两种情况:1、run方法执行完毕正常退出;2、因为一个没有被捕获的异常而终止了run方法,导致了线程进入终止状态。
3、创建线程
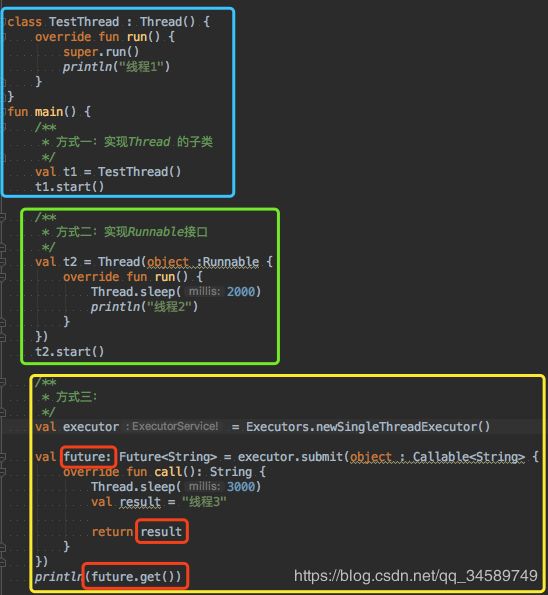
线程的创建和运行一般有三种方式:
1、实现Thread的子类,重写它的run()方法;
2、实现Runnable接口,并且重写它的run()方法;
3、实现Callable接口,重写它的call()方法。Callable接口其实是Executor框架中的功能类,它和Runnable接口类似,但是比Runnable接口功能强大,主要表现在以下三点:
<1>Callable可以在运行结束后提供一个返回值,Runnable没有返回值
<2>Callable中的call()方法可以主动抛出异常
<3>运行Callable对象可以得到一个Future对象,Future表示异步计算的结果。由于线程属于异步计算模型,因此无法从别的线程中得到函数的返回结果,在这种情况下,就可以使用Future来监视目标线程调用call()的返回结果。当你调用Future的get()方法获取返回值的时候,当前线程会被阻塞,直到call()方法返回结果。
4、线程同步
在多线程应用中, 通常情况下,两个或者两个以上的线程需要共享对同一个数据的存取。如果两个线程存取相同的对象,并且每一个线程都调用了修改该对象的方法,这种情况通常被叫做竞争条件。而解决这种竞争情况的方法就是 锁机制。
在Java中,我们一般使用锁的方式是通过synchronized关键字来实现。但是这里我们先介绍以下可重入锁和不可重入锁来让你对synchronized有一个更深的认识。
4.1、可重入锁
可重入锁:指的是以线程为单位,当一个线程获取对象A的锁之后,这个线程可以再次获取对象A上的锁,而其他的线程是不可以的。
synchronized 和 ReentrantLock 都是可重入锁。
可重入锁的作用:防止死锁。
实现原理:是通过为每个锁关联一个请求计数器和一个占有它的线程。当计数为0时,认为锁是未被占有的;线程请求一个未被占有的锁时,JVM将记录锁的占有者,并且将请求计数器置为1。
如果同一个线程再次请求这个锁,计数将递增;
每次占用线程退出同步块,计数器值将递减。直到计数器为0,锁被释放。
4.2、不可重入锁的实现
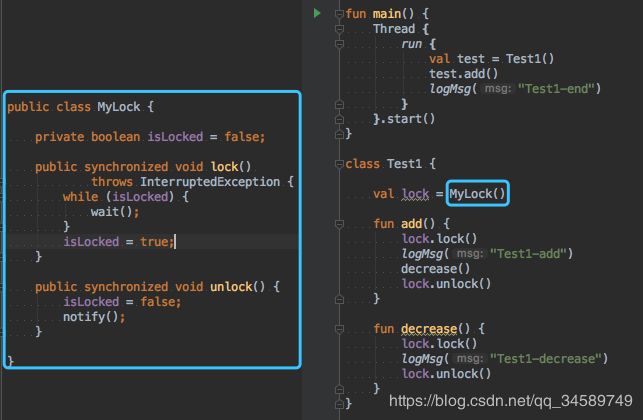
我们先来实现一下不可重入锁的实现,代码如下图:(这里实现用Java实现MyLock的原因是Kotlin中Any类无法调用wait()方法)
由上面的可重入锁的定义我们应该直到不可重入锁的定义:当一个线程获取对象A的锁之后,这个线程不可以再次获取对象A上的锁。
左侧是我们锁的实现,我们可以根据该锁的lock() 和unlock()方法来实现同步代码块,当一个线程第一次调用该锁的lock()方法时,会将isLock置为true,当另一个线程(或者自己)想再次调用lock()方法时,会进入阻塞状态,这也就和定义形成了照应,一个线程无法多次获取MyLock对象的锁。
输出结果如下:
从输出结果我们可以看出,线程Thread-0 只执行了add()方法的内容,当执行到decrease()的lock.lock()方法时,我们线程进入了阻塞的状态,而且一直阻塞下去,这就导致了死锁了状态,这也就解释了我们的可重入锁的作用为什么是防止死锁了。
![]()
4.3、可重入锁的实现
实现如下图:
它和不可重入锁的区别在于,如果是线程A执行了lock对象锁构成的同步代码块时,当该线程A再次执行获取lock对象的锁时,不会被阻塞,而是会继续执行,但是其他线程获取不到lock对象的锁。
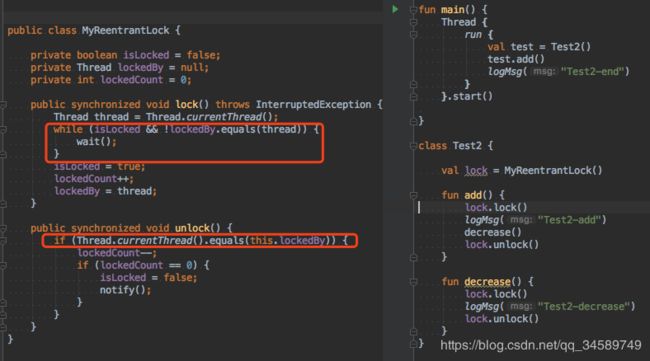
输出结果也证明了它的定义。
4.4、Java中的可重入锁---ReentrantLock
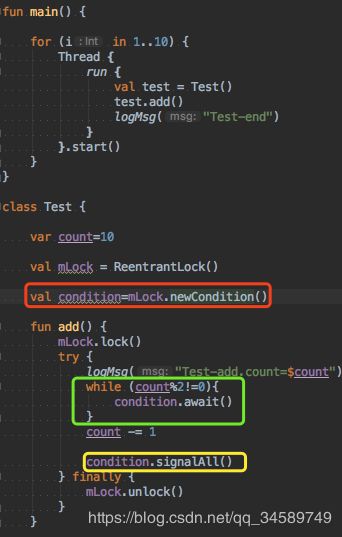
Java中对于可重入锁的实现除了synchronized之外,还有ReentrantLock类,它的使用如下图:
我们可以通过lock()和unlock()方法来实现下同步代码块,使用try...finally 语句是必要的,因为在我们同步代码块执行异常的情况下,也应该正常释放锁。否则的话,其他线程将永远会被阻塞。
-------------------------------------------------------------------------------
对于ReentrantLock,当我们的线程在调用ReentrantLock构成的同步代码块时,进入死循环中时,可以通过条件对象来让该线程释放锁,给其他线程执行的机会。
如右下图绿色框中,当该线程执行内容不符合条件时,会进入到死循环中,这时候我们可以通过await()方法来让线程退出死循环,并且进入阻塞状态和放弃对锁的控制,让其他符合条件的线程进行执行。
那么你阻塞的线程怎么恢复执行呢?可以通过黄色框内的signalAll()来重新激活因为while循环条件不符合而进入阻塞的线程。

4.5、同步方法---synchronized
Lock和Condition接口为程序设计人员提供了高度的锁控制,然而大多数情况下, 并不需要那样的控制,并且可以使用一种嵌入到Java语言内部的机制。从Java 1.0版本开始,Java中的每一个对象都有一个内部锁 ,如果一个方法用synchronized声明,那么对象的锁将保护整个方法。
下图中,黄色框和绿色框内的内容是等价的。
在Kotlin中是没有Synchronized、Volatile关键字的,但是有他们的注解,注解出来的是同步的方法,对于同步代码块可以如下图那样编写。但是同步代码块是比较脆弱的,所以我们建议可以使用阻塞队列,或者上面讲到的Lock、Condition来实现同步代码。

5、volatile
有时仅仅为了读写一个或者两个实例域就使用同步的话,显得开销过大;而Volatile关键字为实例域的同步访问提供了免锁的机制。
在详细讲解volatile之前,我们先了解一下Java内存模型。
5.1、Java 内存模型
Java中堆内存用来存储对象实例,堆内存是所有线程的共享的运行时内存区域。
而局部变量、方法定义的参数则不会在线程之间共享。
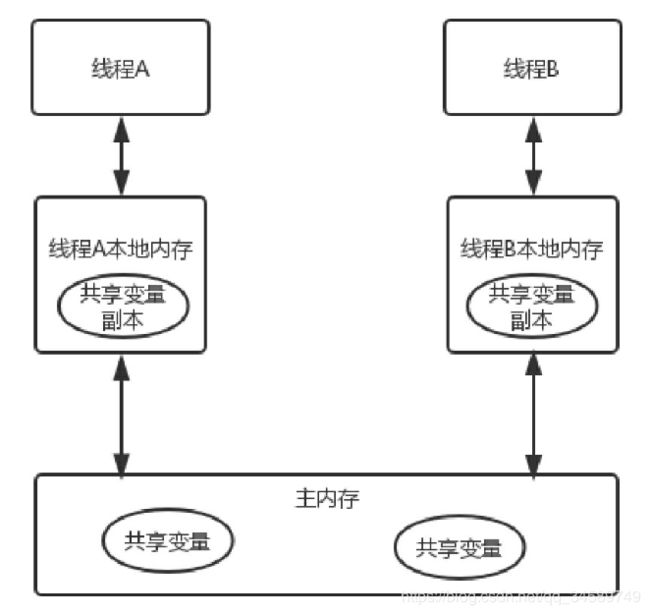
Java内存模型定义了线程和主存之间的的抽象关系,线程之间的共享变量存储在主存中,每个线程都有自己的私有的本地内存,本地内存中存储了该线程共享变量的副本。
需要注意的是,主存和本地内存是Java内存模型的一个抽象概念,其实并不存在,它涵盖了缓存、写缓存区、寄存器等区域。
Java内存模型控制线程之间进行通行,它决定一个线程对主存共享变量的写入 何时对另一个线程可见。
----------------------------------------------------------------------------------------------
Java内存模型的抽象示意图如下:
那么线程A和线程B之间的通信过程:
线程A更新本地内存共享变量副本的值---->将该值刷新到主存中----->线程B从主存中去读取该共享变量的值---->更新线程B共享变量的副本
5.1.1、原子性
对于基本数据类型变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行完毕,要么就不执行。
对于上图三条语句,只有第一条语句是原子性操作;
语句2包含了两个操作:1、读取x的值;2、将x的值写入到工作内存中。这两个操作单独放的话就是原子性操作,但是合起来就不是了。
语句3包含了三个操作:1、读取x的值;2、将x的值+1;3、将x的值写入到工作内存中。
通过上面的介绍,我们应该直到一个语句包含多个操作的话,就不是原子性操作,只有简答的读取和赋值才是原子性操作。
java.util.concurrent.atomic包中有很多类使用了很高效的机器级指令(而不是使用锁)来保证其他操作的原子性。例如AtomicInteger类提供了方法incrementAndGet()和decrementAndGet,它们分别以原子方式将一个整数自增自减。可以安全地使用AtomicInteger类作为共享计数器而无需同步。
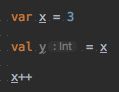
5.1.2、可见性
可见性,是指线程之间的可见性,一个线程修改的状态是对另一个线程是可见的。也就是说一个线程修改的结果,另一个线程可以马上看到。当一个共享变量被volatile修饰时,它会保证被修改的值立即更新到主存中,所以对其他线程是可见的。没有被volatile修饰的变量则无法保证变量的可见性,当其他线程读取该值的时候,该值有可能还没有被更新到主存中。
5.1.3、有序性
Java内存模型允许编译器和处理器对指令进行重排序,虽然重排序过程不会影响到单线程执行的正确性, 但是会影响到多线程并发执行的正确性。
这是可以通过volatile来保证有序性,除了volatile,也可以通过synchronized和Lock来保证有序性,我们知道synchronized和Lock构成的同步代码块,每个时刻只有一个线程执行,这相当于让多线程顺序地执行同步代码,从而保证了有序性。
5.2、volatile功能
当一个共享变量被vlatile修饰时,其就具备两个含义:
1、一个线程修改了变量的值,变量的新值对其他线程是立即可见的
2、禁止使用指令重排序
-------------------------------------------
什么是指令重排序呢?
重排序通常是编译器或者运行环境为了优化程序性能而采取的对指令重新排序执行的一种手段。重排序分为两类:编译期重排序和运行期重排序,分别对应着编译时和运行时环境。
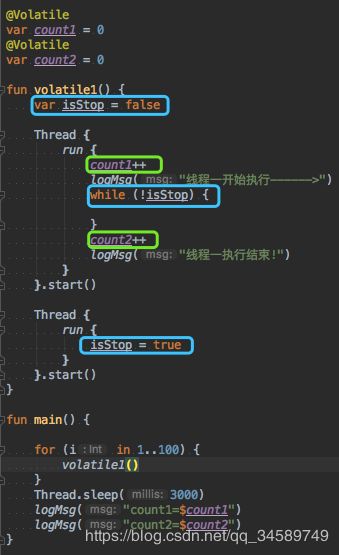
5.2.1、volatile变量具有可见性
看下面的程序,如果按照正常的执行程序的话,我们线程1中的while循环应该每次都能在线程2改变isStop的值之后,退出这个死循环,执行count2++的语句,但是当我们执行一百次的时候,发现结果,并不是每次都能跳出while循环,这就是因为线程2在改变了isStop的值之后没有将值更新到主存中,这样线程1以为isStop还是false的状态,这样它就不会停止循环。
但是当我们用Volatile修饰该变量之后,就不会出现这种情况了。
5.2.2、volatile不保证原子性
看如下代码:
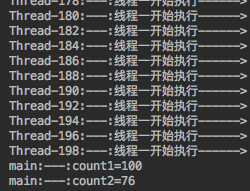
当你在多次执行该代码的时候,你会发现它每次的输出结果都是不一样的。
假设线程1读取了count1的原始值=0.然后开始自增操作,当自增到999的时候,线程1被阻塞了,这时候线程1还没有把5这个值写入到主存中,所以线程2去读取的时候,count1的值还是0,这时候线程2开始自增,当线程2自增结束,并将count1的值更新到了主存中,这时候线程1恢复了自增操作,并将1000的值也更新到了主存中,这时候你会发现总共进行了2000次自增操作,但是值还是1000。
前面讲过了 count1++语句不是原子性操作,它具有三个子操作步骤:1、读取x的值;2、将x的值+1;3、将x的值写入到工作内存中。
所以我们的volatile语句也不能保证对变量的操作是原子性的。

5.2.3、volatile保证有序性
volatile能禁止指令的重排序,因此volatile保证有序性。
volatile禁止指令重排序的含义:当程序执行到volatile变量的时候,在其前面的语句已经全部执行完成,并且结果对后面可见,而且该变量后面的语句都没有执行。
5.3、正确使用volatile
synchronized可以防止多个线程同时执行一段代码,这会阻塞一部分线程的执行,这样就会影响程序的执行效率。
而volatile在某些情况下的性能是优于synchronized的。
但是volatile无法替代synchronized,因为volatile无法保证操作的原子性。
--------------------------------------------------------------
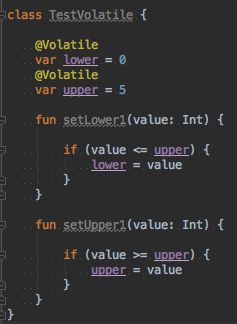
通常情况下,我们使用volatile关键字要避开两种场景:
1、对变量的写操作依赖当前值;比如前面我们示例的自增操作。
2、该变量包含在具有其他变量的不变式中。如下图:我们的初始范围 0-5 ,但如果两个线程同时对该类进行执行的时候,比如setLower1(4),setUpper1(3),那么我们最后的范围将会变成 4-3 。这显然是不对的。
使用volatile的场景有很多,这里介绍两种常见的场景:
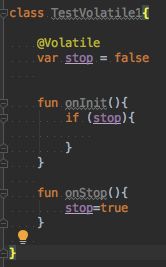
场景1:状态标志
当多线程执行该类的时候,我们需要对状态标志stop保持可见性,这样我们的运行才能实时保持正确的执行。这种情况如果使用sychronized的话显然要复杂的多。
场景2: 双重检查模式(DCL)
我们的单例模式经常会这样写,第一次判空是为了不必要的同步操作,第二次判断是只有在MyLock实例==null的时候才会去new一个实例出来,当多线程调用时,当进行这两次判空时,我们需要保证instance的可见性。