webmagic爬取图片
webmagic算是一个国人开发比较简单粗暴的爬虫框架,首页:http://webmagic.io/ 中文文档:http://webmagic.io/docs/zh/posts/ch2-install/
这次随便找了个小图片网站爬取(大网站没代理怕被封IP):http://www.mmonly.cc/ktmh/hzw/list_34_1.html
分析网站:
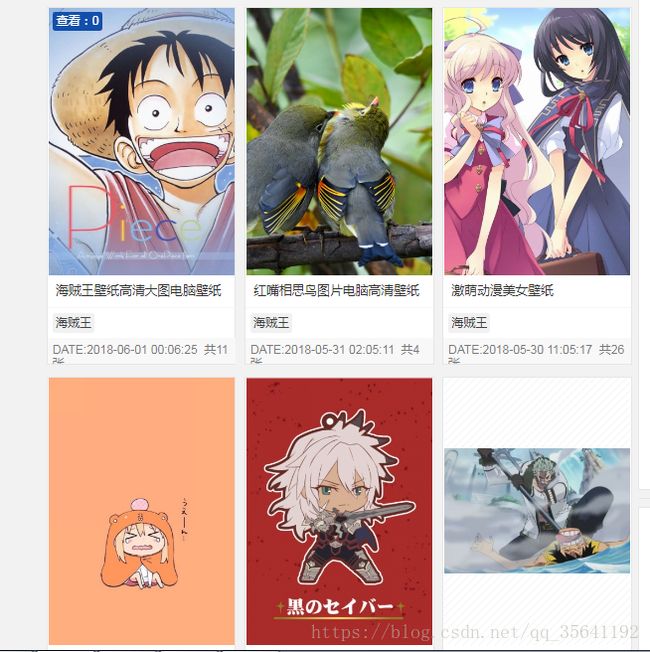
要获取这些主要内容的连接
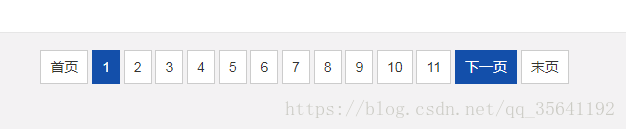
获取下一页的地址

最后根据前面的地址进入详细页面获取图片和下一页的连接
按F12查看资源有什么共性然后分析抓取

可以通过鼠标右键copy->copy selector等等获取该元素在网页中的位置(爬虫框架支持select选择器)
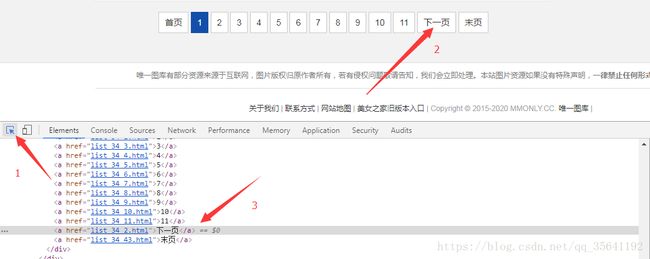
可以这样快速定位需要找的元素代码在哪
上代码:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.dagroupId>
<artifactId>spider-picartifactId>
<version>0.0.1-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-coreartifactId>
<version>0.7.3version>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-extensionartifactId>
<version>0.7.3version>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-seleniumartifactId>
<version>0.7.3version>
dependency>
<dependency>
<groupId>org.seleniumhq.seleniumgroupId>
<artifactId>selenium-javaartifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.seleniumhq.seleniumgroupId>
<artifactId>selenium-chrome-driverartifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.seleniumhq.seleniumgroupId>
<artifactId>selenium-serverartifactId>
<version>2.18.0version>
dependency>
dependencies>
project>后面几个依赖还没弄清楚具体什么用
主程序:
package com.da.main;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
public class PicProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000);
@Override
public void process(Page page) {
if (page.getUrl().toString().startsWith("http://www.mmonly.cc/ktmh/hzw/list_")) {
// System.out.println(1);
// 获取详情页面
page.addTargetRequests(page.getHtml().$("div.item_t > div > div.ABox > a").links().all());
// 获取下一页,倒数第个a标签
page.addTargetRequest(page.getHtml().$("#pageNum > a:nth-last-child(2)").links().toString());
} else if (page.getUrl().regex("http://www.mmonly.cc/ktmh/hzw/[\\d]+") != null) {
// System.out.println(page.getUrl());
// 下一页
Selectable links = page.getHtml().$("#nl > a").links();
if (links != null && links.toString() != "##")
page.addTargetRequest(links.toString());
// 抓取内容
String img = page.getHtml().$("#big-pic p img").toString();
if (img == "null")
img = page.getHtml().$("#big-pic a img").toString();
img = img.substring(img.indexOf("src=\"") + 5, img.length() - 2);
// System.out.println(img);
page.putField("img", img);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new PicProcessor()).addUrl("http://www.mmonly.cc/ktmh/hzw/list_34_1.html")
.addPipeline(new MyPipeline()).thread(5).run();
}
}主程序就用官方推荐的模版就行了,主要抓取逻辑在process方法里面,就是一些正则和选择器获取解析内容工作
最后如果要那下载图需要重写Pipeline方法,默认是控制台打印路径
package com.da.main;
import com.da.utils.UrlFileDownloadUtil;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public class MyPipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task task) {
// System.out.println(resultItems.getRequest().getUrl());
String url = resultItems.get("img").toString();
UrlFileDownloadUtil.downloadPicture(url);
}
}下载工具类:
package com.da.utils;
import java.io.DataInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.List;
public class UrlFileDownloadUtil {
/**
* 传入要下载的图片的url列表,将url所对应的图片下载到本地
*/
public static void downloadPictures(List urlList, List names) {
String baseDir = "E:\\spider\\";
URL url = null;
for (int i = 0; i < urlList.size(); i++) {
try {
url = new URL(urlList.get(i));
DataInputStream dataInputStream = new DataInputStream(url.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(new File(baseDir + names.get(i)));
byte[] buffer = new byte[1024 * 50];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
fileOutputStream.write(buffer, 0, length);
}
System.out.println("已经下载:" + baseDir + names.get(i));
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void downloadPictures(List urlList) {
String baseDir = "E:\\spider\\";
URL url = null;
for (int i = 0; i < urlList.size(); i++) {
try {
String[] files = urlList.get(i).split("/");
String name = files[files.length - 1];
url = new URL(urlList.get(i));
DataInputStream dataInputStream = new DataInputStream(url.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(new File(baseDir + name));
byte[] buffer = new byte[1024 * 50];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
fileOutputStream.write(buffer, 0, length);
}
System.out.println("已经下载:" + baseDir + name);
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 下载一张图片
public static void downloadPicture(String u, String name) {
String baseDir = "E:\\spider\\";
URL url = null;
try {
url = new URL(u);
DataInputStream dataInputStream = new DataInputStream(url.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(new File(baseDir + name));
byte[] buffer = new byte[1024 * 50];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
fileOutputStream.write(buffer, 0, length);
}
System.out.println("已经下载:" + baseDir + name);
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
// 下载一张图片
public static void downloadPicture(String u) {
String baseDir = "E:\\spider\\";
URL url = null;
String[] files = u.split("/");
String name = files[files.length - 1];
try {
url = new URL(u);
DataInputStream dataInputStream = new DataInputStream(url.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(new File(baseDir + name));
byte[] buffer = new byte[1024 * 50];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
fileOutputStream.write(buffer, 0, length);
}
System.out.println("已经下载:" + baseDir + name);
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}